
A unified deep neuro-fuzzy approach for COVID-19 twitter sentiment classification
Abstract
Covid-19 braces serious mental health crisis across the world. Since a vast majority of the population exploit social media platforms such as twitter to exchange information, rapid collecting and analyzing social media data to understand personal well-being and subsequently adopting adequate measures could avoid severe socio-economic damage. Sentiment analysis on twitter data is very useful to understand and identify the mental health issues. In this research, we proposed a unified deep neuro-fuzzy approach for Covid-19 twitter sentiment classification. Fuzzy logic has been a very powerful tool for twitter data analysis where approximate semantic and syntactic analysis is more relevant because correcting spelling and grammar in tweets are merely obnoxious. We conducted the experiment on three challenging COVID-19 twitter sentiment datasets. Experimental results demonstrate that fuzzy Sugeno integral based ensembled classifiers succeed over individual base classifiers.
1Introduction
Coronavirus pandemic has caused major changes in peoples’ personal and social lives. The psychological effects have been substantial because they have affected the way people live, work, and even socialize. It has also become a part of major discussions on social media platforms as people showcase their opinions and the effects of the virus on their mental health particularly [29]. Social media has become one of the major sources of information due to information sharing on a very large scale. People perception and emotions are also portrayed through their conversations. In this research work, the interaction and conversation of people on social media, particularly Twitter, has been analyzed using machine learning tools and algorithms to determine the effect of the virus on the mental health of people and help suggest the area of concentration to medical practitioners in order to speed up the recovery process and reduce the mental health issues which has escalated due to the virus.
Several classifiers, such as K-Nearest Neighbours, Decision tree, Random forest, and Gaussian Nearest Neighbours have been developed in the literature [20] to deal with sentiment classification. However, most of the classification approaches include single classifiers. In this paper, we propose a framework sugeno integrals [4] as meta-classifiers to aggregate the results of several individual classifiers. Given its characteristics, Sugeno integral associated with its fuzzy measure has been applied in data mining and information fusion in different tasks such as decision making and classification problems. In this research, we proposed a unified approach for twitter sentiment classification using Sugeno integral which performs better than individual classifiers. Fuzzy logic is most appropriate for imperfect data like Twitter in which grammar and spelling correction is entirely unpleasant. We tested the proposed methods on three challenging kaggle datasets. We conducted extensive experiments using a combination of text features such as N-grams, word2vec, word embeddings, and fuzzy features, as well as, a set of machine learning and deep learning classifiers and their fuzzy variants. Experimental results demonstrate that unsupervised fuzzy based aggregation framework obtains state-of-the-art performances.
The rest of the paper is as follows. Section 2 presents related works regarding machine learning and deep learning algorithms for sentiment analysis and COVID-19 induced mental health prediction from twitter data. Section 3 describes the architecture for the proposed unified deep neuro-fuzzy approach for COVID-19 twitter sentiment analysis. Section 4 represents data description and demonstrates the superiority of the proposed unified approach over existing algorithms. Section 5 concludes the work.
2Literature review
Related works found in the literature are categorized into four different classes based on the proposed approach: fuzzy rule based approach, deep learning, hybrid, and ensemble methods.
Fuzzy rule based approach. Vashishtha et al. [30] proposed a fuzzy logic based approach for dynamic plotting of mood swings from tweets by using the linguistic hedges with fuzzy logic to compute the sentiment of tweet. Vashishtha et al. [31] proposed a novel fuzzy system which integrates natural language processing techniques and word sense disambiguation using a novel unsupervised nine fuzzy rule based system to classify the social media posts into positive, negative or neutral sentiment classes. The proposed method uses three sentiment lexicons, unlike the traditional sentiment analysis method which uses a single lexicon and thus obtains better accuracy. Han et al. [18] used the fuzzy C-means clustering method (an unsupervised soft computing technology) for emotion sentiment classification which divided the content of Weibo, Chinese Social Networking Service, into seven categories: fear, happiness, disgust, surprise, sadness, anger, and good. Jefferson et al. [22] used a fuzzy rule-based system for sentiment analysis which performs marginally better than decision tree and Naïve Bayes on dual sentiment dataset. This approach produced more refined outputs by exploiting fuzzy membership degrees. Wang et al. [33] used fuzzy logic-based approach to identify the sentiment classification of the students’ feedback that contain lexicon based classification approach. Efrilianda et al. [14] analyzed public sentiments towards Covid-19 events and built a bot that finds out trending orders of topics on Twitter during the Covid-19 pandemic. Basha et al. [7] evaluated the performance of fuzzy rule in classifying sentiments from tweets using the twitter corpus of 50,000 tweets and compared them against the MAXNET based approach. Alsolamy et al. [19] used the Latent Dirichlet Allocation (LDA) for feature extraction of the text whereas a lexicon-based approach (LBA) was performed for sentiment analysis from a large corpus data. Jefferson et al. [22] proposed a fuzzy based approach to classify the tweets which focus on polarity classification. The proposed approach could produce more refined outputs based on the fuzzy membership degree values. Chakraborty et al. [8] had proposed a gaussian membership function based fuzzy rule model to correctly identify the sentiment from the tweets. Ghani et al. [17] used a fuzzy logic approach using SentiWordNet library to evaluate the polarity score of the sentiments.
Deep learning Algorithms. Uma et al. [24] proposed a new general cost function for classification problem using optimized deep learning approach to solve the misclassification problem present in the social media review data set. This research uses a new general accuracy feature selection technique using convolutional neural network equipped with evolutionary optimization techniques. They designed a new deep learning fuzzy based classification algorithm to extract features for identifying the optimal feature selection using bag of words, evolutionary method along with conditional neural networks. Iwendi et al. [21] developed an Adaptive Neuro-Fuzzy Inference System (ANFIS) aimed for determining the attributes contributing to the early Coronavirus Disease (COVID-19) detection. This work computes the accuracy of different machine learning classifiers and selects the best classifier for COVID-19 detection based on a comparative analysis. Jelodar et al. [23] used NLP and deep learning model based on Long Short Term Memory (LSTM) recurrent neural network for sentiment classification of public opinions on social issues related to COVID-19. Haque et al. [19] analyzed the sentiments on a topic extracted from Twitter and labelled them as the positive or negative category of the topic. This proposed method used SentiWordNet 3.0.0 for having the values of the user’s opinions or sentiments. Chintalapudi et al. [9] used the BERT model for data and sentiment analysis from covid-19 tweets having three levels: positive, negative and neutral. The evaluation results showed that the BERT model performed better than Logistic Regression, SVM, and LSTM.
Hybrid Models. Daoyuan et al. [11] intended a new sentiment computation approach, which is defined as public sentiments discriminator (PSD), considering both fuzzy logic and sentiment complexity. Unlike traditional machine learning methods, PSD is based on the rational hypothesis that sentiments are correlated with each other. A three-level computing structure, sentiment-term level, microblog level and public sentiment level are employed. Madani et al. [27] developed a hybrid approach based on the fuzzy logic with its three important steps (fuzzification, Rule Inference/aggregation and defuzzification) and the concepts of information retrieval system (IRS) by calculating the semantic similarity between a tweet to classify and two opinion documents (one for the positive opinion words and another one for the negative opinion words) using the WordNet dictionary to classify tweets into three classes: positive, negative or neutral. Ahmad et al. [5] used a mathematical model called fuzzy autocatalytic set, which helps to solve the problems of the scarcity, quantity, and availability of data to analyze the Covid-19 pandemic. Cresswell et al. [10] presented a hybrid based approach by combining the state-of-art lexicon rule-based and deep learning-based approach on covid19 twitter datasets.
Ensemble Methods. Mehdi Emadi et al. [15] proposed a new approach for twitter sentiment analysis by combining the results of classic classifiers and NLP based methods which uses fuzzy measures with Choquet Integral to aggregate the labels predicted by individual classifiers to obtain a better accuracy. Alhumoud et al. [6] proposed a deep learning based sentiment analysis from twitter data related to Covid-19 using ensemble learning techniques to obtain a better accuracy than that of the single classifiers.
3Proposed unified deep neuro-fuzzy approach for COVID-19 twitter sentiment classification
In this paper, we intend a fuzzy Sugeno integral based unified approach for deep neuro-fuzzy system for COVID-19 twitter sentiment classification. The architecture for implementing the unified approach is demonstrated in Fig. 1. The proposed methodology consists of the following sequential steps.
Fig. 1
Proposed architecture for unified deep neuro-fuzzy based sentiment classification.

3.1Data preprocessing
Data Preprocessing is the most important step of data mining which deals with the transformation and preparation of datasets for knowledge extraction. There are several techniques involved in preprocessing. Some of them are cleaning, integrating, transforming and reducing the dataset. This results in a structured / clean data that are useful for modelling. Data collected or extracted from different sources are usually in their raw format which are not feasible for analysis, therefore, the raw data must first be cleaned before analysis. Some of the preprocessing done on the twitter raw data include: removal of the (i) urls from the text; (ii) the special characters; (iii) all usernames with ; (iv) numbers from characters; (v) stopwords; (vi) convert all letters to lowercase; and (vii) drop null values.
3.2Computing features
In this study we computed two different types of features from text data for sentiment classification: (a) Text features; and (b) Fuzzy features.
3.2.1Text features
The data are usually in text data type which are not compatible with machine learning models. Machine learning models are only compatible with numeric values. There are techniques available in the literature to convert these text data into numeric features without losing the meanings of the data such as N-gram, word2vec, continuous bag of words, continuous skip-gram model, and bag of words [25]. In this study we computed N-gram for twitter sentiment classification. N-gram is a sequence of words in a sentence. N-gram is probably the simplest concept in machine learning. There are quite some varieties of usefulness of N-gram. It can be used for auto-correction of words, auto spell check and also grammar checks. It also helps to check the relationship between words especially when one is trying to figure out what someone is more likely to say to determine the emotions or sentiments. N-grams are the combination of words that are used together. Unigrams are N-grams with N = 1. For N = 2, and 3 are referred to as bigrams and trigrams respectively. N-grams capture the structure of the language helping to determine which word is likely to follow a given word.
3.2.2Fuzzy features
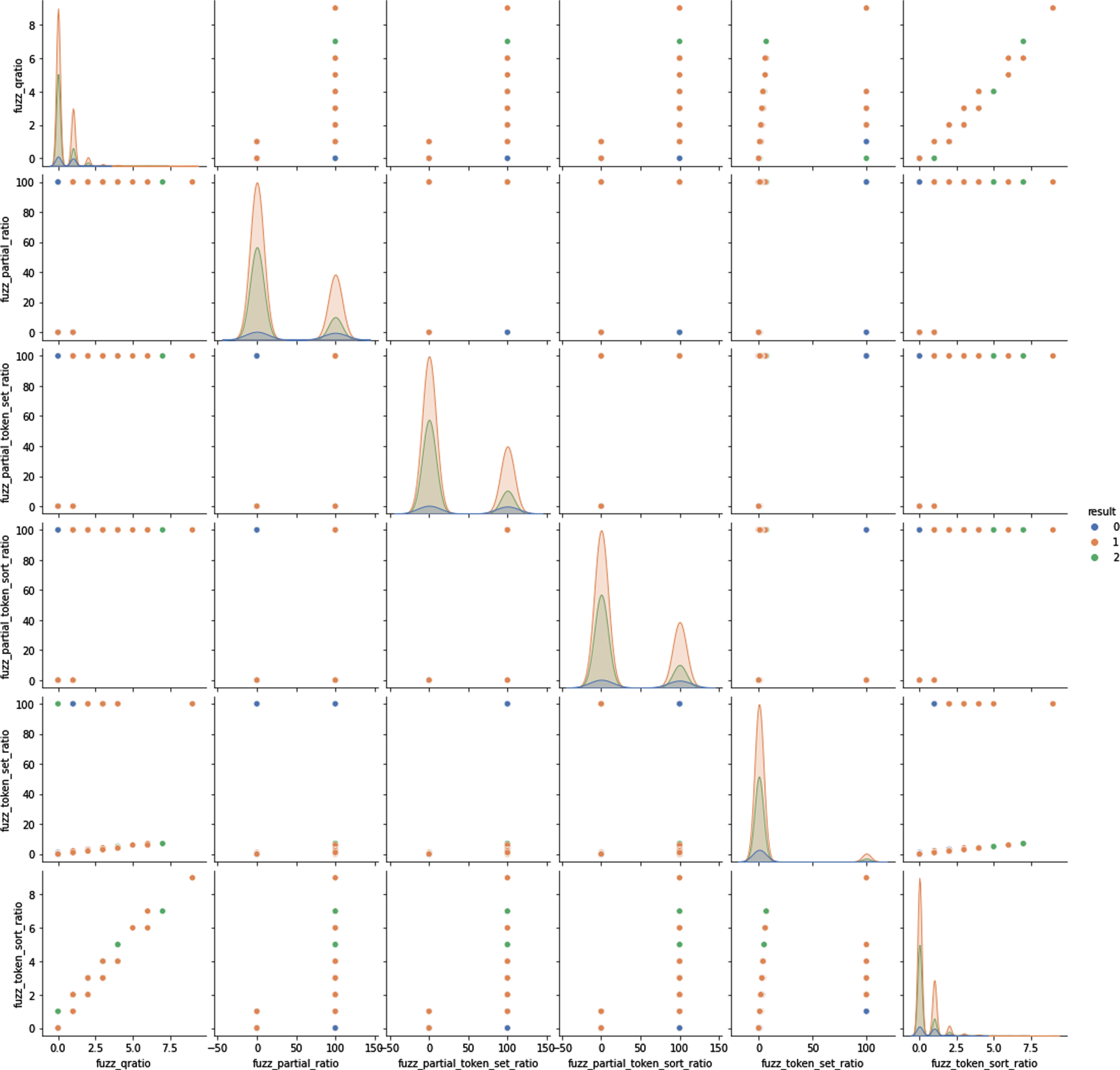
In this problem we have used 6 different fuzzy features which are typically used for string matching [16]. String matching is useful in variety of NLP problems, for example joining two tables by player name when it spelled differently. Fuzzy QRatio, also called Fuzzy Quick Ration, computes the Levenshtein distance similarity ratio between the two strings. Partial Ration has more powerful functions to help with matching strings in more complex situations. The partial ratio function allows us to perform substring matching. It is computed by taking the shortest string and matching it with all substrings that are of the same length. This function is also useful when matching names. Token Sort Ratio also has functions that tokenize the strings, change capitals to lowercase, and remove punctuation. The token sort ratio function sorts the strings alphabetically and then joins them together. The fuzzy ratio is calculated when two strings are the same in spelling but are not in the same order. The token set ratio function is similar to the token sort ratio function above, except it takes out the common tokens before calculating the fuzzy ratio between the new strings. This function is the most helpful when applied to a set of strings with a significant difference in lengths. Figure 2 illustrates the pairwise correlation between the fuzzy features for covid vaccine (third) dataset described later.
Fig. 2
Pairwise correlation between the fuzzy features for covid vaccine dataset.
3.3Text feature selection
Feature selection is the process of identifying and selecting a subset of input features that are most relevant to the target variable. Different methods are available for feature selection techniques such as mutual information, variance threshold, anova test, and Pearson correlation coefficient [20]. In this study we used mutual information for text feature selection techniques. Mutual information from the field of information theory is the application of information gain (typically used in the construction of decision trees) to feature selection. Mutual information is calculated between two variables and measures the reduction in uncertainty for one variable given a known value of the other variable.
3.4Machine learning Algorithms
In this study, we exploited both machine learning classifiers such as K-Nearest Neighbours, Decision tree, Random forest, and Gaussian Nearest Neighbours [20] and their fuzzy variants.
3.4.1Fuzzy min max classifier
The Fuzzy Min-Max (FMM) neural network [12] is a powerful neural network combining neural network and fuzzy set theory for solving classification problems. FMM neural network is composed of three layers where the first layer is inputs (FA), the second layer is Hyperboxes (FB) and each node in the third layer (FC) represents a class. Each hyperbox is a node of middle layer (FB) and membership function of this hyperbox is transition function of that node.
3.4.2Fuzzy decision tree classifier
Fuzzy decision trees (FDT) [32] is an extension of Decision Trees, which combine symbolic decision trees with approximate reasoning offered by fuzzy representation. Fuzzy decision trees use the same routines as symbolic decision trees but with fuzzy representation. Fuzzy decision trees are able to process data expressed with symbolic, numerical values and fuzzy terms.
3.4.3Fuzzy support vector machine
Fuzzy Support Vector Machine (SVM) [26] applies a fuzzy membership to each input point and transforms the SVM in such a way that different input points can make different contributions to the learning of decision surface.
3.4.4Unsupervised fuzzy rule based classifier
Vashishtha et al. [31] computed the sentiment of social media posts using a novel set of fuzzy rules involving multiple lexicons and datasets. They proposed a novel unsupervised nine fuzzy rule-based system that classifies a social media post into three sentiment classes, positive, negative, and neutral.
3.4.5Fuzzy convolutional neural network
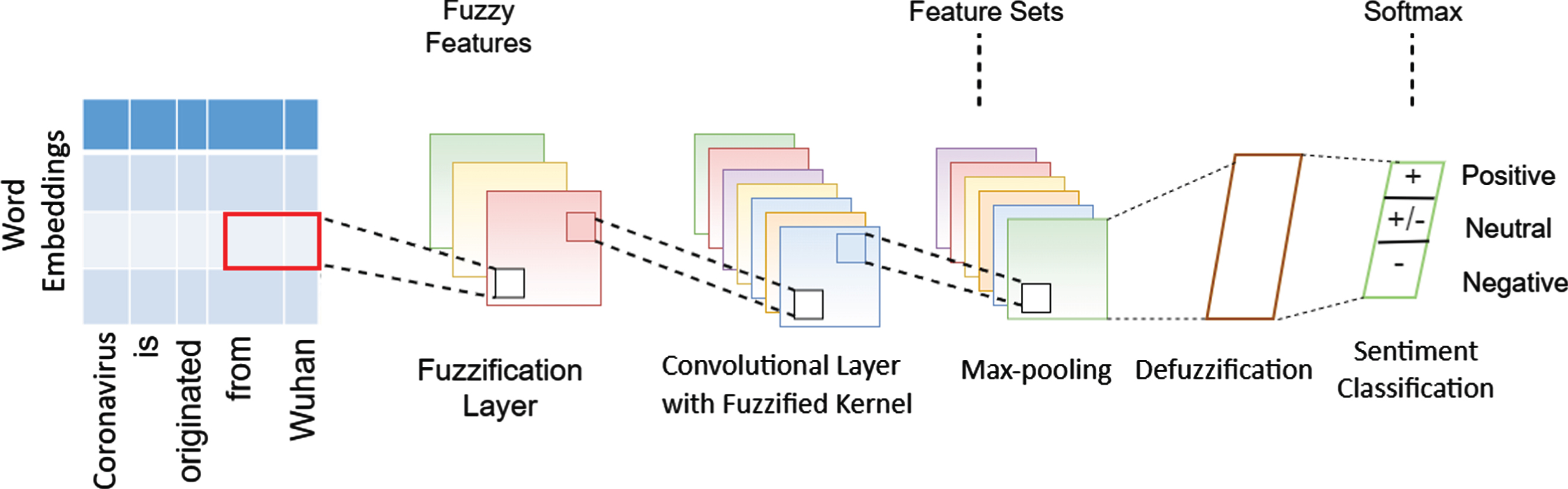
In this study we have used Fuzzy Convolutional Neural Network (FCNN) [28] for COVID-19 twitter sentiment classification. The architecture of FCNN is illustrated in Fig. 3 and it’s working principle is as follows. Firstly, the input sentence is embedded by embedding layer to a real value matrix. Then fuzzification layer transforms the input matrix into fuzzy domain. After that, the fuzzy representation is convoluted in fuzzy convolutional layers which works as a filter to get high-level features from the data. After passing through the fuzzy convolutional stage, the extracted feature set is converted into crisp value by defuzzification layer. Finally, fully connected layer works as output classifier for FCNN. FCNN computes a score value for each emotional label for sentiment classification of a sentence. To achieve this, the model first receives the input as a sequence of words and passes through the layers of the model. Through each layer, higher-level features are extracted and taken to the next layer. The model then extracts the features from the vector level of the word to the sentiment level of the sentence. For sentiment classification from the text data using FCNN, the words in the sentence must be expressed as numerical values. In this study we used N-gram, word2vec and fastText and fed them into CNN. After embedding each input, each element in the input matrix is assigned multiple linguistic labels based on membership functions. The fuzzy membership function computes the grade which represents the membership of the input node to a particular fuzzy set.
Fig. 3
Fuzzy Convolutional Neural Network for sentiment analysis.
3.5Fuzzy fusion
There are two popular fuzzy integrals. Sugeno Integral [4] and Choquet integral [13] are effective aggregation operators based on the fuzzy measures which can be used for fusion framework. Depending on the values of each element in the fuzzy measure, they model a variety of relationships amongst the fusion sources. It combines a set of values u1, . . . , um pertaining to m criteria into a single representative value, accounting for the importance of subsets of criteria as specified by the capacity. Unlike Choquet Integral which uses addition and the multiplication operators, Sugeno Integral uses maximum and the minimum operators. In this study we used Sugeno integral for combining the base (individual) classifiers.
4Experimental results and discussions
4.1Dataset description
In this research, we have analyzed three Covid-19 twitter sentiment datasets collected from Kaggle which are as follows:
The first dataset collected from “Open Challenge Covid-19 Twitter Sentiment Analysis" [3] contains 9890 tweets related to COVID-19 and includes three sentiment labels: positive, negative, and neutral.
– Positive Tweets (Polarity score 1): The tweets which indicate positive mindset such as feelings, judgement, emotions, and evaluations are marked as positive tweets. Tweets include good news from the coronavirus perspective, recovery of the people, safe places etc. Example: “Medical workers at #Wuhan hospital sing to the #coronavirus patients to support them in fight against the virus.”
– Negative Tweets (Polarity score 2): Tweets that include the deaths, spread and effects of coronavirus, bad language etc. Example 1: “UAE confirms 5th case of #Wuhan #CoronaVirus.”
– Neutral Tweets (Polarity score 3): The tweets that do not fall under positive and negative tweet criteria are marked as neutral tweets. Tweets that include general discussion, links only or information etc. Example: “How #Coronavirus Damage Your #Mobile #PC and #Laptop - Be Safe https://t.co/Gmtui3nmKE Thanks @Kaspersky for informing us."
The main attributes of the second dataset [1] include: Tweet ID, Creation Date & Time, Source Link, Original Tweet, Favorite Count, Retweet Count, Original Author, Hashtags, User Mentions, Place. The first and second phase of this dataset contain 22,35,240 and 3,20,316 tweets respectively. The dataset include the hash-tagged keywords like - #covid 19, #coronavirus, #covid, #covaccine, #lockdown, #homequarantine, #quarantinecenter, #socialdistancing, #stayhome, and #staysafe.
Finally, the third dataset [2] has a total of 5991 tweets that contain vaccine related tweets with manually annotated sentiments (negative, neutral, positive). Negative sentiment is labeled as 1, neutral as 2, and positive as 3.
4.2Exploratory data analysis
Fig. 4 shows the wordcloud for positive and negative tweets of all three datasets used in this study. The size of the words depends on the popularity (frequency) of the words. Fig. 5 demonstrates the distribution of tweets across the datasets. The distribution demonstrated in Fig. 5 follows Zipf’s Law which was first presented by French stenographer Jean-Baptiste Estoup and later named after the American linguist George Kingsley Zipf. Zipf’s Law states that a small number of words are used all the time, while the vast majority are used very rarely. In addition, it is found that the frequency of any word is inversely proportional to its rank in the frequency table. Thus the most frequent word will occur approximately twice as often as the second most frequent word, three times as often as the third most frequent word, and so on. Mathematically, it can be expressed as the rth most frequent word has a frequency f (r) that scales according to
Fig. 4
Wordcloud of the COVID-19 twitter datasets. Top and bottom row show positive and negative tweets respectively.

Fig. 5
Tweet distribution across the datasets.
Fig. 6
Tweet distribution across the datasets.
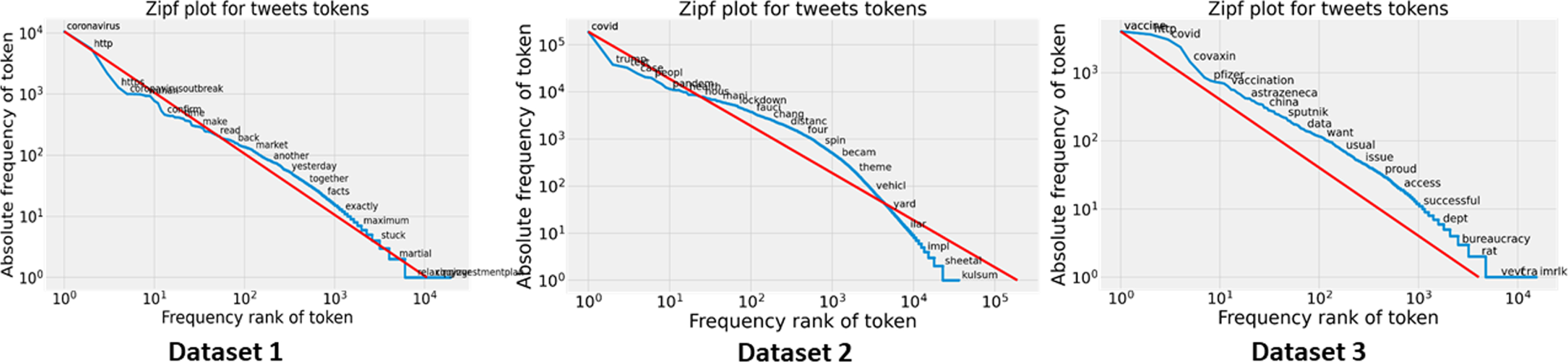
Fig. 7
Frequency of the COVID-19 twitter datasets. Top and bottom row show positive and negative tweets respectively.
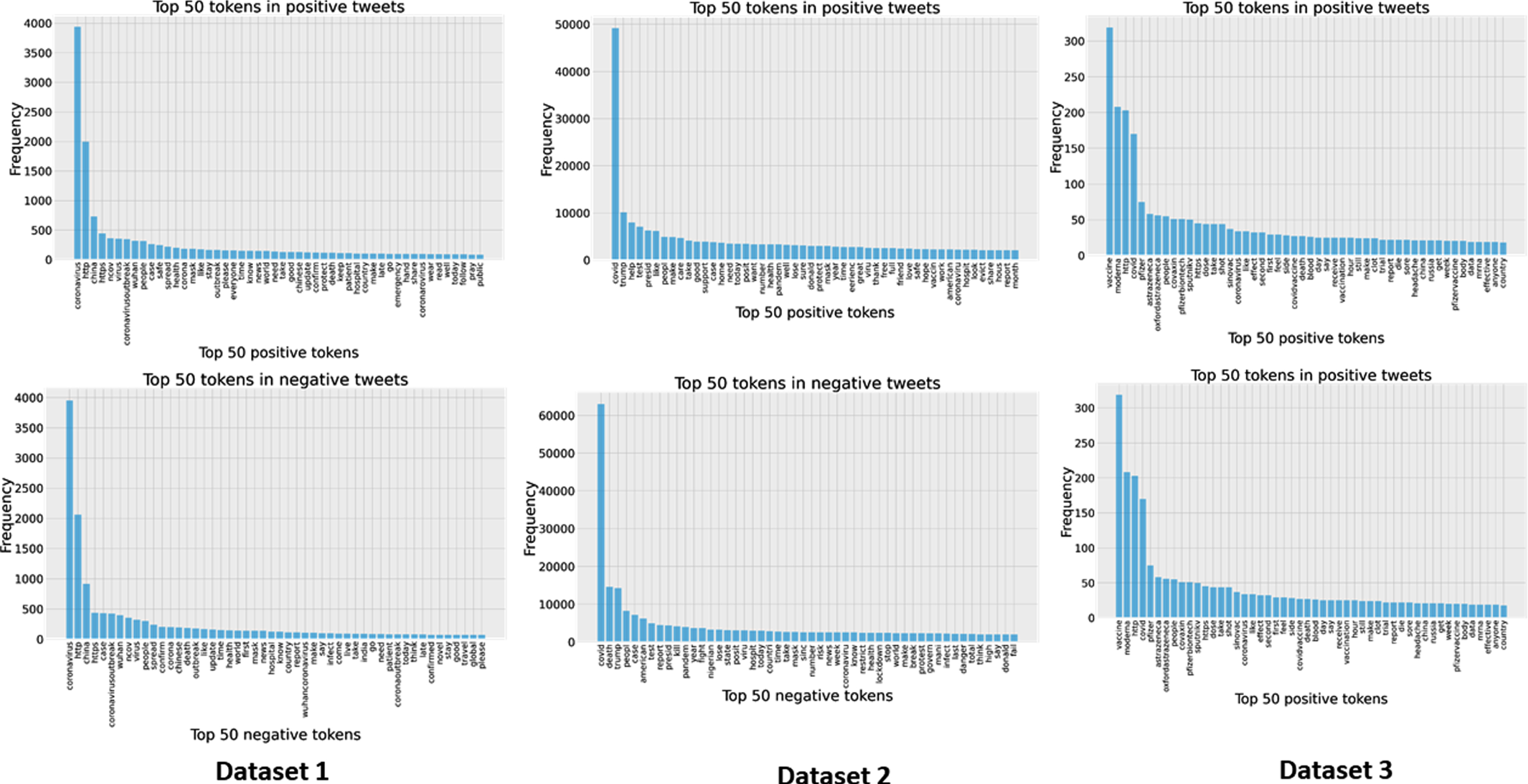
Fig. 8
Results of mutual information based text feature selection methods. Top and bottom row show fuzzy and text features respectively.
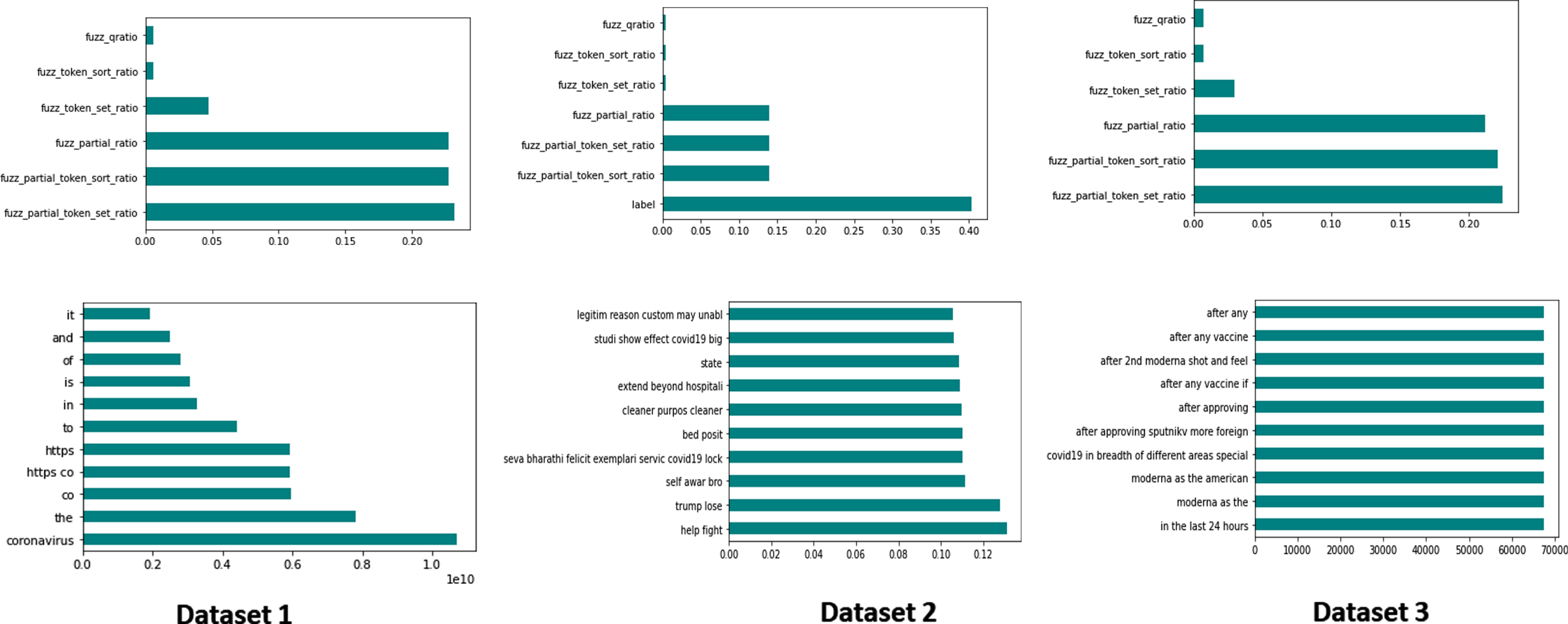
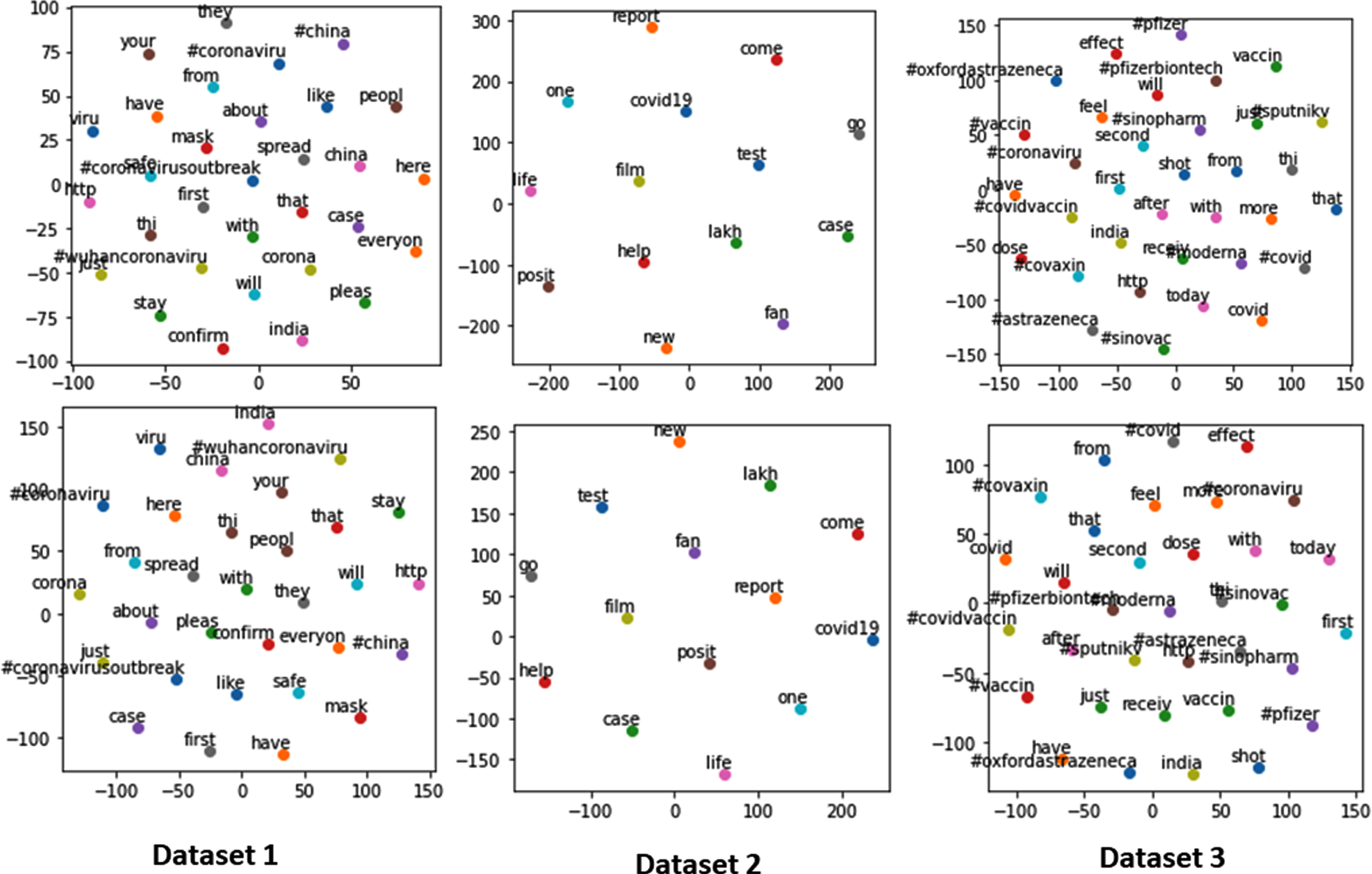
Fig. 9
Word2vec of the COVID-19 twitter datasets. Top and bottom row show Continous Bag Of Words (CBOW) and Skip-gram respectively.
4.3Results of N-Gram based text feature selection
A sample result of the text feature selection method for all three datasets are illustrated in Fig. 8. This figure shows that fuzzy partial ratio, fuzzy partial token sort ratio, and fuzzy partial token set ratio are the important features selected by the mutual information based feature selection methods for all three datasets. For N-gram feature (bottom row), the token "Coronavirus", "help fight", and "moderna as the" are manifested as important features for dataset 1, 2, and 3 respectively.
4.4Word vector representation
Fig. 9 illustrates the word vector representation in terms of Continuous Bag of Words (CBOW) and Skip-gram. CBOW model combines the distributed representations of context (or surrounding words) to predict the word in the middle. On the other hand, the Skip-gram model uses the distributed representation of the input word to predict the context.
4.5Comparison of different classifier algorithms
We wrote the code in python and experiments were conducted in google colab pro. For fair comparison, we used the same 70% and 30% of the dataset for training and testing for all classifiers and datasets. The input features for the classifiers mentioned in Table 1, and 2 are fuzzy features. Test accuracy for different fuzzy and Machine Learning (ML) classifiers as well as Convolutional Neural Network (CNN) are demonstrated in Table 1, 2, 3 respectively. Bottom row of each of the table shows the results of the fuzzy fusion of the classifiers mentioned in the corresponding table. Few important findings noted here are: (i) fuzzy fusion always obtains greater accuracy than base (individual) classifiers for fuzzy, ML, and convolutional neural networks; (ii) convolutional neural network shows greater accuracy for dataset 2 because of its large size (22,35,240 number of tweets); (iii) fuzzy fusion based unsupervised aggregation framework perform better than supervised ensemble methods (AdaBoost); and (iv) Only three fuzzy features are as efficient as large text feature sets (N-gram, word2vec, and fastText (word embedding)) for sentiment classification in terms of test accuracy.
Table 1
Accuracy of Different Fuzzy Classifiers
| Classifier Name | Dataset 1 | Dataset 2 | Dataset 3 |
| Fuzzy Min Max Classifier | 0.371 | 0.279 | 0.228 |
| Fuzzy Decision Tree Classifier | 0.392 | 0.554 | 0.605 |
| Fuzzy Support Vector Machine | 0.391 | 0.64 | 0.605 |
| Unsupervised Fuzzy Rule Based | 0.395 | 0.195 | 0.45 |
| FCNN | 0.466 | 0.293 | 0.3 |
| Fuzzy Fusion | 0.623 | 0.557 | 0.617 |
Table 2
Accuracy of Different Machine Learning Classifiers
| Classifier Name | Dataset 1 | Dataset 2 | Dataset 3 |
| KNeighborsClassifiers | 0.288 | 0.457 | 0.735 |
| Decision Tree Classifier | 0.394 | 0.554 | 0.736 |
| Random Forest Classifier | 0.392 | 0.554 | 0.736 |
| AdaBoost Classifier | 0.392 | 0.554 | 0.736 |
| Gaussian Nearest Neighbor Classifier | 0.299 | 0.554 | 0.503 |
| Fuzzy Fusion | 0.522 | 0.634 | 0.784 |
Table 3
Accuracy of Convolutional Neural Network
| Feature Name | Dataset 1 | Dataset 2 | Dataset 3 |
| N-gram (N=1..4) | 0.419 | 0.989 | 0.0.702 |
| Word2Vec | 0.431 | 0.395 | 0.635 |
| FastText | 0.515 | 0.422 | 0.638 |
| Fuzzy Fusion | 0.701 | 0.99 | 0.737 |
5Conclusion and future work
In this paper, a novel unified framework based on Sugeno integral for the prediction of Covid-19 tweets is presented. The main characteristic of this approach is the aggregation of information by means of a combination of supervised (individual classifiers) and non-supervised (Sugeno Integral) methodology. A variety of text and fuzzy features, machine and deep learning classifiers and their fuzzy variants are explored on three very challenging open large scale kaggle datasets. Results of extensive experiments illustrate that fuzzy based unified framework is superior to base classifiers. Given the success of our approach in this sentiment classification problem, we plan to implement in other areas such as image processing, bioinformatics, and signal processing.
References
[1] | https://www.kaggle.com/arunavakrchakraborty/covid19-twitter-dataset. last accessed: 31 July, (2021). |
[2] | https://www.kaggle.com/datasciencetool/covid19-vaccinetweets-with-sentiment-annotation. last accessed: 31 July, (2021). |
[3] | https://www.kaggle.com/imranzaman5202/covid19-sentiment-analysis. last accessed: 31 July, (2021). |
[4] | Abbaszadeh S. and Hüllermeier E. , Machine learning with the sugeno integral: The case of binary classification, (2020). |
[5] | Ahmad T. , Ashaari A. , Awang S.R. , Mamat S.S. , Mohamad W.M.W. , Ahmad Fuad A.A. and Hassan N. , Fuzzy auto catalytic analysis of covid-19 outbreak in malaysia, medRxiv, (2020). |
[6] | Alhumoud S. , Arabic sentiment analysis using deep learning for covid-19 twitter data, IJCSNS International Journal of Computer Science and Network Security 20: (9) ((2020) ), 132–138. |
[7] | Basha S.M. , Zhen-ning Y. , Rajput D. , Iyengar N.Ch.S.N. and Caytiles R.D. , Weighted fuzzy rule based sentiment prediction analysis on tweets, International Journal of Grid and Distributed Computing 10: ((2017) ), 41–54. |
[8] | Chakraborty K. , Bhatia S. , Bhattacharyya S. , Platos J. , Bag R. and Hassanien A.E. , Sentiment analysis of covid-19 tweets by deep learning classifiers— a study to show how popularity is affecting accuracy in social media, Applied Soft Computing 97: ((2020) ), 106754. |
[9] | Chintalapudi N. , Battineni G. and Amenta F. , Sentimental analysis of covid-19 tweets using deep learning models, Infectious Disease Reports 13: (2) ((2021) ), 329–339. |
[10] | Cresswell K. , Tahir A. , Sheikh Z. , Hussain Z. , Domínguez Hernández A. , Harrison E. , Williams R. , Sheikh A. and Hussain A. , Understanding public perceptions of covid-19 contact tracing apps: Artificial intelligence–enabled social media analysis, J Med Internet Res 23: (5) ((2021) ), e26618. |
[11] | Daoyuan Li J.K. , Bissyande T.F. and Traon Y.L. , Time series classification with discrete wavelet transformed data, International Journal of Software Engineering and Knowledge Engineering 26: ((2016) ). |
[12] | Davtalab R. , Parchami A. , Dezfoulian M.H. , Mansoorizadeh M. and Akhtar B. , M-fmcn: Modified fuzzy min-max classifier using compensatory neurons. 01 (2012). |
[13] | Du X. and Zare A. , Multiple instance choquet integral classifier fusion and regression for remote sensing applications, IEEE Transactions on Geoscience and Remote Sensing 57: (5) ((2019) ), 2741–2753. |
[14] | Efrilianda E.N.K.O.G. and Devi Ajeng D. , Analysis of twitter sentiment in covid-19 era using fuzzy logic method, Surya Hijau Manfaat 2: (1) ((2021) ), 1–5. |
[15] | Emadi M. and Rahgozar M. , Twitter sentiment analysis using fuzzy integral classifier fusion, Journal of Information Science 46: (2) ((2020) ), 226–242. |
[16] | Venkata Rao K. , Prasad Reddy P.V.G.D. , Appa Rao G. and Srinivas G. , A partial ratio and ratio based fuzzy-wuzzy procedure for characteristic mining of mathematical formulas from documents, ICTACT Journal on Soft Computing 8: ((2018) ), 1732. |
[17] | Ghani U. , Bajwa I.S. and Ashfaq A. , A fuzzy logic based intelligent system for measuring customer loyalty and decision making, Symmetry 10: (12) ((2018) ). |
[18] | Han F. , Zhang Z. , Zhang H. , Aoki T. and Ogasawara K. , Public perception of the covid-19 pandemic on chinese social networking service (weibo): Sentiment analysis and fuzzy-cmeans model, (2021). |
[19] | Haque A. and Rahman T. , Sentiment analysis by using fuzzy logic, International Journal of Computer Science, Engineering and Information Technology 4: ((2014) ), 33–48. |
[20] | Hastie T. , Tibshirani R. and Friedman J. , The Elements of Statistical Learning, Springer Series in Statistics. Springer New York Inc., New York, NY, USA, ((2001) ). |
[21] | Khalid Z. , Javed A.R. , Rizwan M. , Ghosh U. , Iwendi C. and Mahboob K. , Classification of covid-19 individuals using adaptive neuro-fuzzy inference system, International Journal of Scientific and Technology 15: ((2021) ). |
[22] | Jefferson C. , Liu H. and Haig E. , Fuzzy approach for sentiment analysis. (2017), 1–6. |
[23] | Jelodar H. , Wang Y. , Orji R. and Huang H. , Deep sentiment classification and topic discovery on novel coronavirus or covid-19 online discussions:Nlp using lstmrecurrent neural network approach, (2020). |
[24] | Meenakshisundaram Dr.K. and Uma K.K. , Optimization based fuzzy deep learning classification for sentiment analysis,, International Journal of Scientific and Technology 9: ((2020) ). |
[25] | Li Y. and Yang T. , Word embedding for understanding natural language: A survey. In: Srinivasan S. (eds) Guide to Big Data Applications. Studies in Big Data, 26:Springer, Cham., (2018). |
[26] | Lin C.-F. and Wang S.-D. , Fuzzy support vector machines, IEEE Transactions on Neural Networks 13: (2) ((2002) ), 464–471. |
[27] | Erritali M. , Bengourram J. and Madani Y. , A multilingual fuzzy approach for classifying twitter data using fuzzy logic and semantic similarity, Neural Computing and Applications 32: ((2020) ). |
[28] | Nguyen T.L. , Kavuri S. and Lee M. , A fuzzy convolutional neural network for text sentiment analysis, Journal of Intelligent & Fuzzy Systems 35: ((2018) ), 1–10. |
[29] | Valdez D. , ten Thij M. , Bathina K. , Rutter L.A. and Bollen J. , Social media insights into us mental health during the covid-19 pandemic: Longitudinal analysis of twitter data, J Med Internet Res 22: (12) ((2020) ), e21418. |
[30] | Vashishtha S. and Susan S. , Fuzzy logic based dynamic plotting of mood swings from tweets, Advances in Intelligent Systems and Computing 939: ((2019) ), 112834. |
[31] | Vashishtha S. and Susan S. , Fuzzy rule based unsupervised sentiment analysis from social media posts, Expert Systems with Applications 138: ((2019) ), 112834. |
[32] | Wang T. , Li Z. , Yan Y. and Chen H. , A survey of fuzzy decision tree classifier methodology, In B.-Y. Cao, editor, Fuzzy Information and Engineering, pages 959–968, Berlin, Heidelberg, (2007). Springer Berlin Heidelberg. |
[33] | Shamshirband S. , Asghar M.Z. , Ullah I. , Habib A. , Wang Y. and Subhan F. , Fuzzybased sentiment analysis system for analyzing student feedback and satisfaction, Computers, Materials & Continua 62: (2) ((2020) ), 631–655. |


