
Deep deductive reasoning is a hard deep learning problem
Abstract
Deep Deductive Reasoning refers to the training and then executing of deep learning systems to perform deductive reasoning in the sense of formal, mathematical logic. We discuss why this is an interesting and relevant problem to study, and explore how hard it is as a deep learning problem. In particular, we present some of the progress made on this topic in recent years, understand some of the theoretical limitations that can be assessed from existing literature, and discuss negative results we have obtained regarding improving on the state of the art.
1.Introduction
Deductive reasoning over formal logics is arguably the central computational task in symbolic Artificial Intelligence (AI) [9]. A given formal logic usually carries a formal semantics that is often model-theoretic and as such defines in mathematically precise terms the notion of logical consequence. In symbolic form, given a logical theory K (in symbolic AI – more precisely in the subfield of Knowledge Representation – often called a knowledge base, i.e., a set of logical formulas over the formal logic), we write
An important aspect of Knowledge Representation (KR) research is to find correct and scalable algorithms for deductive reasoning over KR-relevant logics. However, the mathematical definitions often do not easily translate into algorithms. Indeed, algorithms for more expressive logics tend to be so involved that they often need correctness proofs. Furthermore, they tend to be of high computational complexity, if the problem of computing logical consequences is at all decidable. Indeed, some prominent logics, such as first-order predicate logic, are not decidable but only semi-decidable, and some higher-order logics, including some non-monotonic logics of importance to KR, are not even semi-decidable [12]. Among the decidable logics are many from the Description Logics family [4] that are relevant for KR-based data management, and some of which have become W3C standards for the Semantic Web research field [20]. Their complexities can be very high, e.g., the OWL 2 DL standard is based on the Description Logic
Deep Deductive Reasoning (DDR) [14] refers to the training and then executing of deep learning (DL) systems to perform deductive reasoning. There are several reasons why the study of DDR is a worthwhile undertaking. Fundamentally, DDR presents us with a set of related problems of differing difficulty, at scales that can be chosen arbitrarily, and with mostly easy-to-obtain training data, and thus makes it possible to explore the capabilities and limitations of DL in what is similar to a controlled laboratory setting. A different perspective on the problem is motivated from a cognitive science viewpoint, in that KR and DL can be understood as simple formal abstractions of cognition, respectively, the human brain: And while we humans are capable of performing deductive reasoning, we would like to understand if and how this can be done with DL systems. A third perspective is more applied: DDR, if it could be made to work with high accuracy and at scale, may lead to improvements over conventional deductive reasoning algorithms through better tolerance of errors and noise in the data (which conventional algorithms do not handle well) and to improved reasoning speed (in the light of high computational complexities). At the same time, capturing deductive reasoning in DL systems opens avenues for neurosymbolic architectures that truly combine learning and reasoning, without the need to recourse to hybrid architectures.
The rest of the paper is organized as follows. In Section 2, we will give a brief overview of existing DDR research. In Section 3 we will discuss theoretical limitations on DDR that can be derived from the literature. In Section 4 we report on some of our failed attempts to improve DDR, which we include to emphasize how difficult the problem is, and in order to aid other researchers by reporting on paths that appear to be dead ends. In Section 5 we conclude.
2.Brief literature review
There are a number of particularly important features when assessing DDR approaches and systems:
– The specific logic that is being reasoned over, and in some cases also the reasoning task, as different reasoning tasks have differing complexities for some logics. For example, in logic programming [24], often only the derivation of logical consequences that are ground facts (and not complex formulas) is important. Computational complexities of the reasoning tasks provide a first indicator how difficult reasoning over the logic is. A less formal notion than complexity is expressivity of a logic: A more expressive logic makes it easier for a human to encode complex problems in them. For example, RDFS and
– In order to do DDR, the deductive reasoning problem needs to be transformed into a problem suitable for DL. There appear to be two different principled ways to do this. The first is to phrase DDR as a classification problem: Given a knowledge base K and a logical formula F, determine whether or not
– In deductive reasoning, the names of identifiers (constants, predicates, etc.) are insubstantial in that a consistent renaming within a knowledge base does not change the deductive reasoning results or procedures. Symbolic algorithms are likewise independent of identifier names. Ideally, DDR systems would have the same capability, i.e., to transfer to inputs over new and previously unseen vocabularies.
– Scalability is another important aspect and has at least three distinct variants:
∗ Scalability in terms of input size. Application oriented knowledge bases sometimes have hundreds, and sometimes millions or even billions of logical statements. For DDR systems, it is important to note what input sizes can be ingested so that accuracy is still high.
∗ Scalability in terms of training time needed, which of course is related to the input sizes considered.
∗ Scalability in terms of the runtime of the trained DDR system.
– Finally, accuracy of a DDR system is of importance, and it is probably best assessed in terms of precision, recall, and f-measure values by taking a symbolic reasoner as basis for ground truth.
Table 1
Comparison of DDR approaches
| Method | Logic | Generative | Transferable | Scalability | Training time | Testing time | Accuracy |
| [19] | RDF | No | No | Moderate | ≈60 min | <1 ms | Accuracy of 87–99% |
| [53] | RDF | Yes | No | Moderate | N/A | N/A | F1-score of 0.03–1 |
| [36] | RDFS | Yes | No | Low | ≈12 min | N/A | Accuracy of ≈100% |
| [35] | RDFS | Yes | No | Low | N/A | N/A | Accuracy of 95% |
| [16] | RDFS | No | Yes | Moderate | N/A | N/A | Accuracy of 52–96% |
| [44] | ASP | Yes | No | Very low | N/A | N/A | N/A |
| [13] | Yes | No | Moderate | N/A | N/A | Somewhat better than guessing | |
| [41] | No | No | High | N/A | N/A | Hits at rank 1 ≈0.06 | |
| [27] | OWL 2 RL | No | No | Low | N/A | N/A | Accuracy of 99% |
| [1] | No | No | Moderate | <27 min | N/A | Accuracy of ≈97% | |
| [54] | OWL DL | Yes | No | High | N/A | <355 s | F1-score of ≈0.95 |
| [8] | FOL | Yes | No | Very low | ≈20 sec | N/A | Precision of 0.7 |
We note, in particular, that none of the current systems is both generative and able to transfer. Furthermore, scalability is generally below many requirements in practice. The exception may be [54] – however this system makes use of only small TBoxes (which are the actual logical axioms), i.e., only the ABox (essentially, the non-axiom facts) is large.
While it is not our focus herein, we would like to mention that some studies have focused on investigating reasoning within propositional logic. For instance, in [47] efforts were made to fine-tune GPT-2 and GPT-3 to emulate resolution rules applicable to propositional logic programs, and in [18] the issue of entailment within propositional logic is addressed.
Also related is research in automated theorem proving involving DL, which can be categorized into two main groups. Firstly, there are hybrid approaches that combine neural network encodings with conventional deduction methods [28,29,34]. Secondly, there exist fully deep learning-based models such as the one proposed by [45], which presents a DNN architecture customized for automated proof synthesis, estimating the probability of applying an inference rule at each step of the proof. Additionally, in [10,46], a graph neural network-based model is proposed for the classification and resolution of SAT problems.
OVerall it seems fair to say that, at present, research results do not yet meet realistic application requirements, in particular for KR applications.
3.Theoretical limitations
Deductive reasoning problems have a long history as complete problems for complexity classes, and those in knowledge representation tend to possess high complexity. Therefore it is natural to think that DDR is subject to severe theoretical limitations, but is this true?
Deep learning can be studied through several abstract models. The most direct and literal is the analytic model (see e.g., [6,52]), in which neural networks are a class of functions of real variables, studied in terms of approximation, convergence, etc., with computational considerations kept to a minimum. An advantage of this point of view is its ability to see specifics of different architectures that would be washed out in other models, letting us more often compare predictions against empirical results. However, it is not well suited to study hardness in absolute terms: typically one can prove facts such as rapid convergence-in-probability of stochastic gradient descent, or lack thereof, but this only concerns the performance of one algorithm (e.g., stochastic gradient descent) at a time.
The other obvious model is boolean circuit computation [50]. We represent neural networks as discrete functions acting on boolean vectors, and so all considerations are quite different. Typically some proxy such as “majority threshold circuits of constant depth” (
The circuit model is more germane to the study of DDR, because deductive reasoning problems are discrete, but there is another issue that bears mentioning. Whereas a Turing machine has a finite number of states, a circuit family, with enough circuits to process inputs of any length, is an infinite one [51] because a different circuit is required for each input length. It is thus possible to decide some nonrecursive languages with circuits. This feature, called “nonuniformity”, is a plague on lower-bound proofs; proving problems too hard for circuits is generally harder than proving them too hard for Turing machines with similar resource bounds. We do not understand whether this reflects a significant phenomenon or just a gap in our knowledge.
When a decision (classification) problem is not in a nonuniform complexity class, such as
We have neglected the issue that deep learning is inherently random and fuzzy. Since most known facts about hardness of logic concern exact decision problems, with no provision for error, the easiest type of limitations to prove are those of exactly-correct networks. These results mostly just confirm the intuition that deep learning has to be random or fuzzy. Sometimes, though, results do generalize to the fuzzy case. Suppose we want to train, in polynomial time and from a polynomial amount of data, a network that does
For deep learning in general, one might argue that we do not have a computational model for the knowledge in a dataset of arbitrary real-world examples because thinking about the example generator as a Turing machine is misleading – we do not know whether the universe can be modeled as a Turing machine.1111 Even for DDR, perhaps the bottleneck really is just the uninsightful ways we can automatically generate ground truth, and if we trained on example deductions made by human experts we could do better.1212 If this is so, then perhaps we ought to model neural networks as if training data is arbitrary. This approximation made, the only circuit-based limits to their power are non-uniform ones, but there is now no possibility of stochastic models performing better than exact ones, since randomness and error tolerance give no advantage to nonuniform computers.1313 It is almost trivial to prove that 2EXPTIME-hard problems do not have polynomial-size circuits. So
Weaker logics provide more interesting problems. It is widely conjectured, though hard to prove (it implies P ≠ NP), that NP-hard problems do not have polynomial-size circuits. If this is the case, then regardless of our assumptions about training, no neural architecture whose operation, once trained, involves a polynomial number of calculations can solve the SAT problem for Boolean formulas, which are vastly less expressive than e.g.,
One pertinent compromise model between uniform and nonuniform is exact learning [2,30], in which circuits are constructed by a Turing machine with query access to the target function, and an oracle that can provide counterexamples for incorrect circuits. From an AI perspective, this corresponds to active learning with ideal data available but limited computational resources. Klivans, Kothari, and Oliveira show [32, Theorem 8] implies1414 that if there exists an algorithm to exact-learn all functions learnable by a particular class of circuits (i.e., an “architecture”) in polynomially many queries, then there are functions computable in almost polynomial time1515 that cannot be represented by this architecture. The takeaway from this is that, insofar as exact learning is a good abstraction, there is a tradeoff between the generalization capacity of an architecture and guarantees of efficient learning, and many deductive reasoning problems are hard enough to bring this tradeoff into play.
Overall, the verdict of theory (as of the time of writing) is that the limitations of deep learning for logic problems are not well understood. Since these problems occur at many levels of the complexity hierarchy, they provide an interesting bellwether for the hardness of deep learning in general. Indeed, all the results we have been able to cite above have been excessively general; if there is something particularly challenging for practical neural systems about reasoning, as compared to other computationally hard tasks, this remains to be explained by future research.
4.Practical hardness
In principle, DDR should represent a deep learning problem that is readily investigated. Using symbolic reasoners it is straightforward to produce vast amounts of training data algorithmically. Given the promises of deep learning as a cure-all for all manner of complex problems, it should be expected that, at least for simple logics, solutions for DDR should be findable without too much hassle. It turns out that this is not the case at all, even when staying within the bounds of the theoretical limitations discussed above. In this section, we report on two of our investigations, and their (relative) failures. Given the frequent emphasis in published research on positive results, we take this opportunity to discuss negative results, i.e., failure to solve DDR in some settings.
4.1.LSTMs for EL +
We briefly discuss the investigation reported in detail in [13] regarding the use of LSTMs for
It was our intention to avoid, as much as possible, embeddings or any distance adjustments that might help the system learn answers based on embedding similarity without first learning the reasoning structure.1616 In fact, a primary feature of our network is its lack of complexity. We take a very simple logic, reason over knowledge bases in that logic, and then extract so-called supports from the reasoning steps, mapping the reasoner supports back to sets of the original knowledge base axioms. This allows us to encode the input data in terms of only knowledge base statements. Essentially, such a support consists, for each reasoning step in a symbolic reasoner, of the set of axioms (in the original knowledge base) that allow to draw the inferences for this reasoning step.1717 Support also provides an intermediate answer that might improve results when provided to the system. We experimented with three different LSTM architectures with identical input and output dimensionalities. One architecture, which we call “Deep”, does not train with support data but has a hidden layer the same size as the supports we have defined. Another architecture, called “Piecewise”, trains two separate half-systems, one with knowledge bases and one with supports from the reasoner.1818 The last system, called “Flat”, simply learns to map inputs directly to outputs for each reasoning step. We will discuss in detail each part of the system in the following sections, then provide some results.
LSTMs are a type of recurrent neural network that work well with data that has long-term dependencies [26]. We choose to use an LSTM to learn the reasoning patterns of
Fig. 1.
Piecewise architecture (top); deep architecture (middle); flat architecture (bottom).
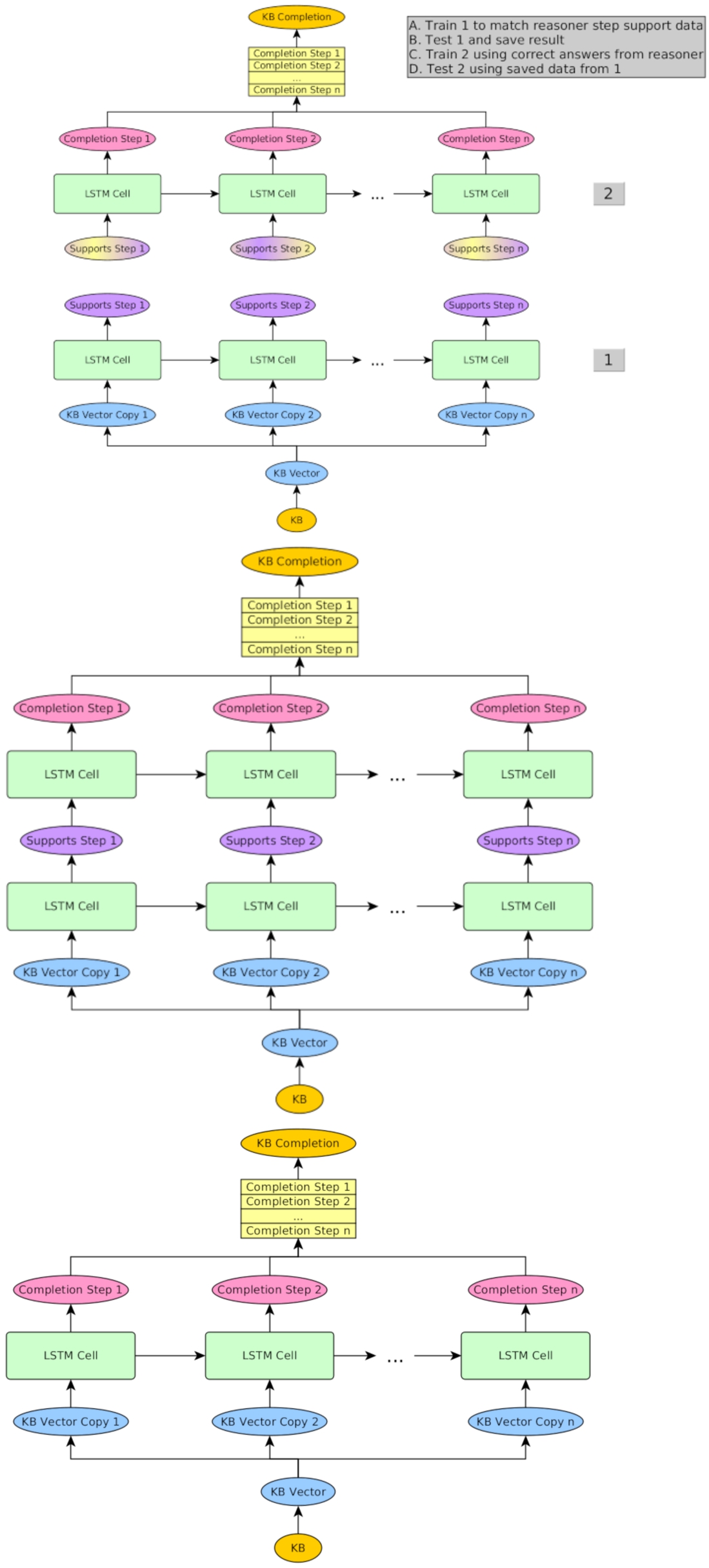
We would like to emphasize the distinction between our method, which we prefer to call an encoding, and a traditional embedding. Our encoding adds no additional information to the names beyond the transformation from integer to scaled floating point number. (It can be directly reversed with a slight loss of precision due to integer conversion.) The semantics of each encoded predicate name with regards to its respective knowledge base is structural in relation to its position in the 4-tuple (just like it would be in an
Every data set we use has a fixed number of names that it can contain for both roles and concepts, and every concept or role has an arbitrary number of name identifiers. Identifier labels are stripped and the concept and role numbers are shuffled around and substituted with random integers to remove any possibility of the names injecting a learning bias. These labels are remembered for later retrieval for output but the LSTMs do not see them. Knowledge bases have a maximum number of role and concept names that are used to scale all of the integer values for names into a range of
To input knowledge bases into the LSTM, we first apply the encoding defined in the previous section to each of its statements then concatenate each of these encodings end-to-end to obtain a much longer vector. For instance,
Table 2
Translation rules: c = number of possible concept names r = number of possible role names
| KB statement | Vectorization | |
| CX ⊑ CY | → | |
| CX ⊓ CY ⊑ CZ | → | |
| CX ⊑ ∃RY.CZ | → | |
| ∃RX.CY ⊑ CZ | → | |
| RX ⊑ RY | → | |
| RX ∘ RY ⊑ RZ | → |
As already mentioned (and we will not replicate the results tables from [13]), our attempts failed in so far as we only managed to do a little bit better than a random guesser. Of course this does not mean that the problem is not solvable, but it appears that a-priori reasonable set-ups do not readily solve it.
4.2.Pointer networks for generative RDFS reasoning
Artificial Neural Networks (ANNs) have been in use to learn sequence-to-sequence problems for a long time. Particularly, Recurrent Neural Networks (RNNs) have achieved state-of-the-art performance in mapping such problems. One key point in such applications is that the dimensions of the output dictionary must be known beforehand. In combinatorial problems such as the Travelling Salesman Problem (or for generative DDR), each input sequence may have any number of entities. In addition, the size of the output dictionary depends on the input sequence (i.e., not only on its length). This creates a distinction with the general settings of sequence-to-sequence problems.
To understand the task of (generative) DDR, we shall look at it through the lens of RDF, or more precisely RDFS [23]. It is a logic where each statement consists of a triple
Pointer Networks, introduced by Vinyals, Fortunato, and Jaitly [49] learn the conditional probability of an output sequence. Each token in the output sequence points to an item in the input sequence. It uses attention to point to a token of the input sequence as part of the probable output sequence. In combinatorial optimization problems such as TSP, Convex-hull, and Delaunay Triangulations, the authors show that the Pointer Network achieves state-of-the-art performance, and therefore seems to be a natural choice to explore generative DDR in this case. Since in RDFS reasoning, the input triples define the different node-edge-node sections of a graph, and the output of the reasoning entails establish previously undefined relationships among nodes using information already provided in the input – Pointer Networks becomes a candidate architecture because its general working principle involves pointing to input tokens as output tokens. This has prompted the study reported in [15] with positive initial results. However, as we are reporting in more detail below, these results do not appear to stand up to additional scrutiny.1919
A Pointer Network has an encoder-decoder based architecture with attention mechanism that uses position of tokens in the input sequence to represent the output tokens. In a sample input sequence, positions of different tokens are encoded, while during decoding – the output sequence obtains a part of the input tokens expressed by their respective positions. For more implementation details we refer the reader to [49]. The completion of a graph T is denoted
Using Apache Jena API and an RDF dataset containing approximately 16K graphs to generate the corresponding inferences for each graph to supervise the model. The dataset is split into 60% training, 20% validation, and 20% test. The dataset is first encoded on the URI level, where a dictionary is created with all the unique URIs. Thereafter, the encoded graphs and inferences are fed to train the model. We have tested with different learning rates between 0.001 and 0.1, maximum length of a graph between 200 and 700. (We have also experimented with encoding the dataset on the token level where each token in the URIs is encoded, but then the produced output sequences contained a large number of invalid URIs where tokens from different URIs are combined.)
To evaluate the approach, a metric needs to be calculated on a triple level instead of the URI level because a correct prediction needs to have all URIs to be valid to compose a correct triple. In other words, a partial true prediction for a triple does not count towards a right prediction. In our analysis we have found that Pointer Network’s capability of producing correct triples is very limited. It resulted in less than 10% accuracy in terms of predicting triples. Unsurprisingly, we have found Precision and Recall to be insignificant as well. Given these negative findings, we also returned to our initial study reported in [15] which showed better results, but these were not on the triple level, but on the token level, and it appears that token padding (to arrive at same-length inputs) played a major role and the results simply did not hold on the triple level. However, any fit-for-purpose ANN-based model must learn the underlying relationships between subjects and objects of a triple when trying to perform deep deductive reasoning.
For instance, in the case of transitive property, where entities A and B have a relation, then B and C have the same relation, the model should be able to understand that A and C have the same relation. However, it should learn this property in a symbol-invariant fashion. Concretely, if the same property is fed into the model with a different set of symbols, ideally the model should be able to identify it too. Our speculation for the Pointer Network failing to perform well is that the model is trying to learn the relationship between symbols, which is rather a difficult job. Consequently, it fails to remember what it has seen before. We believe the Pointer Network approach works on the Travelling Salesman Problem because there is only one relationship to consider amongst all nodes (cities) and the number of considered cities is small. However, in case of DDR, the number of nodes (subjects and objects) is naturally rather large. To make things even more difficult, in DDR there are as many relations to consider as the number of RDFS rules in play, and it appears that the Pointer Network fails to grasp the relationships due to their number being large compared to the overall input size. Finally, due to the fact that it is trying to learn the relationship between “symbols”, it fails to remember what it has seen before. This is important because, in RDFS graphs, the order of triples do not matter. In the transitive property example, after the model sees the first part of a transitive property, if the second part comes after a few triples, the model fails to connect the two parts.
5.Conclusions
We have presented the state of the art in DDR, discussed theoretical limitations, and argued that (even within the theoretical limits) it is a hard deep learning problem in practice based on our own prior experiences.
For the theoretical limitations, we have shown that very expressive logics are out of bounds (with 100% accuracy), and even NP-complete ones may be out of bounds (depending on how the P vs. NP problem will be addressable eventually). Of course, this does not mean that investigating DDR for NP-complete or harder logics should not be done, but it does mean that any DDR system for such logics will always be approximate; however it can of course still be useful [25,43].
In terms of practical hardness, we note that there is currently no well-performing system even for the comparatively simple polynomial logic
As for practical usefulness, it should be mentioned that RDFS is a prominent logic in the context of Knowledge Graphs, Ontologies, and the Semantic Web [20], and that a generative system capable of transfer and scalability up to non-trivial input sizes with high accuracy (say, even inputs of about
Deep Deductive Reasoning at scale, and with logics more expressive than RDFS, would of course open up many more opportunities by providing a path to a deep integration of symbolic formal logical reasoning within deep learning systems [3] – in contrast to approaches that use deep learning and separate symbolic reasoners in more of a hybrid systems fashion requiring clearly defined interactions between the separate components (e.g., [37]), and corresponding mapping between vector and symbolic components.
As such, DDR remains a highly interesting area of research, where practical applications seem within grasp. However we have also seen that the right approaches have not been found yet. To advance, it requires new ideas, and investigations on a broad front, with many different deep learning architectures and approaches.
Notes
1 which is nondeterministic double exponential, i.e., nondeterministic
2 Propositional reasoning can in fact be represented exactly using artificial neural networks, see, e.g., [22,38].
3 Most, but not all, of DDR work for KR-relevant logics has been done on logics relevant to Semantic Web [23].
4 There are exceptions. Some neural architectures, e.g., recurrent, can feed variable-length inputs to a single network [42]; we can easily represent its different “length modes” as different circuits, but this makes “constant depth” implausible and introduces uniformity (see below). Constant-depth may also be implausible for convolutional networks. Recognizing objects in images generally requires more down-sampling layers for higher resolution, i.e., at least logarithmically more layers for larger inputs. The class of languages accepted by logarithmically-deep threshold circuits is called
7 Though it may have something unintuitively in common; sometimes trained networks “organize” in a planned-looking way [17].
8 in the network input width and in the amount of training data.
9 We mean that, for some ϵ, for every input x, if we train a fresh network, it will accept x with probability at least
10 This is because we can use random bits to train a network, then simulate it on the input, and the result is a polynomial-time stochastic algorithm that is correct if given the right training data, but whenever such an algorithm exists there is also a deterministic polynomial-space algorithm [33], which we can pipeline with the data-generator.
11 e.g., because the Turing machine in question would be so intricate that its size is not negligible compared to our inputs, which calls into question the whole framework of “asymptotic resource use in terms of input size”.
12 This is an idealization, because human experts only work up to a certain input size, but they can solve many reasoning problems not captured by any known decidable logics.
13
14 see the abstract for this claim.
15
16 We just don’t see how pre-compiled embeddings would be helpful for deep deductive reasoning if reasoning should transfer in the sense discussed in Section 2: To have embeddings reflect similarity relevant for transferable deductive reasoning would have to capture similarity in some sense conveyed by the input theory, which is not known before runtime, i.e., which is in particular not available for training embeddings.
17 As such, support is dependent on the symbolic reasoning algorithms chosen, and we used the most basic one [23].
18 I.e., the system learns to produce support, and then learns to create output from both support and input knowledge base.
19 On a related note, this serves to show that preprints that have not been peer reviewed always need to be taken with caution.
Acknowledgement
The authors acknowledge partial funding by the National Science Foundation under grants 2033521 KnowWhereGraph, 2119753 BioWRAP and 2333532 EduGate.
References
[1] | D.M. Adamski and J. Potoniec, Reasonable embeddings: Learning concept embeddings with a transferable neural reasoner, Semantic Web ((2023) ). doi:10.3233/SW-233355. |
[2] | D. Angluin, Queries and concept learning, Machine Learning 2: ((1988) ), 319–342. |
[3] | S. Artemov, H. Barringer, A. d’Avila Garcez, L.C. Lamb and J. Woods, We Will Show Them in Honour of Dov Gabbay, Vol. 2: , (2005) , pp. 167–194. |
[4] | F. Baader, D. Calvanese, D.L. McGuinness, D. Nardi and P.F. Patel-Schneider (eds), The Description Logic Handbook: Theory, Implementation, and Applications, 2nd edn, Cambridge University Press, (2007) . |
[5] | S. Bader, P. Hitzler, S. Hölldobler and A. Witzel, A fully connectionist model generator for covered first-order logic programs, in: IJCAI 2007, Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, January 6–12, 2007, M.M. Veloso, ed., (2007) , pp. 666–671, http://ijcai.org/Proceedings/07/Papers/106.pdf. |
[6] | J. Berner, P. Grohs, G. Kutyniok and P. Petersen, The modern mathematics of deep learning, in: Mathematical Aspects of Deep Learning, P. Grohs and G. Kutyniok, eds, Cambridge University Press, (2022) , pp. 1–111. |
[7] | T.R. Besold, A.S. d’Avila Garcez, S. Bader, H. Bowman, P.M. Domingos, P. Hitzler, K. Kühnberger, L.C. Lamb, P.M.V. Lima, L. de Penning, G. Pinkas, H. Poon and G. Zaverucha, Neural-symbolic learning and reasoning: A survey and interpretation, in: Neuro-Symbolic Artificial Intelligence: The State of the Art, P. Hitzler and M.K. Sarker, eds, Frontiers in Artificial Intelligence and Applications, Vol. 342: , IOS Press, (2021) , pp. 1–51. doi:10.3233/FAIA210348. |
[8] | F. Bianchi and P. Hitzler, On the capabilities of logic tensor networks for deductive reasoning, in: Proceedings of the AAAI Spring Symposium on Combining Machine Learning with Knowledge Engineering (AAAI-MAKE), A. Martin, K. Hinkelmann, A. Gerber, D. Lenat, F. van Harmelen and P. Clark, eds, CEUR Workshop Proceedings, Vol. 2350: , CEUR-WS.org, (2019) . |
[9] | R.J. Brachman and H.J. Levesque, Knowledge Representation and Reasoning, Elsevier, (2004) . ISBN 978-1-55860-932-7. |
[10] | B. Bünz and M. Lamm, Graph neural networks and boolean satisfiability, (2017) , arXiv preprint arXiv:1702.03592. |
[11] | R. Chen, V. Kabanets and J. Kinne, Lower bounds against weakly-uniform threshold circuits, Algorithmica 70: (1) ((2014) ), 47–75. doi:10.1007/s00453-013-9823-y. |
[12] | E. Dantsin, T. Eiter, G. Gottlob and A. Voronkov, Complexity and expressive power of logic programming, ACM Comput. Surv. 33: (3) ((2001) ), 374–425. doi:10.1145/502807.502810. |
[13] | A. Eberhart, M. Ebrahimi, L. Zhou, C. Shimizu and P. Hitzler, Completion reasoning emulation for the description logic EL+, in: AAAI Spring Symposium on Combining Machine Learning and Knowledge Engineering in Practice (AAAI-MAKE) Volume I, A. Martin, K. Hinkelmann, H. Fill, A. Gerber, D. Lenat, R. Stolle and F. van Harmelen, eds, CEUR Workshop Proceedings, Vol. 2600: , CEUR-WS.org, (2020) . |
[14] | M. Ebrahimi, A. Eberhart, F. Bianchi and P. Hitzler, Towards bridging the neuro-symbolic gap: Deep deductive reasoners, Appl. Intell. 51: (9) ((2021) ), 6326–6348. doi:10.1007/s10489-020-02165-6. |
[15] | M. Ebrahimi, A. Eberhart and P. Hitzler, On the capabilities of pointer networks for deep deductive reasoning, CoRR, (2021) , arXiv:2106.09225. |
[16] | M. Ebrahimi, M.K. Sarker, F. Bianchi, N. Xie, A. Eberhart, D. Doran, H. Kim and P. Hitzler, Neuro-symbolic deductive reasoning for cross-knowledge graph entailment, in: AAAI Spring Symposium: Combining Machine Learning with Knowledge Engineering, (2021) . |
[17] | D. Erhan, Y. Bengio, A. Courville and P. Vincent, Visualizing higher-layer features of a deep network, Technical Report, Université de Montréal, (2009) . |
[18] | R. Evans, D. Saxton, D. Amos, P. Kohli and E. Grefenstette, Can neural networks understand logical entailment? (2018) , arXiv preprint arXiv:1802.08535. |
[19] | R. Ferreira, C. Lopes, R. Gonçalves, M. Knorr, L. Krippahl and J. Leite, Deep neural networks for approximating stream reasoning with C-SPARQL, in: Progress in Artificial Intelligence: 20th EPIA Conference on Artificial Intelligence, EPIA 2021, Virtual Event, September 7–9, 2021, Proceedings, Vol. 20: , Springer, (2021) , pp. 338–350. doi:10.1007/978-3-030-86230-5_27. |
[20] | P. Hitzler, A review of the Semantic Web field, Commun. ACM 64: (2) ((2021) ), 76–83. doi:10.1145/3397512. |
[21] | P. Hitzler, F. Bianchi, M. Ebrahimi and M.K. Sarker, Neural-symbolic integration and the Semantic Web, Semantic Web (Preprint) ((2019) ), 1–9. |
[22] | P. Hitzler, S. Hölldobler and A.K. Seda, Logic programs and connectionist networks, Journal of Applied Logic 2: (3) ((2004) ), 245–272. doi:10.1016/j.jal.2004.03.002. |
[23] | P. Hitzler, M. Krötzsch and S. Rudolph, Foundations of Semantic Web Technologies, Chapman and Hall/CRC Press, (2010) . |
[24] | P. Hitzler and A.K. Seda, Mathematical Aspects of Logic Programming Semantics, Studies in Informatics, Chapman and Hall/CRC Press, (2011) . |
[25] | P. Hitzler and F. van Harmelen, A reasonable Semantic Web, Semantic Web 1: (1–2) ((2010) ), 39–44. doi:10.3233/SW-2010-0010. |
[26] | S. Hochreiter and J. Schmidhuber, LSTM can solve hard long time lag problems, in: Advances in Neural Information Processing Systems, (1997) , pp. 473–479. |
[27] | P. Hohenecker and T. Lukasiewicz, Ontology reasoning with deep neural networks, Journal of Artificial Intelligence Research 68: ((2020) ), 503–540. doi:10.1613/jair.1.11661. |
[28] | G. Irving, C. Szegedy, A.A. Alemi, N. Eén, F. Chollet and J. Urban, Deepmath-deep sequence models for premise selection, Advances in neural information processing systems 29: ((2016) ). |
[29] | C. Kaliszyk, F. Chollet and C. Szegedy, Holstep: A machine learning dataset for higher-order logic theorem proving, (2017) , arXiv preprint arXiv:1703.00426. |
[30] | A. Kawachi, Circuit lower bounds from learning-theoretic approaches, Theoretical Computer Science 733: ((2018) ). doi:10.1016/j.tcs.2018.04.038. |
[31] | Y. Kazakov, M. Krötzsch and F. Simančík, ELK: A reasoner for OWL EL ontologies, System Description, (2012) . |
[32] | A.R. Klivans, P. Kothari and I.C. Oliveira, Constructing hard functions from learning algorithms, Electron. Colloquium Comput. Complex. TR13: ((2013) ). |
[33] | C. Lautemann, BPP and the polynomial hierarchy, Inf. Process. Lett. 17: ((1983) ), 215–217. doi:10.1016/0020-0190(83)90044-3. |
[34] | S. Loos, G. Irving, C. Szegedy and C. Kaliszyk, Deep network guided proof search, (2017) , arXiv preprint arXiv:1701.06972. |
[35] | B. Makni, I. Abdelaziz and J. Hendler, Explainable deep RDFS reasoner, (2020) , arXiv preprint arXiv:2002.03514. |
[36] | B. Makni and J. Hendler, Deep learning for noise-tolerant RDFS reasoning, Semantic Web 10: (5) ((2019) ), 823–862. doi:10.3233/SW-190363. |
[37] | R. Manhaeve, G. Marra, T. Demeester, S. Dumancic, A. Kimmig and L.D. Raedt, Neuro-symbolic AI = neural + logical + probabilistic AI, in: Neuro-Symbolic Artificial Intelligence: The State of the Art, P. Hitzler and M.K. Sarker, eds, Frontiers in Artificial Intelligence and Applications, Vol. 342: , IOS Press, (2021) , pp. 173–191. doi:10.3233/FAIA210354. |
[38] | W.S. McCulloch and W.H. Pitts, A logical calculus of the ideas immanent in nervous activity, in: The Philosophy of Artificial Intelligence, M.A. Boden, ed., Oxford Readings in Philosophy, Oxford University Press, (1990) , pp. 22–39. |
[39] | A. Meier, Generalized complexity of ALC subsumption, CoRR, (2012) , arXiv:1205.0722. |
[40] | B. Mohapatra, S. Bhatia, R. Mutharaju and G. Srinivasaraghavan, EmELvar: A NeuroSymbolic reasoner for the EL++ description logic, in: Proceedings of the Semantic Reasoning Evaluation Challenge (SemREC 2021) Co-Located with the 20th International Semantic Web Conference (ISWC 2021). Virtual Event, October 27th, 2021, Vol. 3123: , G. Singh, R. Mutharaju and P. Kapanipathi, eds, CEUR Workshop Proceedings, (2021) , pp. 44–51. |
[41] | B. Mohapatra, A. Bhattacharya, S. Bhatia, R. Mutharaju and G. Srinivasaraghavan, EmEL-V: EL ontology embeddings for many-to-many relationships. Preprint, available from: https://www.semantic-web-journal.net/content/emel-v-el-ontology-embeddings-many-many-relationships. |
[42] | K.P. Murphy, Probabilistic Machine Learning: An Introduction, MIT Press, (2022) . |
[43] | S. Rudolph, T. Tserendorj and P. Hitzler, What is approximate reasoning? in: Web Reasoning and Rule Systems, Second International Conference, RR, D. Calvanese and G. Lausen, eds, Lecture Notes in Computer Science, Vol. 5341: , Springer, (2008) , pp. 150–164. doi:10.1007/978-3-540-88737-9_12. |
[44] | T. Sato, A. Takemura and T. Inoue, Towards end-to-end ASP computation, (2023) , arXiv preprint arXiv:2306.06821. |
[45] | T. Sekiyama and K. Suenaga, Automated proof synthesis for propositional logic with deep neural networks, (2018) , arXiv preprint arXiv:1805.11799. |
[46] | D. Selsam, M. Lamm, B. Bünz, P. Liang, L. de Moura and D.L. Dill, Learning a SAT solver from single-bit supervision, (2018) , arXiv preprint arXiv:1802.03685. |
[47] | A. Tomasic, O.J. Romero, J. Zimmerman and A. Steinfeld, Propositional reasoning via neural transformer language models, (2021) . |
[48] | S.P. Vadhan, Pseudorandomness, Foundations and Trends in Theoretical Computer Science 7: (1–3) ((2012) ), 1–336. doi:10.1561/0400000010. |
[49] | O. Vinyals, M. Fortunato and N. Jaitly, Pointer networks 28, (2015) . |
[50] | H. Vollmer, Introduction to Circuit Complexity, Texts in Theoretical Computer Science. An EATCS Series, (1999) . |
[51] | R. Williams, Algorithms for Circuits and Circuits for Algorithms, (2014) , pp. 248–261. ISBN 978-1-4799-3626-7. doi:10.1109/CCC.2014.33. |
[52] | G. Yang, Tensor programs I: Wide feedforward or recurrent neural networks of any architecture are Gaussian processes, CoRR, (2019) , arXiv:1910.12478. |
[53] | X. Zhu, B. Liu, Z. Ding, C. Zhu and L. Yao, Approximate ontology reasoning for domain-specific knowledge graph based on deep learning, in: 2021 7th International Conference on Big Data and Information Analytics (BigDIA), (2021) , pp. 172–179. doi:10.1109/BigDIA53151.2021.9619694. |
[54] | X. Zhu, B. Liu, C. Zhu, Z. Ding and L. Yao, Approximate reasoning for large-scale ABox in OWL DL based on neural-symbolic learning, Mathematics 11: (3) ((2023) ), 495. doi:10.3390/math11030495. |


