
Selection of Suitable Cloud Vendors for Health Centre: A Personalized Decision Framework with Fermatean Fuzzy Set, LOPCOW, and CoCoSo
Abstract
Cloud computing has emerged as a transformative technology in the healthcare industry, but selecting the most suitable CV (“cloud vendor”) remains a complex task. This research presents a decision framework for CV selection in the healthcare industry, addressing the challenges of uncertainty, expert hesitation, and conflicting criteria. The proposed framework incorporates FFS (“Fermatean fuzzy set”) to handle uncertainty and data representation effectively. The importance of experts is attained via the variance approach, which considers hesitation and variability. Furthermore, the framework addresses the issue of extreme value hesitancy in criteria through the LOPCOW (“logarithmic percentage change-driven objective weighting”) method, which ensures a balanced and accurate assessment of criterion importance. Personalized grading of CVs is done via the ranking algorithm that considers the formulation of CoCoSo (“combined compromise solution”) with rank fusion, providing a compromise solution that balances conflicting criteria. By integrating these techniques, the proposed framework aims to enhance the rationale and reduce human intervention in CV selection for the healthcare industry. Also, valuable insights are gained from the framework for making informed decisions when selecting CVs for efficient data management and process implementation. A case example from Tamil Nadu is presented to testify to the applicability, while sensitivity and comparison analyses reveal the pros and cons of the framework.
1Introduction
In the healthcare industry, cloud computing has revolutionized data management and has been efficiently implemented across various healthcare units. It provides an attractive solution to the vast problem of handling massive volumes of data in this sector. Healthcare organizations can improve their work culture and address data management challenges by incorporating cloud computing into their systems. Cloud computing in healthcare includes data analysis, sharing, access, and storage capabilities, which become more effective and scalable as data volumes grow (Satoskar et al., 2023). Furthermore, cloud computing aids in increasing customer engagement and commercial outcomes for large enterprises and healthcare organizations. Given that research has demonstrated a beneficial relationship between cloud computing and data management in the healthcare industry, it is clear that this novel technology has the potential to play a significant role in this industry and others in the future. Despite various issues confronting the healthcare business, the demand for advanced technology is increasing, making cloud computing an increasingly important component in overcoming these obstacles and driving advancement in the field (Agapito and Cannataro, 2023).
The usage of cloud computing by healthcare organizations is subtle in India compared to other countries like the USA and China. As of 2022, it was determined that only 400 out of 62,000 hospitals in India actively utilized cloud computing to collect, organize, and manage data (Krishankumar et al., 2022b). Although India has become well-advanced in using cloud services in the healthcare industry, there must be a gap in how the data are effectively organized, stored, and managed. After surveying the Indian healthcare industry, Dash et al. (2019) inferred that implementing cloud computing in healthcare industry sectors is crucial for handling massive amounts of medical data and promoting healthcare quality. Due to the high demand for cloud computing services, there has been a sharp increase in CVs (“cloud vendors”) globally. The fast growth of CVs has complicated the selection of the appropriate vendor for the healthcare industry.
From the user’s point-of-view, different CVs have different preferences based on different QoS (“quality of service”) parameters, making the selection of CVs even more challenging. Mardani et al. (2019) reviewed various decision models available in the healthcare industry. They inferred that fuzzy sets are crucial for handling uncertainty, and MCDM (“multi-criteria decision-making”) can be adopted for solving decision problems. MCDM is a promising concept that can effectively consider multiple competing/conflicting criteria for rating different alternatives (CVs) based on pre-defined preference scales from a group of experts. Since then, researchers, including Sharma and Sehrawat (2020) and Krishankumar et al. (2022b), have developed interesting MCDM solutions for selecting CVs in the healthcare industry. According to this research, it can be inferred that existing CV selection approaches (i) may inadequately handle uncertainty, (ii) may overlook expert hesitation and uncertainty, (iii) struggle with extreme value hesitancy in criteria, and (iv) may neglect the importance of compromise solutions in balancing conflicting criteria. These inferences have motivated the following research points:
• A decision framework must be adopted to handle the uncertainty of the experts’ and users’ views. This structure has to reduce the uncertainty present in the data.
• The data from the experts must be preprocessed to acquire preference and non-preference degree values, which would greatly help in handling the uncertainty.
• The importance of the experts must be effectively captured in an uncertain environment to handle extreme values.
• The hesitation in the criteria must be effectively captured in an uncertain environment using a model that also considers the experts’ importance.
• An effective and compromised ranking model considering the importance of both experts and criteria must be modelled in an uncertain environment.
Driven by these motivations, the key contributions achieved in the presented study include:
• Uncertainty has been handled effectively by adopting FFS (“Fermatean fuzzy sets”) since it represents the choices as degree values of preference and non-preference using a broader window than the earlier orthopair versions.
• The importance of the experts has been effectively captured using the variance approach since it captures the hesitation present in the criteria.
• The importance of the criteria has been effectively captured using the LOPCOW (“logarithmic percentage change-driven objective weighting”), which captures the extreme values effectively using a logarithmic operator.
• Finally, a compromise ranking of CVs is obtained using the CoCoSo (“combined compromise solution”) algorithm, which provides a ranking index as a cumulative aggregate of three measures: sum, minimum, and maximum compromise solutions.
The contributions presented above are backed by some rationale that is presented here. FFS (Senapati and Yager, 2020) was introduced as an extension of the IFS (“intuitionistic fuzzy sets”) (Atanassov, 1986) and PFS (“Pythagorean fuzzy sets”) (Yager, 2016). FFS has properties similar to an orthopair fuzzy set with value
The rest of the article is presented as follows. Section 2 reviews the recent work done on CV selection, FFS, variance method, LOPCOW, and CoCoSo. Section 3 describes the methodology of the proposed framework. Section 4 presents a case study to demonstrate the usefulness of the proposed framework. Section 5 compares the proposed framework with existing frameworks to reveal its strengths and limitations. Section 6 provides the concluding remarks and directs attention to future work.
2Literature Review
2.1Selection of Cloud Vendor Services
Ranking cloud service providers is essential for optimizing resource utilization and improving the user experience. It enables informed decision-making and addresses the challenges of the rapidly changing cloud environment. Garg et al. (2013) proposed the first decision framework for ranking cloud services using the AHP (“analytical hierarchical process”) based ranking mechanism to compare different cloud services. Since then, several studies have proposed fuzzy logic-based techniques to enhance cloud computing services. These techniques include an intelligent intermediary that assists inexperienced users in specifying their requirements, a self-learning approach for efficiently allocating resources in online games, and an algorithm for minimizing costs and time in IaaS clouds.
Additionally, a hybrid system is developed for analysing nuanced sentiments in tweets about cloud services. Another method considers QoS attributes and user feedback to rank cloud providers. A fuzzy logic model is suggested for selecting cloud providers, while another measures the uncertainty in survey responses. Finally, a trust model is introduced to aid users in identifying reliable cloud service providers (Mateen et al., 2020; Alharbi and Alhalabi, 2020; Gireesha et al., 2020; Khorsand et al., 2019; Nagarajan and Thirunavukarasu, 2019; Rizvi et al., 2020; Zhou et al., 2019). A comprehensive summary of literature focusing on CV selection using MCDM and fuzzy methodologies is provided in Table 1.
Table 1
Literature summary of MCDM and fuzzy methodologies involved in the selection of CVs.
| Source | Fuzzy set used | Criteria considered | Expert weight estimation | Criteria weight estimation | Ranking algorithm | Uncertainty handling | SA/CA |
| Dahooie et al. (2020) | IVIFS | Performance, Cost, Availability, System reliability and security, System elasticity as consumption peak, System stability, Usability and serviceability, Functional transparency, Throughput and efficiency, Average time required for repair, Average CPU utilization, Scalability, and Open-source | n/a | Delphi method | CODAS | No | n/a |
| Hussain et al. (2020a) | n/a | Reliability, Assurance, Tangibility, Empathy, Responsiveness, Processes of CVs, Administrative support, Security practices, and Technical capabilities and processes | n/a | Best-worst method | MOSS | No | CA |
| Hussain et al. (2020b) | Triangular fuzzy numbers | Response time, Latency, Throughput, Availability, and Price | n/a | Max-normalization | FLBWM | Yes | SA and CA |
| Krishankumar et al. (2020) | IFS | Economics, Technology, Environment, CV profile | n/a | IFSV | Three-way IF-VIKOR | Yes | SA and CA |
| Krishankumar et al. (2021) | Probabilistic hesitant fuzzy set | Assurance, Availability, Security, Agility, Scalability, Total cost, and Response time | Inequality-constrained optimization model using partial information | Inequality-constrained optimization model using partial information | COPRAS | Yes | SA and CA |
| Radhika and Sadasivam (2021) | Triangular fuzzy numbers | Performance, Cloud availability, Cost optimization, Scalability, and Reliability | n/a | n/a | Fuzzy–AHP | Yes | n/a |
| Krishankumar et al. (2022a) | q-rung Orthopair fuzzy set | Availability, Assurance, Agility, Security, Scalability, Response time, and Total cost | n/a | Constrained optimization model using partial information | Evidence | Yes | CA |
| Krishankumar et al. (2022b) | Hesitant fuzzy linguistic term set | Availability, Security, Accessibility, Speed, Storage capacity, Features, Ease of use, Response time, and Total cost | n/a | Constrained optimization model using partial information | EDAS | Yes | SA and CA |
| Kumar et al. (2022) | Triangular fuzzy numbers | CPU performance, Memory performance, Disk performance, Disk I/O latency, Network latency, and Cost on demand | n/a | AHP | TOPSIS | Yes | SA and CA |
| Haque et al. (2023) | Generalized spherical fuzzy number | Accessibility & performance, Reliability & management skills, Costing & security | n/a | n/a | LGSWA, LGSWG | Yes | SA and CA |
| Hang Nguyen et al. (2023) | PULTS | Agility and innovation, Cost, Time to market, and Risks | n/a | CRITIC | TODIM | Yes | SA and CA |
| Ghorui et al. (2023) | PIFN | Cloud security/privacy, Pricing, Downtime, Support services, Portability, Scalability, Disaster & recovery, Deployment & upgrades, and Service level agreements | n/a | AHP | TOPSIS | Yes | SA and CA |
| Krishankumar et al. (2023) | DHHFLTS | Assurance, Performance, Accountability, Agility, Usability, Scalability, Data/privacy breach, and E-waste generation | CRITIC | Evidence-based Bayesian approach | CRADIS | No | SA and CA |
Note: SA – sensitivity analysis; CA – comparative analysis; IVIFS – interval-valued intuitionistic fuzzy set; CODAS – combinative distance-based assessment; CV – cloud vendor; MOSS – methodology for optimal service selection; FLBWM – fuzzy linear best-worst method; IFS – intuitionistic fuzzy set; IFSV – intuitionistic fuzzy statistical variance; IF-VIKOR – intuitionistic fuzzy viekriterijumsko kompromisno rangiranje; COPRAS – complex proportional assessment; AHP – analytical hierarchical process; EDAS – evaluation based on distance from average solution; LGSWA – logarithmic generalized spherical weighted averaging; LGSWG – logarithmic generalized spherical weighted geometric; PULTS – probabilistic uncertainty linguistic fuzzy set; CRITIC – criteria importance through inter-criteria correlation; TODIM – tomada de decisão interativa e multicritério; PIFN – pentagonal intuitionistic fuzzy number; DHHFLTS – double hierarchy hesitant fuzzy linguistic term set; CRADIS – compromise ranking of alternatives from distance to ideal solution.
Table 1 provides an overview of various MCDM and fuzzy methodologies for CV selection. From Table 1, the following inferences can be drawn. (i) The existing approaches to CV selection may not robustly handle uncertainty through linguistic and hesitant fuzzy set variations in criteria weights, expert opinions, or alternatives, potentially resulting in unreliable or inconsistent results. (ii) The existing approaches to CV selection may not effectively capture the hesitation or uncertainty of experts where human-centric hesitation and varying degrees of confidence are not adequately accounted for in these approaches. (iii) The existing approaches to CV selection struggle to capture extreme value hesitancy in criteria, where experts have difficulty assigning precise importance to the criteria for ranking the CVs. (iv) The existing approaches to CV selection may need to pay more attention to the need for a compromise solution that balances conflicting criteria or objectives in an uncertain, potentially leading to suboptimal or biased CV selections. Motivated by these inferences, the authors formulated an MCDP (“multi-criteria decision problem”) for CV selection in an uncertain condition having a precise depiction of data, a human-centric approach for capturing experts’ importance, methodology to capture extreme values for criteria importance, a compromised methodology for ranking the CVs.
2.2Fermatean Fuzzy Sets
In recent years, fuzzy logic has been successfully used to resolve the challenges of estimating decision-making under uncertain conditions. Atanassov (1986) proposed IFS, which can solve many MCDM problems in uncertain environments. IFS does not cover more data points
Since its introduction, many researchers have utilized FFS and its extensions. For instance, Garg et al. (2020) developed new aggregation operators, merging FFS with Yager’s t-norm and t-conorm, and applied them in an MCDM scenario of selecting an authentic lab for COVID-19 tests. Keshavarz-Ghorabaee et al. (2020) proposed a methodology using WASPAS (“weighted aggregated sum product assessment”), SMART (“simple multi-attribute rating technique”), and FFS for evaluating and selecting green suppliers in the construction industry, demonstrating its stability and congruence with existing methods through sensitivity and comparative analyses. Aydemir and Yilmaz Gunduz (2020) introduced FF aggregation operators based on Dombi operations, analysed their arithmetic and geometric properties, compared them with existing operators, and applied them in the TOPSIS to evaluate their impact on the MCDM process. Gül (2021) extended SAW (“simple additive weighting”), ARAS (“additive ratio assessment”), and VIKOR (“viekriterijumsko kompromisno rangiranje”) to handle FFD, with application in selecting the best COVID-19 testing laboratory, validating the proposed methods against existing FFS-based decision methods. Jeevaraj (2021) introduced IVFFS (“interval-valued Fermatean fuzzy sets”) as an extension of FFS, established mathematical operations and score functions for IVFFS, compared ranking methods using the proposed score functions, and applied the TOPSIS method on IVFFS to demonstrate their applicability through numerical examples. Rani and Mishra (2021) proposed an integrated decision-making method based on the MULTIMOORA (“multiplicative form of multi-objective optimization based on ratio analysis and reference point approach”), maximizing deviation method, and Einstein aggregation operators within FFS context. They applied this method for optimal EVCS (“electric vehicle charging station”) location selection to effectively handle uncertainty and incorporate quantitative and qualitative factors, providing a robust and consistent approach compared to existing methods.
Mishra et al. (2022b) assessed different barriers in the IoT (“internet of things”) by considering the CoCoSo method in the FFS context for supporting waste management in smart cities. Akram et al. (2022) introduced linguistic FFS as a novel approach to qualitative information processing and decision-making, showcasing its applications in multi-attribute group decision-making and solving practical problems in food company ranking and green supplier selection while comparing its effectiveness with existing methods. Rani et al. (2022) proposed a novel MCDM approach by combining the CRITIC (“criteria importance through inter-criteria correlation”) and COPRAS (“complex proportional assessment”) methods with IVFFS for addressing the imprecise and incomplete information in MCDM under an uncertain environment and demonstrated its effectiveness in evaluating and selecting sustainable community-based tourism locations. Mishra et al. (2022a) introduced IVHFFS (“interval-valued hesitant Fermatean fuzzy sets”), presented various operations, distance measures, and aggregation operators for IVHFFS, and demonstrated their application in MCDM using COPRAS, specifically for the selection of desalination technology, providing a robust and stable method to address uncertainties and influencing factors. Ashraf et al. (2023) developed innovative FFS-based information measures, including distance, similarity, entropy, and inclusion measures, and demonstrated their applicability in pattern recognition, building materials, and medical diagnosis without encountering counter-intuitive cases. Akram and Bibi (2023) introduced an improved version of the PROMETHEE (“preference ranking organization method for enrichment evaluation”) using 2-tuple linguistic FFS for MCDM problems with linguistic variables, demonstrating its effectiveness and reliability in addressing such issues. Zeng et al. (2023) presented a novel framework combining FF hybrid weighted distance measure and TOPSIS for comprehensive evaluation of LCC (“low-carbon city”) quality, addressing challenges posed by uncertainty and complicated indicators, and providing insights for LCC development assessment and decision-making. Saha et al. (2023) introduced two new methods, FF-Delphi for criteria identification and FF-DN MARCOS for criteria weighting, to optimize warehouse location in the automotive industry, emphasizing “energy availability and cost” and “proximity to port and customs” as pivotal factors. Deveci et al. (2023) assessed the risks impacting sustainable mining in Greece, employing a new FF score function with SWARA for risk weighting to find the most crucial risks, aligning with SDG12 and identifying “Risk to Environment” as the highest risk category, thereby offering a roadmap for sustainable mining practices. Zaman et al. (2023) developed new decision-making techniques based on complex Fermatean fuzzy numbers and introduced various aggregation operators like CFFEWAA (“complex Fermatean fuzzy Einstein weighted average aggregation”), CFFEOWAA (“complex Fermatean fuzzy Einstein ordered weighted average aggregation”), and CFFEHAA (“complex Fermatean fuzzy Einstein hybrid average aggregation”), applying them in an extended TOPSIS method for multi-attribute group decision-making, specifically for selecting an English language instructor.
On reviewing the literature on FFS, the following points can be inferred. (i) FFS possesses distinctive characteristics that make it highly advantageous in uncertain decision-making scenarios. (ii) The ability of FFS to manage uncertainty effectively and depict detailed uncertainty representations renders it an invaluable tool for experts. (iii) Integrating FFS into decision models and methodologies enhances the resulting decisions’ dependability, resilience, and precision. (iv) Approaches based on FFS provide a comprehensive and precise assessment of various options, empowering experts with a heightened comprehension of the inherent uncertainty within the decision-making environment. Hence, the authors propose using FFS to precisely depict data to solve the MCDP of CV selection for healthcare centres in uncertain conditions.
2.3Variance, LOPCOW & CoCoSo Methods
Kao (2010) claimed that weights must be determined via a method rather than direct assignment as they tend to be inaccurate and driven by bias. Specifically, variance is a method for weight calculation that resembles human behaviour by considering the hesitation of experts during MCDM. Higher variability indicates high hesitation/confusion from the experts regarding that particular criterion, so uncertainty is high. Hence, the uncertainty of the model has to be measured, which is done using the variance. Optimistically, experts tend to pay less attention to or are influenced by those criteria. Still, from a pessimistic perspective, these criteria are considered vital as they influence the ranking, and such behavioural depiction is possible from the variance measure. Hence, the authors propose utilizing the variance method to effectively capture the experts’ importance within the defined MCDP.
Ecer and Pamucar (2022) proposed the LOPCOW method to generate more acceptable outcomes by addressing significant differences in weight values, negative values, criterion limitations, and data size discrepancies in real-life problems. They benchmarked LOPCOW with other objective weighting methods, such as Entropy and MEREC. Subsequently, they showed that the LOPCOW method achieves a relatively smaller ratio between the most crucial and least important criteria, indicating a more balanced weight calculation capability and addressing the drawbacks of the other methods. Since its introduction, many researchers have utilized the LOPCOW method and its extensions. Simic et al. (2023) proposed an advanced two-stage model under the T2NN (“type-2 neutrosophic number”) environment, combining T2NN-LOPCOW and T2NN-ARAS methods, to support the transition and upgrading of warehouse management systems with Industry 4.0-based solutions. The latter study includes a case study demonstrating the superiority of AGVs as the most favourable material handling solution. Ecer et al. (2023) introduced a practical decision-making framework combining Delphi, LOPCOW, and CoCoSo methods with IVFNN (“interval-valued fuzzy neutrosophic number”) information to evaluate the sustainability performance of MMS (“micro-mobility solutions”), providing insights into critical criteria and identifying the most promising MMS options. Ulutaş et al. (2023) developed a novel integrated MCDM model utilizing PSI (“preference selection index”), MEREC (“method based on removal effects of criteria”), LOPCOW, and MCRAT (“multiple-criteria ranking by alternative trace”) methods to effectively select the most efficient natural fibre insulation material, addressing the complexity of criteria and alternatives in the decision-making process. Nila and Roy (2023) introduced a hybrid multi-criteria decision-making model that combines LOPCOW, FUCOM, and DOBI (“Dombi Bonferroni”) methods with triangular fuzzy numbers to objectively evaluate and select third-party logistics providers for food manufacturing companies. Biswas and Joshi (2023) analysed the performance of IPOs in the Indian Stock Market from 2018–2021, using the LOPCOW method to assess market-based indicators and fundamental efficiency, suggesting that post-listing IPO performance is not necessarily tied to fundamentals and is often influenced by investor speculation, with the LOPCOW ranking method proving consistent with the widely-used Entropy model. From this literature review, the following point can be made about the LOPCOW method: (i) LOPCOW addresses significant differences in weight values, negative values, criterion limitations, and data size discrepancies in real-life problems, ensuring a more balanced weight calculation capability and leading to more acceptable outcomes compared to other objective weighting methods. (ii) Since LOPCOW achieves a relatively smaller ratio between the most crucial and least important criteria, it indicates a more reasonable and balanced assessment of criterion importance, helping experts achieve a more comprehensive and accurate evaluation of different criteria in their decision-making processes. Hence, the authors propose utilizing the LOPCOW method to effectively capture the criteria importance within the defined MCDP.
The CoCoSo method, developed by Yazdani et al. (2019), aims to provide a compromise solution to rank alternatives based on three levels of compromise space: sum, minimum, and maximum. This method aggregates weights of compared alternatives using the multiplication rule and weighted power of distance methods, calculates a ranking index as an aggregate of these three measures, and provides the final ranking of alternatives. Since the inception of CoCoSo by Yazdani et al. (2019), many researchers have utilized this method and its extensions. Wen et al. (2019) employed a probabilistic fuzzy linguistic term set and applied SWARA (“step-wise weight assessment ratio analysis”) along with CoCoSo for the selection of cold chain logistics management for medicine in clinical decision support systems. Banihashemi et al. (2021) utilized triangular fuzzy numbers and the CoCoSo method to investigate the environmental impacts of construction projects. Mishra et al. (2021) employed hesitant fuzzy sets and CoCoSo to rank sustainable third-party reverse logistic providers. Rani et al. (2021) used single-valued neutrosophic fuzzy sets and applied SWARA and CoCoSo to the renewable energy resource selection problem. Deveci et al. (2021) extended the CoCoSo method by incorporating logarithmic and power Heronian functions and applied triangular fuzzy numbers for ranking real-time traffic management systems. Demir et al. (2022) used triangular fuzzy numbers as well as both the FUCOM (“fuzzy composite evaluation method”) and CoCoSo to evaluate the sump development in urban areas. Qiyas et al. (2022) employed logarithmic picture fuzzy sets along with CoCoSo and used this framework for the drug selection for COVID-19. Jafarzadeh Ghoushchi et al. (2023) utilized spherical fuzzy sets and applied the Best-Worst method and CoCoSo to assess strategies for managing the COVID-19 infodemic. Zhang and Wei (2023) employed spherical fuzzy sets and combined CoCoSo and D-CRITIC (“distance correlation criteria importance through inter-criteria correlation”) for the location selection of electric vehicle charging stations. Su et al. (2023) used Pythagorean fuzzy sets along with the CoCoSo method to identify the technical challenges of blockchain technology for a sustainable manufacturing paradigm. Zhu et al. (2023) used an Entropy-CoCoSo framework to evaluate China’s inter-provincial Doing Business environment, finding significant regional differences and suggesting targeted improvements for optimizing business conditions and promoting economic development. Tripathi et al. (2023) introduced an MCDM approach using IFS and CoCoSo, which utilizes a generalized score function and parametric divergence measures for criteria weighting, and it was applied to medical decision-making problems for therapy evaluation. Based on this literature review, the following points about the CoCoSo method can be inferred: (i) CoCoSo is widely used because it provides a comprehensive and compromise-based approach to rank alternatives, considering multiple levels of compromise space and aggregating weights using various methods. (ii) Its ability to handle different types of fuzzy sets and incorporate other decision-making techniques makes it a versatile and effective method for addressing various research problems. Hence, the authors propose utilizing the CoCoSo method to rank the CVs within the defined MCDP.
3Methodology
This section describes the methodology used in the present study. A pictorial representation of the methodology is shown in Fig. 1.
Fig. 1
Methodology of the proposed framework.
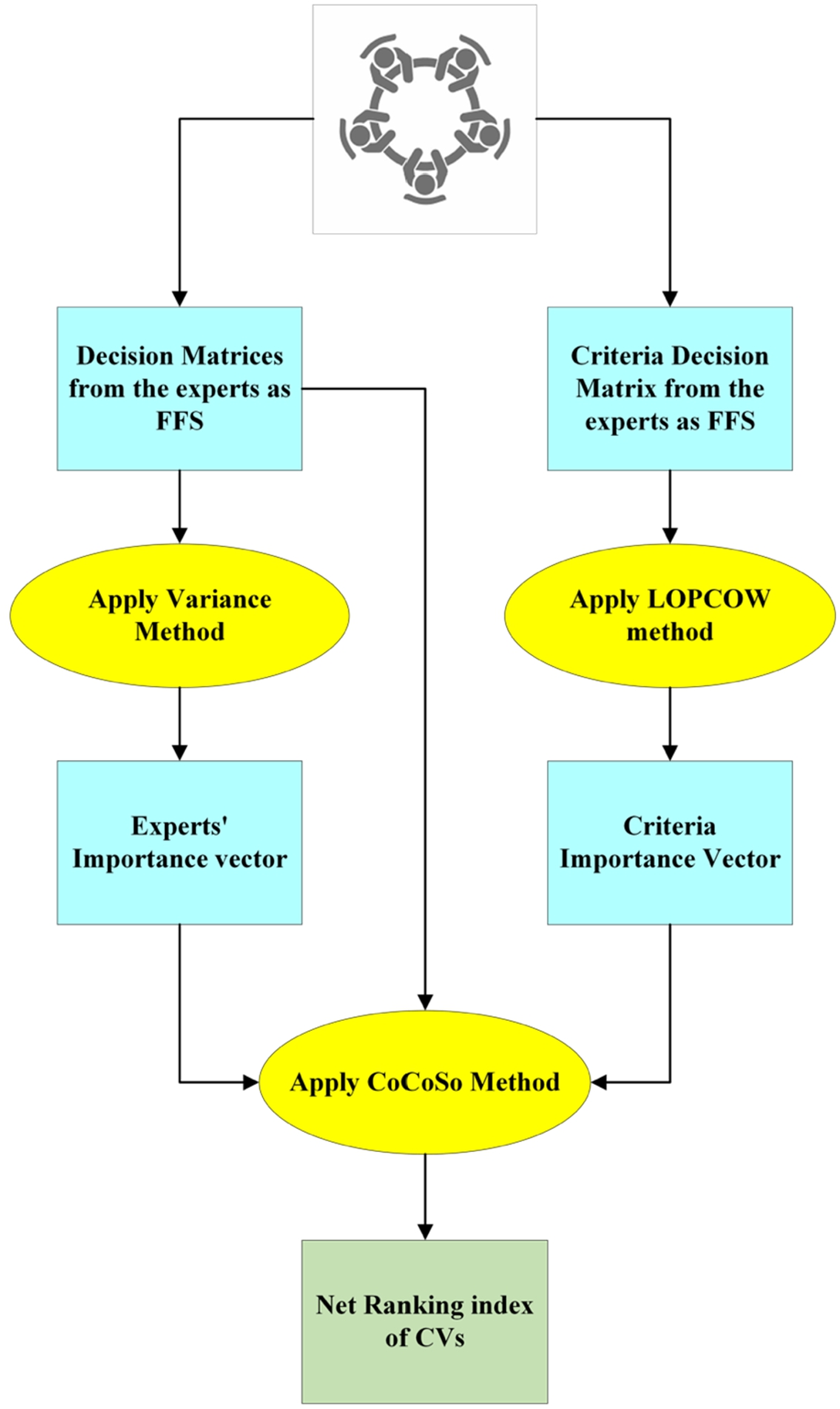
Fig. 1 depicts the research model and methodology used in this research to solve the MCDP of CV selection for healthcare centres in uncertain environments. The methodology described in Fig. 1 is presented below in the following manner: (i) Section 3.1 presents some basic concepts related to FFS; (ii) Section 3.2 describes the steps involved in calculating the expert’s importance vector using the variance method; (iii) Section 3.3 explains the steps involved in calculating the criteria importance vector using the LOPCOW method; and (iv) Section 3.4 discusses the steps involved in calculating the net ranking index of CVs using the CoCoSo method.
3.1Preliminaries
Some basic concepts related to IFS and FFS are presented below:
Definition 1
Definition 1(Atanassov, 1986).
Let H be a fixed set and let N be another fixed set such that
(1)
Definition 2
Definition 2(Senapati and Yager, 2020).
Let H be a fixed set.
(2)
Definition 3
Definition 3(Senapati and Yager, 2020).
Let
(3)
(4)
(5)
(6)
(7)
(8)
3.2Expert Weight Estimation
This section discusses the calculation of experts’ weights, which were calculated using the variance method. The advantage of the variance method inferred from Section 2.3 is as follows: (i) The variance method effectively captures the hesitation and uncertainty exhibited by experts when assigning weights to different criteria. A higher variance in weight values signifies greater uncertainty, allowing the model to reflect real-world complexities that experts may grapple with; and (ii) This method allows for a nuanced understanding of how experts view the importance of various criteria. From a pessimistic perspective, these criteria are vital as they significantly influence the ranking. This behavioural depiction is made possible through the use of variance, providing a more comprehensive understanding of the decision-making process. The steps followed for the calculation of expert weights using the variance method are given below:
Step 1: Let d experts give ratings on x CVs based on c competing criteria. Likert scales are used for converting the ratings into FFNs. The following points are to be noted:
• l refers to the expert number, where
• i refers to the alternative, i.e. CV number, where
• j refers to the criteria number, where
The dimension of the decision matrices for every expert l is
Step 2: Calculate the accuracy
Step 3: Determine the normalized accuracy
(11)
Step 4: Determine the variance vector for every expert d by applying Eq. (12). Please note that Eq. (12) yields a
(12)
Step 5: Determine the experts’ net confidence using Eq. (13), which is considered the importance of the experts. Please note that Eq. (13) yields a
(13)
3.3Criteria Weight Estimation
This section gives an overview of the steps involved in calculating the weight of the criteria, which was calculated via the LOPCOW method. A few advantages of the LOPCOW method can be inferred from Section 2.3 as follows: (i) LOPCOW method is designed to handle significant differences in the criteria weights, making it more adaptable for real-time problems; (ii) This method can also handle negative values present in the criteria, making it more versatile to different decision-making scenarios; (iii) This method also provides a more balanced and reasonable criteria importance, since it achieves relatively smaller ration between most important and least important criteria; (iv) LOPCOW can also manage data size discrepancies, make it more adaptable to varying size of datasets; and (v) LOPCOW provides a more acceptable and a comprehensive criteria importance in decision-making processes. The steps involved in the calculation of criteria weights using the LOPCOW method are presented below:
Step 1: Let d experts give ratings on c competing criteria. Likert scales are used for converting the ratings into FFNs. The following points are to be noted:
• l refers to the expert number, where
• j refers to the criteria number, where
The dimension of the criteria decision matrix is
Step 2: Calculate the accuracy
Step 3: Determine the normalized accuracy
(14)
Step 4: Calculate the percentage values
(15)
It is to be noted that in Eq. (15),
Step 5: Compute the criteria weights using Eq. (16). Please note that Eq. (16) yields a
(16)
3.4Ranking Algorithm
This section elucidates the steps involved in ranking the CVs, which were performed using the CoCoSo method. The advantages of the CoCoSo method can be inferred from Section 2.3 as follows: (i) CoCoSo method provides a comprehensive approach to ranking alternatives by considering three levels of compromise space: sum, minimum, and maximum allowing for a more nuanced and balanced decision-making process; (ii) This method employs multiple techniques for aggregating weights, such as the multiplication rule and weighted power of distance methods enhancing the flexibility of its applicability in various scenarios; (iii) This method captures the behavioural aspects of decision-making, allowing for a more human-centric evaluation that can be more aligned with real-world decision-making processes; (iv) The method’s ability to aggregate weights using various methods makes it well-suited for scenarios where simple weighting schemes may not capture the complexity of the decision-making environment; and (v) The method’s flexibility in aggregating weights allows it to adapt to problems with different scales or units, making it easier to combine disparate types of information into a unified decision-making framework. The steps involved in ranking the CVs using the CoCoSo method are presented below:
Step 1: Let d experts give ratings on x CVs based on c competing criteria. Likert scales are used for converting the ratings into FFNs. The following points are to be noted:
• l refers to the expert number, where
• i refers to the alternative, i.e. CV number, where
• j refers to the criteria number, where
The dimension of the decision matrices for every expert l is
Step 2: Calculate the accuracy
Step 3: Determine the normalized accuracy
Step 4: Determine the weighted normalized accuracy
(17)
Step 5: Determine the multi-stage compromise solutions
(18)
(19)
(20)
Step 6: Combine the compromise solutions using Eq. (21) to obtain the net ranking vector for every expert l. Please note that Eq. (21) yields a
(21)
Step 7: Aggregate the rank values for every expert l using Eq. (22). Please note that Eq. (22) yields a
(22)
The flowchart of the proposed model has been presented in Fig. 2.
Fig. 2
Flowchart of the proposed model.
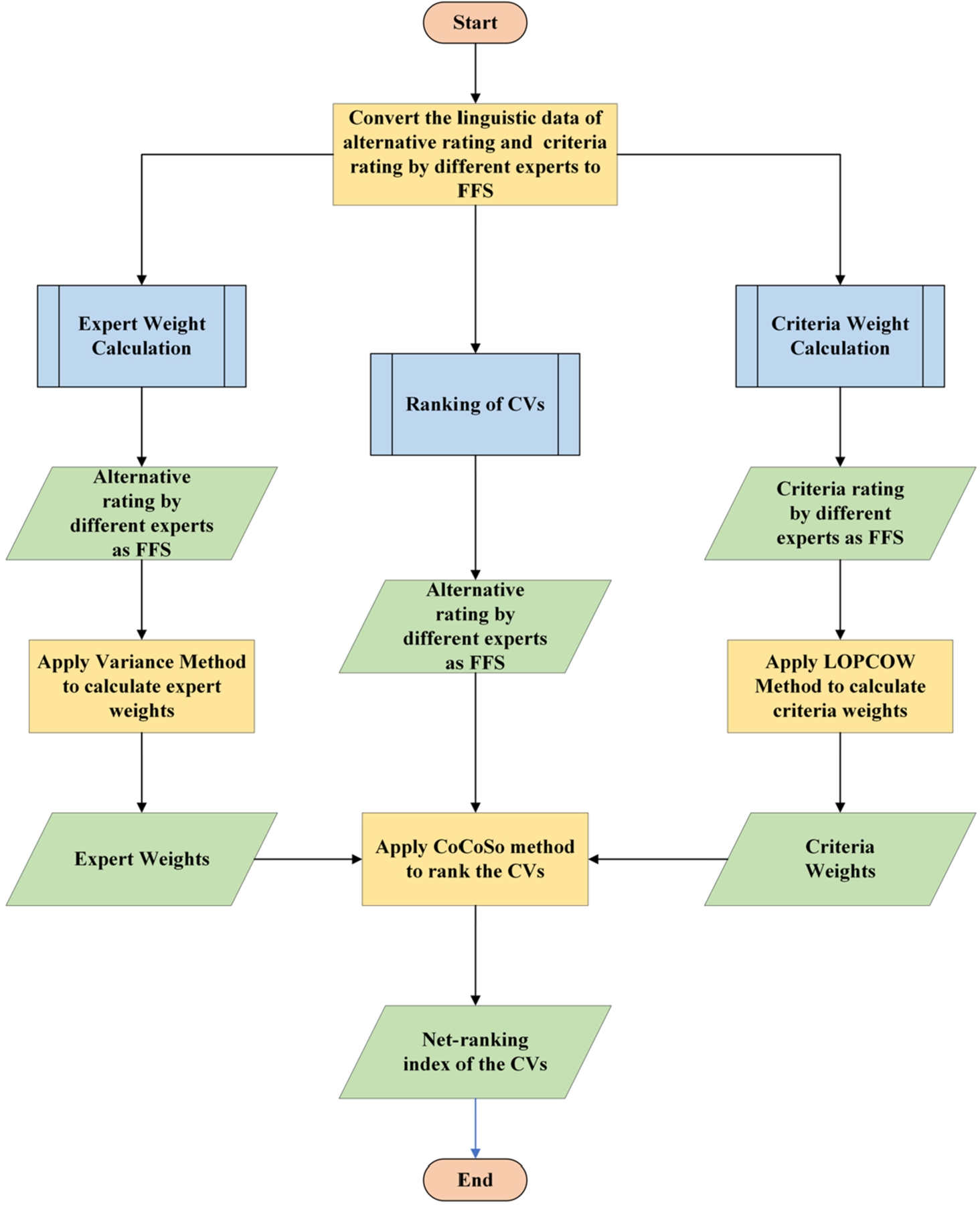
In Fig. 2, the flowchart delineates a systematic process for evaluating and ranking CVs. The process commences by converting the linguistic data of both alternative ratings and criteria ratings from various experts into FFS. Subsequently, the evaluation splits into two parallel paths: the left focuses on the calculation of expert weights by first obtaining alternative ratings as FS from different experts and then applying the Variance Method, culminating in a derived set of expert weights. The right path is dedicated to calculating criteria weights, which involves obtaining criteria ratings as FS from different experts and employing the LOPCOW Method. Once both weights are ascertained, the CoCoSo method ranks the CVs, resulting in a net-ranking index. The procedure concludes once the final rankings of the CVs are established.
4Case Study
This section presents a case example of CV selection for a health centre, concentrating effectively on the centre’s core activities without compromising utility activities. Such utility activities include data storage for patients’ data, employee data, inventory data, and official records, appointment maintenance, and analytics operations for planning the next five-year target and focusing on the mechanism for improving profitability. As a result, there was an urge for rational selection of CVs to support the health centre.
During the annual audit meeting, the centre’s officials decided to invest in cloud technology to stay competitive and balance core and utility activities. The advent of the pandemic emphasized the urgent need for effective data storage and maintenance to serve patients and employees better. Learning from the pandemic, the officials framed a panel of three experts with six to eight years of experience in their respective fields, such as technology, finance and audit, and legal/ethical aspects. The experts include a senior professor from the cloud computing division, legal/audit personnel, and a senior cloud admin from a company. These experts selected ten CVs from a cloud armor repository. Based on a peer discussion through emails and phone calls, seven CVs were chosen for the study and were rated by experts based on ten QoS attributes, considered from CSMIC (Siegel and Perdue, 2012) that offers benchmarking factors for cloud services. The ten QoS criteria are agility, assurance, scalability, availability, security, user-friendliness, customer relationship, privacy breach, total cost, and integrity risk. For ease of representation,
The steps involved in ranking the seven CVs against the ten criteria with the collected data by three experts using the proposed framework are presented below:
Step 1: Construct a
Table 2
Likert scale to convert data to FFN.
| CV rating | Criteria rating | ||
| Linguistic term | FFN | Linguistic term | FFN |
| Extremely Low (EL) | Extremely Less Preferred (ELP) | ||
| Very Low (VL) | Very Less Preferred (VLP) | ||
| Moderately Low (ML) | Moderately Less Preferred (MLP) | ||
| Low (L) | Less Preferred (LP) | ||
| Moderate (M) | Neutral (N) | ||
| High (H) | Highly Preferred (HP) | ||
| Moderately High (MH) | Moderately Highly Preferred (MHP) | ||
| Very High (VH) | Very Highly Preferred (VHP) | ||
| Extremely High (EH) | Extremely Highly Preferred (EHP) | ||
Table 2 presents the Likert scale for converting linguistic data to FFN. Values from Table 2 were used in Table 3 and Table 4 for performing the decision-making process.
Table 3
Dataset consisting of ratings of seven CVs by three experts using ten criteria.
| CVs | Experts | Criteria | |||||||||
| ML | VH | EH | VL | H | VH | L | M | L | H | ||
| L | VL | MH | ML | VL | H | EH | L | EH | M | ||
| EH | VH | L | EH | ML | VL | L | M | ML | ML | ||
| VH | H | MH | MH | M | L | MH | L | M | M | ||
| VH | VH | ML | MH | H | ML | VH | VH | M | VH | ||
| L | H | VH | M | ML | L | MH | VH | ML | MH | ||
| MH | H | VH | ML | VL | ML | M | L | L | MH | ||
| H | M | H | ML | ML | EH | VL | M | VH | L | ||
| M | H | ML | M | M | EH | ML | M | M | L | ||
| VH | ML | ML | VL | H | M | H | EH | MH | MH | ||
| EH | EH | VL | VH | H | M | L | ML | MH | M | ||
| VH | H | VL | ML | L | M | VL | VL | VH | VH | ||
| M | H | H | M | MH | L | VH | M | EH | M | ||
| M | VH | ML | L | M | MH | ML | VL | ML | H | ||
| M | ML | L | VL | ML | M | MH | M | L | L | ||
| VH | VL | M | ML | EH | MH | VL | VH | VH | L | ||
| H | M | H | MH | VH | L | ML | ML | M | ML | ||
| H | ML | H | L | ML | VL | M | H | MH | VH | ||
| M | MH | M | MH | L | L | VH | VL | H | EH | ||
| EH | VH | VL | L | M | ML | EH | ML | M | L | ||
| H | M | M | H | EH | MH | ML | ML | EH | M | ||
Note: CV – cloud vendor; Please refer to Table 2 for the expansions of the abbreviations used in this table.
Table 3 presents the dataset containing ratings for seven CVs based on the ten criteria by three experts. This data was converted into an FFN by finding the accuracy using Eq. (7) after converting it to
Step 2: Calculate the experts’ importance with the matrices from Step 1 using the variance method presented in Section 3.2 using Eqs. (11)–(13).
The accuracy computed using Eq. (7) was normalized based on cost and benefit criteria using Eq. (11). Variance values were then determined by considering Eq. (12), and later, the experts’ importance was computed using Eq. (13). The importance of experts
Step 3: Construct a
Table 4
Dataset consisting of ratings of ten criteria by three experts.
| Experts | Criteria | |||||||||
| N | MHP | LP | VHP | MHP | N | EHP | VLP | N | HP | |
| VHP | VHP | LP | N | MLP | EHP | VHP | MHP | HP | HP | |
| MLP | LP | MHP | MLP | N | N | EHP | HP | HP | VHP | |
Note: Please refer to Table 2 for the expansions of the abbreviations used in this table.
Table 4 contains the ratings of the ten criteria by the three experts. This data was converted into an FFN by finding the accuracy using Eq. (7) after converting it to
Step 4: Calculate the criteria importance with the matrices from Step 3 using the LOPCOW method presented in Section 3.3 using Eqs. (14)–(16).
The accuracy computed using Eq. (7) was normalized based on cost and benefit criteria using Eq. (14). The criteria importance was computed to be 0.068, 0.102, 0.153, 0.068, 0.057, 0.153, 0.057, 0.131, 0.153, and 0.057 for criteria
Step 5: Calculate the net ranking index of CVs with the matrices from Step 1, experts’ importance from Step 2, and criteria importance from Step 4 using the CoCoSo method presented in Section 3.4 using Eqs. (17)–(22).
Table 5
Net ranking index of CVs.
| Cloud vendors | Net ranking index | |||
| Experts | Cumulative | |||
| 17.876 | 16.966 | 19.901 | 18.263 | |
| 14.675 | 17.874 | 18.302 | 16.856 | |
| 17.652 | 15.343 | 13.318 | 15.312 | |
| 18.543 | 16.238 | 20.202 | 18.338 | |
| 13.903 | 15.299 | 15.232 | 14.787 | |
| 19.973 | 14.568 | 17.776 | 17.387 | |
| 16.769 | 16.104 | 16.510 | 16.470 | |
After finding the accuracy with Eq. (7) and normalizing them with Eq. (11), the weighted normalized accuracy was computed using Eq. (17). The multi-stage compromise solutions, i.e. sum, minimum, and maximum, were computed using Eqs. (18)–(20), respectively. Eq. (21) was then used to aggregate the compromise solutions as the sum of the arithmetic and geometric mean of these solutions. Finally, the net-ranking index was computed using Eq. (22), multiplying all the compromise solutions raised to its corresponding expert weights.
Table 5 presents the net-ranking index of each expert,
5Results & Discussion
5.1Sensitivity Analysis
This section attempts to understand the effect of criteria weights on the ordering of CVs. For this purpose, we performed weight rotation using a left shift operator that swaps weights between the criteria set to form new weight sets so that every weight value is assigned to every criterion once. Additionally, this gave us ten sets of weight vectors, each of
For each weight set, parameter values are determined for each expert, and net values are calculated. This results in a
Fig. 3
Sensitivity graph of the framework.
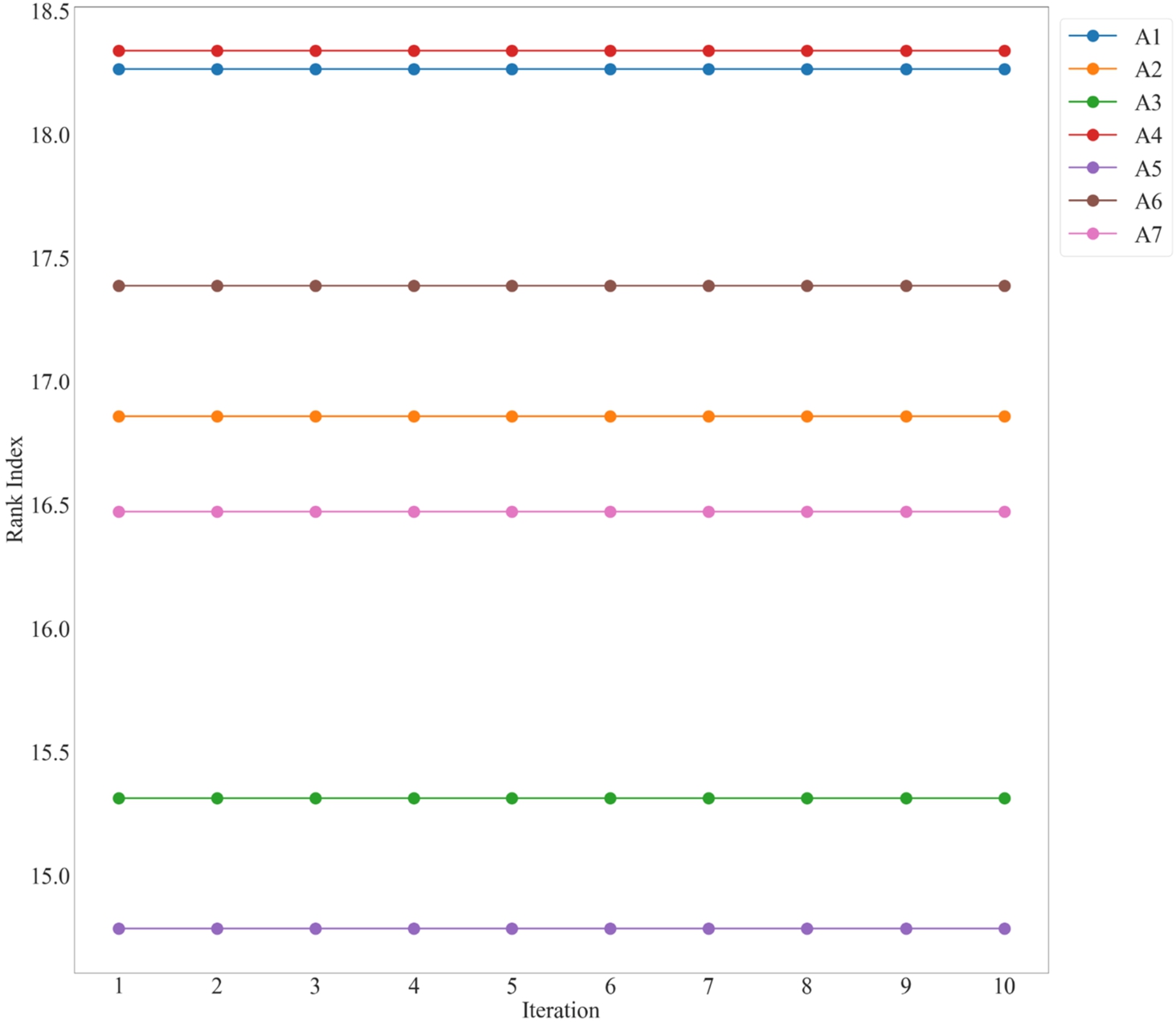
5.2Comparative Analysis
This section provides a bidirectional comparison between the application and method perception. In the application context for CV selection, the authors considered extant models that use IFS and its extensions in the method context. The proposed model was compared with the extant models to understand its efficacy. From the application perspective, models like those proposed by Krishankumar et al. (2020), Dahooie et al. (2020), Hussain et al. (2020a), Hussain et al. (2020b), and Hang Nguyen et al. (2023) were compared with proposed model to understand its efficacy from the application perspective. A comparison of the proposed model and extant models is presented in Table 6.
Table 6
Comparison of the proposed model with existing models.
| Features | Proposed model | Hang Nguyen et al. (2023) | Hussain et al. (2020a) | Hussain et al. (2020b) | Dahooie et al. (2020) | Krishankumar et al. (2020) |
| Rating | FFS | PULTS | Crisp | Triangular fuzzy numbers | IVIFS | IFS |
| Subjective randomness | Captured | n/a | n/a | n/a | Captured | Captured |
| Preference flexibility | Highly flexible | Highly flexible | n/a | n/a | Moderately flexible | Less flexible |
| Uncertainty modelling | Better | Better | n/a | n/a | Good | Good |
| Experts’ importance | Determined | n/a | n/a | n/a | n/a | n/a |
| Experts’ hesitation | Captured | n/a | n/a | n/a | n/a | Captured |
| Criteria type | Considered during weight calculation and ranking | –Considered during ranking– | ||||
| Personalized ranking | Possible | n/a | n/a | n/a | n/a | n/a |
| Weight consideration | Both expert and criteria weights | –Only criteria weights– | ||||
Note: FFS – Fermatean fuzzy sets; PULTS – probability uncertainty linguistic term set; IVIFS – interval-valued intuitionistic fuzzy set; IFS – intuitionistic fuzzy set.
Some innovative features of the developed model are provided below:
• FFS is considered the preference information that could model uncertainty from three zones, i.e. preference, non-preference, and hesitancy, with a broader scope for preference expression, unlike the other fuzzy variants shown in Table 6. Owing to the flexibility in terms of the q parameter, the range of expression is broadened, thereby allowing better expression of choices. Also, FFS handles subjective randomness effectively, as it is a crucial property of an orthopair fuzzy set.
• Human intervention is managed effectively by calculating parameter values rather than direct assignment. As a result, the bias and inaccuracy in the decision process are reduced, thereby providing rationality in the decision process. Furthermore, the hesitation of experts is handled effectively by the developed methods, along with the scope for better discrimination of criteria based on their importance and values. Also, the consideration of the reliability of experts and criteria type allows for rational weight assessment, unlike other methods.
• Since experts play a crucial role in the decision process, consideration of their weights/importance during criteria weight calculation and ranking is crucial. Unlike other models, in this case, the importance of experts is considered during criteria weight calculation, and both criteria and experts’ weights are considered during the ranking of CVs. Such a connected decision system allows rational ranking of CVs with better consistency.
• Finally, the ranking of CVs is done in two ways, i.e. personalized and cumulative ways, which needs to be improved in the extant models. Also, the consistent rank fusion with the help of weights of experts and consideration of criteria weights during rank estimation makes the developed model well-connected and systematic, unlike other CV selection approaches.
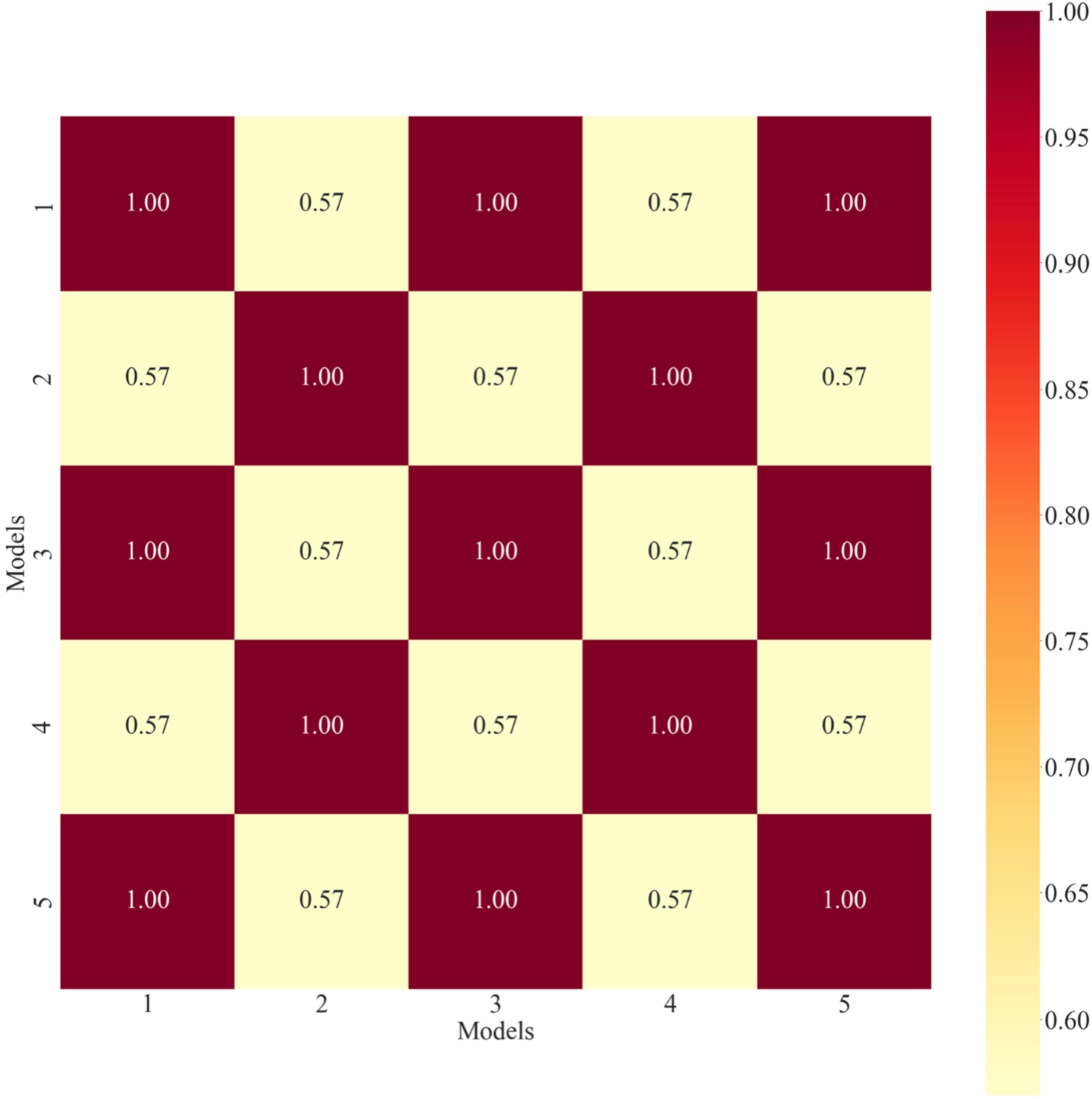
From the method perspective, the models proposed by Senapati and Yager (2020), Mishra et al. (2022b), Rani and Mishra (2021), and Zeng et al. (2023) were compared with the developed framework to determine its consistency level by applying Spearman correlation to the rank orders obtained from each method. It can be noted from Fig. 4 that the proposed framework is consistent with the other decision models with coefficient values of 1, 0.57, 1, 0.57, and 1 for proposed versus other models. Fig. 4 provides the complete correlation plot to show the net consistency effect of the proposed model with respect to other decision models.
Fig. 5
Broadness analysis of the proposed model against other models.
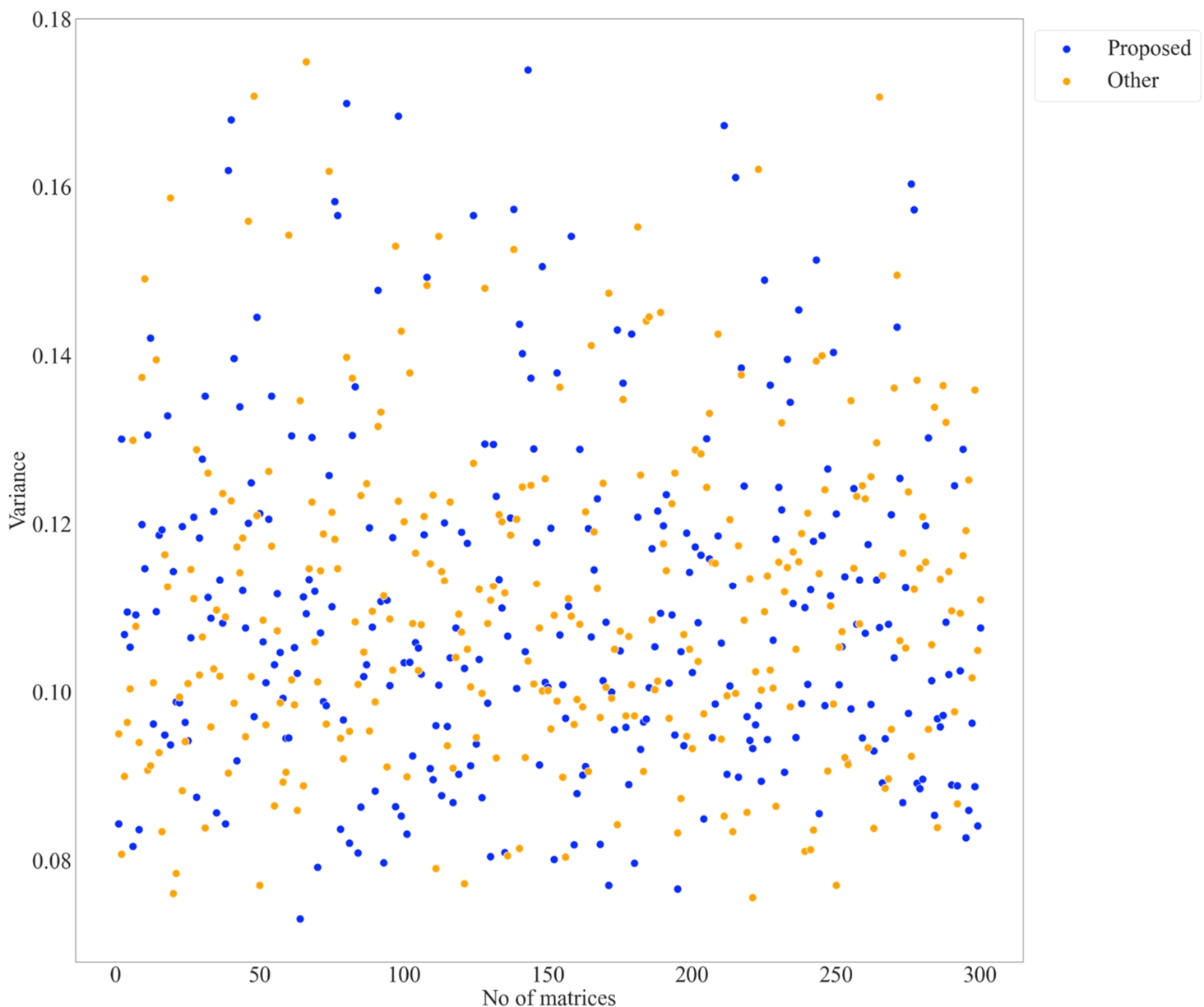
Apart from consistency, we also explored the broadness aspect of the proposed model to give stakeholders a convenient ordering of CVs that would facilitate better backup planning and management. For this, we performed a simulation study with a set of 300 matrices with a
5.3Discussion
CV selection is an important decision problem aimed at supporting diverse sectors to manage data and resources properly. Since the health industry is packed with crucial and private data, health industries need to maintain such data efficiently and less expensively. Besides, data management must help the health sector’s daily activity; in this aspect, cloud technology is a prominent DT that meets the industry’s demand. However, the hurdle lies in choosing a suitable CV based on diverse criteria and uncertain preferences.
To tackle the challenge, we propose a model possessing integrated decision approaches focusing on the methodical determination of parameter values and reduced human intervention to alleviate biases and inaccuracies in the process. The selection problem involves the consideration of multiple criteria that are QoS presented by the CSMIC as benchmarking factors for aiding appropriate CV selection. Since there are multiple criteria and the opinion of a CV with respect to these criteria is uncertain, the problem is mapped to MCDM. Here, criteria weights are methodically derived, and from the values in Section 4, it is seen that scalability, user-friendliness, and total cost are highly preferred criteria, followed by privacy breach and assurance. Likewise, other criteria preferences are gained. Based on the ranking algorithm, CV
The efficacy of the framework was investigated from both the application and methodology perspectives based on Table 6, Fig. 4, and Fig. 5. It is inferred that the proposed framework is methodical and reduces human intervention, subjectivity, and biases. Furthermore, the model demonstrated consistency with respect to other models and the ability to showcase both individualistic and cumulative ranking of CVs with an acceptable level of broadness, which the other models need to improve.
6Conclusion
The framework developed in this article is valuable for the rational selection of CVs to manage utility activities in the health industry effectively. Primarily, the framework focuses on better modelling uncertainty and reducing human intervention to tackle the issues of bias and subjectivity. Weights of experts and criteria are methodically determined with better capturing of hesitation of experts during preference articulation along with personalized rank orders of CVs, which aids in mitigating subjectivity and biases. The model provides both cumulative and personalized ordering of CVs that offers better planning and rationale toward a specific selection. Utilization of FFN for data models uncertainty effectively from three dimensions, i.e. membership, hesitancy, and non-membership, gives a broader window for preference expressions. Variance and LOPCOW methods are presented for determining the weights of entities, and later, a ranking algorithm with CoCoSo and rank fusion is put forward for determining the rank values of CVs at both the individualistic and cumulative levels.
From Table 6, Fig. 3, and Fig. 4, the efficacy of the framework is clarified from both the application and method perspectives. Some notable aspects of the proposed framework include consistency, broad rank values, and methodical parameter calculations. Further, some implications of the framework include: (i) is a ready-to-use module that can supplement decisions from stakeholders; (ii) reduces human intervention and provides a methodical approach for calculating decision parameters that reduce inaccuracies and subjectivity; (iii) can be used both by users and CVs for their respective purposes, such as aiding selection and planning strategies to improve market growth, respectively; (iv) offers both sense of personalization and cumulative rank estimation that adds value to stakeholders at the decision-making process; (v) uncertainty is handled from three dimensions – preference, non-preference, and hesitancy; (vi) subjective randomness issue and bias from the system is handled via methodical calculation of entities; and (vii) can be used by policymakers and other stakeholders after training which can be facilitated via seminars, hands-on sessions, and workshop.
Some limitations of the work are: (i) data are assumed to be complete, and if, due to hesitation, some instances are not available, the system cannot handle the issue; (ii) partial information about entities cannot be considered in the present formulation; (iii) customized ranking; (iii) pre-defined terms are being used, which in some sense restricts the experts from flexibly providing her/his rating; and (iv) functional criteria are considered for rating CVs, but social and environmental factors are not included in the present study. In terms of future research scope, we plan to address the limitations and extend the framework to different MCDM applications from supply chains, energy, sustainability, environment sectors, and so on. Further, we also anticipate extending different fuzzy versions, such as interval and probabilistic variants of orthopair fuzzy sets, hesitant fuzzy sets, neutrosophic fuzzy sets, and alike, to better understand uncertainty modelling for CV selection. Also, the data-preprocessing module is planned to enhance the rating information with consistent preference information from experts either via feedback mechanism or methodical data entry. Finally, concepts of machine learning and recommender systems can be integrated with the proposed framework to perform large-scale decision-making better.
Author contributions
S. Dhruva – Conceptualization, Data curation, Prototyping, Implementation, Writing and Editing.
R. Krishankumar – Conceptualization, Data curation, Implementation, Writing and Editing.
E.K. Zavadskas – Implementation, Supervision, Review, Writing and Editing.
K.S. Ravichandran – Prototyping, Supervision, Review Writing and Editing.
A.H. Gandomi – Language Editing, Implementation, Supervision, Writing and Editing.
Declarations
Conflict of interest: The authors declare no competing interest.
Appendices
A
AAppendix
Table A1
Terms and their abbreviations.
| Term | Abbreviation |
| AHP | Analytical hierarchical process |
| ARAS | Additive ratio assessment |
| CA | Comparative analysis |
| CFFEWAA | Complex Fermatean fuzzy Einstein weighted average aggregation |
| CFFEOWAA | Complex Fermatean fuzzy Einstein ordered weighted average aggregation |
| CFFEHAA | Complex Fermatean fuzzy Einstein hybrid average aggregation |
| CoCoSo | Combined compromise solution |
| CODAS | Combinative distance-based assessment |
| COPRAS | Complex proportional assessment |
| CRADIS | Compromise ranking of alternatives from distance to ideal solution |
| CRITIC | Criteria importance through inter-criteria correlation |
| CV | Cloud vendor |
| D-CRITIC | Distance correlation criteria importance through inter-criteria correlation |
| DHHFLTS | Double hierarchy hesitant fuzzy linguistic term set |
| DOBI | Dombi Bonferroni |
| EDAS | Evaluation based on distance from average solution |
| EVCS | Electric vehicle charging station |
| FF | Fermatean fuzzy |
| FFD | Fermatean fuzzy data |
| FFN | Fermatean fuzzy number |
| FFS | Fermatean fuzzy set |
| FLBWM | Fuzzy linear best-worst method |
| FUCOM | Fuzzy composite evaluation method |
| IF-VIKOR | Intuitionistic fuzzy viekriterijumsko kompromisno rangiranje |
| IFS | Intuitionistic fuzzy set |
| IFSV | Intuitionistic fuzzy statistical variance |
| IoT | Internet of things |
| IVFFS | Interval-valued Fermatean fuzzy sets |
| IVFNN | Interval-valued fuzzy neutrosophic number |
| IVHFFS | Interval-valued hesitant Fermatean fuzzy sets |
| IVIFS | Interval-valued intuitionistic fuzzy set |
| LCC | Low carbon city |
| LGSWA | Logarithmic generalized spherical weighted averaging |
| LGSWG | Logarithmic generalized spherical weighted geometric |
| LOPCOW | Logarithmic percentage change-driven object weighting |
| MCDM | Multi-criteria decision making |
| MCDP | Multi-criteria decision problem |
| MCRAT | Multiple-criteria ranking by alternative trace |
| MEREC | Method based on removal effect of criteria |
| MMS | Micro mobility solutions |
| MOSS | Methodology for optimal service selection` |
| MULTIMOORA | Multiplicative form of multi-objective optimization based on ratio analysis and reference point approach |
| PFS | Pythogorean fuzzy set |
| PIFN | Pentagonal intuitionistic fuzzy number |
| PROMTHEE | Perference ranking organization method for enrichment evaluation |
| PSI | Preference selection index |
| PULTS | Probabilistic uncertainty linguistic fuzzy set |
| QoS | Quality of service |
| SA | Sensitivity analysis |
| SAW | Simple additive weighting |
| SMART | Simple multi-attribute rating technique |
| SWARA | Step-wise weight assessment ratio analysis |
| T2NN | Type-2 neutrosophic number |
| TODIM | Tomada de decisão interativa e multicritério |
| TOPSIS | Technique for order preference by similarity to ideal solution |
| WASPAS | Weighted aggregated sum product assessment |
Table A2
Symbols and their definitions.
| Symbol(s) | Definition | Symbol(s) | Definition |
| H | Fixed set | c | No of criteria |
| N | Fixed set | j | Criteria number |
| IFS | FFN of ith CV, jth criteria, and lth expert | ||
| h | Value belonging to set H | Accuracy of | |
| Degree of truth in IFS | Normalized accuracy of | ||
| Degree of false in IFS | Variance of jth criteria and lth expert | ||
| Degree of hesitance in IFS | Weight of lth expert | ||
| FFS | FFN of jth criteria and lth expert | ||
| Preference value of FFS | Accuracy of | ||
| Non-preference value of FFS | Normalized accuracy of | ||
| FFN | Percentage value of jth criteria | ||
| η | Constant | Weight of jth criteria | |
| Accuracy of FFN | Weighted normalized accuracy of | ||
| Score of FFN | First compromise solution of ith CV and lth expert | ||
| d | Number of experts | Second compromise solution of ith CV and lth expert | |
| l | Expert number | Third compromise solution of ith CV and lth expert | |
| x | No of CVs | Combined compromise solution of ith CV and lth expert | |
| i | CV number | Net-ranking index of ith CV |
References
1 | Agapito, G., Cannataro, M. ((2023) ). An overview on the challenges and limitations using cloud computing in healthcare corporations. Big Data and Cognitive Computing, 7: (2), 68. |
2 | Akram, M., Bibi, R. ((2023) ). Multi-criteria group decision-making based on an integrated PROMETHEE approach with 2-tuple linguistic Fermatean fuzzy sets. Granular Computing, 8: , 917–941. |
3 | Akram, M., Ramzan, N., Feng, F. ((2022) ). Extending COPRAS method with linguistic Fermatean fuzzy sets and Hamy mean operators. Journal of Mathematics, 2022: , 1–26. |
4 | Alharbi, J.R., Alhalabi, W.S. ((2020) ). Hybrid approach for sentiment analysis of twitter posts using a dictionary-based approach and fuzzy logic methods: study case on cloud service providers. International Journal on Semantic Web and Information Systems (IJSWIS), 16: (1), 116–145. |
5 | Ashraf, S., Naeem, M., Khan, A., Rehman, N., Pandit, M.K. ((2023) ). Novel information measures for Fermatean fuzzy sets and their applications to pattern recognition and medical diagnosis. Computational Intelligence and Neuroscience, 2023. |
6 | Atanassov, K. ((1986) ). Intuitionistic fuzzy sets. Fuzzy Sets and Systems, 20: (1), 87–96. |
7 | Aydemir, S.B., Yilmaz Gunduz, S. ((2020) ). Fermatean fuzzy TOPSIS method with Dombi aggregation operators and its application in multi-criteria decision making. Journal of Intelligent & Fuzzy Systems, 39: (1), 851–869. |
8 | Banihashemi, S.A., Khalilzadeh, M., Zavadskas, E.K., Antucheviciene, J. ((2021) ). Investigating the environmental impacts of construction projects in time-cost trade-off project scheduling problems with CoCoSo multi-criteria decision-making method. Sustainability, 13: (19), 10922. |
9 | Biswas, S., Joshi, N. ((2023) ). A performance based ranking of Initial Public Offerings (IPOs) in India. Journal of Decision Analytics and Intelligent Computing, 3: (1), 15–32. |
10 | Dahooie, J.H., Vanaki, A.S., Mohammadi, N. ((2020) ). Choosing the appropriate system for cloud computing implementation by using the interval-valued intuitionistic fuzzy CODAS multiattribute decision-making method (case study: Faculty of New Sciences and Technologies of Tehran University). IEEE Transactions on Engineering Management, 67: (3), 855–868. |
11 | Dash, S., Shakyawar, S.K., Sharma, M., Kaushik, S. ((2019) ). Big data in healthcare: management, analysis and future prospects. Journal of Big Data, 6: (1), 1–25. |
12 | Demir, G., Damjanović, M., Matović, B., Vujadinović, R. ((2022) ). Toward sustainable urban mobility by using fuzzy-FUCOM and fuzzy-CoCoSo methods: the case of the SUMP podgorica. Sustainability, 14: (9), 4972. |
13 | Deveci, M., Pamucar, D., Gokasar, I. ((2021) ). Fuzzy Power Heronian function based CoCoSo method for the advantage prioritization of autonomous vehicles in real-time traffic management. Sustainable Cities and Society, 69: , 102846. |
14 | Deveci, M., Varouchakis, E.A., Brito-Parada, P.R., Mishra, A.R., Rani, P., Bolgkoranou, M., Galetakis, M. ((2023) ). Evaluation of risks impeding sustainable mining using Fermatean fuzzy score function based SWARA method. Applied Soft Computing, 139: , 110220. |
15 | Ecer, F., Pamucar, D. ((2022) ). A novel LOPCOW-DOBI multi-criteria sustainability performance assessment methodology: an application in developing country banking sector. Omega, 112: , 102690. |
16 | Ecer, F., Küçükönder, H., Kaya, S.K., Görçün, Ö.F. ((2023) ). Sustainability performance analysis of micro-mobility solutions in urban transportation with a novel IVFNN-Delphi-LOPCOW-CoCoSo framework. Transportation Research Part A: Policy and Practice, 172: , 103667. |
17 | Garg, H., Shahzadi, G., Akram, M. ((2020) ). Decision-making analysis based on Fermatean fuzzy Yager aggregation operators with application in COVID-19 testing facility. Mathematical Problems in Engineering, 2020: , 1–16. |
18 | Garg, S.K., Versteeg, S., Buyya, R. ((2013) ). A framework for ranking of cloud computing services. Future Generation Computer Systems, 29: (4), 1012–1023. |
19 | Ghorui, N., Mondal, S.P., Chatterjee, B., Ghosh, A., Pal, A., De, D., Giri, B.C. ((2023) ). Selection of cloud service providers using MCDM methodology under intuitionistic fuzzy uncertainty. Soft Computing, 27: (5), 2403–2423. |
20 | Gireesha, O., Somu, N., Krithivasan, K., VS, S.S. ((2020) ). IIVIFS-WASPAS: an integrated Multi-Criteria Decision-Making perspective for cloud service provider selection. Future Generation Computer Systems, 103: , 91–110. |
21 | Gül, S. ((2021) ). Fermatean fuzzy set extensions of SAW, ARAS, and VIKOR with applications in COVID-19 testing laboratory selection problem. Expert Systems, 38: (8), e12769. |
22 | Hang Nguyen, T.M., Nguyen, V.P., Nguyen, D.T. ((2023) ). Selecting cloud database services provider through multi-attribute group decision making: a probabilistic uncertainty linguistics TODIM model. Applied Mathematics in Science and Engineering, 31: (1), 2156502. |
23 | Haque, T.S., Chakraborty, A., Alam, S. ((2023) ). A novel scheme to detect the best cloud service provider using logarithmic operational law in generalized spherical fuzzy environment. Knowledge and Information Systems, 65: , 3695–3724. |
24 | Hussain, A., Chun, J., Khan, M. ((2020) a). A novel customer-centric Methodology for Optimal Service Selection (MOSS) in a cloud environment. Future Generation Computer Systems, 105: , 562–580. |
25 | Hussain, A., Chun, J., Khan, M. ((2020) b). A novel framework towards viable Cloud Service Selection as a Service (CSSaaS) under a fuzzy environment. Future Generation Computer Systems, 104: , 74–91. |
26 | Jafarzadeh Ghoushchi, S., Bonab, S.R., Ghiaci, A.M. ((2023) ). A decision-making framework for COVID-19 infodemic management strategies evaluation in spherical fuzzy environment. Stochastic Environmental Research and Risk Assessment, 37: (4), 1635–1648. |
27 | Jeevaraj, S. ((2021) ). Ordering of interval-valued Fermatean fuzzy sets and its applications. Expert Systems with Applications, 185: , 115613. |
28 | Kao, C. ((2010) ). Weight determination for consistently ranking alternatives in multiple criteria decision analysis. Applied Mathematical Modelling, 34: (7), 1779–1787. |
29 | Keshavarz-Ghorabaee, M., Amiri, M., Hashemi-Tabatabaei, M., Zavadskas, E.K., Kaklauskas, A. ((2020) ). A new decision-making approach based on Fermatean fuzzy sets and WASPAS for green construction supplier evaluation. Mathematics, 8: (12), 2202. |
30 | Khorsand, R., Ghobaei-Arani, M., Ramezanpour, M. ((2019) ). A self-learning fuzzy approach for proactive resource provisioning in cloud environment. Software: Practice and Experience, 49: (11), 1618–1642. |
31 | Krishankumar, R., Ravichandran, K.S., Tyagi, S.K. ((2020) ). Solving cloud vendor selection problem using intuitionistic fuzzy decision framework. Neural Computing and Applications, 32: , 589–602. |
32 | Krishankumar, R., Garg, H., Arun, K., Saha, A., Ravichandran, K.S., Kar, S. ((2021) ). An integrated decision-making COPRAS approach to probabilistic hesitant fuzzy set information. Complex & Intelligent Systems, 7: (5), 2281–2298. |
33 | Krishankumar, R., Pamucar, D., Ravichandran, K.S. ((2022) a). Evidence-based cloud vendor assessment with generalized orthopair fuzzy information and partial weight data. In: q-Rung Orthopair Fuzzy Sets: Theory and Applications. Springer Nature Singapore, Singapore, pp. 197–217. |
34 | Krishankumar, R., Sivagami, R., Saha, A., Rani, P., Arun, K., Ravichandran, K.S. ((2022) b). Cloud vendor selection for the healthcare industry using a big data-driven decision model with probabilistic linguistic information. Applied Intelligence, 52: (12), 13497–13519. |
35 | Krishankumar, R., Ecer, F., Yilmaz, M.K., Deveci, M. ((2023) ). Selection of cloud vendors for medical centers using personalized ranking with evidence-based fuzzy decision-making algorithm. IEEE Transactions on Engineering Management. https://doi.org/10.1109/TEM.2023.3305402. |
36 | Kumar, R.R., Shameem, M., Kumar, C. ((2022) ). A computational framework for ranking prediction of cloud services under fuzzy environment. Enterprise Information Systems, 16: (1), 167–187. |
37 | Mardani, A., Hooker, R.E., Ozkul, S., Yifan, S., Nilashi, M., Sabzi, H.Z., Fei, G.C. ((2019) ). Application of decision making and fuzzy sets theory to evaluate the healthcare and medical problems: a review of three decades of research with recent developments. Expert Systems with Applications, 137: , 202–231. |
38 | Mateen, M., Hayat, S., Tehreem, T., Akbar, M.A. ((2020) ). A self-adaptive resource provisioning approach using fuzzy logic for cloud-based applications. International Journal of Computing and Digital Systems, 9(03). https://doi.org/10.12785/ijcds/090301. |
39 | Mishra, A.R., Rani, P., Krishankumar, R., Zavadskas, E.K., Cavallaro, F., Ravichandran, K.S. ((2021) ). A hesitant fuzzy combined compromise solution framework-based on discrimination measure for ranking sustainable third-party reverse logistic providers. Sustainability, 13: (4), 2064. |
40 | Mishra, A.R., Liu, P., Rani, P. ((2022) a). COPRAS method based on interval-valued hesitant Fermatean fuzzy sets and its application in selecting desalination technology. Applied Soft Computing, 119: , 108570. |
41 | Mishra, A.R., Rani, P., Saha, A., Hezam, I.M., Pamucar, D., Marinović, M., Pandey, K. ((2022) b). Assessing the adaptation of Internet of Things (IoT) barriers for smart cities’ waste management using Fermatean fuzzy combined compromise solution approach. IEEE Access, 10: , 37109–37130. |
42 | Nagarajan, R., Thirunavukarasu, R. ((2019) ). A fuzzy-based decision-making broker for effective identification and selection of cloud infrastructure services. Soft Computing, 23: , 9669–9683. |
43 | Nila, B., Roy, J. ((2023) ). A new hybrid MCDM framework for third-party logistic provider selection under sustainability perspectives. Expert Systems with Applications, 234: , 121009. |
44 | Qiyas, M., Naeem, M., Khan, S., Abdullah, S., Botmart, T., Shah, T. ((2022) ). Decision support system based on CoCoSo method with the picture fuzzy information. Journal of Mathematics, 2022: , 1–11. |
45 | Radhika, E.G., Sadasivam, G.S. ((2021) ). Budget optimized dynamic virtual machine provisioning in hybrid cloud using fuzzy analytic hierarchy process. Expert Systems with Applications, 183: , 115398. |
46 | Rani, P., Mishra, A.R. ((2021) ). Fermatean fuzzy Einstein aggregation operators-based MULTIMOORA method for electric vehicle charging station selection. Expert Systems with Applications, 182: , 115267. |
47 | Rani, P., Ali, J., Krishankumar, R., Mishra, A.R., Cavallaro, F., Ravichandran, K.S. ((2021) ). An integrated single-valued neutrosophic combined compromise solution methodology for renewable energy resource selection problem. Energies, 14: (15), 4594. |
48 | Rani, P., Mishra, A.R., Deveci, M., Antucheviciene, J. ((2022) ). New complex proportional assessment approach using Einstein aggregation operators and improved score function for interval-valued Fermatean fuzzy sets. Computers & Industrial Engineering, 169: , 108165. |
49 | Rizvi, S., Mitchell, J., Razaque, A., Rizvi, M.R., Williams, I. ((2020) ). A fuzzy inference system (FIS) to evaluate the security readiness of cloud service providers. Journal of Cloud Computing, 9: (1). https://doi.org/10.1186/s13677-020-00192-9. |
50 | Saha, A., Pamucar, D., Gorcun, O.F., Mishra, A.R. ((2023) ). Warehouse site selection for the automotive industry using a fermatean fuzzy-based decision-making approach. Expert Systems with Applications, 211: , 118497. |
51 | Satoskar, M.J.S., Patil, B.V., Gala, D.M. ((2023) ). An overview of computing in health care sector. International Research Journal of Modernization in Engineering Technology and Science, 5(5). https://www.doi.org/10.56726/IRJMETS40234. |
52 | Senapati, T., Yager, R.R. ((2020) ). Fermatean fuzzy sets. Journal of Ambient Intelligence and Humanized Computing, 11: , 663–674. |
53 | Sharma, M., Sehrawat, R. ((2020) ). A hybrid multi-criteria decision-making method for cloud adoption: evidence from the healthcare sector. Technology in Society, 61: , 101258. |
54 | Siegel, J., Perdue, J. ((2012) ). Cloud services measures for global use: the Service Measurement Index (SMI). In: SRII ’12: Proceedings of the 2012 Annual SRII Global Conference, pp. 411–415. |
55 | Simic, V., Dabic-Miletic, S., Tirkolaee, E.B., Stević, Ž., Ala, A., Amirteimoori, A. ((2023) ). Neutrosophic LOPCOW-ARAS model for prioritizing Industry 4.0-based material handling technologies in smart and sustainable warehouse management systems. Applied Soft Computing, 143: , 110400. |
56 | Su, D., Zhang, L., Peng, H., Saeidi, P., Tirkolaee, E.B. ((2023) ). Technical challenges of blockchain technology for sustainable manufacturing paradigm in Industry 4.0 era using a fuzzy decision support system. Technological Forecasting and Social Change, 188: , 122275. |
57 | Tripathi, D.K., Nigam, S.K., Rani, P., Shah, A.R. ((2023) ). New intuitionistic fuzzy parametric divergence measures and score function-based CoCoSo method for decision-making problems. Decision Making: Applications in Management and Engineering, 6: (1), 535–563. |
58 | Ulutaş, A., Balo, F., Topal, A. ((2023) ). Identifying the most efficient natural fibre for common commercial building insulation materials with an integrated PSI, MEREC, LOPCOW and MCRAT model. Polymers, 15: (6), 1500. |
59 | Wen, Z., Liao, H., Ren, R., Bai, C., Zavadskas, E.K., Antucheviciene, J., Al-Barakati, A. ((2019) ). Cold chain logistics management of medicine with an integrated multi-criteria decision-making method. International Journal of Environmental Research and Public Health, 16: (23), 4843. |
60 | Yager, R.R. ((2016) ). Properties and applications of Pythagorean fuzzy sets. In: Imprecision and Uncertainty in Information Representation and Processing, Studies in Fuzziness and Soft Computing, Vol. 332: . Springer, Cham, pp. 119–136. https://doi.org/10.1007/978-3-319-26302-1_9. |
61 | Yazdani, M., Zarate, P., Zavadskas, E.K., Turskis, Z. ((2019) ). A combined compromise solution (CoCoSo) method for multi-criteria decision-making problems. Management Decision, 57: (9), 2501–2519. |
62 | Zaman, M., Ghani, F., Khan, A., Abdullah, S., Khan, F. ((2023) ). Complex Fermatean fuzzy extended TOPSIS method and its applications in decision making. Heliyon, 9: (9), e19170. |
63 | Zeng, S., Gu, J., Peng, X. ((2023) ). Low-carbon cities comprehensive evaluation method based on Fermatean fuzzy hybrid distance measure and TOPSIS. Artificial Intelligence Review, 56: , 8591–8607. |
64 | Zhang, H., Wei, G. ((2023) ). Location selection of electric vehicles charging stations by using the spherical fuzzy CPT–CoCoSo and D-CRITIC method. Computational and Applied Mathematics, 42: (1), 60. |
65 | Zhou, X., Zhang, G., Sun, J., Zhou, J., Wei, T., Hu, S. ((2019) ). Minimizing cost and makespan for workflow scheduling in cloud using fuzzy dominance sort based HEFT. Future Generation Computer Systems, 93: , 278–289. |
66 | Zhu, Y., Zeng, S., Lin, Z., Ullah, K. ((2023) ). Comprehensive evaluation and spatial-temporal differences analysis of China’s inter-provincial doing business environment based on Entropy-CoCoSo method. Frontiers in Environmental Science, 10: , 1088064. |


