
The ten commandments of translational research informatics
Abstract
Translational research applies findings from basic science to enhance human health and well-being. In translational research projects, academia and industry work together to improve healthcare, often through public-private partnerships. This “translation” is often not easy, because it means that the so-called “valley of death” will need to be crossed: many interesting findings from fundamental research do not result in new treatments, diagnostics and prevention. To cross the valley of death, fundamental researchers need to collaborate with clinical researchers and with industry so that promising results can be implemented in a product. The success of translational research projects often does not depend only on the fundamental science and the applied science, but also on the informatics needed to connect everything: the translational research informatics. This informatics, which includes data management, data stewardship and data governance, enables researchers to store and analyze their ‘big data’ in a meaningful way, and enable application in the clinic. The author has worked on the information technology infrastructure for several translational research projects in oncology for the past nine years, and presents his lessons learned in this paper in the form of ten commandments. These commandments are not only useful for the data managers, but for all involved in a translational research project. Some of the commandments deal with topics that are currently in the spotlight, such as machine readability, the FAIR Guiding Principles and the GDPR regulations. Others are mentioned less in the literature, but are just as crucial for the success of a translational research project.
1.Introduction
Translational research applies findings from basic science to enhance human health and well-being. In a medical research context, it aims to “translate” findings in fundamental research into medical practice and meaningful health outcomes. In translational research projects, academia and industry work together to improve healthcare, often through public-private partnerships [28]. This “translation” is often not easy, because it means that the so-called “valley of death” [4] will need to be crossed: many interesting findings from fundamental research do not result in new treatments, diagnostics and prevention. To cross the valley of death, fundamental researchers need to collaborate with clinical researchers and with industry so that promising results can be implemented in a product. Examples of initiatives supporting translational research are EATRIS [3], the European Infrastructure for Translational Medicine and NCATS [24], the National Center for Advancing Translational Sciences in the USA.
The success of translational research projects often does not depend only on the fundamental science and the applied science, but also on the informatics needed to connect everything: the ‘translational research informatics’. This type of informatics was first described in 2005 by Payne et al. [36], as the intersection between biomedical informatics and translational research. Translational research informatics should enable the researchers to store and analyze their ‘big data’ in a meaningful way, and enable application in the clinic [19]. This translational research informatics field includes data management, data stewardship and data governance, which are receiving more attention recently. Data management (in research) is the care and maintenance of the data that are produced during the course of a research cycle. It is an integral part of the research process and helps to ensure that your data are properly organized, described, preserved, and shared [40]. Data management ensures that the story of a researcher’s data collection process is organized, understandable, and transparent [48]. According to Rosenbaum, 2010 [41], data stewardship is a concept with deep roots in the science and practice of data collection, sharing, and analysis. It denotes an approach to the management of data, particularly data that can identify individuals. Data governance is the process by which responsibilities of stewardship are conceptualized and carried out. Perrier et al. (2017) presents an extensive overview of 301 articles on data management, distributed over the six phases of the Research Data Lifecycle [15]: (1) Creating Data, (2) Processing Data, (3) Analysing Data, (4) Preserving Data, (5) Giving Access to Data and (6) Re-Using Data. It shows that most publications focus on phases 4 to 6 (especially phase 5), but not so much on phases 1 to 3, while these are equally important.
The author has worked on the information technology (IT) infrastructure, data integration and data management for several translational research projects in oncology [20–22,27,39] for the past nine years, as well as on a large Dutch translational research informatics project [32], and presents his lessons learned in this paper in the form of ten commandments. These commandments are not only useful for the data managers, but for all involved in a translational research project, since they touch upon crucial elements such as data quality, data access and sustainability, and cover all phases of the research data lifecycle. As opposed to most publications in the field of data management, this article even puts an emphasis on the early phases of the research data lifecycle.
2.The ten commandments
2.1.Commandment 1: Create a separate data management work package
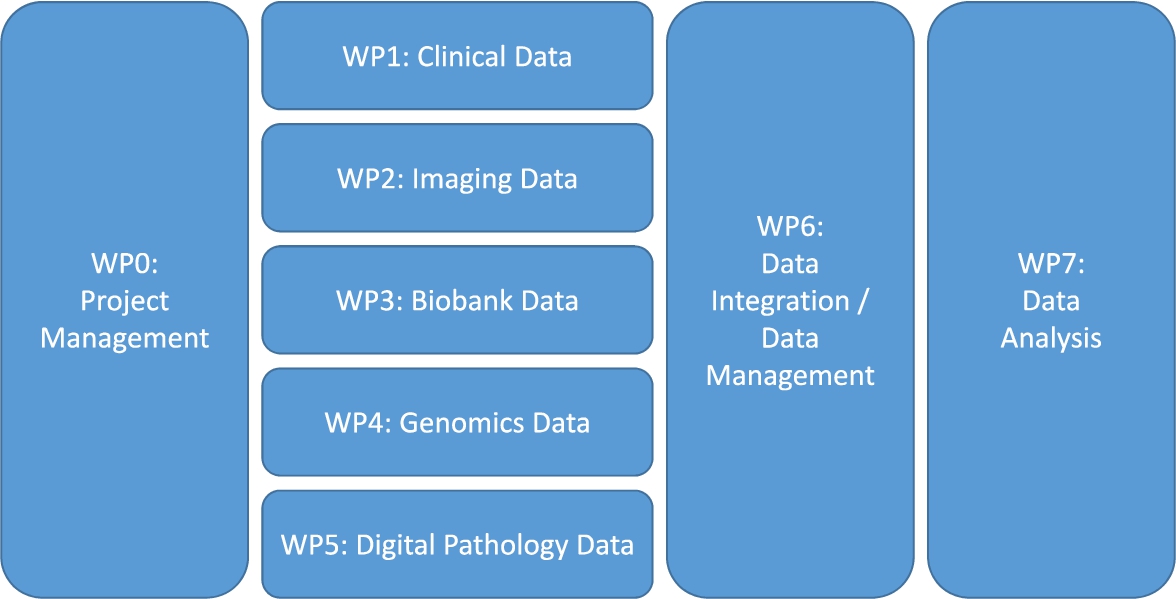
When clinicians, biologists and other researchers come together in a translational research project, they often do not think about data management, data curation, data integration and the IT infrastructure, except for when it is already too late: the data sit on several computers scattered over different organizations, and nobody knows how to combine them and make sense of them. The solution: create a separate work package or work stream on data management. This work package can be thought of as a sub-project, which has its own goal (or even a list of milestones and deliverables) and has full-time equivalents (FTEs) and other financial resources allocated. Within this work package, a data management plan (DMP) will be created which describes exactly how the data management will take place (such a DMP is obligated nowadays in several funding programmes such as Horizon 2020 [17], and with good reason). Since this data management work package will have touchpoints with the other (data generating) work packages, the data management work package leader needs to be involved in all project meetings. It is also advised to create a separate work package on data analysis, which gets its input from the data management / data integration work package (Fig. 1).
Fig. 1.
A proposed work package (WP) structure for a translational research project.
2.2.Commandment 2: Reserve time and money for data entry
Investigators tasked with generating the hypotheses may not have the expertise to understand the complexities of processing and managing data that are not clean and ready for analysis. For example, they usually lack knowledge about an Electronic Data Capture (EDC) system such as OpenClinica [35], Castor EDC [6] or REDCap [16], as part of work package 1 in Fig. 1. This work is often assigned to trial nurses, who usually already have a high workload. The data entry work is on the bottom of their priority list, which can cause delays and even errors. Which is a large concern, because data quality is an important matter when it comes to data analysis [5]. Even when the data are extracted from an Electronic Health Record (EHR) and entered into the EDC system automatically, this needs to be checked by someone. The term “Garbage in, garbage out” (GIGO) comes from computer science, but applies to medical data as well [26]. The solution here is to reserve money to hire people who can do this job for a certain amount of hours per week. By spending relatively little money on data entry, one can save a lot of time and money by not having to redo analyses because of missing or erroneous data.
This commandment does not apply to just clinical data but to the other data types as well: imaging and digital pathology data often need to be annotated, biobank data usually need to be exported from a Laboratory Information Management System (LIMS), and raw genomics data need to be processed first before they can be used in an integrated database. All these steps need sufficient resources to make sure that they are executed correctly.
2.3.Commandment 3: Define all data fields up front together with the help of data analysis experts
Within the Prostate Cancer Molecular Medicine (PCMM [20]) project, we noticed after a few years that some information that was essential to answer certain research questions was not being collected in the electronic case report form (eCRF). A second eCRF needed to be constructed, which resulted in a lot of time being spent on going back to the patient’s entries in the hospital system and collecting the data, if they were there at all. We learned our lesson. Within the Movember Global Action Plan 3 (GAP3) project [21], all parties together created the Movember GAP3 codebook, which was an extensive list of data fields designed to answer all research questions that we could think of at the start of the project. The statisticians within the project were very much involved in the codebook creation, because they had the clearest insights on what was needed here. Besides the data field name, we stored the data type (integer, float, string, categorical, etc.) and the unit (days, years, cm, kg, kg/m2, ng/ml, etc.), and (in case of a categorical data type) listed the categories (e.g. the TNM staging system). In case of a derived data field, the codebook explains how this data field is calculated. Examples here are data fields such as age, BMI and days since diagnosis. Because part of the Movember GAP3 data was retrospective, we created some data model mapping scripts [23] to map the existing data to this codebook, as well as some data curation scripts that check if the data fall into the expected range and do not contain any discrepancies.
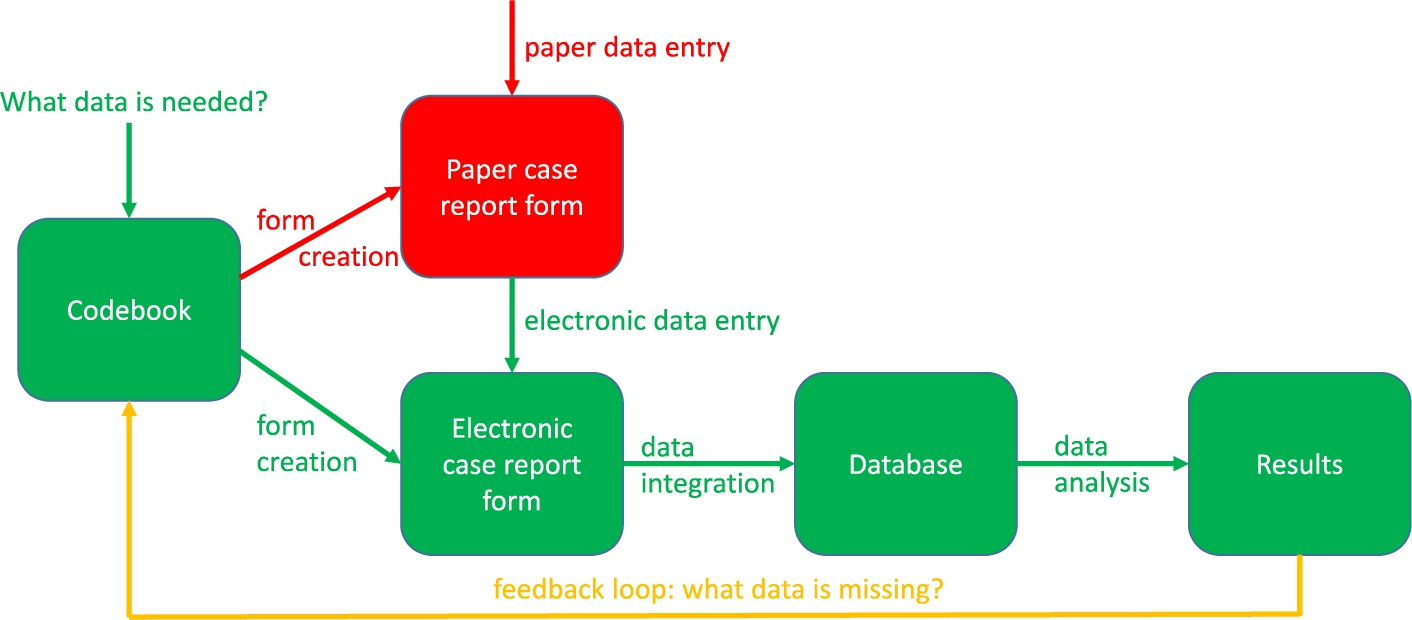
Figure 2 describes the clinical data collection process. The green parts are these steps of the process that are necessary, whereas the red parts are steps that are unnecessary in modern translational research. The green parts include the construction of the codebook, the eCRF creation, the data entry into the eCRF, the data integration into the database and the data analysis leading to results. The red parts include the creation of and the data entry into the paper CRF, which ideally should be avoided because this gives the data entry person double work. The information should be entered directly into the eCRF instead. The yellow line should only be followed when, even after carefully constructing the codebook, more data fields need to be included. Ideally, the codebook should also be compliant with ontologies for translational research such as the Basic Formal Ontology (BFO), the ontologies listed by the Open Biological and Biomedical Ontology (OBO) foundry and the Relation Ontology (RO) [46].
Fig. 2.
The clinical data collection process.
Other data types that are important in translational research, as listed in Fig. 1 (WP 2–5), often do not need a codebook because they are stored in standardized file formats such as Digital Imaging and Communications in Medicine (DICOM, for imaging and digital pathology data). However, information derived from these data types, such as PI-RADS scores (from prostate cancer MR images) and Gleason scores (from prostate cancer digital pathology images) should be stored in the codebook as well, to ensure that these values can be compared with the clinical data gathered in the eCRF.
2.4.Commandment 4: Make clear arrangements about data access
In large consortia, especially consortia with both academic partners and commercial partners, data access can be a sensitive issue. Therefore, it needs a clear arrangement up front. Of course, data access needs to be arranged in the informed consent as well, as patients are the data owners, and the General Data Protection Regulation (GDPR [10], within the EU) and the Health Insurance Portability and Accountability Act (HIPAA [12], within the US) have strict regulations about the patient’s privacy. The GDPR puts some constraints on data sharing, e.g., if a data controller wants to share data with a third party, and that third party is a processor, then a Data Processor Agreement (DPA) needs to be created. Furthermore, the informed consent that the patient signs before participating in a study needs to state clearly for what purposes their data will be used.
Ideally, at the end of the project, when all goals have been met and results have been published, the de-identified data should be shared with the whole world, if privacy regulations allow it. After all, the goal of a translational research project is to “translate” findings in fundamental research into medical practice and meaningful health outcomes, which can only be achieved if data are being shared as soon as possible, because then the whole world can use the data. This future public availability of the data should be included in the informed consent as well. As GDPR article 4 [10] states that “consent of the data subject means any freely given, specific, informed and unambiguous indication of the data subject’s wishes by which he or she, by a statement or by a clear affirmative action, signifies agreement to the processing of personal data relating to him or her”, this means that there should be a “yes/no” question or checkbox for the option to share the data in a public repository at the end of the study. If the patient answers “no” or does not check the box, the patient should still be allowed to enter the study, but his/her data cannot be submitted to a public repository.
2.5.Commandment 5: Agree about de-identification and anonymization
The responsibility for proper de-identification of the data often lies with the organization that collects the data (usually the hospital), because they are the ones that have the EHR. They should create a study subject ID for each subject, which can only be mapped to the original subject ID by a mapping table residing at the hospital. If the party performing the data integration receives data that are not properly de-identified by the hospital, the data should be destroyed immediately, the breach should be reported, and a new data submission should be requested. If a subject at any time requests to have his/her data removed from the central database, the hospital should inform the data manager about which data belonging to which study subject ID need to be removed. In the case that the data integration expert also needs to do the de-identification and anonymization, this should be arranged very clearly in the informed consent and the data processor agreement. For textual and numerical data, open-source software packages are available that can help with anonymization, such as the ARX anonymization tool [38]. For imaging data, anonymization tools are available that can strip any identifiable information from DICOM tags, such as the DICOM anonymizer [8] and the DicomCleaner [9].
2.6.Commandment 6: Reuse existing software where possible
There is usually no need to develop tools for data capturing, data management, data quality control, etc. from scratch, because there are many open source tools available for this, which can not only be used freely but also developed further. Within the Translational Research IT (TraIT) project [32] of the Center for Translational Molecular Medicine (CTMM), a list of suitable open source tools was created, which included OpenClinica [35], XNAT [29] and tranSMART [43]. For areas where there was no tool available, software was created. An overview of the TraIT tools can be found at https://trait.health-ri.nl/trait-tools/. Most translational research projects have similar problems, so when starting a new project, it is generally a good idea to see how they solved these problems, and if their solution can be reused. This reusability also increases the reproducibility of the research, because there is no reliance on obscure, custom-made computer scripts or websites. Table 1 shows an up-to-date list of freely available software related to translational research, including a description and the main data type it processes. This list was created by combining the overview of TraIT tools with an extensive PubMed search. It might be out of date soon, but provides a useful summary of the currently available tools.
Table 1
Freely available software in the area of translational research informatics
| Name | Main data type | Description | URL |
| cBioPortal [11] | Genomics | The open source cBioPortal for Cancer Genomics provides visualization, analysis, and download of large-scale cancer genomics data sets. A public instance of cBioPortal (https://www.cbioportal.org) is hosted and maintained by Memorial Sloan Kettering Cancer Center. It provides access to data by The Cancer Genome Atlas as well as many carefully curated published data sets. The cBioPortal software can be used to create local instances that provide access to private data. | https://github.com/cBioPortal/ |
| Dicoogle [7] | Imaging | Dicoogle is an open source Picture Archiving and Communications System (PACS) archive. Its modular architecture allows the quick development of new functionalities, due to the availability of a Software Development Kit (SDK). | http://www.dicoogle.com/ |
| Galaxy [1] | Genomics | Galaxy is a scientific workflow, data integration, and digital preservation platform that aims to make computational biology accessible to research scientists that do not have computer programming or systems administration experience. Although it was initially developed for genomics research, it is largely domain agnostic and is now used as a general bioinformatics workflow management system. | https://usegalaxy.org/ |
| I2B2 [33] | Clinical | Informatics for Integrating Biology and the Bedside (i2b2) is one of the sponsored initiatives of the NIH Roadmap National Centers for Biomedical Computing. One of the goals of i2b2 is to provide clinical investigators with the software tools necessary to collect and manage project-related clinical research data in the genomics age as a cohesive entity; a software suite to construct and manage the modern clinical research chart. | https://www.i2b2.org/ |
| Occhiolino [34] | Biobank | GNU LIMS, also known as Occhiolino is an open source laboratory information management system (LIMS), aiming for healthcare laboratories. It is fully compatible with GNU-Health with complete workflow process control integration. | http://lims.gnu.org/ |
| OpenClinica Community Edition [35] | Clinical | The world’s first commercial open source clinical trial software serving for the purpose of clinical data management and electronic data capture. | https://www.openclinica.com/ |
| OpenSpecimen [30] | Biobank | The OpenSpecimen LIMS application allows bio-repositories to track biospecimens from collection to utilization across multiple projects, collect annotations, storage containers, track requests and distribution, and has multiple reporting options. It streamlines management across collection, consent, quality control, request and distribution and is highly configurable and customizable. | https://www.openspecimen.org/ |
| Orthanc [25] | Imaging | Orthanc aims at providing a simple, yet powerful standalone DICOM server. It is designed to improve the DICOM flows in hospitals and to support research about the automated analysis of medical images. | https://www.orthanc-server.com/ |
| QuPath [2] | Digital pathology | QuPath is new bioimage analysis software designed to meet the growing need for a user-friendly, extensible, open-source solution for digital pathology and whole slide image analysis. | https://qupath.github.io/ |
| REDCap [16] | Clinical | REDCap (Research Electronic Data Capture) is a browser-based, metadata-driven electronic data capture software solution and workflow methodology for designing clinical and translational research databases. Development of the software takes place by collaborative software development through the REDCap consortium. | https://projectredcap.org/ |
| SlideAtlas [45] | Digital pathology | SlideAtlas is an open-source, web-based, whole slide imaging platform. It provides features for multiple stages of a digital pathology workflow, including automated image uploading, image organization and management, automatic alignment and high-performance viewing of 3D image stacks, online annotation/markup and collaborative viewing of images. | https://slide-atlas.org/ |
| tranSMART [43] | Integration | tranSMART is a suite of data exploration, visualization, and extract-transform-load (ETL) tools, which were originally developed by Johnson & Johnson for translational research studies. The software was released in 2012 as an open-source platform. It continues to be developed and maintained by a community effort, coordinated by the i2b2 tranSMART Foundation. | https://transmartfoundation.org/current-transmart-platform-release/ |
| XNAT [29] | Imaging | XNAT is an open-source imaging informatics software platform dedicated to helping perform imaging-based research. XNAT’s core functions manage importing, archiving, processing and securely distributing imaging and related study data. | https://www.xnat.org/ |
2.7.Commandment 7: Make newly created software reusable
Although it is proposed at commandment 6 that existing software should be reused as much as possible, there might be cases where study-specific software needs to be created, for example to perform novel analyses. If there are no intellectual property issues, this newly created software can be submitted to repositories such as GitHub [37], SourceForge [47] or FigShare [44], or it can be made available on a custom-made website, and then referenced on Zenodo [52]. Griffin et al. [13] gives a good overview of the possibilities. This way, future translational researchers can reuse the software and do not need to reinvent the wheel. Github already hosts several scientific data management packages, such as Rucio (https://github.com/rucio/rucio), ISA tools (https://github.com/ISA-tools/isa-api) and Clowder (https://github.com/ncsa/clowder). There is also an overview of all 1,720 bioinformatics repositories on GitHub available [42]. If the software is submitted to one of these popular repositories, and it is accompanied with metadata that describes accurately what the software can do, it will be much easier for researchers to find the software and share it with other potential users.
2.8.Commandment 8: Adhere to the FAIR guiding principles
In 2016, the FAIR Guiding Principles for scientific data management and stewardship [50] were published. FAIR stands for the four foundational principles – Findability, Accessibility, Interoperability, and Reusability – that serve to guide data producers and publishers as they navigate around the obstacles around data management and stewardship. The difference with similar initiatives is that the FAIR principle do not only support the reuse of data by individuals, but also put emphasis on enhancing the ability of machines to automatically find and use the data. The elements of the FAIR Guiding Principles are related, but independent and separable:
– Findability is about making sure that the data can be found, e.g. by using a unique and persistent identifier and by the use of rich metadata which is registered or indexed in a searchable resource.
– Accessibility refers to the retrievability of the data and metadata by their identifier using a standardized communications protocol, and the access to the metadata even when the data are no longer available.
– Interoperability is about the usage of ontologies, vocabularies and qualified references to other (meta)data so that the data can be integrated with other data.
– Reusability refers to describing the (meta)data with a plurality of accurate and relevant attributes, releasing with a clear and accessible data usage license, etc., in order to enable reuse of the data.
The FAIR Guiding Principles should be applied to both data and software created in a translational research project, to achieve transparency and scientific reproducibility. An example of a FAIR-compliant dataset, is the Rembrandt brain cancer dataset [14]. This dataset is ‘findable’: it is hosted in the Georgetown Database of Cancer (G-DOC), with provenance and raw data available in the National Institute of Health (NIH) Gene Expression Omnibus (GEO) data repository. These resources are publicly available and thus ‘accessible’. The gene expression and copy number data are in standard data matrix formats that support formal sharing and satisfy the ‘interoperable’ condition. Finally, this dataset can be ‘reused’ for additional research through either the G-DOC platform or GEO.
2.9.Commandment 9: Make sure that successors are being instructed correctly
Translational research projects usually take 4 to 5 years. Clinicians, researchers and data managers, but also trial nurses, might come and go during this period. If these trial nurses performed the data entry for the study, they probably spent quite some time learning how to enter data into the eCRF. To avoid that the new data entry person needs to spend a similar amount of time to learn about this data entry, the old data entry person should properly instruct the new person, reducing the learning time. The same holds for the data managers. The leader of the data management work package (see commandment 1) might even make a data entry manual together with the data entry person, to ensure that any transfers of data entry tasks will go smoothly. As stated in commandment 2: data quality is extremely important and thus correct data entry should be a priority.
2.10.Commandment 10: Make it sustainable: What happens after the project?
When starting a new translational research project, big plans are made for the duration of the project, but very often not so much for the period after. What will happen when the project is finished? For example: who will pay for the continued storage of left-over biomaterials? Who will keep the database running? The researchers might even want to continue the project with yearly updates, because long-term follow-up information could be very valuable in these type of projects. Or they want to submit the data to a repository such as Dataverse [31] or Dryad [49], if the informed consent allows it. Publicly available datasets can be a goldmine for future research [18], certainly with the rise of artificial intelligence methods. At the start of the project, the researchers should already make a plan for what happens at the end of the study, when funding runs out, to avoid that data and biomaterials are lost for future research. This planning should also include a financial paragraph, because hosting of data (and storage of biomaterials) will need to be financed somehow, especially if the data are not submitted to a public repository.
Table 2
Summary of the ten commandments of translational research informatics
| 1 | Create a separate data management work package |
| 2 | Reserve time and money for data entry |
| 3 | Define all data fields up front with the help of data analysis experts |
| 4 | Make clear arrangements about data access |
| 5 | Agree about de-identification and anonymization |
| 6 | Reuse existing software where possible |
| 7 | Make newly created software reusable |
| 8 | Adhere to the FAIR Guiding Principles |
| 9 | Make sure that successors are being instructed correctly |
| 10 | Make it sustainable: what happens after the project? |
3.Summary and conclusions
Translational research informatics is a field that is linked to data science and big data analytics, because of the ever growing size of the datasets and the need for analysis by machines. This means that the research output generated by the studies should be machine-readable, i.e. properly described by metadata, standardized according to ontologies, etc. [50]. The field is also heavily influenced by new privacy laws such as the GDPR: the infrastructure that is created needs to comply with stricter security and privacy rules than ever before. More emphasis is being placed on the importance of de-identification, pseudonymization and anonymization, certainly now that there is a trend to connect translational research informatics systems directly to the EHR [51], which contains personal data. Moreover, security measures such as multi-factor authentication (MFA) and data encryption are getting more common. The ten commandments presented in this article (see Table 2 for the summary) reflect the current state of the field, and might be subject change in a rapidly developing field. The rise of ‘open science’ and, related to this, the FAIR Guiding Principles, gives much-needed attention to data sharing, reuse of data and methods, and reproducibility. In some funding programs, such as Horizon 2020 from the EU, projects are already instructed to adhere to the FAIR Guiding Principles, and to create a Data Management Plan (DMP) which helps to think about data sharing, what will happen to the data after the project, etc. The other commandments listed here are mentioned less in the literature, but are just as crucial for the success of a translational research project.
Competing interest statement
Dr. Hulsen is employed by Philips Research.
Disclaimer
This manuscript reflects an interpretation of the GDPR by the author, who is not a legal expert.
References
[1] | E. Afgan, D. Baker, B. Batut, M. van den Beek, D. Bouvier, M. Cech, J. Chilton, D. Clements, N. Coraor, B.A. Gruning, A. Guerler, J. Hillman-Jackson, S. Hiltemann, V. Jalili, H. Rasche, N. Soranzo, J. Goecks, J. Taylor, A. Nekrutenko and D. Blankenberg, The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update, Nucleic Acids Res 46: ((2018) ), W537–W544. 29790989. doi:10.1093/nar/gky379. |
[2] | P. Bankhead, M.B. Loughrey, J.A. Fernandez, Y. Dombrowski, D.G. McArt, P.D. Dunne, S. McQuaid, R.T. Gray, L.J. Murray, H.G. Coleman, J.A. James, M. Salto-Tellez and P.W. Hamilton, QuPath: Open source software for digital pathology image analysis, Sci Rep 7: ((2017) ), 16878. 29203879. doi:10.1038/s41598-017-17204-5. |
[3] | R. Becker and G.A. van Dongen, EATRIS, a vision for translational research in Europe, J Cardiovasc Transl Res 4: ((2011) ), 231–237. 21544739. doi:10.1007/s12265-011-9260-8. |
[4] | D. Butler, Translational research: Crossing the valley of death, Nature 453: ((2008) ), 840–842. 18548043. doi:10.1038/453840a. |
[5] | L. Cai and Y. Zhu, The challenges of data quality and data quality assessment in the big data era, Data Science Journal 14: ((2015) ), 2. doi:10.5334/dsj-2015-002. |
[6] | Castor, Castor EDC – Cloud-based electronic data capture platform, https://www.castoredc.com. |
[7] | C. Costa, C. Ferreira, L. Bastiao, L. Ribeiro, A. Silva and J.L. Oliveira, Dicoogle – An open source peer-to-peer PACS, J Digit Imaging 24: ((2011) ), 848–856. 20981467. doi:10.1007/s10278-010-9347-9. |
[8] | DICOM Anonymizer, https://dicomanonymizer.com/. |
[9] | DicomCleaner, http://www.dclunie.com/pixelmed/software/webstart/DicomCleanerUsage.html. |
[10] | The European Parliament and the Council of the European Union, Regulation on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (Data Protection Directive), Official Journal of the European Union 59: ((2016) ), 1–88. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJ:L:2016:119:TOC. |
[11] | J. Gao, B.A. Aksoy, U. Dogrusoz, G. Dresdner, B. Gross, S.O. Sumer, Y. Sun, A. Jacobsen, R. Sinha, E. Larsson, E. Cerami, C. Sander and N. Schultz, Integrative analysis of complex cancer genomics and clinical profiles using the cBioPortal, Sci Signal 6: ((2013) ), pl1. 23550210. doi:10.1126/scisignal.2004088. |
[12] | U.S. Government, Health Insurance Portability and Accountability Act Of 1996, https://www.govinfo.gov/content/pkg/PLAW-104publ191/html/PLAW-104publ191.htm. |
[13] | P.C. Griffin, J. Khadake, K.S. LeMay, S.E. Lewis, S. Orchard, A. Pask, B. Pope, U. Roessner, K. Russell, T. Seemann, A. Treloar, S. Tyagi, J.H. Christiansen, S. Dayalan, S. Gladman, S.B. Hangartner, H.L. Hayden, W.W.H. Ho, G. Keeble-Gagnere, P.K. Korhonen, P. Neish, P.R. Prestes, M.F. Richardson, N.S. Watson-Haigh, K.L. Wyres, N.D. Young and M.V. Schneider, Best practice data life cycle approaches for the life sciences, F1000Res 6: ((2017) ), 1618. 30109017. doi:10.12688/f1000research.12344.1. |
[14] | Y. Gusev, K. Bhuvaneshwar, L. Song, J.C. Zenklusen, H. Fine and S. Madhavan, The REMBRANDT study, a large collection of genomic data from brain cancer patients, Sci Data 5: ((2018) ), 180158. 30106394. doi:10.1038/sdata.2018.158. |
[15] | Handbook for adequate natural data stewardship (HANDS) – Data stewardship, https://data4lifesciences.nl/hands2/data-stewardship/. |
[16] | P.A. Harris, R. Taylor, R. Thielke, J. Payne, N. Gonzalez and J.G. Conde, Research electronic data capture (REDCap) – A metadata-driven methodology and workflow process for providing translational research informatics support, J Biomed Inform 42: ((2009) ), 377–381. 18929686. doi:10.1016/j.jbi.2008.08.010. |
[17] | Horizon 2020 – The EU framework programme for research and innovation, https://ec.europa.eu/programmes/horizon2020/en. |
[18] | T. Hulsen, An overview of publicly available patient-centered prostate cancer datasets, Transl Androl Urol 8: ((2019) ), S64–S77. 31143673. doi:10.21037/tau.2019.03.01. |
[19] | T. Hulsen, S.S. Jamuar, A.R. Moody, J.H. Karnes, O. Varga, S. Hedensted, R. Spreafico, D.A. Hafler and E.F. McKinney, From big data to precision medicine, Front Med (Lausanne) 6: ((2019) ), 34. 30881956. doi:10.3389/fmed.2019.00034. |
[20] | T. Hulsen, J.H. Obbink, E.A.M. Schenk, M.F. Wildhagen and C.H. Bangma, PCMM Biobank, IT-infrastructure and decision support, 2013. http://tim.hulsen.net/documents/pcmm_wp3_130912.pdf. doi:10.13140/RG.2.2.32121.01123. |
[21] | T. Hulsen, J.H. Obbink, W. Van der Linden, C. De Jonge, D. Nieboer, S.M. Bruinsma, M.J. Roobol and C.H. Bangma, 958 integrating large datasets for the Movember Global Action Plan on active surveillance for low risk prostate cancer, European Urology Supplements 15: ((2016) ), e958. doi:10.1016/S1569-9056(16)60959-4. |
[22] | T. Hulsen, W. Van der Linden, C. De Jonge, J. Hugosson, A. Auvinen and M.J. Roobol, Developing a future-proof database for the European randomized study of screening for prostate cancer (ERSPC), European Urology Supplements 18: ((2019) ), e1766. 9088276. doi:10.1016/S1569-9056(19)31278-3. |
[23] | T. Hulsen, W. Van der Linden, D. Pletea, J.H. Obbink and M.J. Quist, Data model mapping, 2017. https://patentscope.wipo.int/search/en/detail.jsf?docId=WO2017167628. |
[24] | CTSA Principal Investigators, H. Shamoon, D. Center, P. Davis, M. Tuchman, H. Ginsberg, R. Califf, D. Stephens, T. Mellman, J. Verbalis, L. Nadler, A. Shekhar, D. Ford, R. Rizza, R. Shaker, K. Brady, B. Murphy, B. Cronstein, J. Hochman, P. Greenland, E. Orwoll, L. Sinoway, H. Greenberg, R. Jackson, B. Coller, E. Topol, L. Guay-Woodford, M. Runge, R. Clark, D. McClain, H. Selker, C. Lowery, S. Dubinett, L. Berglund, D. Cooper, G. Firestein, S.C. Johnston, J. Solway, J. Heubi, R. Sokol, D. Nelson, L. Tobacman, G. Rosenthal, L. Aaronson, R. Barohn, P. Kern, J. Sullivan, T. Shanley, B. Blazar, R. Larson, G. FitzGerald, S. Reis, T. Pearson, T. Buchanan, D. McPherson, A. Brasier, R. Toto, M. Disis, M. Drezner, G. Bernard, J. Clore, B. Evanoff, J. Imperato-McGinley, R. Sherwin and J. Pulley, Preparedness of the CTSA’s structural and scientific assets to support the mission of the National Center for Advancing Translational Sciences (NCATS), Clin Transl Sci 5: ((2012) ), 121–129. 22507116. doi:10.1111/j.1752-8062.2012.00401.x. |
[25] | S. Jodogne, The Orthanc ecosystem for medical imaging, J Digit Imaging 31: ((2018) ), 341–352. 29725964. doi:10.1007/s10278-018-0082-y. |
[26] | M.F. Kilkenny and K.M. Robinson, Data quality: “Garbage in–garbage out”, Health Inf Manag 47: ((2018) ), 103–105. 29719995. doi:10.1177/1833358318774357. |
[27] | LIMA – Liquid biopsies and imaging, https://lima-project.eu/. |
[28] | P.R. Luijten, G.A. van Dongen, C.T. Moonen, G. Storm and D.J. Crommelin, Public-private partnerships in translational medicine: Concepts and practical examples, J Control Release 161: ((2012) ), 416–421. 22465390. doi:10.1016/j.jconrel.2012.03.012. |
[29] | D.S. Marcus, T.R. Olsen, M. Ramaratnam and R.L. Buckner, The extensible neuroimaging archive toolkit: An informatics platform for managing, exploring, and sharing neuroimaging data, Neuroinformatics 5: ((2007) ), 11–34. 17426351. doi:10.1385/NI:5:1:11. |
[30] | L.D. McIntosh, M.K. Sharma, D. Mulvihill, S. Gupta, A. Juehne, B. George, S.B. Khot, A. Kaushal, M.A. Watson and R. Nagarajan, caTissue Suite to OpenSpecimen: Developing an extensible, open source, web-based biobanking management system, J Biomed Inform 57: ((2015) ), 456–464. 26325296. doi:10.1016/j.jbi.2015.08.020. |
[31] | B. McKinney, P.A. Meyer, M. Crosas and P. Sliz, Extension of research data repository system to support direct compute access to biomedical datasets: Enhancing dataverse to support large datasets, Ann N Y Acad Sci 1387: ((2017) ), 95–104. 27862010. doi:10.1111/nyas.13272. |
[32] | G.A. Meijer, J.W. Boiten, J.A.M. Beliën, H.M.W. Verheul, M.N. Cavelaars, A. Dekker, P. Lansberg, R.J.A. Fijneman, W. Van der Linden, R. Azevedo and N. Stathonikos, TraIT – Translational research IT, 2017. https://trait.health-ri.nl/TraITbookletFinalHR.pdf. |
[33] | S.N. Murphy, G. Weber, M. Mendis, V. Gainer, H.C. Chueh, S. Churchill and I. Kohane, Serving the enterprise and beyond with informatics for integrating biology and the bedside (i2b2), J Am Med Inform Assoc 17: ((2010) ), 124–130. 20190053. doi:10.1136/jamia.2009.000893. |
[34] | Occhiolino – Laboratory information management system for healthcare and biomedicine, http://lims.gnu.org. |
[35] | OpenClinica – Electronic data capture for clinical research, https://www.openclinica.com. |
[36] | P.R. Payne, S.B. Johnson, J.B. Starren, H.H. Tilson and D. Dowdy, Breaking the translational barriers: The value of integrating biomedical informatics and translational research, J Investig Med 53: ((2005) ), 192–200. 15974245. doi:10.2310/6650.2005.00402. |
[37] | J. Perkel, Democratic databases: Science on GitHub, Nature 538: ((2016) ), 127–128. 27708327. doi:10.1038/538127a. |
[38] | F. Prasser, F. Kohlmayer, R. Lautenschlager and K.A. Kuhn, ARX – A comprehensive tool for anonymizing biomedical data, AMIA Annu Symp Proc 2014: ((2014) ), 984–993. 25954407. |
[39] | RE-IMAGINE – Correcting five decades of error through enabling image-based risk stratification of localised prostate cancer, https://www.reimagine-pca.org/. |
[40] | Research data management (a how-to guide): Research data management definition, https://libguides.depaul.edu/c.php?g=620925&p=4324498. |
[41] | S. Rosenbaum, Data governance and stewardship: Designing data stewardship entities and advancing data access, Health Serv Res 45: ((2010) ), 1442–1455. 21054365. doi:10.1111/j.1475-6773.2010.01140.x. |
[42] | P.H. Russell, R.L. Johnson, S. Ananthan, B. Harnke and N.E. Carlson, A large-scale analysis of bioinformatics code on GitHub, PLoS One 13: ((2018) ), e0205898. 30109017. doi:10.1371/journal.pone.0205898. |
[43] | E. Scheufele, D. Aronzon, R. Coopersmith, M.T. McDuffie, M. Kapoor, C.A. Uhrich, J.E. Avitabile, J. Liu, D. Housman and M.B. Palchuk, tranSMART: An open source knowledge management and high content data analytics platform, AMIA Jt Summits Transl Sci Proc 2014: ((2014) ), 96–101. 25717408. |
[44] | J. Singh, FigShare, J Pharmacol Pharmacother 2: ((2011) ), 138–139. 21772785. doi:10.4103/0976-500X.81919. |
[45] | SlideAtlas – Whole slide image viewer, https://slide-atlas.org/. |
[46] | B. Smith and R.H. Scheuermann, Ontologies for clinical and translational research: Introduction, J Biomed Inform 44: ((2011) ), 3–7. 21241822. doi:10.1016/j.jbi.2011.01.002. |
[47] | SourceForge – The complete open-source and business software platform, https://sourceforge.net/. |
[48] | A. Surkis and K. Read, Research data management, J Med Libr Assoc 103: ((2015) ), 154–156. 26213510. doi:10.3163/1536-5050.103.3.011. |
[49] | H.C. White, S. Carrier, A. Thompson, J. Greenberg and R. Scherle, The Dryad data repository: A Singapore framework metadata architecture in a DSpace environment, in: DCMI ’08 Proceedings of the 2008 International Conference on Dublin Core and Metadata Applications, (2008) , pp. 157–162. https://dl.acm.org/citation.cfm?id=1503435. |
[50] | M.D. Wilkinson, M. Dumontier, I.J. Aalbersberg, G. Appleton, M. Axton, A. Baak, N. Blomberg, J.W. Boiten, L.B. da Silva Santos, P.E. Bourne, J. Bouwman, A.J. Brookes, T. Clark, M. Crosas, I. Dillo, O. Dumon, S. Edmunds, C.T. Evelo, R. Finkers, A. Gonzalez-Beltran, A.J. Gray, P. Groth, C. Goble, J.S. Grethe, J. Heringa, P.A. t Hoen, R. Hooft, T. Kuhn, R. Kok, J. Kok, S.J. Lusher, M.E. Martone, A. Mons, A.L. Packer, B. Persson, P. Rocca-Serra, M. Roos, R. van Schaik, S.A. Sansone, E. Schultes, T. Sengstag, T. Slater, G. Strawn, M.A. Swertz, M. Thompson, J. van der Lei, E. van Mulligen, J. Velterop, A. Waagmeester, P. Wittenburg, K. Wolstencroft, J. Zhao and B. Mons, The FAIR guiding principles for scientific data management and stewardship, Sci Data 3: ((2016) ), 160018. 26978244. doi:10.1038/sdata.2016.18. |
[51] | Y.L. Yip, Unlocking the potential of electronic health records for translational research. Findings from the section on bioinformatics and translational informatics, Yearb Med Inform 7: ((2012) ), 135–138. 22890355. doi:10.1055/s-0038-1639444. |
[52] | Zenodo – Research. Shared, https://zenodo.org/. |


