
Development of a robust eye exam diagnosis platform with a deep learning model
Abstract
BACKGROUND:
Eye exam diagnosis is one of the early detection methods for eye diseases. However, such a method is dependent on expensive and unpredictable optical equipment.
OBJECTIVE:
The eye exam can be re-emerged through an optometric lens attached to a smartphone and come to read the diseases automatically. Therefore, this study aims to provide a stable and predictable model with a given dataset representing the target group domain and develop a new method to identify eye disease with accurate and stable performance.
METHODS:
The ResNet-18 models pre-trained on ImageNet data composed of 1,000 everyday objects were employed to learn the dataset’s features and validate the test dataset separated from the training dataset.
RESULTS:
A proposed model showed high training and validation accuracy values of 99.1% and 96.9%, respectively.
CONCLUSION:
The designed model could produce a robust and stable eye disease discrimination performance.
1.Introduction
The ophthalmoscope and slit lamps are typically connected to the signal processing electronics and store the images in the computers so the clinicians can determine eye condition for further treatment [1, 2, 3].
The eye exam diagnosis platform could provide specific disease patterns so traditional image processing techniques with several classification methods such as support vector machines or typical spatial patterns have been applied [4, 5].
In addition, there is a lack of trained optometrists even though there are several screening tools for eye exam platforms [6, 7, 8]. Therefore, automatic eye diagnosis techniques with deep learning (DL) algorithms have been highlighted in ophthalmology fields. Compared to the traditional image processing techniques in the manual eye check, the DL algorithms could provide high accuracy for data classification and extraction and reduce processing time for largesize datasets owing to advanced integrated circuit technology with high performance graphic processing units and computer programs [9, 10]. The DL-based research for eye exams could be more attractive because some eye disease patterns could be scanned automatically and diagnosed with minimum clinician’s opinion [11].
There is previous research on the DL techniques which assisted the outcome of the eye exam in clinics or developed the image processing techniques. A DL algorithm was applied for automatic eye detection to compare the traditional diabetic retinopathy test results [12]. A DL framework with a trained neural network dataset for optical coherent tomography (OCT) images was proposed to find new diabetic macular edema [13]. A DL technique with CenterNet and DenseNet-100 models was used to be accurately classified [14]. A DL technique was used for automatic retinal exudate with ultra-wide angle images [15]. A DL method was used to diagnose eye disease in OCT images [16]. A self-adaptive DL technique was used to diagnose eye disease from fundus photography images [17]. An auto-encoder-based DL and densely connected CNN models were applied to classify the blood vessel of the eye [18, 19]. A modified stochastic gradient descent model with the DL technique was used to segment the blood vessel images. To find age-related macular degeneration and glaucoma, a deep neural network model was applied to improve the classification [20]. A real-time deep neural network was used to diagnose abnormal retina diseases [21]. Therefore, the DL techniques based on robust CNN models could improve the accuracy of the automatic eye exam platform.
Chapter 2 provides a description and analysis of the proposed model based eye exam method. Chapter 3 shows the obtained data with the proposed method. Chapter 4 is the conclusion and future work of the proposed research.
2.Method
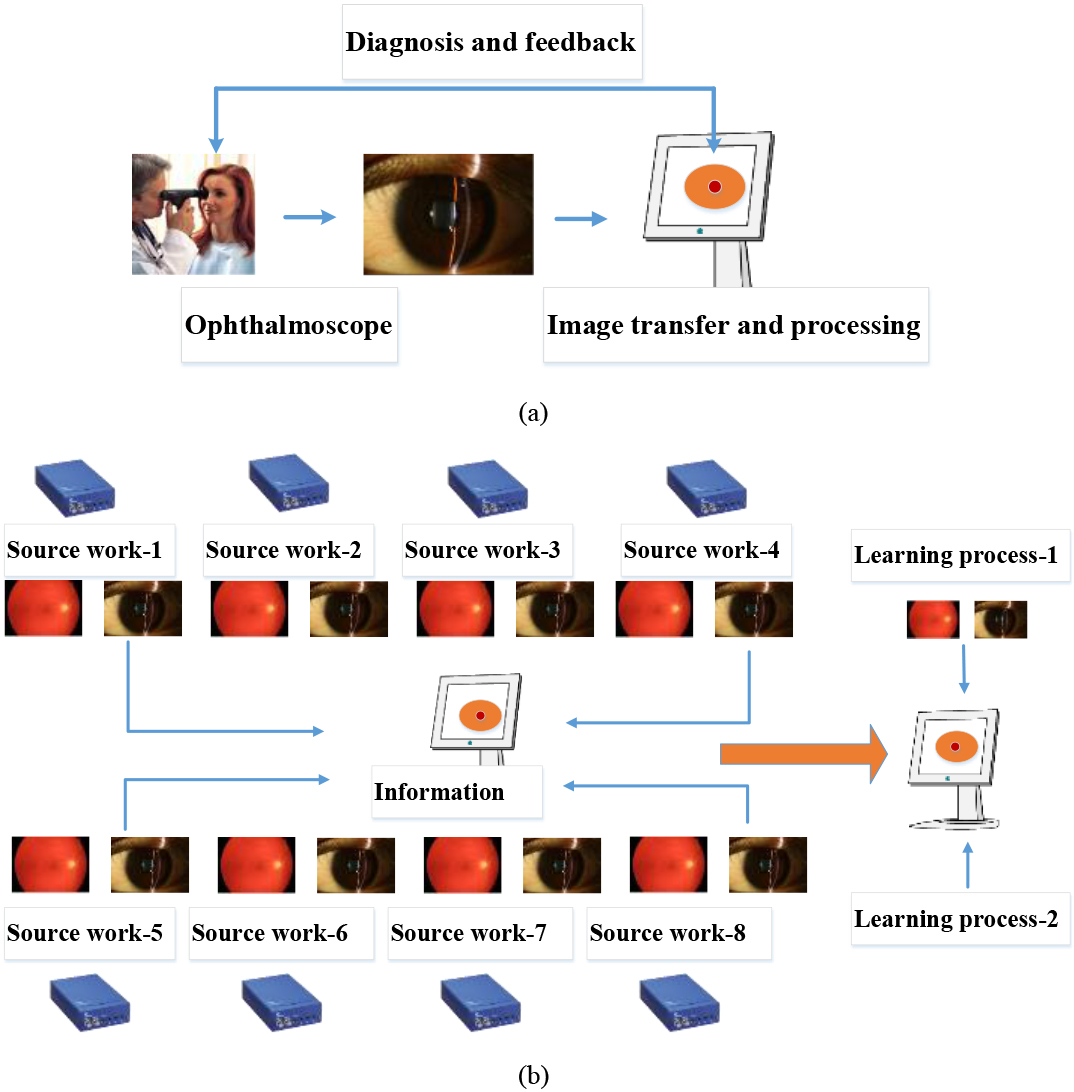
Figure 1a shows a concept of the block diagram of the eye exam platform with typical image processing work. Figure 1b shows the transfer learning process from source work based on our proposed DL model. The datasets obtained from each terminal network were used for pre-trained learning weights. The dimension and task of the transfer learning from our proposed DL model were provided in the specific domains as described using Eq. (2).
(1)
where
With the given source dimension with the learning task, the transfer learning process must work with the function of
Figure 1.
(a) A block diagram of the proposed eye exam platform with deep learning model and (b) a transfer learning process from source work based on our proposed DL model.
The simulation was processed to verify the capability of our proposed CNN model with robust classification performance. The Python and PyTorch program tools were used to encode the algorithm and run the learning codes, respectively. The ResNet-18 model composed of 18 layers, was used for transfer learning codes [22, 23].
The ImageNet dataset, according to the WordNet hierarchy with 1,000 datasets was used for pre-trained learning weight. The function was generated using Eq. (2) as below.
(2)
where
3.Results and discussion
The cross-entropy was used to measure the average numbers between two adjacent values [24]. The stochastic gradient descent (SGD) was used to optimize the objective function and smooth the data classification [25]. The transfer learning model of ResNet-18 was used to obtain the 1,000 datasets from 1,000 object classes.
This study aims to develop a method for automatically discriminating eye diseases with high accuracy by optimizing the model with the minimum fundus photographic data. The data represents the domain of the subject group by applying the transfer learning technique. Because the dataset used in this experiment is balanced, accuracy can be used as the primary evaluation parameter to consider the limitation of computational ability.
Figure 2.
The simulated results of the (a) training and validation loss and (b) training and validation accuracy when using the first dataset in the eye exam platform.
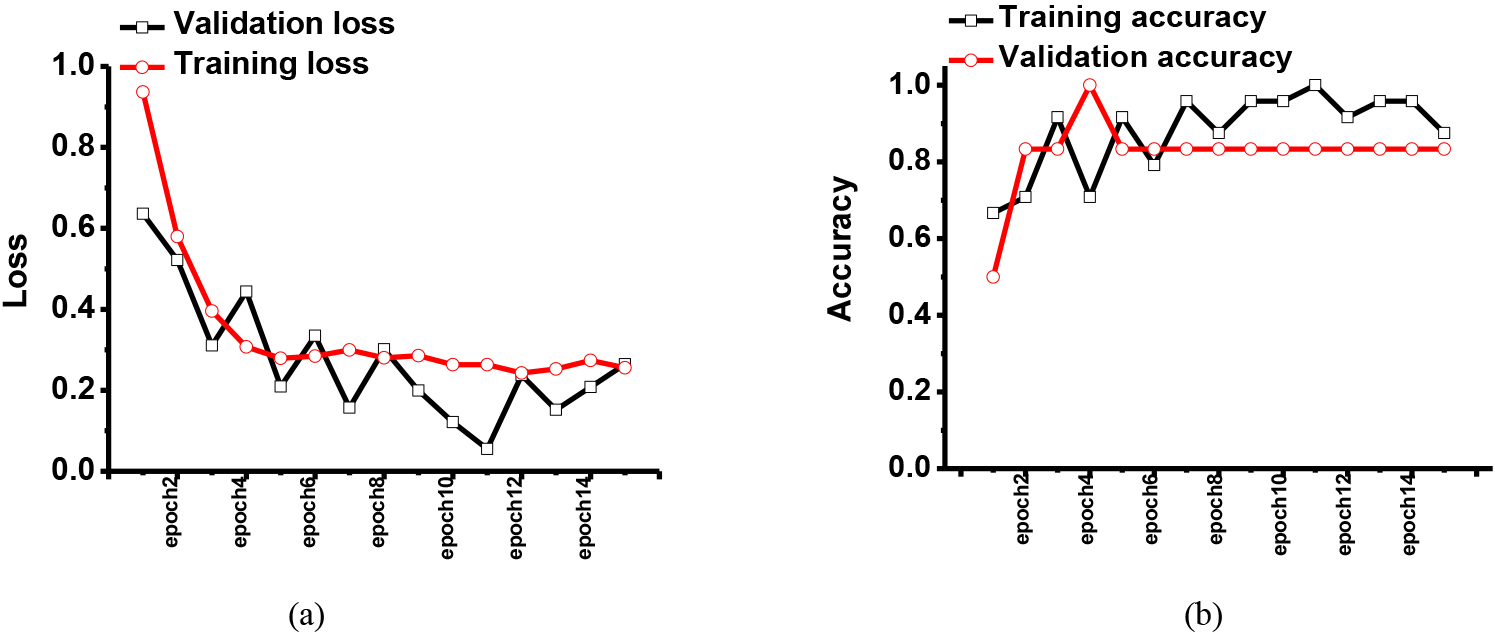
Figure 3.
The simulated results of the (a) training and validation loss and (b) training and validation accuracy when using the second dataset in the eye exam platform.
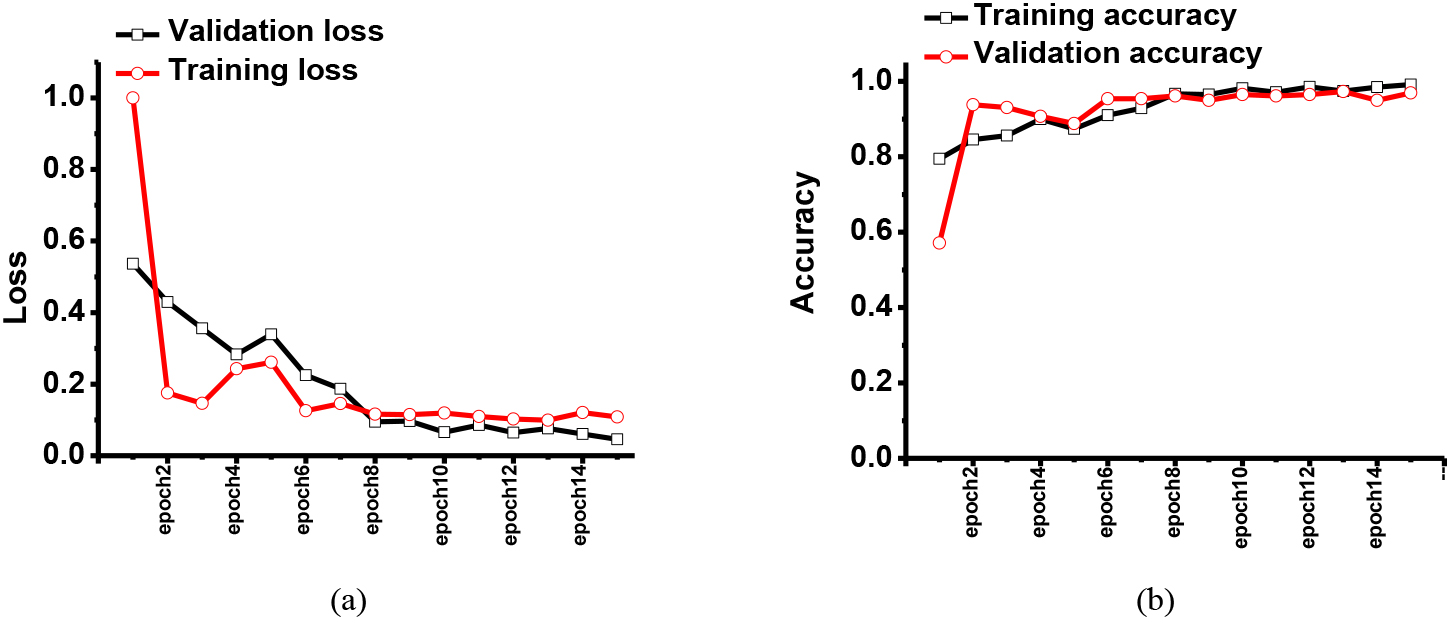
Figure 2 shows the training and validation results with the given dataset. The eye exam image dataset was obtained from the pattern recognition lab at Friedrich-Alexander-Universität. In Figs 2 and 3, the first and second results were obtained using previously published CNN and our proposed CNN models, respectively. In the dataset, there were eye images with healthy, retinopathy, and glaucoma conditions.
As shown in Fig. 2, the training loss was close to 10% as epoch numbers were increased, so the training accuracy was improved to 96.7%. However, the validation loss was higher than 16.5%. This result showed the previously proposed CNN model could not be stable.
Figure 3 shows the training and validation results for eye exam platform. In the dataset, there were also eye images with the healthy, retinopathy, and glaucoma conditions. As shown in Fig. 3, the training loss was less than 5% as epoch numbers were increased, so the training accuracy was improved to 99.1%. Therefore, the validation accuracy approached 96.9%.
4.Conclusion
As the smartphone and tablet personal computers are widely used, intraocular pressure naturally increases. Eye disease is getting faster, and more people have red flags in the eye due to chronic diseases caused by high blood pressure and diabetes. The first step to protecting eye health is an eye exam diagnosis. The field of eye exam platforms has recently re-emerged with the help of artificial intelligence and digital optical photography technology in diagnosing ophthalmic diseases.
For the complete implementation of automatic photo identification, high-quality photo data annotated by experts is required. The discrimination performance which is greatly affected by the image domain must be resolved. However, the production and management of medical images incur the costs such as expert annotation process, de-identification work, and distribution security maintenance. Therefore, this research aims to optimize the model directly with a minimum dataset, which represents the target domain group, by applying the transfer learning technique, and to develop a robust and stable method to identify eye diseases with high accuracy automatically
The ResNet-18 model with ImageNet data composed of 1,000 everyday objects was used. In addition, the pre-trained model was used to learn the photo’s characteristics, and it was verified with the test dataset separated from the training dataset.
The proposed CNN model showed the highest accuracy and validation values of 99.1% and 96.9% from the datasets, respectively. Compared to the previously published CNN model, our proposed model showed more stable results, so it can be helpful to be implemented. In addition, the newly proposed deep learning model showed robust eye disease discrimination performance despite a limited quantity of photo datasets and variances in the image domain. Through this study, we can demonstrate our proposed technique is a simple but robust transfer learning model.
Acknowledgments
This work was supported by Korea Institute for Advancement of Technology (KIAT) grant funded by the Korea Government (MOTIE) (P0011930, The Establishment Project of Industry-University Fusion District).
Conflict of interest
None to report.
References
[1] | Najarian K, Splinter R. Biomedical Signal and Image Processing. Boca Raton, FL, USA: CRC press; (2005) . |
[2] | Jung U, Choi JH, Choo HT, Kim GU, Ryu J, Choi H. Fully Customized Photoacoustic System Using Doubly Q-Switched Nd: YAG Laser and Multiple Axes Stages for Laboratory Applications. Sensors. (2022) ; 22: (7): 2621. |
[3] | Ahn J, Baik JW, Kim Y, Choi K, Park J, Kim H, et al. Fully integrated photoacoustic microscopy and photoplethysmography of human in vivo. Photoacoustics. (2022) ; 100374. |
[4] | Nixon M, Aguado A. Feature Extraction and Image Processing for Computer Vision. Cambridge, MA, USA: Academic Press; (2019) . |
[5] | Jung U, Choi H. Active echo signals and image optimization techniques via software filter correction of ultrasound system. Applied Acoustics. (2022) ; 188: : 108519. |
[6] | Strojnik P, Peckham PH. The Biomedical Engineering Handbook. Boca Raton, FL, USA: CRC Press; (2000) . |
[7] | Carr JJ, Brown JM. Introduction to Biomedical Equipment Technology. Upper Saddle River, NJ, USA: Prentice hall; (2001) . |
[8] | Shortliffe EH, Cimino JJ. Biomedical Informatics. Berlin, Germany: Springer; (2006) . |
[9] | Deisenroth MP, Faisal AA, Ong CS. Mathematics for machine learning. Cambridge, United Kingdom: Cambridge University Press; (2020) . |
[10] | Choi H, Park J, Yang Y-M. Whitening technique based on gram-schmidt orthogonalization for motor imagery classification of brain-computer interface applications. Sensors. (2022) ; 22: (16): 6042. |
[11] | Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge, MA, USA: MIT Press; (2016) . |
[12] | Abràmoff MD, Lou Y, Erginay A, Clarida W, Amelon R, Folk JC, et al. Improved automated detection of diabetic retinopathy on a publicly available dataset through integration of deep learning. Invest Ophthalmol Visual Sci. (2016) ; 57: (13): 5200-6. |
[13] | Kermany DS, Goldbaum M, Cai W, Valentim CCS, Liang H, Baxter SL, et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell. (2018) ; 172: (5): 1122-31.e9. |
[14] | Nazir T, Nawaz M, Rashid J, Mahum R, Masood M, Mehmood A, et al. Detection of Diabetic Eye Disease from Retinal Images Using a Deep Learning Based CenterNet Model. Sensors. (2021) ; 21: (16): 5283. |
[15] | Li Z, Guo C, Nie D, Lin D, Cui T, Zhu Y, et al. Automated detection of retinal exudates and drusen in ultra-widefield fundus images based on deep learning. Eye. (2021) . |
[16] | Chase C, Elsawy A, Eleiwa T, Ozcan E, Tolba M, Abou Shousha M. Comparison of autonomous AS-OCT Deep learning algorithm and clinical dry eye tests in diagnosis of dry eye disease. Clin Ophthalmol. (2021) ; 15: : 4281. |
[17] | Liu C, Han X, Li Z, Ha J, Peng G, Meng W, et al. A self-adaptive deep learning method for automated eye laterality detection based on color fundus photography. PLOS ONE. (2019) ; 14: (9): e0222025. |
[18] | Maji D, Santara A, Ghosh S, Sheet D, Mitra P, editors. Deep neural network and random forest hybrid architecture for learning to detect retinal vessels in fundus images. 2015 37th annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBC); IEEE, 2015: . |
[19] | Liu Z-F, Zhang Y-Z, Liu P-Z, Zhang Y, Luo Y-M, Du Y-Z, et al. Retinal vessel segmentation using densely connected convolution neural network with colorful fundus images. J Med Imaging Health Inf. (2018) ; 8: (6): 1300-7. |
[20] | Ngo L, Han J-H. Multi-level deep neural network for efficient segmentation of blood vessels in fundus images. Electron Lett. (2017) ; 53: (16): 1096-8. |
[21] | Wei H, Sehgal A, Kehtarnavaz N, editors. A deep learning-based smartphone app for real-time detection of retinal abnormalities in fundus images. Proceedings Volume 10996, Real-Time Image Processing and Deep Learning 2019; Baltimore, Maryland, USA: SPIE. (2019) . |
[22] | Zhou Q, Zhu W, Li F, Yuan M, Zheng L, Liu X. Transfer Learning of the ResNet-18 and DenseNet-121 Model Used to Diagnose Intracranial Hemorrhage in CT Scanning. Curr Pharm Des. (2022) ; 28: (4): 287-95. |
[23] | Choi H, Park J, Yang Y-M. A novel quick-response eigenface analysis scheme for brain-computer interfaces. Sensors. (2022) ; 22: (15): 5860. |
[24] | Han W, Xue J, Yan H. Detecting anomalous traffic in the controlled network based on cross entropy and support vector machine. IET Inf Secur. (2019) ; 13: (2): 109-16. |
[25] | Lei Y, Hu T, Li G, Tang K. Stochastic gradient descent for nonconvex learning without bounded gradient assumptions. IEEE Trans Neural Networks Learn Syst. (2019) ; 31: (10): 4394-400. |


