
DeepOnto: A Python package for ontology engineering with deep learning
Abstract
Integrating deep learning techniques, particularly language models (LMs), with knowledge representation techniques like ontologies has raised widespread attention, urging the need of a platform that supports both paradigms. Although packages such as OWL API and Jena offer robust support for basic ontology processing features, they lack the capability to transform various types of information within ontologies into formats suitable for downstream deep learning-based applications. Moreover, widely-used ontology APIs are primarily Java-based while deep learning frameworks like PyTorch and Tensorflow are mainly for Python programming. To address the needs, we present DeepOnto, a Python package designed for ontology engineering with deep learning. The package encompasses a core ontology processing module founded on the widely-recognised and reliable OWL API, encapsulating its fundamental features in a more “Pythonic” manner and extending its capabilities to incorporate other essential components including reasoning, verbalisation, normalisation, taxonomy, projection, and more. Building on this module, DeepOnto offers a suite of tools, resources, and algorithms that support various ontology engineering tasks, such as ontology alignment and completion, by harnessing deep learning methods, primarily pre-trained LMs. In this paper, we also demonstrate the practical utility of DeepOnto through two use-cases: the Digital Health Coaching in Samsung Research UK and the Bio-ML track of the Ontology Alignment Evaluation Initiative (OAEI).
Repository: https://github.com/KRR-Oxford/DeepOnto
Documentation: https://krr-oxford.github.io/DeepOnto/
License: Apache License, Version 2.0
1.Introduction
An ontology is a formal, explicit specification of knowledge within the scope of a domain. It provides a vocabulary of concepts and properties that enables a shared understanding of semantics among humans and machines, with wide applications in many domains such as bioinformatics, information systems, and the Semantic Web. Ontology engineering, a sub-field of knowledge engineering, underpins the various stages of ontology development, encompassing ontology design, construction, curation, evaluation, and maintenance, among others [44]. Concrete tasks of ontology engineering include: (i) defining the entities and constructing the logical axioms that make up an ontology, (ii) validating and ensuring quality (e.g., completeness and correctness) of an ontology, (iii) inserting new knowledge into an ontology, (iv) integrating domain ontologies that come from heterogeneous sources, and so on. These tasks can collectively enhance an ontology’s practical utility, making it applicable to different real-world scenarios.
Deep learning approaches have gained significant popularity across various research and engineering domains. These techniques have shown notable advantages over conventional ontology engineering tools. For example, LogMap [25], a long-standing state-of-the-art ontology alignment system, relies on lexical similarity and lacks the ability to capture textual contexts. In contrast, BERTMap [17], a language model (LM)-based system which leverages the attention mechanism of the transformer architecture for contextual text embeddings [48], can be more robust to linguistic variations such as synonyms and polysemies. Another example concerns ontology completion. Traditional systems, leveraging formal logics and/or heuristic rules, are capable of inferring entailed knowledge (e.g., HermiT for ontology reasoning [16]). But the requirement of manual design and curation for these logics and rules frequently results in their under-specification. This constraint significantly curtails their capability to deduce absent but plausible knowledge. As opposed to these rule-based solutions, deep learning-based techniques can automatically learn patterns from the existing knowledge, the metadata and different kinds of other information, and make predictions accordingly [8,9,31]. Nevertheless, the benefit is not single sided. The formal and structural semantics embedded in ontologies can augment deep learning models, enhancing not only their training efficiency but also their interpretability. For instance, leveraging structural contexts via graph-based attention mechanisms has yielded substantial advancements in predictive modelling [10]. Furthermore, the issue of mitigating hallucinated responses produced by recent large language models (LLMs) can be addressed through the incorporation of attributions [6,39], potentially from symbolic knowledge. In this context, ontologies can play a crucial role, acting as robust and trustworthy reference points to validate and support the generated answers.
However, there lacks a systematic support for integrating ontology engineering with deep learning, posing challenges for both developers and users. While there are packages such as OWL API [21] and Jena [7] that effectively support basic ontology processing features, particularly those associated with OWL (Web Ontology Language) [33] – a prominent ontology language grounded in Description Logic – to the best of our knowledge, no existing packages are designed to transform various types of information within ontologies into formats to facilitate a broad spectrum of deep learning-based ontology engineering solutions. This is further complicated by the fact that leading deep learning frameworks like Tensorflow [1] and PyTorch [36] primarily offer Python-based APIs, whereas the majority of ontology APIs are Java-based. Although the mOWL toolkit [52] resolves this gap by employing JPype11 to bridge Python and Java, it mainly focuses on ontology embedding models and their applications to the biomedical domain, thereby neglecting fundamental ontology processing features and a variety of essential tasks pivotal for ontology construction and curation. In order to provide a comprehensive, general, and versatile package for supporting deep learning-based ontology engineering, we develop DeepOnto.
Figure 1 depicts the architecture of DeepOnto. It consists of an ontology processing module as the foundation, which can support basic operations like loading, saving, retrieving entities, querying for ancestors/descendants, and modifying entities and axioms, as well as more advanced functions like reasoning, verbalisation, normalisation, and projection (see Section 3 for their specifications). Built upon this basic module, DeepOnto features a collection of ontology engineering tools and resources, devised for ontology alignment, completion, and ontology-based LM probing. DeepOnto provides a fairly flexible and extensible interface for further implementations. This includes our ongoing efforts, such as logic embedding [23] and the identification and insertion of new concepts [14], as well as other typical works that can facilitate ontology construction and curation, such as the OWL ontology embedding method OWL2Vec* [9]. The incorporation of these new tools and resources may necessitate the integration of other fundamental features into the core ontology processing module, further enhancing its capabilities and robustness. Through this positive development cycle, we expect DeepOnto to emerge as a powerful package for the community, providing general support and fostering innovation within the field.
2.Design principle
2.1.Dependencies
We chose the OWL API as the backend dependency due to its stability, reliability, and widespread adoption in notable projects and tools, such as Protégé [34], ROBOT [24] and HermiT [16]. DeepOnto was initially built on Owlready222 [28], a Python-based ontology API. However, we found that Owlready2 is still in a preliminary stage and lacks support for several fundamental features. For instance, runtime errors are frequently triggered when attempting to delete entities from an ontology. Furthermore, it also posed difficulties when dealing with multiple ontologies simultaneously, as entities are loaded into a shared space without a reference to their original ontologies. While the underlying library RDFLib,33 on which Owlready2 is built, does offer a platform to process RDF triples directly and introduce some missing functionalities for handling OWL ontologies, its use would necessitate significant additional development. This makes RDFLib a less viable option considering the developmental effort and resources required. To facilitate the import of OWL API, we adopted the solution from the mOWL44 toolkit [52], which utilises JPype to connect the Java Virtual Machine (JVM) with Python programming. Specifically, the Java dependency files are compiled into the Java Archive (JAR) format and will be shipped upon package installation. JVM can then be launched within a Python program, establishing a connection to the JAR files. We constrain the direct import of the Java dependencies within the central ontology processing module, maintaining them in a relatively static version. This strategy ensures long-term stability and streamlines the updating and management processes of the codebase.
DeepOnto adopts PyTorch [36] as the backbone for deep learning dependencies. PyTorch is characterised by its dynamic computation graph, which enables runtime modification of the model’s architecture, providing flexibility and ease of use for users. Also, significant efforts are invested to ensure backward compatibility. Currently, ontology engineering modules in DeepOnto mainly target applications of language models (LMs), which are well supported by the Huggingface’s Transformers library [51]. Building upon this, the OpenPrompt library [13] supports the prompt learning paradigm, which is one of the key foundations of recent cutting-edge large language models, such as ChatGPT [35] and LLaMA 2 [45].
2.2.Architecture
The architecture of DeepOnto is straightforward and succinct. As shown in Fig. 1, the basis of DeepOnto is the core ontology processing module, which comprises a collection of essential sub-modules that revolve around the main class55  . The ontology class serves as the main entry point for introducing the OWL API’s features, such as accessing ontology entities, querying for ancestor/descendent (and parent/child) concepts, deleting entities, modifying axioms, and retrieving annotations. These functions are encapsulated in a more cohesive and easy-to-use66 manner. Along with these basic functionalities, we introduce several essential sub-modules to enhance the core module, such as reasoning, pruning, verbalisation, normalisation, projection, and more. One shared objective of all these components is to transform an ontology into various data forms, such as verbalising an ontology entity into natural language text and projecting an ontology into an RDF graph, thereby facilitating deep learning-based ontology engineering solutions.
. The ontology class serves as the main entry point for introducing the OWL API’s features, such as accessing ontology entities, querying for ancestor/descendent (and parent/child) concepts, deleting entities, modifying axioms, and retrieving annotations. These functions are encapsulated in a more cohesive and easy-to-use66 manner. Along with these basic functionalities, we introduce several essential sub-modules to enhance the core module, such as reasoning, pruning, verbalisation, normalisation, projection, and more. One shared objective of all these components is to transform an ontology into various data forms, such as verbalising an ontology entity into natural language text and projecting an ontology into an RDF graph, thereby facilitating deep learning-based ontology engineering solutions.
Fig. 1.
Illustration of DeepOnto’s architecture, with the lower half depicting the core ontology processing module, and the upper half presenting various tools and resources for diverse ontology engineering tasks. The thick arrow signs indicate dependency support and the thin arrow signs in the core ontology processing module point to sub-modules related to different functionalities.
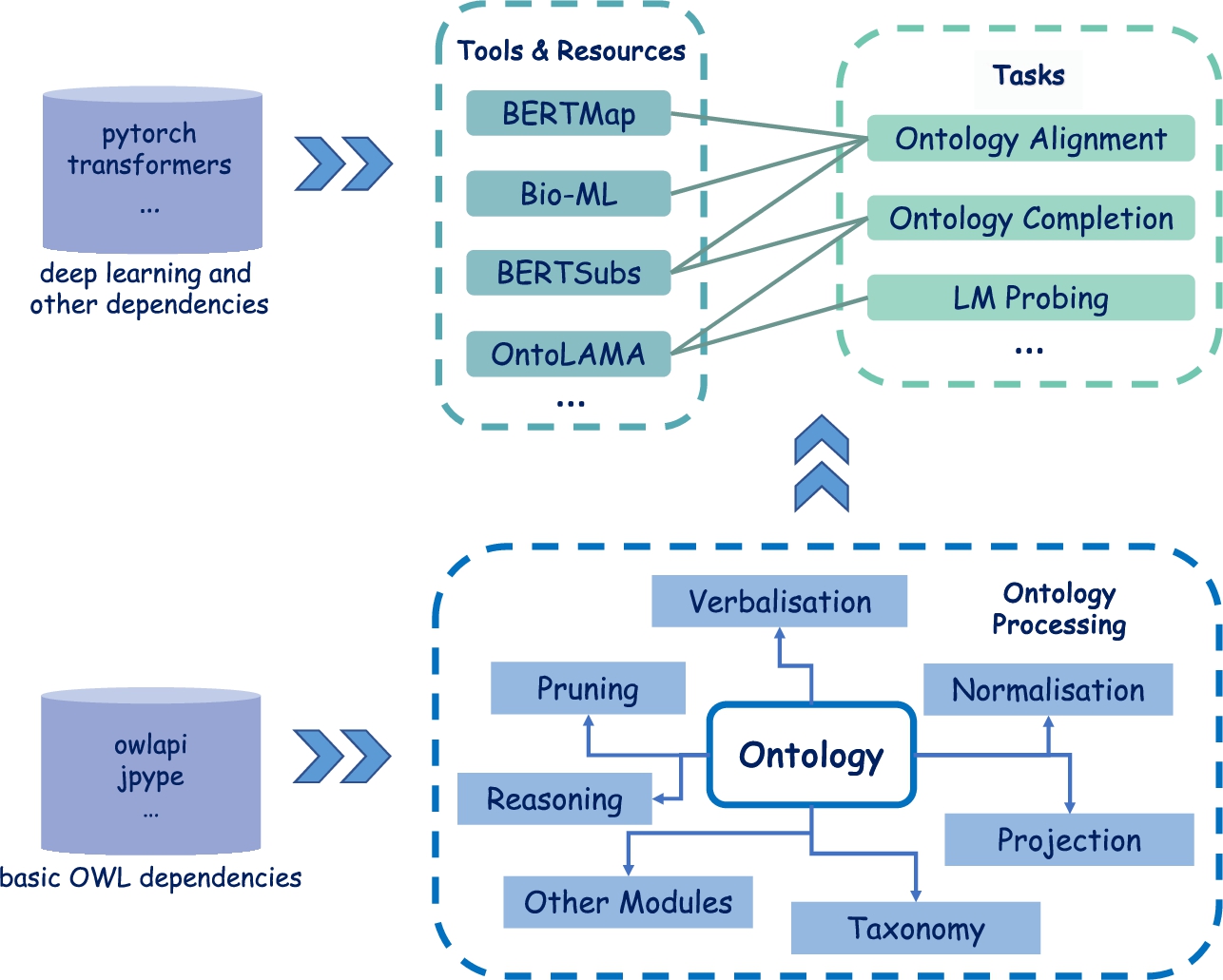
The core ontology processing module paves the way for implementing individual tools and resources to support ontology construction and curation. At present, DeepOnto mainly incorporates systems based on pre-trained LMs, and has covered the tasks of ontology alignment, ontology completion with subsumptions, and ontology-based LM probing. In the near future, DeepOnto is expected to incorporate new tools for ontology embedding, concept insertion, and more. Notably, the DeepOnto system can be easily updated and extended with new tools to support other knowledge engineering scenarios, such as entity linking, entity alignment, and link prediction for knowledge graphs mainly composed of relational facts.
3.Ontology processing
Fig. 2.
The left figure illustrates the process of removing a concept while preserving the subsumption hierarchy in the ontology pruning algorithm proposed in Bio-ML [19]. The right figure illustrates an example of the application of the recursive concept verbalisation algorithm proposed in OntoLAMA [20].
![The left figure illustrates the process of removing a concept while preserving the subsumption hierarchy in the ontology pruning algorithm proposed in Bio-ML [19]. The right figure illustrates an example of the application of the recursive concept verbalisation algorithm proposed in OntoLAMA [20].](https://ip.ios.semcs.net:443/media/sw/2024/15-5/sw-15-5-sw243568/sw-15-sw243568-g002.jpg)
In this section, we present a brief description for each component in the core ontology processing module.
Ontology The base class of DeepOnto is named as  , which offers basic operations for accessing or modifying an ontology. An instance of
, which offers basic operations for accessing or modifying an ontology. An instance of  can be initialised by taking an ontology file as input. Users can then access named entities (concepts and properties) through their IRIs, obtain asserted parents and children of an entity, retrieve and modify axioms, and so on. When implemented in Java using OWL API, even simple features like these may require several lines of code. DeepOnto’s encapsulation in Python improves code cleanliness and readability.
can be initialised by taking an ontology file as input. Users can then access named entities (concepts and properties) through their IRIs, obtain asserted parents and children of an entity, retrieve and modify axioms, and so on. When implemented in Java using OWL API, even simple features like these may require several lines of code. DeepOnto’s encapsulation in Python improves code cleanliness and readability.
Ontology reasoning Every instance of 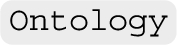 is accompanied by an instance of
is accompanied by an instance of  as its attribute. It is used for conducting reasoning activities, including obtaining inferred subsumers and subsumees, as well as checking entailment and consistency. By encapsulating these basic reasoning functions, we can implement more complex or specific reasoning algorithms. For example, we have implemented the assumed disjointness proposed by [20], which can be particularly useful in the negative sampling process frequently employed in various machine learning-driven ontology curation tasks, including but not limited to, subsumption prediction. Currently, DeepOnto supports three types of reasoners:
as its attribute. It is used for conducting reasoning activities, including obtaining inferred subsumers and subsumees, as well as checking entailment and consistency. By encapsulating these basic reasoning functions, we can implement more complex or specific reasoning algorithms. For example, we have implemented the assumed disjointness proposed by [20], which can be particularly useful in the negative sampling process frequently employed in various machine learning-driven ontology curation tasks, including but not limited to, subsumption prediction. Currently, DeepOnto supports three types of reasoners:
Ontology pruning Real-world ontologies frequently exhibit a large-scale nature, leading to diminished efficiency during system evaluation. To extract a scalable subset from an ontology, we often prune the ontology by removing its concepts based on certain criteria, e.g., semantic types. In order to maintain the hierarchical structure during the pruning process, we implement the pruning algorithm proposed in [19] (found in 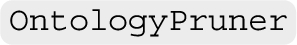 ), which introduces subsumption axioms between the asserted (atomic or complex) parents and children of the concept targeted for removal (see Fig. 2; left). For future development, we aim to incorporate more pruning approaches. A key addition will be ontology modularisation, a technique that seeks to extract a (small) sub-ontology that entails a given axiom or is sufficient to answer a specific concept of queries [11]. We also aim to explore its various variants that involve approximation, catering to different scenarios such as the construction of personalised knowledge graphs.
), which introduces subsumption axioms between the asserted (atomic or complex) parents and children of the concept targeted for removal (see Fig. 2; left). For future development, we aim to incorporate more pruning approaches. A key addition will be ontology modularisation, a technique that seeks to extract a (small) sub-ontology that entails a given axiom or is sufficient to answer a specific concept of queries [11]. We also aim to explore its various variants that involve approximation, catering to different scenarios such as the construction of personalised knowledge graphs.
Ontology verbalisation Verbalising an entity into natural language text with close meaning as its counterpart OWL statements can improve an ontology’s accessibility and support many ontology engineering tasks. For example, ontology alignment systems often rely on string similarity or other text-level features to achieve successful results. While a named entity can be easily verbalised using its name (or labels), complex expressions that involve logical operators need a more sophisticated algorithm. In DeepOnto, we implement a recursive concept verbaliser (found in  ) proposed in [20], which can automatically transform a complex logical expression into a textual sentence based on entity names or labels available in the ontology. An example is shown in the right of Fig. 2, where the complex concept expression
) proposed in [20], which can automatically transform a complex logical expression into a textual sentence based on entity names or labels available in the ontology. An example is shown in the right of Fig. 2, where the complex concept expression  ). The leaf nodes are named concepts or properties and they are verbalised directly. The recursion occurs when merging verbalised child nodes according to the logical pattern in their parent node, and terminates when the sentence is complete. In this example, the final output is “food product that derives from invertebrate animal or vertebrate animal”.
). The leaf nodes are named concepts or properties and they are verbalised directly. The recursion occurs when merging verbalised child nodes according to the logical pattern in their parent node, and terminates when the sentence is complete. In this example, the final output is “food product that derives from invertebrate animal or vertebrate animal”.
Ontology normalisation Normalisation refers to the transformation of axioms into one of the following normal forms:
Ontology taxonomy An ontology defines a hierarchy of concepts through asserted subsumption axioms, resulting in a taxonomy. This taxonomy simplifies the ontology’s structure, allowing easier navigation and retrieval by focusing exclusively on hierarchical relationships. This, in turn, facilitates graph-based deep learning models. In DeepOnto, the ontology taxonomy (found in  ) is implemented as a directed acyclic graph with named concepts as nodes and subsumption relations as directed edges. The top concept owl:Thing is used as the root node. To establish the subsumption edges, we employ an ontology reasoner (refer to the Ontology Reasoning section for more details) to infer direct subsumers for each named concept. According to the OWL API documentation,99 a direct subsumption implies that if the ontology entails
) is implemented as a directed acyclic graph with named concepts as nodes and subsumption relations as directed edges. The top concept owl:Thing is used as the root node. To establish the subsumption edges, we employ an ontology reasoner (refer to the Ontology Reasoning section for more details) to infer direct subsumers for each named concept. According to the OWL API documentation,99 a direct subsumption implies that if the ontology entails
Ontology projection DeepOnto offers the capability to transform an OWL ontology into a set of RDF triples. A default method for this transformation, which adheres to the W3C standard,1010 is provided by OWL API. This method preserves the ontology’s semantics and is effective for storing or exchanging ontologies. However, as it may introduce many blank nodes for representing complex logical expressions, its utility for ontology visualisation or applying graph-based algorithms, such as Random Walk and Graph Neural Networks, is limited. In such situations, a simplified graph representation is often needed, an approach sometimes termed as ontology projection.1111 DeepOnto has implemented the algorithm (found in  ) originally used in the ontology visualisation system OptiqueVQS [43], to transform axioms into a set of simplified RDF triples. Briefly, a concept subsumption axiom
) originally used in the ontology visualisation system OptiqueVQS [43], to transform axioms into a set of simplified RDF triples. Briefly, a concept subsumption axiom
4.Tools and resources
DeepOnto has implemented several tools and resources for various ontology engineering purposes. For ontology matching (OM), DeepOnto has BERTMap [17] for concept equivalence matching, BERTSubs (Inter) [8] for concept subsumption matching, and Bio-ML [19], a collection of biomedical datasets and evaluation protocols to support OM system benchmarking. For ontology completion, DeepOnto has BERTSubs (Intra), and the prompt-based approach proposed in OntoLAMA [20]. The work of OntoLAMA also involves a collection of subsumption inference datasets for language model probing. In the following sub-sections, we present each of these modules in more detail.
4.1.BERTMap
Ontology matching (OM) is the task of identifying mappings that represent a semantic relationship between entities of two different ontologies. BERTMap1212 targets on equivalence matching between named concepts. It adopts Bidirectional Encoder Representations from Transformers (BERT) [12], a masked language model pre-trained on extensive text corpora such as English Wikipedia, in the computation of a mapping score. Specifically, BERTMap utilises concept labels available in the input ontologies to extract pairs of synonyms and non-synonyms, and then fine-tunes a BERT model for synonym classification. The mappings score is determined by the aggregation of synonym scores between labels of two named concepts. To reduce the time complexity of mapping search, BERTMap adopts a sub-word inverted index for candidate selection. This approach takes advantage of the sub-word tokenisation capability inherent in the BERT model. To enrich the mapping set and capture potential missed matches during candidate selection, BERTMap incorporates an iterative mapping extension algorithm based on the locality principle, i.e., if two concepts are matched, their parents or children are likely to be matched. Lastly, BERTMap utilises the mapping repair module proposed in [25] to remove a minimal set of inconsistent mappings.
BERTMap provides flexible configurations to accommodate various needs. For instance, users can easily switch between different masked language models, such as RoBERTa [32] and ALBERT [29], or opt for BERT variants pre-trained on specialised corpora, such as BioBERT [30] and ClinicalBERT [22], by simply altering the input name of the language model. Moreover, BERTMap supports both unsupervised and semi-supervised settings; the former relies solely on the input ontologies, while the latter can leverage a small number of provided mappings for enhanced performance. Data augmentation from external ontologies is also possible and would be very helpful when the input ontologies are short of concept labels. Last but not the least, a light-weight version of BERTMap called BERTMapLt. This version does not necessitate the BERT fine-tuning nor the mapping refinement, rendering it considerably more efficient. Despite its simplified operations, BERTMapLt can attain promising results on certain datasets.
4.2.BERTSubs
BERTSubs1313 [8] aims at predicting (i) the missing concept subsumptions within an OWL ontology for completion, and (ii) the subsumptions between concepts from two OWL ontologies for alignment. In our latest implementation in DeepOnto (since v0.7.0), the super-concepts in both situations can be either named concepts or complex concepts such as existential restrictions. Following the architecture of BERTMap, BERTSubs also fine-tunes a pre-trained BERT (or one of its variants) together with an attached binary classifier which outputs a score for an input candidate subsumption. It extracts the existing subsumptions within the given ontology or ontologies for constructing positive samples, and replaces the super-concepts of these subsumptions by a randomly selected named concept (or complex concept if the original super-concept is complex) for constructing negative samples.
Each concept in a subsumption is transformed into a text sentence, and the subsumption is transformed into a sentence pair as the model input. For a complex concept, we directly call the verbalisation function implemented in the ontology processing module of DeepOnto (see Section 3). For a named concept, we have implemented three approaches (see details in [8]) to generate its (context-aware) text sentence as the model input:
– Isolated Class (IC) which directly uses the given concept’s name according to a pre-defined annotation property like rdfs:label;
– Path Context (PC) which extracts a subsumption path from the ontology’s concept hierarchy, starting from the given super-concept up to the root (or starting from the given sub-concept down to a leaf), and concatenates the names of the concepts in the path, separated by some special token;
– Breadth-first Context (BC) which traverses a set of neighbouring subsumptions of the given concept from the ontology’s concept hierarchy, starting from the given super-concept up to the root (or starting from the given sub-concept down to a leaf) via breadth-first search, and concatenates the names of the concepts of these subsumptions in a specific way, separated by a special token.
4.3.Bio-ML
Table 1
Data statistics for ontology pairs in Bio-ML, including the data sources, ontology names, categories (semantic types) of preserved concepts during ontology pruning, numbers of named concepts and reference mappings in the equivalence (≡) and the subsumption (⊑) settings
| Ontology pair | Category | #Concepts (≡) | #Refs (≡) | #Concepts (⊑) | #Refs (⊑) | |
| Mondo | OMIM-ORDO | Disease | 9,642–8,838 | 3,721 | 9,642–8,735 | 103 |
| NCIT-DOID | Disease | 6,835–8,848 | 4,686 | 6,835–5,113 | 3,339 | |
| UMLS | SNOMED-FMA | Body | 24,182–64,726 | 7,256 | 24,182–59,567 | 5,506 |
| SNOMED-NCIT | Pharm | 16,045–15,250 | 5,803 | 16,045–12,462 | 4,225 | |
| SNOMED-NCIT | Neoplas | 11,271–13,956 | 3,804 | 11,271–13,790 | 213 |
Benchmarking has been a critical challenge that limits OM academic research and system development. Thus, we added Bio-ML into DeepOnto. It currently includes five OM datasets derived from biomedical ontologies, accompanied by a comprehensive OM evaluation framework. The involved biomedical ontologies include SNOMED-CT [15], FMA [40], NCIT [42], OMIM [2], ORDO [46], and DOID [41], based on the human-curated thesaurus and alignment in the integrated ontologies, UMLS [5] and Mondo [47]. It aims to address several limitations of the existing OM datasets and evaluation settings, including the following:
– Sub-optimal ground truth mappings: Many OM datasets have incomplete ground truth mappings, and conventional evaluation metrics Precision, Recall, and F-score become biased towards high-precision and low-recall systems, as they are more likely to match the available ground truth mappings.
– Limited to equivalence matching: The majority of existing OM datasets focus solely on matching equivalent concepts.
– Lack of support for machine learning-based systems: Current OM datasets do not accommodate data splitting (e.g., training, validation, and testing) and the conventional evaluation metrics, which are based on the final output mappings, are inefficient for developing and debugging machine learning-based OM models.
To address these limitations, Bio-ML incorporates the following strategies:
– Human-curated mappings: Bio-ML utilises ground truth mappings from UMLS and Mondo, which have been curated and validated by experts.
– Expanded evaluation metrics: In addition to conventional metrics, Bio-ML proposes the use of ranking metrics such as Hits@K and MRR to provide a more comprehensive assessment of OM systems and support more efficient evaluation of machine learning-based OM systems.
– Subsumption matching: Bio-ML extends the scope of matching beyond equivalence, including subsumption relationships; the subsumption mappings are generated from the ground truth equivalence mappings.
– Data split settings: Bio-ML formulates different data split configurations (unsupervised and semi-supervised) to better support the development and evaluation of machine learning-based OM systems.
Furthermore, given that biomedical ontologies are often large-scale and some OM systems cannot deal with such ontologies or will cost a very long time for computation, Bio-ML employs a pruning algorithm (see Ontology Pruning in Section 3) subject to semantic types, which allows for the extraction of scalable sub-ontologies. For subsumption matching, target concepts that appear in a ground truth equivalence mapping used to construct a ground truth subsumption mapping is purposely deleted in order to enforce direct subsumption matching. The resulting datasets can be downloaded through Zenodo,1414 the detailed instructions and data statistics (also shown in Table 1) are provided in DeepOnto.1515 Moreover, Bio-ML has been introduced as a new track1616 of the Ontology Alignment Evaluation Initiative (OAEI 2022), and the corresponding result report is available [38]. We will discuss more about its usage in the OAEI in Section 5.2.
4.4.OntoLAMA
The investigation of a language model’s comprehension of knowledge and reasoning capability is a widely discussed topic, commonly referred to as “LMs-as-KBs” [37]. While most existing works on ‘LMs-as-KBs’ focus on knowledge graphs composed of relational facts (sometimes known as RDF triple knowledge graphs), OntoLAMA explores OWL ontologies which represent conceptual knowledge with logical reasoning supported. OntoLAMA is essentially a set of subsumption inference (SI) datasets concerning both atomic and complex concept expressions. These datasets are extracted from ontologies of various domains and scales. The probing method proposed in OntoLAMA is based on prompt learning, which is a paradigm used to effectively extract knowledge from language models through prompts. In this method, concept expressions are first transformed into natural language text using the recursive ontology verbaliser (see Ontology Verbalisation in Section 3). Then, the verbalised phrases are wrapped into a template along with the prompt text. The language model’s task is to classify if two concept expressions have a subsumption relationship given this prompt-enhanced text format. Using this approach, a significant and consistent improvement in performance has been observed even with a small number of training and development samples (in a few-shot setting). This outcome highlights the potential of LM-based ontology engineering works in the future, without the need for excessive training resources.
To summarise, OntoLAMA contributes the following to DeepOnto: (i) a set of LM probing datasets1717 extracted from ontology subsumptions, (ii) a verbalisation algorithm that can handle complex concept expressions, (iii) a method to use LMs with prompts to predict subsumptions without fully supervised fine-tuning.
5.Impact and use
DeepOnto has been gaining attention from both the industry and academia. On the industrial front, notable adoptions of DeepOnto include its utilisation by Samsung Research UK for Digital Health Coaching1818 and Madrid Digital,1919 where it played a crucial role in their Proof of Concept process. Our user feedback indicates DeepOnto’s primary applications within the health and biomedical sectors. From the academia side, DeepOnto contributes to the Bio-ML track of the Ontology Alignment Evaluation Initiative (OAEI), and our tools and resources have facilitated numerous research works, evident in existing scholarly citations. For example, BERTMap serves as a typical baseline in subsequent BERT-based ontology alignment studies, including but not limited to Truveta Mapper [3], LaKERMap [50], as well as in large language model-based frameworks such as Retrieve-Rank [49] and LLMap [18].
In the following sub-sections, we elaborate on two use cases of DeepOnto, i.e., Digital Health Coaching in Samsung Research UK and the Bio-ML track of the Ontology Alignment Evaluation Initiative (OAEI).
5.1.Digital health coaching
Digital Health Coaching is commonly required in health management. A paramount priority is centred on the delivery of context-sensitive, personalised, and explainable health recommendations, aiming to aid end-users in understanding and ameliorating their health conditions. Consider, for instance, individuals afflicted with Gastro-oesophageal Reflux Disease who are utilising Amitriptyline to alleviate back pain. The responsibility lies with the Digital Health Coach to understand that the use of Amitriptyline requires the simultaneous administration of another medication to safeguard the stomach, such as Antacids or Duloxetine. Therefore, it should deliver a recommendation that includes an explanation, such as “Given that Amitriptyline can exacerbate reflux issues, it is recommended to discuss your stomach condition with your doctor as preventative measures might be necessary.”
In health scenarios where explainability and in-depth reasoning are prioritised, fully automatic Deep Learning algorithms prove inappropriate due to inherent constraints. These include a dependency on vast datasets for optimal performance, an inability to reason abstractly, and a nature that is largely inscrutable to human comprehension. A rising trend to alleviate these issues involves integrating a symbolic knowledge base (e.g., OWL ontology) that facilitates rigorous and complex reasoning into the process. One of the tasks involves automatically identifying entities from semi-structured and/or unstructured data, and subsequently mapping them to the knowledge base. The BERTMap model, as discussed in Section 4.1, is utilised and evaluated in aligning health and/or medical concepts extracted from the NHS conditions2020 to concepts in the DOID ontology.2121
Table 2
Human evaluation results derived from the unanimous consensus of three domain experts, where a mapping is validated only when all experts are in complete agreement, for aligning medical concepts from NHS conditions to DOID concepts. Given DOID’s primary focus on diseases, non-disease concepts are categorised as out-of-scope
| System | With out-of-scope concepts | Without out-of-scope concepts | ||||
| Precision | Recall | F-score | Precision | Recall | F-score | |
| BERTMap | ||||||
| | 0.805 | 0.883 | 0.842 | 0.837 | 0.883 | 0.859 |
| | 0.922 | 0.820 | 0.868 | 0.937 | 0.820 | 0.874 |
| Sub-string Match | 0.965 | 0.489 | 0.649 | 0.965 | 0.489 | 0.649 |
The NHS conditions (at the time of investigation) consist of 984 concepts that cover health conditions, symptoms, medical treatments/tools, possible causes, and related daily-life situations. Each concept is associated with a web-page of detailed information. As the NHS conditions are essentially a collection of web-pages, we conducted simple transformation over them into a “flat” ontology, i.e., each term is modelled as an OWL ontology concept but there is no subsumption relationship among them. The concept names and aliases were manually collected from the web-pages to serve as concept labels. The DOID ontology has
5.2.Ontology alignment evaluation initiative
Table 3
Equivalence matching results for OMIM-ORDO (Disease) in the Bio-ML track of OAEI 2022
| System | Unsupervised (90% test mappings) | Semi-supervised (70% test mappings) | ||||||||
| Precision | Recall | F-score | MRR | Hits@1 | Precision | Recall | F-score | MRR | Hits@1 | |
| LogMap | 0.827 | 0.498 | 0.622 | 0.803 | 0.742 | 0.783 | 0.547 | 0.644 | 0.821 | 0.743 |
| LogMap-Lite | 0.935 | 0.259 | 0.405 | – | – | 0.932 | 0.519 | 0.667 | – | – |
| AMD | 0.664 | 0.565 | 0.611 | – | – | 0.792 | 0.528 | 0.633 | – | – |
| BERTMap | 0.730 | 0.572 | 0.641 | 0.873 | 0.817 | 0.575 | 0.784 | 0.664 | 0.965 | 0.947 |
| BERTMapLt | 0.819 | 0.499 | 0.620 | 0.776 | 0.729 | 0.775 | 0.713 | 0.743 | 0.900 | 0.876 |
| Matcha | 0.743 | 0.508 | 0.604 | – | – | 0.704 | 0.564 | 0.626 | – | – |
| Matcha-DL | – | – | – | – | – | 0.956 | 0.615 | 0.748 | 0.654 | 0.640 |
| ATMatcher | 0.940 | 0.247 | 0.391 | – | – | 0.835 | 0.286 | 0.426 | – | – |
| LSMatch | 0.650 | 0.221 | 0.329 | – | – | 0.877 | 0.238 | 0.374 | – | – |
Table 4
Subsumption matching results for SNOMED-NCIT (Neoplas) in Bio-ML track of OAEI 2022
| System | Unsupervised (90% test mappings) | Semi-supervised (70% test mappings) | ||||||
| MRR | Hits@1 | Hits@5 | Hits@10 | MRR | Hits@1 | Hits@5 | Hits@10 | |
| Word2Vec+RF | 0.512 | 0.368 | 0.694 | 0.834 | 0.577 | 0.433 | 0.773 | 0.880 |
| OWL2Vec*+RF | 0.603 | 0.461 | 0.782 | 0.860 | 0.666 | 0.547 | 0.827 | 0.880 |
| BERTSubs (IC) | 0.530 | 0.333 | 0.786 | 0.948 | 0.638 | 0.463 | 0.859 | 0.953 |
The Ontology Alignment Evaluation Initiative (OAEI) is an internationally coordinated initiative aiming at performing systematic assessments of ontology alignment techniques, also known as ontology matching (OM). As part of the OAEI 2022, we have introduced a new track, Bio-ML, replacing the previous LargeBio track. As detailed in Section 4.3, the objective of Bio-ML is to furnish datasets and a comprehensive framework for the evaluation of both traditional and machine learning-based OM systems.
The OAEI 2022 version of Bio-ML comprises two ontology pairs derived from Mondo and three pairs from UMLS (see data statistics in Table 1). Every pair is linked with two types of matching: equivalence and subsumption. The equivalence matching incorporates both global matching (evaluated using traditional metrics like Precision, Recall, and F-score) and local ranking (assessed using ranking metrics such as MRR and Hits@K). The subsumption matching, due to its inherent incompleteness of ground truth mappings, only has the local ranking setting. Moreover, for each matching setup, there are two settings for data split: unsupervised and semi-supervised. The unsupervised setting does not provide any training mapping, while the semi-supervised setup provides a small partition designated for training and development. Note that DeepOnto contributes to the construction of Bio-ML, the implementation of BERTMap and BERTMapLt systems, and the evaluation workaround.
The results for OMIM-ORDO equivalence matching and SNOMED-NCIT (Neoplas) subsumption matching are illustrated in Table 3 and Table 4, respectively. Full results can be accessed on the Bio-ML (OAEI 2022) webpage.2222 The findings from the Bio-ML track can be summarised as: (i) ML-based systems generally outperform others; (ii) no single system leads in all tasks, indicating that the effectiveness of systems varies based on the specific task; (iii) traditional OM systems struggle with the subsumption matching task, primarily due to their dependency on lexical similarity, which is very useful in equivalence matching but not that much in subsumption matching.
6.Conclusion and future work
In this system paper, we introduce DeepOnto, a Python library designed to facilitate ontology engineering with deep learning. The package provides a broad spectrum of ontology engineering capabilities, enabling users to (semi-)automatically and efficiently deal with ontologies and develop novel systems. The library relies on Python programming in synergy with deep learning methodologies, with a particular emphasis on pre-trained language models. For ease of use, DeepOnto has encapsulated basic ontology processing functions from OWL API, and implemented several essential components such as reasoning, verbalisation, pruning, taxonomy, and projection. Based on these features, DeepOnto has integrated a range of tools and resources for different ontology engineering tasks such as ontology alignment and completion, with comprehensive tutorials and detailed instructions2323 provided. Furthermore, we show evidence of DeepOnto’s successful applications in both industry and academia, with promising results reported in different application contexts.
For future development, we aim to incorporate more automated ontology engineering tasks. These include, but are not limited to, embedding concepts and properties with both formal semantics and literals considered, placing new concepts derived from text mentions into an ontology, generating descriptions for concepts based on their contexts in an ontology, and identifying, generating, and placing appropriate common parents for concepts clustered under certain criteria. These enhancements will lead to more ontology processing requirements, all of which will be seamlessly encapsulated into our API.
Notes
4 mOWL is not used as a direct dependency but parts of its functionalities (e.g., normalisation and projection) encapsulated in Java were migrated to DeepOnto to avoid duplicated implementations.
5 In this work, the term “class” refers to a blueprint for creating objects–encapsulating attributes and methods in Python programming.
6 For instance, when using the OWL API, retrieving subsumption axioms for different entity types requires distinct codes. We have consolidated these similar functions into a single Python method for easier use.
11 Note that ontology taxonomy can be seen as a special case of projection, but we separate the functionalities into different modules because the former is purely for hierarchy and the latter is for triples.
12 BERTMap tutorial: https://krr-oxford.github.io/DeepOnto/bertmap/.
13 BERTSubs tutorial: https://krr-oxford.github.io/DeepOnto/bertsubs/.
14 Bio-ML dataset download: https://zenodo.org/record/6946466.
15 Bio-ML instructions: https://krr-oxford.github.io/DeepOnto/bio-ml/.
16 Bio-ML Track of the OAEI: https://www.cs.ox.ac.uk/isg/projects/ConCur/oaei/.
17 OntoLAMA dataset download is available at Zenodo: https://zenodo.org/record/7700458, and Huggingface: https://huggingface.co/datasets/krr-oxford/OntoLAMA.
20 A list of medical concepts maintained by the National Health Service in the UK is available at: https://www.nhs.uk/conditions/.
21 DOID version IRI: http://purl.obolibrary.org/obo/doid/releases/2022-02-21/doid.owl.
22 Bio-ML Track (OAEI 2022) Results: https://www.cs.ox.ac.uk/isg/projects/ConCur/oaei/2022/index.html#results.
23 See the “TUTORIALS” section at https://krr-oxford.github.io/DeepOnto/.
Acknowledgements
This work was supported by Samsung Research UK (SRUK), and the EPSRC projects OASIS (EP/S032347/1), UK FIRES (EP/S019111/1) and ConCur (EP/V050869/1).
References
[1] | M. Abadi, TensorFlow: Learning functions at scale, in: Proceedings of the 21st ACM SIGPLAN International Conference on Functional Programming, (2016) , pp. 1–1. |
[2] | J.S. Amberger, C.A. Bocchini, F. Schiettecatte, A.F. Scott and A. Hamosh, OMIM.org: Online Mendelian Inheritance in Man (OMIM®), an online catalog of human genes and genetic disorders, Nucleic Acids Research 43(D1) ((2015) ), D789–D798. |
[3] | M. Amir, M. Baruah, M. Eslamialishah, S. Ehsani, A. Bahramali, S. Naddaf-Sh and S. Zarandioon, Truveta Mapper: A zero-shot ontology alignment framework, arXiv preprint, (2023) . arXiv:2301.09767. |
[4] | F. Baader, S. Brandt and C. Lutz, Pushing the EL envelope, in: Proceedings of the 19th International Joint Conference on Artificial Intelligence, (2005) , pp. 364–369. |
[5] | O. Bodenreider, The unified medical language system (UMLS): Integrating biomedical terminology, Nucleic acids research 32: (suppl_1) ((2004) ), D267–D270. doi:10.1093/nar/gkh061. |
[6] | B. Bohnet, V.Q. Tran, P. Verga, R. Aharoni, D. Andor, L.B. Soares, J. Eisenstein, K. Ganchev, J. Herzig, K. Hui et al., Attributed question answering: Evaluation and modeling for attributed large language models, arXiv preprint, (2022) . arXiv:2212.08037. |
[7] | J.J. Carroll, I. Dickinson, C. Dollin, D. Reynolds, A. Seaborne and K. Wilkinson, Jena: Implementing the semantic web recommendations, in: Proceedings of the 13th International World Wide Web Conference on Alternate Track Papers & Posters, (2004) , pp. 74–83. doi:10.1145/1013367.1013381. |
[8] | J. Chen, Y. He, Y. Geng, E. Jiménez-Ruiz, H. Dong and I. Horrocks, Contextual semantic embeddings for ontology subsumption prediction, World Wide Web ((2023) ), 1–23. |
[9] | J. Chen, P. Hu, E. Jimenez-Ruiz, O.M. Holter, D. Antonyrajah and I. Horrocks, Owl2vec*: Embedding of owl ontologies, Machine Learning 110: (7) ((2021) ), 1813–1845. doi:10.1007/s10994-021-05997-6. |
[10] | E. Choi, M.T. Bahadori, L. Song, W.F. Stewart and J. Sun, GRAM: Graph-based attention model for healthcare representation learning, in: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2017) , pp. 787–795. doi:10.1145/3097983.3098126. |
[11] | M. d’Aquin, A. Schlicht, H. Stuckenschmidt and M. Sabou, Ontology modularization for knowledge selection: Experiments and evaluations, in: Database and Expert Systems Applications: 18th International Conference, DEXA 2007, Regensburg, Germany, September 3–7, 2007, Proceedings 18, Springer, (2007) , pp. 874–883. |
[12] | J. Devlin, M.-W. Chang, K. Lee and K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, arXiv preprint, (2018) . arXiv:1810.04805. |
[13] | N. Ding, S. Hu, W. Zhao, Y. Chen, Z. Liu, H.-T. Zheng and M. Sun, Openprompt: An open-source framework for prompt-learning, arXiv preprint, (2021) . arXiv:2111.01998. |
[14] | H. Dong, J. Chen, Y. He, Y. Liu and I. Horrocks, Reveal the Unknown: Out-of-Knowledge-Base Mention Discovery with Entity Linking, arXiv preprint, (2023) . arXiv:2302.07189. |
[15] | K. Donnelly et al., SNOMED-CT: The advanced terminology and coding system for eHealth, Studies in Health Technology and Informatics 121: ((2006) ), 279. |
[16] | B. Glimm, I. Horrocks, B. Motik, G. Stoilos and Z. Wang, HermiT: An OWL 2 reasoner, Journal of Automated Reasoning 53: ((2014) ), 245–269. doi:10.1007/s10817-014-9305-1. |
[17] | Y. He, J. Chen, D. Antonyrajah and I. Horrocks, BERTMap: A BERT-based ontology alignment system, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36: , (2022) , pp. 5684–5691. |
[18] | Y. He, J. Chen, H. Dong and I. Horrocks, Exploring Large Language Models for Ontology Alignment, arXiv preprint, (2023) . arXiv:2309.07172. |
[19] | Y. He, J. Chen, H. Dong, E. Jiménez-Ruiz, A. Hadian and I. Horrocks, Machine learning-friendly biomedical datasets for equivalence and subsumption ontology matching, in: The Semantic Web–ISWC 2022: 21st International Semantic Web Conference, Virtual Event, October 23–27, 2022, Proceedings, Springer, (2022) , pp. 575–591. doi:10.1007/978-3-031-19433-7_33. |
[20] | Y. He, J. Chen, E. Jiménez-Ruiz, H. Dong and I. Horrocks, Language Model Analysis for Ontology Subsumption Inference, arXiv preprint, (2023) . arXiv:2302.06761. |
[21] | M. Horridge and S. Bechhofer, The owl api: A Java api for OWL ontologies, Semantic Web 2: (1) ((2011) ), 11–21. doi:10.3233/SW-2011-0025. |
[22] | K. Huang, J. Altosaar and R. Ranganath, Clinicalbert: Modeling clinical notes and predicting hospital readmission, arXiv preprint, (2019) . arXiv:1904.05342. |
[23] | M. Jackermeier, J. Chen and I. Horrocks, Box2 EL: Concept and role box embeddings for the description logic EL |
[24] | R.C. Jackson, J.P. Balhoff, E. Douglass, N.L. Harris, C.J. Mungall and J.A. Overton, ROBOT: A tool for automating ontology workflows, BMC Bioinformatics 20: ((2019) ), 1–10. doi:10.1186/s12859-018-2565-8. |
[25] | E. Jiménez-Ruiz and B. Cuenca Grau, Logmap: Logic-based and scalable ontology matching, in: The Semantic Web–ISWC 2011: 10th International Semantic Web Conference, Bonn, Germany, October 23–27, 2011, Proceedings, Part I 10, Springer, Bonn, Germany, (2011) , pp. 273–288. |
[26] | Y. Kazakov, M. Krötzsch and F. Simančík, ELK: A reasoner for OWL EL ontologies, system description, (2012) . http://code.google.com/p/elk-reasoner/wiki/Publications. |
[27] | M. Kulmanov, W. Liu-Wei, Y. Yan and R. Hoehndorf, El embeddings: Geometric construction of models for the description logic el |
[28] | J.-B. Lamy, Owlready: Ontology-oriented programming in Python with automatic classification and high level constructs for biomedical ontologies, Artificial Intelligence in Medicine 80: ((2017) ), 11–28. doi:10.1016/j.artmed.2017.07.002. |
[29] | Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma and R. Soricut, Albert: A Lite BERT for self-supervised learning of language representations, arXiv preprint, (2019) . arXiv:1909.11942. |
[30] | J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C.H. So and J. Kang, BioBERT: A pre-trained biomedical language representation model for biomedical text mining, Bioinformatics 36: (4) ((2020) ), 1234–1240. doi:10.1093/bioinformatics/btz682. |
[31] | N. Li, Z. Bouraoui and S. Schockaert, Ontology completion using graph convolutional networks, in: The Semantic Web–ISWC 2019: 18th International Semantic Web Conference, Auckland, New Zealand, October 26–30, 2019, Proceedings, Part I 18, Springer, (2019) , pp. 435–452. |
[32] | Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer and V. Stoyanov, Roberta: A robustly optimized bert pretraining approach, arXiv preprint, (2019) . arXiv:1907.11692. |
[33] | B. Motik, B.C. Grau, I. Horrocks, Z. Wu, A. Fokoue, C. Lutz et al., OWL 2 web ontology language profiles, W3C recommendation 27(61) ((2009) ). |
[34] | M.A. Musen, The protégé project: A look back and a look forward, AI Matters 1: (4) ((2015) ), 4–12. doi:10.1145/2757001.2757003. |
[35] | OpenAI, GPT-4 Technical Report, ArXiv abs/2303.08774 ((2023) ). https://api.semanticscholar.org/CorpusID:257532815. |
[36] | A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., Pytorch: An imperative style, high-performance deep learning library, Advances in Neural Information Processing Systems 32 ((2019) ). |
[37] | F. Petroni, T. Rocktäschel, S. Riedel, P. Lewis, A. Bakhtin, Y. Wu and A. Miller, Language models as knowledge bases? in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, (2019) , pp. 2463–2473. https://aclanthology.org/D19-1250. doi:10.18653/v1/D19-1250. |
[38] | M.A.N. Pour, A. Algergawy, P. Buche, L.J. Castro, J. Chen, H. Dong, O. Fallatah, D. Faria, I. Fundulaki, S. Hertling, Y. He, I. Horrocks, M. Huschka, L. Ibanescu, E. Jiménez-Ruiz, N. Karam, A. Laadhar, P. Lambrix, H. Li, Y. Li, F. Michel, E. Nasr, H. Paulheim, C. Pesquita, T. Saveta, P. Shvaiko, C. Trojahn, C. Verhey, M. Wu, B. Yaman, O. Zamazal and L. Zhou, Results of the ontology alignment evaluation initiative 2022, in: OM@ISWC, CEUR Workshop Proceedings, Vol. 3324: , CEUR-WS.org, (2022) , pp. 84–128. |
[39] | H. Rashkin, V. Nikolaev, M. Lamm, L. Aroyo, M. Collins, D. Das, S. Petrov, G.S. Tomar, I. Turc and D. Reitter, Measuring attribution in natural language generation models, Computational Linguistics ((2023) ), 1–64. doi:10.1162/coli_a_00490. |
[40] | C. Rosse and J.L. Mejino Jr., The foundational model of anatomy ontology, in: Anatomy Ontologies for Bioinformatics: Principles and Practice, Springer, (2008) , pp. 59–117. doi:10.1007/978-1-84628-885-2_4. |
[41] | L.M. Schriml, C. Arze, S. Nadendla, Y.-W.W. Chang, M. Mazaitis, V. Felix, G. Feng and W. Kibbe, Disease ontology: A backbone for disease semantic integration, Nucleic Acids Research 40: ((2012) ), D940–D946. doi:10.1093/nar/gkr972. |
[42] | N. Sioutos, S. de Coronado, M.W. Haber, F.W. Hartel, W.-L. Shaiu and L.W. Wright, NCI Thesaurus: A semantic model integrating cancer-related clinical and molecular information, Journal of Biomedical Informatics 40: (1) ((2007) ), 30–43. doi:10.1016/j.jbi.2006.02.013. |
[43] | A. Soylu, E. Kharlamov, D. Zheleznyakov, E. Jimenez-Ruiz, M. Giese, M.G. Skjæveland, D. Hovland, R. Schlatte, S. Brandt, H. Lie et al., OptiqueVQS: A visual query system over ontologies for industry, Semantic Web 9: (5) ((2018) ), 627–660. doi:10.3233/SW-180293. |
[44] | S. Staab and R. Studer, Handbook on Ontologies, Springer Science & Business Media, (2010) . |
[45] | H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., Llama 2: Open foundation and fine-tuned chat models, arXiv preprint, (2023) . arXiv:2307.09288. |
[46] | D. Vasant, L. Chanas, J. Malone, M. Hanauer, A. Olry, S. Jupp, P.N. Robinson, H. Parkinson and A. Rath, Ordo: An ontology connecting rare disease, epidemiology and genetic data, in: Proceedings of ISMB, Vol. 30: , ResearchGate.net, (2014) . |
[47] | N. Vasilevsky, S. Essaid, N. Matentzoglu, N.L. Harris, M. Haendel, P. Robinson and C.J. Mungall, Mondo disease ontology: Harmonizing disease concepts across the world, in: CEUR Workshop Proceedings, CEUR-WS, Vol. 2807: , (2020) . |
[48] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, Ł. Kaiser and I. Polosukhin, Attention is all you need, Advances in Neural Information Processing Systems 30 ((2017) ). |
[49] | Q. Wang, Z. Gao and R. Xu, Exploring the in-context learning ability of large language model for biomedical concept linking, arXiv preprint, (2023) . arXiv:2307.01137. |
[50] | Z. Wang, Contextualized Structural Self-supervised Learning for Ontology Matching, arXiv preprint, (2023) . arXiv:2310.03840. |
[51] | T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz et al., Huggingface’s transformers: State-of-the-art natural language processing, arXiv preprint, (2019) . arXiv:1910.03771. |
[52] | F. Zhapa-Camacho, M. Kulmanov and R. Hoehndorf, mOWL: Python library for machine learning with biomedical ontologies, Bioinformatics 39: (1) ((2023) ), btac811. doi:10.1093/bioinformatics/btac811. |


