1.Introduction
The separability problem deals with finding an intensional representation of two datasets, i.e., sets of data items, interpreted as positive and negative examples. In this problem, one is given two sets of data items, one with positive and the other with negative examples, and is asked to provide a query so that the evaluation of such a query over the database contains all the data items in the set of positive examples, and none of the data items in the set of negative examples. We say that a solution to this problem is a query that separates the given datasets. A special case of this problem arises when only one set of positive examples is given as input, and one is interested in finding a query whose evaluation over the database coincides with the data items in such a set. In this paper, we refer to the latter special case with the term characterizability, and we say that a solution to this problem is a query that characterizes the given dataset.
The separability problem has initially been studied for relational databases and is known in the community as the query-by-example problem.11 Over the years, researchers have found several interesting applications of the separability problem, spanning from simplifying query formulation by non-experts, to debugging facilities for data engineers. Indeed, the problem has been studied as a useful tool for data exploration, concept learning, data analysis, usability, data security and more [51,54]. Moreover, as already observed in [37], the problem is studied in two special cases in which the input datasets are constituted by only one single tuple. In separability, this special case is studied for entity comparison in RDF graphs, where the goal is to find a meaningful description that separates one entity from another. Similarly, in characterizability, this special case is studied for generating referring expressions (GRE), where one is interested in describing a single data item by a logical expression that allows to separate it from all other data items. With the rise of Machine Learning (ML), we argue that this topic acquires primary importance for providing meaningful explanations to any typical supervised black-box model used for classification tasks. When applied to classification, the ultimate goal of supervised learning is to construct models that are able to predict the target output (i.e., the class) of the proposed inputs. To achieve this, the learning algorithm is provided with some training examples that demonstrate the intended relation of input and output values. Then, the learned model is supposed to be able to correctly classify instances that have not been shown during training. A crucial problem for wise and safe adoption of ML-based black-box models is that, especially in high-risk domains such as healthcare and finance, it is often very hard to understand the rationale behind a classification made by these models. This may lead to discriminatory biases in the classification that were not intended and, more surprisingly, of which the designers were unaware of.
In this paper, we assume that the classification task is performed in an organization that adopts an Ontology-based Data Management (OBDM)22 approach [46,48]. OBDM is a paradigm for accessing data using a conceptual representation of the domain of interest expressed as an ontology. The OBDM paradigm relies on a three-level architecture, consisting of the data layer, the ontology, and the mapping between the two. Consequently, an OBDM specification is a triple J=⟨O,S,M⟩ which, together with an S-database D, form a so-called OBDM system Σ=⟨J,D⟩. We are going to tackle the separability problem by leveraging the notion of evaluation of a query with respect to an OBDM system, in turn based on the notion of certain answers to a query over an OBDM system. Intuitively, given an OBDM system Σ=⟨J,D⟩ and two D-datasets λ+ and λ−, our goal is to derive a query expression over O that separates λ+ and λ− in Σ (called here proper separation).
Example 1.
Let J=⟨O,S,M⟩ be the OBDM specification in which O={MathStudent⊑Student,ForeignStudent⊑Student} asserts that both math students and foreign students are students, S={s1,s2,s3,s4,s5}, and the mapping M consists of the following assertions:
{(x)∣s1(x)}→{(x)∣Student(x)}{(x)∣s2(x)}→{(x)∣Student(x)}{(x1,x2)∣s3(x1,x2)}→{(x1,x2)∣EnrolledIn(x1,x2)}{(x)∣∃y.s3(x,y)∧s4(y)}→{(x)∣MathStudent(x)}{(x)∣∃y.s3(x,y)∧s5(y)}→{(x)∣ForeignStudent(x)}
Consider now the OBDM system Σ=⟨J,D⟩, where J is the OBDM specification illustrated above and D is the S-database D={s1(c4),s2(c3),s4(b1),s5(d1),s3(c1,b1),s3(c2,d1),s3(c3,e1),s3(c4,e2),s3(c5,e3)}. Let the D-datasets of positive and negative examples be λ1+={(c1),(c2),(c3)} and λ1−={(c5)}, respectively. One can see that the query qO1={(x)∣ Student(x)} over O separates λ1+ and λ1− in Σ because its set of certain answers over Σ, {(c1),(c2),(c3),(c4)}, contains all the positive examples in λ+ and none of the negative examples in λ−.
An important contribution of our work is to provide approximated results for all the cases in which it is not possible to provide a separating query. We argue that, in these cases, reasonable and useful ontological characterizations can still be provided. We propose to resort to suitable approximations of the proper separating query, by introducing the notions of sound and complete separating queries. The former is a query whose certain answers have empty intersection with the D-dataset λ−, whereas the certain answers of the latter form a superset of the D-dataset λ+. Obviously, we are interested in computing the best approximated separating queries, which we call maximally sound and minimally complete separations, respectively. A maximally sound (resp., minimally complete) separation is a sound (resp., complete) separation such that no other sound (resp., complete) separation exists that better approximates the input datasets. Moreover, we cover the special cases in which the input datasets are constituted by only one single tuple for all our results and refer to them as the single tuple variants of the problems we deal with.
In this context, the training set used in the classification task, which is a collection of data items that are labeled as positive and negative examples, is seen as two sets of tuples in the database schema. The query derived by solving the separability problem results into an intensional definition of such training set, and are considered as an explanation of the intensional properties of the training set. The same principle can also be applied to a set of tuples that has not been seen during the training of the model. In this scenario, one can consider the black-box model as an oracle that assigns a class to all given tuples. Then, the query derived by solving the separability problem in this new context, is considered as an explanation of the intrinsic behaviour of the model. Traditionally, there are two different types of explanations: global and local. We refer to the former for explanations of the general behaviour of the model, and to the latter for explanations of the output of the model with respect to a specific object. The present work poses the foundational basis for providing both kind of explanations. Indeed, it deals with global explanations when the separating query is searched with respect to positive and negative examples containing and arbitrary number of tuples. It deals with local explanations when the sets of positive and negative examples for which one searches for a separating query contain only one single tuple.
Our procedure fits into the definition of post-hoc explanations of black-box models, i.e. a set of techniques aimed at approximating the behaviour of a black-box model with a surrogate interpretable model. We are now going to describe how in our context the role of the surrogate model is played by the query resulting from the solution of the separability problem. Suppose an organization that adopts the OBDM paradigm wants to train a model for predicting which candidates in a selection process are the most likely to perform well in a certain job. For training the model, the organization is given the curricula of current employees with a feedback on their performances that makes it possible to divide the training set in two different classes: the good and bad performers. For the sake of simplicity, suppose John, Mary, and Jane, who studied Biology, Medicine, and Math respectively, perform well. Suppose also that Matt, Angeline, and Jess, who studied Music, Linguistics, and Fashion respectively, perform badly. The ML-based black-box model is trained with this dataset and it is optimised to reach the highest possible accuracy. Now suppose some candidates apply for the job and are evaluated by the model. The latter states that Lucy, Mara, and George, who studied Math, Chemistry, and Physics respectively, have high probability to perform well in doing the job. At the same time, the model states that Lucas, and Paul, who studied Art, and Classics are believed to perform badly. The organization now wonders why the black-box model divided the candidates in this way. By instantiating a separability problem with the two sets of positive and negative candidates, the organization finds out that, no matter how sophisticated the internal details of the black-box model are, the resulting classification is so that all positive candidates are answers to the query “return all the candidates with a scientific background”, and none of the negative candidates are. This separating query provides an intuitive explanation of the actual behaviour of the model. Of course, there are in general many valid separating queries for a given instance of a separability problem, as it is possible that in many cases there is no valid separating query at all.
Contributions of the paper The contribution provided by this paper can be summarized as follows:
– We present a formal framework for separability in OBDM. In particular, we first cast the classical notion of separating query in the OBDM context (called here proper separation), and then we propose the relaxations mentioned above (complete separation and sound separation) as well as their optimal versions (minimally complete separation and maximally sound separation). We do exactly the same for the special case of characterization, which deals only with a dataset of positive examples rather than both positive and negative examples.
– We study the Verification problem for both separability and characterizability in OBDM, i.e. check whether a given query is a proper, complete, or sound separation (resp., characterization) of two given datasets (resp., a given dataset). More specifically, we introduce three families of decision problems for both separability and characterizability, called X-VSEP(LO, LM, Q) (resp., X-VCHAR(LO, LM, Q)) for X = {Proper, Complete, Sound}, which are parametric with respect to an ontology language LO, a mapping language LM, and a query language Q. We provide tight computational complexity bounds for the most common languages used in OBDM, i.e., LO is DL-LiteR, LM is GLAV, and Q is UCQ. The results are summarized in Table 1.
– We study the Computation problem. We provide two algorithms that, taking as input an OBDM system Σ=⟨O,S,M,D⟩ and two D-datasets λ+ and λ−, where O is a DL-LiteR ontology and M is a GLAV mapping, return, respectively, a UCQ-minimally complete Σ-separation of λ+ and λ− and a UCQ-maximally sound Σ-separation of λ+ and λ−. As a consequence, this proves that in the scenario under consideration the two best approximated versions of proper separations always exist.
– We study the Existence problem for both separability and characterizability in OBDM. Since for the scenario under consideration their two best approximated versions always exist, we only focus on the existence of a proper separation (resp., characterization), i.e., check whether a proper separation (resp., characterization) in a target query language Q of two given datasets (resp., a given dataset) exists at all. More specifically, we introduce a family of decision problems for both separability and characterizability, called SEP(LO, LM, Q) (resp., CHAR(LO, LM, Q)), which are parametric with respect to an ontology language LO, a mapping language LM, and a query language Q. Also in this case, we provide tight computational complexity bounds for the most common languages used in OBDM. The results are summarized in Table 2.
Table 1
For X = {Proper, Complete, Sound}, the table reports the exact computational complexity of X-VSEP(LO, LM, Q) and X-VCHAR(LO, LM, Q) when LO is DL-LiteR, LM is GLAV, and Q is UCQ. We point out that all the lower bounds already hold for the single-tuple version of the considered problem (i.e., when all the input datasets consist of a single tuple) and when LO is ∅ (i.e., the ontology language allowing only for ontologies without assertions), LM is GAV∩LAV (i.e., the mapping language allowing only for assertions that are both GAV and LAV), and Q is CQ
| X-VSEP(DL-LiteR, GLAV, UCQ)/X-VCHAR(DL-LiteR, GLAV, UCQ) |
| X = Complete | NP-complete |
| X = Sound | coNP-complete |
| X = Proper | DP-complete |
Table 2
For LM={LAV,GAV,GLAV}, the table reports the exact computational complexity of SEP(LO,LM,Q) and CHAR(LO,LM,Q) when LO is DL-LiteR and Q is UCQ. Again, all the lower bounds already hold for the single-tuple version of the considered problem and when LO is ∅. Moreover, such lower bounds hold for both Q=CQ and Q=UCQ
| SEP(DL-LiteR,LM,UCQ)/CHAR(DL-LiteR,LM,UCQ) |
| LM=LAV | coNP-complete |
| LM=GAV | Θ2p-complete |
| LM=GLAV | Π3p-complete |
This paper is an extended version of our CIKM’21 conference paper [22]. We point out that the conference paper focused only on the characterizability reasoning task, whereas here we illustrate a formal framework and study the related computational problems both for separability and characterizability. Furthermore, in this extended version we provide all the full proofs that were only sketched in [22]. Finally, we observe that the CHAR(DL-LiteR,GLAV,UCQ) decision problem is incorrectly claimed to be CONEXPTIME-complete in the conference version of this paper. In this extended version, we fix this error and show that this decision problem is actually Π3p-complete.
To the best of our knowledge, the present work is the first to introduce separability and characterizability in the OBDM context. In particular, while separability and characterizability have been studied in various ontology-enriched query answering settings, this is the first to take into account all the layers stack of the OBDM paradigm, thus including also the mapping layer, and also propose and study natural relaxations of the separability and characterizability notions. Nevertheless, we remark that both in the Computation and in the Existence problems for separability and characterizability we mainly focus only on UCQ as a query language, while other works on the subject also investigate the typically more challenging scenario of CQ as a query language (see, e.g., [7,30,34,64]).
Finally, we mention that, since DL-LiteR is insensitive to the adoption of the unique name assumption (UNA) for UCQ answering [5], all our results hold both with and without the UNA.
Outline of the paper The paper is organized as follows. After the discussion of related works in Section 2, Section 3 introduces the relevant background for our study and Section 4 illustrates a formal framework for separation in OBDM. Then, Sections 5, 6, and 7 present the results on the three computational problems Verification, Computation, and Existence, respectively. We deal first with the Computation problem and then with the Existence problem because the solutions we will provide about the Computation problem will help us to solve some tasks about the Existence problem. Finally, Section 8 concludes the paper with a perspective on future work.
2.Related work
Query definability and query-by-example have long been studied for classical databases, starting from [70] up to many recent studies [3,7,41,52,64,65,68]. We have laid the foundations for analysing the complexity of our decision problems from the results in [3,7]. We found the work in [65] inspirational since they dealt with the problem of deriving a metric for establishing how close is a non proper separating query to the optimal solution. We found the survey in [52] important for the whole research problem as they present a well described motivating example and they outline the main open problems of this topic.
Our work has also been inspired by the notion of Abstraction [19,20,23]. Although the goal is still to derive a query expression over the ontology, in that work the input is a query over the data layer of the OBDM architecture, whereas in query definability (resp. in query-by-example) the input is a set of tuples (or two sets of tuples). It follows that the two tasks are completely different and require different technical solutions. We postpone a detailed comparison between Abstraction and the separability notion investigated in this paper in Section 4.1 (when we will have all the technical tools in hand to provide an in-depth comparison).
The works that are closer to ours are the ones in [4,34,55]. In [4] the authors study the existence, and verification problems both for query definability and for query-by-example, and computation problem for the query definability case. In their work, the ontology is expressed as an RDF graph and they consider several fragments of SPARQL as the query language to be used for the separation of the examples. Differently from the present work, they do not aim at finding the best approximated separation. We share with [55] the expressive power of the language used for the ontology (DL-Lite), and for the separation query the input examples (UCQs). However, the work in [55] does not deal with the cases in which proper separations for the input examples do not exist, and it is based on a slightly different framework from ours, i.e. since in that work they study the problems in the context of ontology-mediated queries, they do not have the mapping layer that instead is part of our more general OBDM paradigm.
The work in [34], studies the query-by-example problem for expressive horn description logic ontologies, namely Horn-ALCI. Apart from the clear difference in the expressive power of the ontologies, their work does not consider the case of approximated separations of the input examples, and it does not consider the mapping layer.
This work has also been inspired by [11,31,38,44]. All these papers’ goal is to learn a concept expression that best captures a given set of examples (or two set of positive and negative examples for query-by-example). We differ from these works because our goal is to derive a full-blown query that separates the input examples.
The problem of checking whether there exists a formula separating positive and negative examples in the presence of an ontology has recently been studied in [37,40]. Other than verifying that the ontology entails the searched formula for all positive examples, the authors conducted an in-depth analysis of the so-called separability problem accounting for both weak separability, i.e. the one we study in this paper, and strong separability, i.e. checking whether the negation of the separating formula is entailed by the KB. They also consider the case of enriching the separating formula by adding helper symbols that are not originally present in the ontology, and study the complexity of the decision problems for a wide range of languages both for expressing the ontology and the separating formula. In this paper, we are interested in studying the weak separability problem in the context of the OBDM by also considering the cases in which the separating formula does not exist and one wants to search for sound and complete approximations of it.
Another important line of research related to the present work is the one regarding post-hoc explanations of opaque machine learning models. As also highlighted by other works [25,26,49,60], the query-by-example problem can easily be adapted for explaining the output of a black-box machine learning classification model. For example, consider the case of a binary classifier labelling a set of examples in two classes 1 and 0. In this scenario, the solution of the query-by-example problem is considered as a surrogate of the machine learning model, so that the examples labelled by class 1 are the answers of the reverse engineered query, while none of the examples labelled by class 0 are. Therefore the query acts as an explanation because it provides a more human understandable way, especially in our framework in which the query is based on the knowledge of the ontology, for classifying the given examples in the two different classes. Although relevant for our work, we differ from all the above cited papers. In [60], they map the inputs of the machine learning classifier to the ontology and then uses a concept learning tool to find a class expression over the ontology that best describes the positive example. In [25], for explaining the behaviour of a black-box classifier, they build another black-box classifier (a neural network) and then project the output of this latter model onto a so-called rule space, where each coordinate represents the activation of a rule that is described in First Order Logic. In [26] they present the TREPAN algorithm, i.e. a way for building a decision tree in which the nodes are linked to an ontology, that is used as a means for explaining the input positive and negative examples. We consider the work in [49] to be relevant for our work, even though is rather preliminary and does not specify many important details such as the expressive power of the language of the ontology, and the language of the query they search for. The biggest differences with the present work are the fact that they do not consider the mapping layer between the ontology and the data, and that they do not focus on the concepts of maximally-sound and minimally-complete solutions, in cases where a perfect solution does not exist. On the contrary, they define a best approximated query as the one minimising the jaccard distance between the answers of the query and the set of positive examples in the input.
Inductive Logic Programming (ILP) [43] has long been considered related to the query definability and query-by-example tasks. We also considered it inspiring for our work, but we soon acknowledged that the expressive power of the languages used for representing the knowledge base are incomparable, and that in ILP they are interested in searching for explanations of a set of logical facts rather than a set of tuples.
The Active Learning task initially introduced by [2] has been studied as a possible framework for learning queries from examples in relational databases [64] and in the presence of DL-Lite ontologies [30]. Moreover, instances of the framework in [2] can be found in [42] and in [57]. In particular, the goal of [42] is to learn an ontology that is equivalent to a target ontology, while the goal of [57] is to learn an ontology that is query inseparable with respect to a target ontology T and a query language Q, i.e. given a set of ground atoms (ABox) A, the learned ontology H must be such that ⟨H,A⟩⊧q if and only if ⟨T,A⟩⊧q, for every q∈Q.
Finally, query inseparability has been studied even outside the learning task. For example, [9] studies query inseparability for (fragments of) Horn-ALC as ontology language and CQ as a query language, whereas [10] studies query inseparability for both the ontology languages ALC and EL and for (fragments of) UCQ as a query language.
3.Preliminaries
We recall some notions about relational databases [1], Description Logics (DLs) [6], and Ontology-based Data Management (OBDM) [47]. We define ΓS, ΓO, Const, and V to be the pairwise disjoint, countably infinite sets of symbols for database predicates, ontology predicates, constants, and variables, respectively. We further assume that ΓO is partitioned into the disjoint sets ΓA and ΓP for atomic concepts and atomic roles, respectively.
Databases, datasets, and queries A relational database schema (or simply schema) S is a finite subset of ΓS. Given a schema S, an S-database D is a finite set of facts (a.k.a. ground atoms) of the form s(c→), where s is an n-ary predicate in S, and c→=(c1,…,cn) is an n-tuple of constants from Const. We denote by dom(D) the finite subset of Const of those constants occurring in D. Given a schema S and an S-database D, a D-dataset λ of arity n is simply a finite set of n-tuples c→ of constants occurring in D, i.e., λ⊆dom(D)n.
A query qS over a schema S is an expression in a certain query language Q using the predicate symbols of S and arguments of predicates are variables from V, i.e., we disallow constants to occur in queries. Each query has an associated arity. The evaluation of a query qS of arity n over an S-database D is a set of answers qSD, each answer being an n-tuple of constants occurring in dom(D), i.e., qSD⊆dom(D)n. A query qS of arity 0 over a schema S is called a boolean query, and we denote by qSD={⟨⟩} (resp., qSD=∅) the fact that D⊧qS (resp., D⊭qS).
Following the terminology of [7,63], we say that a query qS over a schema S explains two D-datasets λ+ and λ− (resp., defines a D-dataset λ+) inside an S-database D if λ+⊆qSD and qSD∩λ−=∅ (resp., qSD=λ+). We also say that λ+ and λ− are Q-explainable (resp., λ+ is Q-definable) inside D, for a query language Q, if there exists a query qS∈Q that explains λ+ and λ− (resp., defines λ+) inside D.
We are particularly interested in conjunctive queries and unions thereof. A conjunctive query (CQ) over a schema S is an expression of the form qS={x→∣∃y→.ϕ(x→,y→)} such that (i) x→=(x1,…,xn), called the target list of qS, is an n-tuple of distinguished variables from V, where n is the arity of qS (ii) y→=(y1,…,ym) is an m-tuple of existential variables from V; and (iii) ϕ(x→,y→), called the body of qS, is a finite conjunction of atoms of the form s(v1,…,vp), where s is an p-ary predicate in S and vi is either a distinguished or an existential variable, i.e., vi∈x→∪y→ for each i∈[1,p]. A union of conjunctive queries (UCQ) qS over a schema S is a finite set {x1→∣∃y1→.ϕ1(x1→,y1→)}∪⋯∪{xm→∣∃ym→.ϕm(xm→,ym→)} of CQs over S with same arity, called its disjuncts.
For a conjunction of atoms ϕ(x→,y→), we denote by set(ϕ) the set of all the atoms occurring in ϕ. For a set of atoms C and a tuple c→=(c1,…,cn) of constants, we denote by query(C,c→) the CQ {x→∣∃y→.ϕ(x→,y→)}, where (i) ϕ(x→,y→) is the conjunction of all the atoms occurring in the set of atoms C′, where C′ is obtained from C by replacing everywhere each constant ci occurring in c→ with a fresh variable xci and each constant c not occurring in c→ with a fresh variable yc, (ii) x→=(xc1,…,xcn), and (iii) y→ is the tuple of all variables occurring in C′ that do not occur in x→.
Given a set of atoms C, we denote by dom(C) the set of all constants and variables occurring in C. Observe that dom(C)⊆Const∪V. Let C1 and C2 be two sets of atoms. We say that a function h:dom(C1)→dom(C2) is a homomorphism from C1 to C2 if h(C1)⊆C2, where h(C1) is the image of C1 under h, i.e., h(C1)={h(α)∣α∈C1} with h(s(t1,…,tn))=s(h(t1),…,h(tn)) for each atom α=s(t1,…,tn). For two sets of atoms C1 and C2 and two tuples of terms t1→ and t2→, we write (C1,t1→)→(C2,t2→) if there is a function h from dom(C1)∪t1→ to dom(C2)∪t2→ such that (i) h is a homomorphism from C1 to C2, and (ii) h(t1→)=t2→ (where, for a tuple of terms t→=(t1,…,tn), h(t→)=(h(t1),…,h(tn))), (C1,t1→)↛(C2,t2→) otherwise.
We define the semantics of (U)CQs in terms of homomorphisms. For an S-database D and a CQ qS={x→∣∃y→.ϕ(x→,y→)} over S of arity n, we let qSD to be the set of n-tuples c→ of constants occurring in D for which (set(ϕ),x→)→(D,c→). Furthermore, for an S-database D and a UCQ qS=q1∪⋯∪qm over S, we let qSD=q1D∪⋯∪qmD.
Syntax and semantics of DL-LiteR In this paper, a DL ontology (or simply ontology) O is a TBox (“Terminological Box”) expressed in a specific DL, that is, a finite set of assertions stating general properties of atomic concepts and roles built according to the syntax of the specific DL, which represents the intensional knowledge of a modeled domain. The alphabet of an ontology O is the finite subset of ΓO of atomic concepts and atomic roles mentioned in the assertions of O, and we assume that every ontology O comprises the special bottom concept ⊥ in its alphabet. In this paper, whenever we speak of a query qO over an ontology O, we implicitly mean a query in a certain query language Q that uses the atomic concepts and the atomic roles in the alphabet of O as predicate symbols.
The semantics of DL ontologies is specified through the notion of first-order interpretations: an interpretation I is a pair I=⟨ΔI,·I⟩, where the interpretation domain ΔI is a non-empty, possibly infinite set of objects, and the interpretation function ·I assigns to each constant c∈Const an object cI∈ΔI, to each atomic concept A∈ΓA a subset AI of ΔI (with the requirement ⊥I=∅), and to each atomic role P∈ΓP a subset PI of ΔI×ΔI. We say that an interpretation I satisfies an ontology O, denoted by I⊧O, if I satisfies every assertion in O. When convenient, with a slight abuse of notation, we treat an interpretation I as the (potentially infinite) set of facts of the form A(o) and P(o1,o2) that are true in I, i.e., that are such that o∈AI and (o1,o2)∈PI.
We are particularly interested in DL ontologies expressed in DL-LiteR, the member of the DL-Lite family [15] that underpins OWL 2 QL, i.e., the OWL 2 profile especially designed for efficient query answering [53]. A DL-LiteR ontology O is a finite set of assertions of the form:
B1⊑B2R1⊑R2(concept/role inclusion)B1⊑¬B2R1⊑¬R2(concept/role disjointness)
where
B1,
B2 are
basic concepts, i.e., expressions of the form
A,
∃P, or
∃P−, with
A∈ΓA and
P∈ΓP, and
R1 and
R2 basic roles, i.e., expressions of the form
P, or
P− with
P∈ΓP. We assume that the special bottom concept ⊥ never occurs in the right-hand side of inclusion assertions. This is without loss of generality, since each inclusion assertion of the form
B⊑⊥ is logically equivalent to the disjointness assertion
B⊑¬B.
For the constructs of DL-LiteR, the interpretation function ·I of an interpretation I=⟨ΔI,·I⟩ extends to basic concepts and basic roles as follows: (∃P)I={o∣∃o′.(o,o′)∈PI} and (P−)I={(o,o′)∣(o′,o)∈PI}. Finally, an interpretation I satisfies a concept inclusion assertion B1⊑B2 (respectively, role inclusion assertion R1⊑R2) if B1I⊆B2I (respectively, R1I⊆R2I), and it satisfies a concept disjointness assertion B1⊑¬B2 (respectively, role disjointness assertion R1⊑¬R2) if B1I∩B2I=∅ (respectively, R1I∩R2I=∅).
Syntax and semantics of ontology-based data management According to [47,58], an Ontology-based Data Management (OBDM) specification is a triple J=⟨O,S,M⟩, where O is a DL ontology, S is a relational database schema, also called source schema, and M is a mapping, i.e., a finite set of assertions relating the source schema S to the ontology O. An OBDM system is a pair Σ=⟨J,D⟩, where J=⟨O,S,M⟩ is an OBDM specification and D is an S-database. For readability purposes, with a slight abuse of notation, we sometimes denote an OBDM system as a quadruple Σ=⟨O,S,M,D⟩, where ⟨O,S,M⟩ is an OBDM specification and D is an S-database.
In this paper, each assertion in the mapping component of an OBDM system is a Global-And-Local-As-View (GLAV) assertion [27], that is, an assertion of the form qS→qO, where qS and qO are CQs over S and over O, respectively, with the same target list x→=(x1,…,xn). Special cases of GLAV assertions highly considered in the data integration literature are Global-As-View (GAV) and Local-As-View (LAV) assertions [45]: in a GAV (resp., LAV) assertion, qO (resp., qS) is simply an atom without existential variables. Finally, a GLAV (resp., GAV, LAV, GAV∩LAV) mapping M consists in a finite set of GLAV (resp., GAV, LAV, both GAV and LAV) assertions.
Given a GLAV mapping M relating a source schema S to an ontology O, an interpretation I, and an S-database D, we denote by ⟨I,D⟩⊧M the fact that (c1,…,cn)∈qSD implies (c1I,…,cnI)∈qOI for each possible mapping assertion qS→qO in M and for each possible tuple (c1,…,cn) of constants occurring in D. Here, qOI denotes the evaluation of qO over the interpretation I seen as a (potentially infinite) set of facts.
As customary in OBDM, we define the semantics of OBDM systems Σ=⟨O,S,M,D⟩ by specifying which are the first-order models of the OBDM specification ⟨O,S,M⟩ relative to the S-database D. Specifically, we say that an interpretation I is a model of an OBDM system Σ=⟨O,S,M,D⟩ if (i) I⊧O, and (ii) ⟨I,D⟩⊧M. Finally, we say that an OBDM system Σ is consistent if it has at least one model, inconsistent otherwise.
For an OBDM system Σ=⟨J,D⟩, with J=⟨O,S,M⟩, and a query qO over O, we denote by certqO,JD the set of certain answers of qO w.r.t. Σ, i.e., the set of tuples of constants (c1,…,cn) occurring in D such that (c1I,…,cnI)∈qOI for each model I of Σ. If Σ is inconsistent, then the set of certain answers of any query qO over O w.r.t. Σ is simply the set of all possible tuples of constants occurring in D whose arity is the one of the query. Finally, we say that two queries q1 and q2 are equivalent w.r.t. an OBDM system Σ=⟨J,D⟩ if certq1,JD=certq2,JD.
Query rewriting Given a UCQ qO over a DL-LiteR ontology O, we denote by PerfectRef(O,qO) the UCQ computed by executing the algorithm PerfectRef [15] on O and qO (slightly extended to deal also with the bottom concept ⊥). In a nutshell, the PerfectRef algorithm uses the concept/role inclusions of the input DL-LiteR ontology O as rewriting rules applied to the input UCQ qO. In this way, it compiles into the query qO all the knowledge provided by O that is relevant to answering the query. PerfectRef applies repeatedly the following two steps until a fixpoint is reached: step (i) uses concept/role inclusions as rewriting rules to rewrite query atoms one by one, each time producing a new CQ to be added to the final output; step (ii) unifies the query atoms to enable further executions of step (i). For additional details, we refer the reader to [15].
Let J=⟨O,S,M⟩ be an OBDM specification where O=∅, i.e., O has no assertions, and M is a GLAV mapping. From results of [17,29], it is well-known that, given a UCQ qO over O, by splitting the GLAV mapping M into a GAV mapping followed by a LAV mapping over an intermediate alphabet, it is always possible to compute a UCQ over S, denoted by MapRef(M,qO), such that MapRef(M,qO)D=certqO,JD for each S-database D.
Now, let J=⟨O,S,M⟩ be an OBDM specification where O is a DL-LiteR ontology and M is a GLAV mapping. Given a UCQ qO over O, in what follows, we denote by rewqO,J the following UCQ over S: rewqO,J:=MapRef(M,PerfectRef(O,qO)). By combining the above observation regarding MapRef with the correctness of the PerfectRef algorithm [15] and the fact that DL-LiteR is insensitive to the adoption of the UNA for UCQ answering [5], we derive that certqO,JD=rewqO,JD holds for each UCQ qO over O and for each S-database D such that ⟨J,D⟩ is consistent. Furthermore, by combining the above observation regarding MapRef with results of [58], we derive that, given an S-database D, the OBDM system ⟨J,D⟩ is inconsistent if and only if rewVO,JD={⟨⟩}. Here, VO is the O-violation query, i.e., the boolean UCQ over O constituted by the disjunct {()∣∃y.⊥(y)} and a disjunct of the form {()∣∃y.A1(y)∧A2(y)} (respectively, {()∣∃y1,y2.A1(y1)∧R(y1,y2)}, {()∣∃y1,y2,y3.R1(y1,y2)∧R2(y1,y3)}, and {()∣∃y1,y2.R1(y1,y2)∧R2(y1,y2)}) for each disjointness assertion A1⊑¬A2 (respectively, A1⊑¬∃R or ∃R⊑¬A1, ∃R1⊑¬∃R2, and R1⊑¬R2) occurring in O, where an atom of the form R(y,y′) stands for either P(y,y′) if R denotes an atomic role P, or P(y′,y) if R denotes the inverse of an atomic role, i.e., R=P−.
Canonical structure Given an S-database D and a GLAV mapping M relating a source schema S to an ontology O, the chase [13] of D with respect to M, denoted by M(D), is the set of atoms computed as follows: (i) M(D) is initially set to the empty set of atoms; then (ii) for every GLAV assertion {x→∣∃y→.ϕS(x→,y→)}→{x→∣∃z→.φO(x→,z→)} in M and for every tuple c→ of constants occurring in D such that (set(ϕS),x→)→(D,c→), we add to M(D) the image of the set of atoms set(φO) under h′, that is, we set M(D):=M(D)∪h′(φO(x→,z→)), where h′ extends h by assigning to each variable z occurring in z→ a different fresh variable of V still not present in dom(M(D)). Observe that M(D) is guaranteed to be finite and can be always computed in exponential time.
We conclude this section with the following observation used for the technical development of the next sections. Let Σ=⟨O,S,M,D⟩ be an OBDM system where O is a DL-LiteR ontology and M is a GLAV mapping. The canonical structure of O with respect to M and D, denoted by COM(D), is the (potentially infinite) set of atoms obtained by first computing M(D) as described before, and then by chasing M(D) with respect to the inclusion assertions of O as described in [15, Definition 5] but using the alphabet V of variables whenever a new element is needed in the chase. Observe that this latter is a fair deterministic strategy, i.e., it is such that if at some point an assertion is applicable, then it will be eventually applied. By combining [28, Proposition 4.2] with [15, Theorem 29], it is well-known that, for a UCQ qO={x1→∣∃y1→.ϕO1(x1→,y1→)}∪⋯∪{xp→∣∃yp→.ϕOp(xp→,yp→)} over O and a tuple c→ of constants occurring in D, if Σ=⟨J,D⟩ is consistent, then the following holds: c→∈certqO,JD if and only if (set(ϕOi),xi→)→(COM(D),c→) for some i∈[1,p].
4.Formal framework
In what follows, we implicitly use Σ=⟨J,D⟩ to denote an OBDM system, where J=⟨O,S,M⟩ is an OBDM specification and D is an S-database. Intuitively, given two sets λ+ and λ− of tuples of constants occurring in D (i.e., λ+ and λ− are D-datasets) of positive and negative examples, respectively, we aim at finding a query qO over the ontology O in a certain target query language Q that logically separates λ+ and λ− w.r.t. Σ. Since the evaluation of queries in OBDM systems is based on certain answers, we are naturally led to the following definition.
Definition 1.
qO∈Q is a proper Σ-separation of λ+ and λ− in the query language Q, if both conditions (i) λ+⊆certqO,JD and (ii) certqO,JD∩λ−=∅ hold.
The next example illustrates the above definition.
Example 2.
Recall the OBDM system Σ=⟨J,D⟩, the D-datasets λ1+={(c1),(c2),(c3)} and λ1−={(c5)}, and the CQ qO1 over the ontology O illustrated in Example 1. As already observed, we have that certqO1,JD={(c1),(c2),(c3),(c4)}, and therefore qO1 is a proper Σ-separation of λ1+ and λ1− in CQ.
Consider now a slight variation of the negative examples, i.e., consider λ+=λ1+ and λ−={(c4),(c5)}. Since qO1 and qO2={(x)∣∃y.EnrolledIn(x,y)} are such that certqO1,JD={(c1),(c2),(c3),(c4)} and certqO2,JD={(c1),(c2),(c3),(c4),(c5)}, and since qO3={(x)∣MathStudent(x)} and qO4={(x)∣ ForeignStudent(x)} are such that certqO3,JD={(c1)} and certqO4,JD={(c2)}, one can verify that no proper Σ-separation of λ+ and λ− in UCQ exists.
Clearly, the more expressive the target query language Q, the more likely it is possible to distinguish (w.r.t. the OBDM system) the properties between the tuples in λ+ and λ− by means of the operators in Q, and therefore the more likely the proper separation in Q exists. Unfortunately, the next example shows that, even in trivial cases and without any restriction on the target query language Q, proper separations are not guaranteed to exist.
Example 3.
Let Σ=⟨J,D⟩ be the following OBDM system: (i) J=⟨O,S,M⟩ is the OBDM specification in which O=∅, i.e., O contains no assertions, S={s1,s2}, and M={m1,m2} with m1={(x)∣s1(x)}→{(x)∣A(x)} and m2={(x)∣s2(x)}→{(x)∣A(x)}; and (ii) D is the S-database D={s1(c1),s2(c2)}.
For the D-datasets λ+={(c1)} and λ−={(c2)}, one can trivially verify that, whatever is the query language Q, there can be no query qO∈Q over O for which certqO,JD include the tuple (c1) but does not include the tuple (c2). To see this, note that COM(D)={A(c1),A(c2)}. It follows that, whatever is the query language Q, there can be no query qO∈Q over O which is a proper Σ-separation of λ+ and λ− in Q.
Notice the importance of the role played by the mapping M in order to reach this conclusion. Indeed, if we replace m2 with {(x)∣s2(x)}→{(x)∣B(x)}, then a proper Σ-separation of λ+ and λ− in UCQ would simply be the CQ {(x)∣A(x)} over the ontology O.
Borrowing similar ideas from [23], to remedy situations where proper separations do not exist, we now introduce approximations of proper separations in terms of completeness and soundness. More specifically, a complete separation is a query that captures all the positive examples in its set of certain answers w.r.t. the OBDM system (i.e., satisfies condition (i) of Definition 1), whereas a sound separation is a query that contains none of the negative examples in its set certain answers w.r.t. the OBDM system (i.e., satisfies condition (ii) of Definition 1).
Definition 2.
qO∈Q is a complete (resp., sound) Σ-separation of λ+ and λ− in the query language Q, if λ+⊆certqO,JD (resp., certqO,JD∩λ−=∅).
We observe that the condition for being a complete (resp., sound) separation does not involve λ− (resp., λ+).
Example 4.
Refer to Example 2. We have that qO1 and qO2 are complete Σ-separations of λ+ and λ− in UCQ, whereas qO3 and qO4 are sound Σ-separations of λ+ and λ− in UCQ.
As the above example manifests, there may be several complete and sound separations. In those cases, the interest is unquestionably in those queries that approximate at best the proper one, at least relative to a target query language Q. Informally, a Q-minimally complete separation is a complete separation in Q containing a minimal (w.r.t. set containment) possible set of negative examples in its set of certain answers, whereas a Q-maximally sound separation is a sound separation in Q capturing a maximal (w.r.t. set containment) possible set of positive examples in its set of certain answers.
Definition 3.
qO is a Q-minimally complete (resp., Q-maximally sound) Σ-separation of λ+ and λ−, if qO is a complete (resp., sound) Σ-separation of λ+ and λ− in Q and there is no qO′∈Q satisfying both the following two conditions:
(i) qO′ is a complete (resp., sound) Σ-separation of λ+ and λ− in Q;
(ii) certqO′,JD∩λ−⊂certqO,JD∩λ− (resp., certqO,JD∩λ+⊂certqO′,JD∩λ+).
By definition, it is immediate to verify that a Σ-proper separation of λ+ and λ− in a query language Q is both a Q-minimally complete Σ-separation of λ+ and λ− and a Q-maximally sound Σ-separation of λ+ and λ−.
Example 5.
Refer again to Example 2. One can verify that the CQ qO1 is a UCQ-minimally complete Σ-separation of λ+ and λ−, whereas qO2 is not. Moreover, both qO3 and qO4 are CQ-maximally sound Σ-separations of λ+ and λ−, but neither of them is a UCQ-maximally sound Σ-separation of λ+ and λ−. Indeed, a UCQ-maximally sound Σ-separation of λ+ and λ− is qO5=qO3∪qO4.
We point out that all the above definitions are a generalization of the definitions illustrated in [22] which deal only with datasets of positive examples, rather than datasets of both positive and negative examples as done here. More specifically, in [22], as well as in all the works addressing the separability task, when only a D-dataset λ+ of positive examples is provided, to λ− it is implicitly associated the D-dataset λ−=dom(D)n∖λ+, where n is the arity of the tuples in λ+. With this remark in mind, we can now specialize the above definitions for the only dataset of positive examples case and report the definitions given in [22].
Definition 4.
qO∈Q is a proper (resp., complete, sound) Σ-characterization of λ+ in the query language Q, if certqO,JD=λ+ (resp., λ+⊆certqO,JD, certqO,JD⊆λ+).
qO is a Q-minimally complete (resp., Q-maximally sound) Σ-characterization of λ+, if qO is a complete (resp., sound) Σ-characterization of λ+ in Q and there is no qO′∈Q satisfying both the following two conditions:
(i) qO′ is a complete (resp., sound) Σ-characterization of λ+ in Q;
(ii) certqO′,JD⊂certqO,JD (resp., certqO,JD⊂certqO′,JD).
In other words, given an OBDM system Σ=⟨J,D⟩ with J=⟨O,S,M⟩, a D-dataset λ+ of arity n, and a query qO∈Q, we have that qO is a proper in Q (resp., complete in Q, sound in Q, Q-minimally complete, Q-maximally sound) Σ-characterization of λ+ if and only if qO is a proper in Q (resp., complete in Q, sound in Q, Q-minimally complete, Q-maximally sound) Σ-separation of λ+ and λ−, where λ−=dom(D)n∖λ+.
4.1.Relation with the abstraction reasoning task
We now discuss the relation between the notion of separation in OBDM introduced here with the notion of Abstraction [19,20], recently introduced in [18] and studied under various scenarios [21,23,24,50] for addressing several reverse engineering tasks in OBDM. In Abstraction, we are given an OBDM specification J=⟨O,S,M⟩ and a query qS over S, and the aim is to find a query qO over O, called a perfect J-abstraction of qS, such that certqO,JD=qSD for each S-database D for which ⟨J,D⟩ is consistent. Conversely, in the separation task also the S-database D is given, and instead of a query qS we have two set of tuples λ+ and λ− of constants taken from D, and the aim is to find a query qO over O such that both λ+⊆certqO,JD and certqO,JD∩λ−=∅ hold.
Following [23], we also say that a query qO over O is a complete (resp., sound) J-abstraction of qS if qSD⊆certqO,JD (resp., certqO,JD⊆qSD) for each S-database D for which ⟨J,D⟩ is consistent. The next proposition establishes a precise relationship between the notion of separation in OBDM introduced here and the notion of abstraction.
Proposition 1.
Let Σ=⟨J,D⟩ be a consistent OBDM system, λ+ and λ− be two D-datasets, and qS be a query that explains λ+ and λ− inside D. If a query qO∈Q is a perfect (resp., complete, sound) J-abstraction of qS, then qO is a proper (resp., complete, sound) Σ-separation of λ+ and λ− in Q.
Proof.
Suppose qO∈Q is a perfect (resp., complete, sound) J-abstraction of qS, i.e., certqO,JD′=qSD′ (resp., qSD′⊆certqO,JD′, certqO,JD′⊆qSD′) for each S-database D′ for which ⟨J,D′⟩ is consistent. Since by assumption Σ=⟨J,D⟩ is consistent, we have that certqO,JD=qSD (resp., qSD⊆certqO,JD, certqO,JD⊆qSD). Now, since both λ+⊆qSD and qSD∩λ−=∅ hold by the assumption that qS explains λ+ and λ− inside D, we derive that both λ+⊆certqO,JD and certqO,JD∩λ−=∅ (resp., only λ+⊆certqO,JD, only certqO,JD∩λ−=∅) hold, which means that qO is a proper (resp., complete, sound) Σ-separation of λ+ and λ− in Q. □
The next example shows that the converse of the above proposition does not necessarily hold, thus stressing the fact that the two problems are indeed different.
Example 6.
Let Σ=⟨J,D⟩ be as follows. J=⟨O,S,M⟩ is the OBDM specification in which O=∅, i.e., O contains no assertions, S={s1,s2,s3}, and M consists of the following two GAV assertions:
{(x)∣s1(x)∧s2(x)}→{(x)∣ Student(x)}{(x)∣s3(x)}→{(x)∣ Student(x)}
Let also the
S-database be
D={s1(a),s2(a),s2(b)} and the
D-datasets
λ+ and
λ− be
λ+={(a)} and
λ−={(b)}. Consider, moreover, the CQ
qS={(x)∣s1(x)}. One can see that the query
qS explains
λ+ and
λ− inside
D because
qSD={(a)}. Consider now the CQ
qO={(x)∣Student(x)} over
O. One can see that
qO is a proper (and therefore, also a complete and a sound) Σ-separation of
λ+ and
λ− in CQ because
certqO,JD={(a)}.
Notice, however, that for the S-database D′={s1(a),s3(b)} we have that (i) ⟨J,D′⟩ is a consistent OBDM system, (ii) qSD′={(a)}, and (iii) certqO,JD′={(b)}. Thus, qO is neither a complete nor a sound (and therefore, nor a perfect) J-abstraction of qS. Indeed both qSD′⊈certqO,JD′ (witnessing that qO is not a complete J-abstraction of qS) and certqO,JD′⊈qSD′ (witnessing that qO is not a sound J-abstraction of qS) hold.
4.2.Computational problems associated with the framework
Given the general framework introduced so far, there are (at least) three computational problems to consider, with respect to an ontology language LO, a mapping language LM, and a query language Q. Given an OBDM system Σ=⟨O,S,M,D⟩ and two D-datasets λ+ and λ−, where O∈LO and M∈LM:
– Verification: given also a query qO∈Q, check whether qO is a proper (resp., complete, sound) Σ-separation of λ+ and λ− in Q.
– Computation: compute any proper in Q (resp., any Q-minimally complete, any Q-maximally sound) Σ-separation of λ+ and λ−, provided it exists.
– Existence: check whether there exists a query qO∈Q that is a proper in Q (resp., a Q-minimally complete, a Q-maximally sound) Σ-separation of λ+ and λ−.
Analogous computational problems can be defined when in the input we have only one D-dataset λ+ of arity n, rather than two D-datasets λ+ and λ−, and we implicitly think of λ− as dom(D)n∖λ+.
In what follows, if not otherwise stated, we refer to the following scenario which considers by far the most popular languages for the OBDM paradigm: (i) LO is DL-LiteR, (ii) LM is GLAV, and (iii) Q is UCQ. In this scenario, there are two interesting properties that are worth mentioning.
Proposition 2.
Let Σ=⟨J,D⟩ be an OBDM system, and λ+ and λ− be two D-datasets of arity n such that λ+∪λ−=dom(D)n. If q1 and q2 are UCQ-minimally complete (resp., UCQ-maximally sound) Σ-separations of λ+ and λ−, then they are equivalent w.r.t. Σ.
Proof.
We first address the case of UCQ-maximally sound, and then the case of UCQ-minimally complete.
Assume that q1 and q2 are UCQ-maximally sound Σ-separations of λ+ and λ− and suppose, for the sake of contradiction, that they are not equivalent w.r.t. Σ. This implies the existence of a tuple c→ such that c→∉certq1,JD and c→∈certq2,JD. Observe that, since λ+∪λ−=dom(D)n, c→ must be such that c→∈λ+, otherwise q2 would not be a sound Σ-separation of λ+ and λ− in UCQ, thus reaching a contradiction. But then, the UCQ Q=q1∪q2 is such that (i) since both q1 and q2 are sound Σ-separations of λ+ and λ− in UCQ, Q is a sound Σ-separation of λ+ and λ− in UCQ as well, and (ii) certq1,JD∩λ+⊂certQ,JD∩λ+ holds because of tuple c→. Obviously, this contradicts the fact that q1 is a UCQ-maximally sound Σ-separation of λ+ and λ−.
Assume now that q1 and q2 are UCQ-minimally complete Σ-separations of λ+ and λ− and suppose, for the sake of contradiction, that they are not equivalent w.r.t. Σ. This implies the existence of a tuple c→ such that c→∈certq1,JD and c→∉certq2,JD. Observe that, since λ+∪λ−=dom(D)n, c→ must be such that c→∈λ−, otherwise q2 would not be a complete Σ-separation of λ+ and λ− in UCQ, thus reaching a contradiction. But then, consider the query Q such that certQ,JD=certq1,JD∩certq2,JD. Obviously, since q1 and q2 are UCQs, Q exists and can be expressed as a UCQ. Moreover, (i) since q1 and q2 are complete Σ-separations of λ+ and λ− in UCQ, Q is a complete Σ-separation of λ+ and λ− in UCQ as well, and (ii) certQ,JD∩λ−⊂certq1,JD∩λ− holds because of tuple c→. Obviously, this contradicts the fact that q1 is a UCQ-minimally complete Σ-separation of λ+ and λ−. □
This also means that, in our scenario, for an OBDM system Σ=⟨J,D⟩ and two D-datasets λ+ and λ− of arity n such that λ+∪λ−=dom(D)n, if a proper Σ-separation of λ+ and λ− in UCQ exists, then it is unique up to equivalence w.r.t. Σ. Furthermore, for the characterizability case where λ− is implicitly set to be dom(D)n∖λ+, proper in UCQ, UCQ-minimally complete, and UCQ-maximally sound Σ-characterizations of λ+ are always unique up to equivalence w.r.t. Σ, provided they exist.
Secondly, in this scenario, as one may expect, proper separations are less likely to exist than explanations in the plain relational database case.
Proposition 3.
Let Σ=⟨J,D⟩ be a consistent OBDM system, and λ+ and λ− be two D-datasets. If there exists a proper Σ-separation of λ+ and λ− in UCQ, then λ+ and λ− are UCQ-explainable inside D.
Proof.
Suppose there exists a proper Σ-separation of λ+ and λ− in UCQ, i.e., there is a UCQ qO over O for which λ+⊆certqO,JD and certqO,JD∩λ−=∅. Recall from Section 3 that the UCQ rewqO,J over S is such that certqO,JD′=rewqO,JD′ for each S-database D′ for which ⟨J,D′⟩ is consistent. Since Σ=⟨J,D⟩ is consistent by assumption, we have that certqO,JD=rewqO,JD. Thus, rewqO,J is such that both λ+⊆rewqO,JD and rewqO,JD∩λ−=∅ hold, from which immediately follows that rewqO,J explains λ+ and λ− inside D by definition, and thus λ+ and λ− are UCQ-explainable inside D. □
In general, the converse of the above proposition does not hold. Indeed, in Example 3, while there is no proper Σ-separation of λ+ and λ− in Q, whatever is the target query language Q, the CQ qS={(x)∣s1(x)} witnesses that λ+ and λ− are CQ-definable inside D.
Note that Definition 1 can be seen as a generalization of the classical notion of explanation in the plain relational database case [7], when one also has to deal with mapping assertions and ontology assertions. In the specific case of OBDM systems Σ=⟨O,S,M,D⟩ such that O=∅ and M contains assertions of the form {(x)∣s(x)}→{(x)∣A(x)} and {(x)∣s′(x1,x2)}→{(x)∣P(x1,x2)} providing a one-to-one correspondence between the alphabet of the ontology and the predicate symbols of the source schema, we observe that, given two D-datasets λ+ and λ− (resp., a D-dataset λ+), there exists a Σ-proper separation of λ+ and λ− (resp., a Σ-proper characterization of λ+) in UCQ if and only if λ+ and λ− are UCQ-explainable (resp., λ+ is UCQ-definable) inside D.
We conclude this section by observing that, in the case of plain relational databases, two D-datasets λ+ and λ− (resp., a D-dataset λ+) are UCQ-explainable (resp., is UCQ-definable) inside D if and only if the union of the CQs describing the tuples in λ+ achieves the separation (resp., the definition). More formally, λ+ and λ− (resp., λ+) are UCQ-explainable (resp., is UCQ-definable) inside D if and only if query(D,c1→)∪⋯∪query(D,cn→) explains λ+ and λ− inside D (resp., defines λ+ inside D), where λ+={c1→,…,cn→}. When casting this problem to the OBDM setting, one of the key challenges is that the separating query needs to be formulated over the ontology level, while data reside at the source level, with a mapping layer mediating the two. One of the contributions of this paper is to provide a similar characterization as in the relational database case for the OBDM setting (cf. Corollary 3).
5.The verification problem
We now define the verification problems for X-separability (X-VSEP) and X-characterization (X-VCHAR), where X={Proper,Complete,Sound}. These decision problems are parametric with respect to the ontology language LO to express the ontology O, the mapping language LM to express the mapping M, and the target query language Q to express the query qO over O.
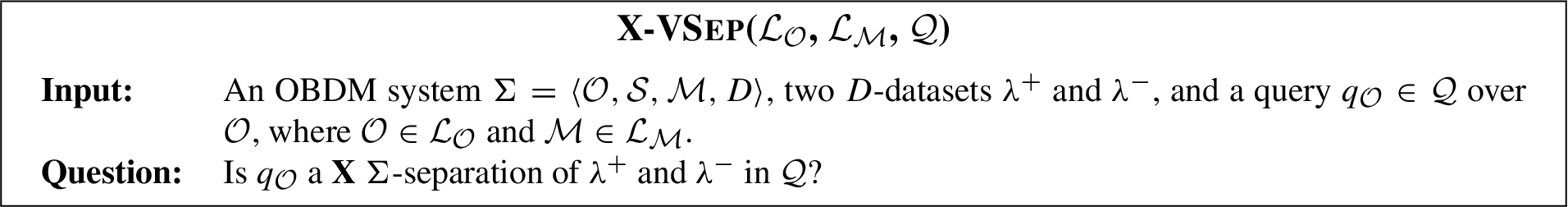
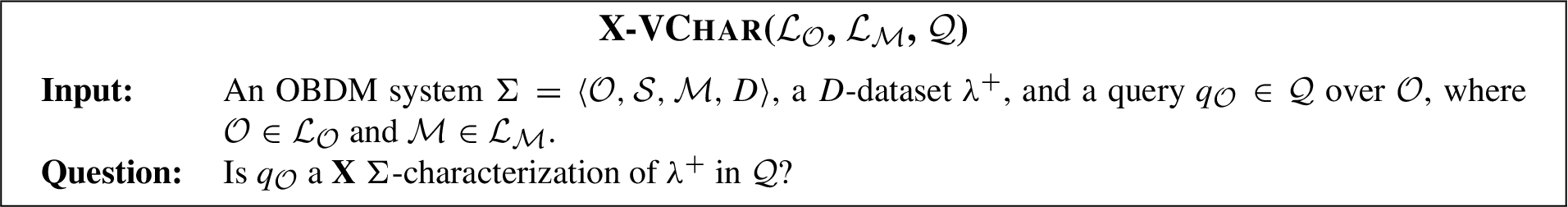
We also introduce two important special cases of the above decision problems, namely: X-VSTSEP(LO, LM, Q) and X-VSTCHAR(LO, LM, Q), which are special cases of X-VSEP(LO, LM, Q) and X-VCHAR(LO, LM, Q), respectively, in which the all the input D-datasets are singleton sets (i.e., they consist of just a single tuple).
In what follows, given a syntactic object x such as a query, an ontology, or a mapping, we denote by |x| its size, which is the number of symbols needed to write it, with names of predicates, variables, etc. counting as one.
We start by analyzing the upper bounds for the case X=Complete. The proof of the next theorems rely on the fact that, given an OBDM specification J=⟨O,S,M⟩ of our considered scenario and a UCQ qO over O, each disjunct in PerfectRef(O,qO) can be obtained after a polynomial number of transformations of an initial disjunct in qO [15], and, analogously, each disjunct in MapRef(M,qO) can be obtained after a polynomial number of transformations of an initial disjunct in qO [17]. This clearly implies that, although there may be an exponential number of disjuncts in the UCQ rewqO,J, the size of each such disjunct is always bounded by a polynomial in the size of qO, O, and M. More precisely, the size of each disjunct in PerfectRef(O,qO) is at most |qO| and the size of each disjunct in rewqO,J is at most |M|·|qO|.
Theorem 1.
Complete-VSEP(DL-LiteR, GLAV, UCQ) and Complete-VCHAR(DL-LiteR, GLAV, UCQ) are in NP.
Proof.
We address Complete-VSEP(DL-LiteR, GLAV, UCQ). The case of Complete-VCHAR(DL-LiteR, GLAV, UCQ) can be addressed in exactly the same way (recall that λ− is immaterial for the complete case). In particular, we now show how to check in NP whether qO is a complete Σ-separation of λ+ and λ− in UCQ (i.e., λ+⊆certqO,JD), where Σ=⟨J,D⟩ with J=⟨O,S,M⟩ in which O is a DL-LiteR ontology and M is a GLAV mapping.
Let n be the arity of the tuple(s) in the D-datasets λ+ and λ−. For each n-tuple of constants c→∈λ+, we first guess (i) a CQ qO′ over O which is either of arity n and size at most |qO|, or a boolean one capturing a disjointness assertion d (e.g., {()∣∃y.A1(y)∧A2(y)} capturing d=A1⊑¬A2); (ii) a sequence ρO of ontology assertions; (iii) a CQ qS over S of size at most |M|·|qO′| which is either of arity n and of the form {x→∣∃y→.ϕS(x→,y→)}, or a boolean one of the form {()∣∃y→.ϕS(y→)}; (iv) a sequence ρM of mapping assertions; and (v) a function f from the variables occurring in qS to dom(D).
Then, we check in polynomial time whether (i) by means of ρO, either we can rewrite a disjunct of qO into qO′ through O (i.e., qO′∈PerfectRef(O,qO)), or we can rewrite a disjunct of VO into qO′ through O (i.e., qO′∈PerfectRef(O,VO)); (ii) by means of ρM, we can rewrite qO′ into qS through M (i.e., qS∈MapRef(M,qO′), and thus either qS∈rewqO,J or qS∈rewVO,J); and finally (iii) f consists in a homomorphism witnessing either (set(ϕS),x→)→(D,c→), i.e., c→∈qSD (and therefore c→∈rewqO,JD, which means c→∈certqO,JD), or (set(ϕS),())→(D,()), i.e., qSD={⟨⟩} (and therefore rewVO,JD={⟨⟩}, which means that Σ is inconsistent and thus c→∈certqO,JD by definition of certain answers). □
By exploiting the above result, we now address the upper bounds for the case X=Sound.
Theorem 2.
Sound-VSEP(DL-LiteR, GLAV, UCQ) and Sound-VCHAR(DL-LiteR, GLAV, UCQ) are in coNP.
Proof.
We start with Sound-VSEP(DL-LiteR, GLAV, UCQ), and then we consider Sound-VCHAR(DL-LiteR, GLAV, UCQ). In particular, we now show how to check in NP whether qO is not a sound Σ-separation of λ+ and λ− in UCQ (i.e., certqO,JD∩λ−≠∅), where Σ=⟨J,D⟩ with J=⟨O,S,M⟩ in which O is a DL-LiteR ontology and M is a GLAV mapping.
We first guess (i) a tuple of constants c→, and, exactly as in the proof of Theorem 1, we also guess (ii) qO′, ρO, qS, ρM, and f. Then, we check in polynomial time whether (i) c→∈λ−, and (ii) using qO′, ρO, qS, ρM, and f, we follow exactly the same polynomial time procedure described in the proof of Theorem 1 to check whether c→∈certqO,JD.
As for the Sound-VCHAR(DL-LiteR, GLAV, UCQ) case, it is sufficient to replace the check (i) c→∈λ− with the check c→∈dom(D)n∖λ+, where n is the arity of the tuple(s) in the D-dataset λ+. Clearly this latter check can be done in polynomial time as well, by first checking that every constant of c→ effectively occurs in dom(D) and then simply checking that c→∉λ+. □
We recall that the complexity class DP, introduced in [56], resides at the second level of the polynomial time hierarchy [61], and it is composed of all those decision problems that are the intersection of a decision problem in NP and a decision problem in coNP, that is, DP=NP∧coNP={P1∩P2∣P1∈NP∧P2∈coNP}.
Since qO is a proper Σ-separation of λ+ and λ− in Q if and only if it is both a sound, and a complete Σ-separation of λ+ and λ− in Q, we immediately derive the following upper bounds for X=Proper.
Corollary 1.
Proper-VSEP(DL-LiteR, GLAV, UCQ) and Proper-VCHAR(DL-LiteR, GLAV, UCQ) are in DP.
We now provide matching lower bounds, proving that all of them already hold for the singleton datasets special cases. More specifically, we show that they already hold for the same fixed OBDM system Σ=⟨J,D⟩, same fixed D-datasets λ+ and λ− (resp., D-dataset λ+) containing only a single unary tuple, and for CQs as queries. Furthermore, the fixed OBDM specification J=⟨O,S,M⟩ is such that O=∅ (i.e., O contains no ontology assertions) and M is a GAV∩LAV mapping (i.e., M is both a GAV and a LAV mapping). To simplify the presentation, with a slight abuse of notation, from now on we denote by LO=∅ the ontology language allowing only for ontologies O=∅, i.e., ontologies O without assertions.
Theorem 3.
There is an OBDM system Σ=⟨O,S,M,D⟩ such that O=∅ and M is a GAV∩LAV mapping, and two D-datasets λ+ and λ− (resp., a D-dataset λ+) containing only one unary tuple for which:
– Complete-VSTSEP(∅, GAV∩LAV, CQ) and Complete-VSTCHAR(∅, GAV∩LAV, CQ) are NP-hard;
– Sound-VSTSEP(∅, GAV∩LAV, CQ) and Sound-VSTCHAR(∅, GAV∩LAV, CQ) are coNP-hard;
– Proper-VSTSEP(∅, GAV∩LAV, CQ) and Proper-VSTCHAR(∅, GAV∩LAV, CQ)) are DP-hard.
Proof.
Let Σ=⟨J,D⟩ be the fixed OBDM system such that (i) J=⟨O,S,M⟩ is an OBDM specification in which O contains no assertions and whose alphabet consists of two atomic roles P1 and P2, S={s1,s2}, and M consists of the following two GAV∩LAV assertions: {(x1,x2)∣s1(x1,x2)}→{(x1,x2)∣P1(x1,x2)} and {(x1,x2)∣s2(x1,x2)}→{(x1,x2)∣P2(x1,x2)}, which simply mirrors source predicate si to atomic role Pi, for i∈[1,2], and (ii) D is the S-database composed of the following facts:
{s1(x,y)∣x={r′,g′,b′} and y={r′,g′,b′} and x≠y}∪{s1(x,y)∣x={r,g,b,o} and y={r,g,b,o} and x≠y}∪{s2(x,c3)∣x={r′,g′,b′}}∪{s2(x,c4)∣x={r,g,b,o}}.
Let, moreover,
λ+ and
λ− be the fixed
D-datasets
λ+={(c4)} and
λ−={(c3)}. Note that
λ− is needed only for the decision problems related to separability but not for the decision problems related to characterizability.
Let G=(V,E) be a finite and undirected graph without loops33 or isolated nodes, where V={y1,…,yn}. We define a CQ qG={(x)∣∃y→.ϕO(x,y→)} over O as follows:
{(x)∣∃y1,…,yn .⋀(yi,yj)∈E(P1(yi,yj))∧⋀yi∈V(P2(yi,x))}
Notice that qG can be constructed in LOGSPACE from an input graph G as above.
By inspecting the OBDM system Σ=⟨J,D⟩, for any graph G as above, the set of certain answers certqG,JD must necessarily be an element of the power set of {(c3),(c4)}. More specifically, the following property holds:
Claim 1.
For both i=3 and i=4, we have that a graph G=(V,E) is i-colourable if and only if (ci)∈certqG,JD.
Proof.
First of all, notice that COM(D) is composed of the following facts:
{P1(x,y)∣x={r′,g′,b′} and y={r′,g′,b′} and x≠y}∪{P1(x,y)∣x={r,g,b,o} and y={r,g,b,o} and x≠y}∪{P2(x,c3)∣x={r′,g′,b′}}∪{P2(x,c4)∣x={r,g,b,o}}.
“Only-if part:” Suppose G=(V,E) is 3-colourable (resp., 4-colourable), that is, there exists a function f:V→{r′,g′,b′} (resp., f:V→{r,g,b,o}) such that f(yi)≠f(yj) for each (yi,yj)∈E. Let ϕO be the body of qG, and consider the extension of f which assigns to the distinguished variable x of qG the constant c3 (resp., c4). It can be readily seen that f consists in a homomorphism from set(ϕO) to COM(D) such that f(x)=c3 (resp., f(x)=c4). In other words, f witnesses that (set(ϕO),(x))→(COM(D),(c3)) (resp., (set(ϕO),(x))→(COM(D),(c4))). Thus, (c3)∈certqG,JD (resp., (c4)∈certqG,JD), as required.
“If part:” Suppose G=(V,E) is not 3-colourable (resp., not 4-colourable), that is, each possible function f:V→{r′,g′,b′} (resp., f:V→{r,g,b,o}) is such that f(yi)=f(yj) for some (yi,yj)∈E. Clearly, this implies that (set(ϕO),(x))↛(COM(D),(c3)) (resp., (set(ϕO),(x))↛(COM(D),(c4))). Thus, (c3)∉certqG,JD (resp., (c4)∉certqG,JD), as required. □
With the above property in hand, and the fact that certqG,JD is an element of the power set of {(c3),(c4)} for each possible graph G=(V,E), we are now ready to prove the claimed lower bounds.
As for the complete case, the proof of NP-hardness is by a LOGSPACE reduction from the 4-colourability problem, which is NP-complete [32]. In particular, from the above claim a graph G is 4-colourable if and only if (c4)∈certqG,JD, i.e., if and only if λ+⊆certqG,JD, which is the condition for qG to be a complete Σ-separation of λ+ and λ− in CQ (resp., a complete Σ-characterization of λ+ in CQ).
As for the sound case, the proof of coNP-hardness is by a LOGSPACE reduction from the complement of the 3-colourability problem, which is coNP-complete [32]. In particular, from the above claim a graph G is not 3-colourable if and only if (c3)∉certqG,JD, i.e., if and only if certqG,JD∩λ−=∅ (resp., certqG,JD⊆λ+), which is the condition for qG to be a sound Σ-separation of λ+ and λ− in CQ (resp., a sound Σ-characterization of λ+ in CQ).
Finally, as for the proper case, the proof of DP-hardness is by a LOGSPACE reduction from the exact-4-colourability problem, which is DP-complete [59]. In particular, a graph G is exact-4-colourable (i.e., 4-colourable and not 3-colourable) if and only if certqG,JD={(c4)}, i.e., if and only if certqG,JD⊆λ+ and certqG,JD∩λ−=∅ (resp., certqG,JD=λ+), which is the condition for qG to be a proper Σ-separation of λ+ and λ− in CQ (resp., a proper Σ-characterization of λ+ in CQ). □
For the scenario under investigation in this paper, we can now establish the precise computational complexity of all the Verification decision problems introduced at the beginning of this section.
Corollary 2.
The following holds:
– Complete-VSEP(DL-LiteR, GLAV, UCQ) and Complete-VCHAR(DL-LiteR, GLAV, UCQ) are NP-complete. The lower bounds already hold for Complete-VSTSEP(∅, GAV∩LAV, CQ) and Complete-VSTCHAR(∅, GAV∩LAV, CQ);
– Sound-VSEP(DL-LiteR, GLAV, UCQ) and Sound-VCHAR(DL-LiteR, GLAV, UCQ) are coNP-complete. The lower bounds already hold for Sound-VSTSEP(∅, GAV∩LAV, CQ) and Sound-VSTCHAR(∅, GAV∩LAV, CQ);
– Proper-VSEP(DL-LiteR, GLAV, UCQ) and Proper-VCHAR(DL-LiteR, GLAV, UCQ) are DP-complete. The lower bounds already hold for Proper-VSTSEP(∅, GAV∩LAV, CQ) and Proper-VSTCHAR(∅, GAV∩LAV, CQ).
Finally, from the lower bounds given in Theorem 3, we can derive two interesting novel results also in the context of explainability and definability in the plain relational database case. More specifically, since the fixed OBDM specification J=⟨O,S,M⟩ used in the proof that theorem is such that O=∅ and M is both a GAV and a LAV mapping, the proof can be straightforwardly adapted also for the plain relational database case. Thus, given a schema S, an S-database D, two D-datasets λ+ and λ− (resp., a D-dataset λ+), and a UCQ qS over S, it is DP-complete the problem of deciding whether qS explains λ+ and λ− (resp., defines λ+) inside D (the DP membership of these decision problems directly follows from Corollary 1).
6.The computation problem
In this section, we address the Computation problem. We start by considering the case when the given OBDM system Σ at hand is inconsistent. Given an inconsistent OBDM system Σ=⟨J,D⟩ with J=⟨O,S,M⟩ and two D-datasets λ+ and λ− (resp., a D-dataset λ+) of arity n, we point out that any query qO∈Q of arity n over O is a Q-minimally complete Σ-separation (resp., Σ-characterization) of λ+ and λ− (resp., of λ+). This is so because, by definition, the certain answers of any query qO of arity n w.r.t. an inconsistent OBDM system Σ is the set of all possible n-tuples of constants occurring in D, i.e., dom(D)n. Furthermore, if λ+=dom(D)n and λ−=∅, then any query qO∈Q of arity n over O is also a Q-maximally sound (and therefore a proper in Q) Σ-separation (resp., Σ-characterization) of λ+ and λ− (resp., of λ+); otherwise, no sound (and therefore, no Q-maximally sound and no proper in Q) Σ-separation (resp., Σ-characterization) of λ+ and λ− (resp., of λ+) exists. Since, however, for OBDM systems of our scenario it is always possible to check whether they are inconsistent or not (cf. Section 3), from the above observations one can trivially derive suitable algorithms for the Computation problem in all the cases in which the input OBDM system Σ is inconsistent.
Having thoroughly covered the case of inconsistent OBDM systems, in what follows in this section, unless otherwise stated, we implicitly assume to only deal with consistent OBDM systems.
Specifically, we now provide two algorithms that, given a consistent OBDM system Σ=⟨J,D⟩ and two D-datasets λ+ and λ− (resp., a D-dataset λ+), always terminate and return, respectively, a UCQ-minimally complete and a UCQ-maximally sound Σ-separation (resp., Σ-characterization) of λ+ and λ− (resp., of λ+). This proves that, in our investigated scenario, they always exist and can be computed. In fact, the algorithms we provide focus only on the Separability case. Algorithms for the Characterizability case can be immediately derived from the ones we provide by simply computing λ−=dom(D)n∖λ+, where n is the arity of the tuple(s) in λ+.
Before delving into the details of the two algorithms, we provide some crucial properties about the canonical structure that will be used to establish the correctness of such algorithms.
Proposition 4.
Let Σ=⟨J,D⟩ with J=⟨O,S,M⟩ be an OBDM system, qO be a UCQ over O, and c→ and b→ be two tuples of constants such that (COM(D),c→)→(COM(D),b→). If c→∈certqO,JD, then b→∈certqO,JD.
Proof.
If Σ is inconsistent, then the claim is trivial. If Σ is consistent, from Section 3 we know that c→∈certqO,JD implies the existence of a disjunct q={x→∣∃y→.ϕ(x→,y→)} in qO for which (set(ϕ),x→)→(COM(D),c→). Let h be the homomorphism witnessing that (set(ϕ),x→)→(COM(D),c→), and let h′ be the homomorphism witnessing that (COM(D),c→)→(COM(D),b→), which exists by the premises of the proposition. The composite function h″=h′∘h is then a homomorphism witnessing that (set(ϕ),x→)→(COM(D),b→). It follows that b→∈certqO,JD, as required. □
Proposition 5.
Let Σ=⟨J,D⟩ with J=⟨O,S,M⟩ be a consistent OBDM system, b→ and c→ be two tuples of constants, and qc→ be the CQ qc→=query(M(D),c→) over O. We have that b→∈certqc→,JD if and only if (COM(D),c→)→(COM(D),b→).
Proof.
Suppose that (COM(D),c→)→(COM(D),b→), and let h be the homomorphism witnessing this. Consider the query qc→=query(M(D),c→)={x→∣∃y→.ϕ(x→,y→)}. Observe that set(ϕ) is obtained from M(D) by appropriately replacing each occurrence of each constant c∈dom(M(D)) either with a distinguished variable xc∈x→ or with an existential variable yc∈y→. This means that h can be immediately transformed into a homomorphism witnessing that (set(ϕ),x→)→(COM(D),b→), thus implying that b→∈certqc→,JD.
Suppose now that b→∈certqc→,JD. Since Σ is consistent, it follows that there is a homomorphism h witnessing that (set(ϕ),x→)→(COM(D),b→), where qc→=query(M(D),c→)={x→∣∃y→.ϕ(x→,y→)}. By considering again the relationship between set(ϕ) and COM(D), the homomorphism h can be immediately transformed into a homomorphism h′ that witnesses (M(D),c→)→(COM(D),b→). By construction of the canonical structure COM(D), it is now trivial to verify that h′ can be properly extended into a homomorphism h″ witnessing that (COM(D),c→)→(COM(D),b→). □
We are now ready to present our algorithms for the Computation problem. We start with the complete case, and provide the Algorithm 1 (MinCompSeparation) for computing UCQ-minimally complete separations.
Algorithm 1
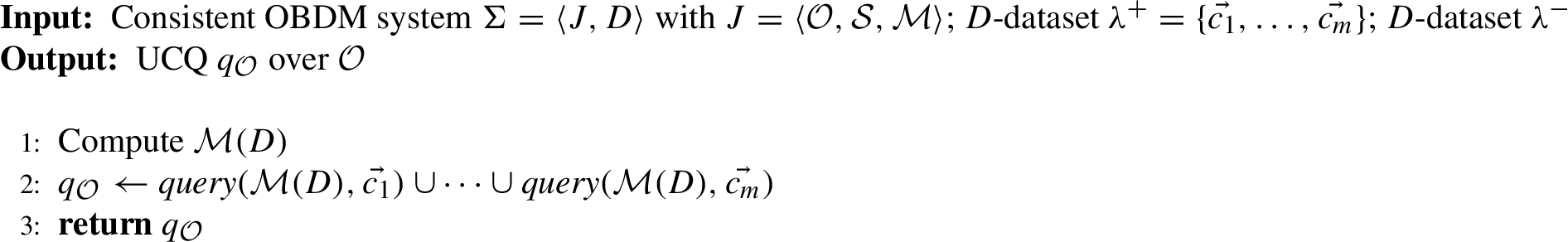
Informally, for each positive example ci→∈λ+, the algorithm obtains from the set of atoms M(D) the CQ query(M(D),ci→). Then, the output query qO is the union of all the CQs obtained in such a way.
Example 7.
Let J=⟨O,S,M⟩ be the same OBDM specification of Example 2. One can verify that for the S-database D={s1(c1),s3(c2,b),s3(c3,b)} and the D-datasets λ+={(c1),(c2)} and λ−={(c3)}, MinCompSeparation(⟨J,D⟩, λ+,λ−) returns the UCQ qO=query(M(D),(c1)) ∪ query(M(D),(c2)), where query(M(D),(c1))={(xc1)∣∃yc2,yc3,yb.Student(xc1)∧EnrolledIn(yc2,yb)∧EnrolledIn(yc3,yb)} and query(M(D),(c2))={(xc2)∣∃yc1,yc3,yb.EnrolledIn(xc2,yb)∧EnrolledIn(yc3,yb)∧Student(yc1)}. Note that the query qO returned by the algorithm is a UCQ-minimally complete Σ-separation of λ+ and λ−, where Σ=⟨J,D⟩.
The following theorem establishes termination and correctness of the Algorithm 1 (MinCompSeparation).
Theorem 4.
Let Σ=⟨J,D⟩ with J=⟨O,S,M⟩ be a consistent OBDM system and λ+ and λ− be two D-datasets. We have that MinCompSeparation(Σ, λ+,λ−) terminates and returns a UCQ-minimally complete Σ-separation of λ+ and λ−.
Proof.
Termination of the algorithm as well as completeness of the UCQ qO returned are straightforward. In particular, due to Proposition 5, it is obvious that each ci→∈λ+ is such that ci→∈certqci→,JD, where qci→=query(M(D),ci→).
To prove that qO is also a UCQ-minimally complete Σ-separation of λ+ and λ−, note that it is enough to show that any query q over O that is a complete Σ-separation of λ+ and λ− in UCQ is such that certqO,JD⊆certq,JD. We do this by contraposition. Let q be a UCQ over O for which certqO,JD⊈certq,JD, i.e., for a tuple of constants b→ we have b→∉certq,JD but b→∈certqO,JD. This latter means that b→∈certqci→,JD for some qci→=query(M(D),ci→) with ci→∈λ+ occurring in qO. By Proposition 5, one can see that b→∈certqci→,JD implies (COM(D),ci→)→(COM(D),b→). By Proposition 4, it follows that each UCQ q′ over O containing the tuple ci→ in its set of certain answers w.r.t. Σ must contain also tuple b→ in such a set, i.e., ci→∈certq′,JD implies b¯∈certq′,JD for any UCQ q′ over O. Thus, since b→∉certq,JD, we derive that ci→∉certq,JD as well. Now, since ci→∈λ+ and ci→∉certq,JD, this immediately implies that q is not a complete Σ-separation of λ+ and λ− in UCQ, as required. □
We now turn to the sound case, and provide the Algorithm 2 (MaxSoundSeparation) for computing UCQ-maximally sound Σ-separations.
Algorithm 2

Intuitively, starting from the query query(M(D),c1→)∪⋯∪query(M(D),cm→), which is a UCQ-minimally complete Σ-separation of λ+ and λ−, the algorithm simply discards all those disjuncts whose set of certain answers w.r.t. Σ contain at least a tuple b→∈λ−. We recall from Section 3 that the set of certain answers of a CQ qci→ w.r.t. a consistent OBDM system Σ=⟨J,D⟩ can be always computed by first obtaining its reformulation rewqci→,J over the source schema S, and then by evaluating this latter query directly over the S-database D. In other words, the if-condition of line 5 can be equivalently reformulated as: rewqci→,JD∩λ−=∅.
Example 8.
Refer to Example 7. Since the certain answers of the CQ query(M(D),(c2)) w.r.t. Σ=⟨J,D⟩ include also (c3)∈λ−, MaxSoundSeparation(Σ, λ+,λ−) returns the CQ qO=query(M(D),(c1)). Note that qO is a UCQ-maximally sound Σ-separation of λ+ and λ−.
The following theorem establishes termination and correctness of the Algorithm 2 (MaxSoundSeparation).
Theorem 5.
Let Σ=⟨J,D⟩ with J=⟨O,S,M⟩ be a consistent OBDM system, and λ+ and λ− be two D-datasets. We have that MaxSoundSeparation(Σ, λ+, λ−) terminates and returns a UCQ-maximally sound Σ-separation of λ+ and λ−.
Proof.
Termination of the algorithm as well as soundness of the UCQ qO returned are straightforward. In particular, by construction, all the disjuncts qci→ of qO are such that there is no tuple b→∈λ− for which b→∈certqci→,JD.
To prove that qO is also a UCQ-maximally sound Σ-separation of λ+ and λ−, note that it is enough to show that any query q over O that is a sound Σ-separation of λ+ and λ− in UCQ is such that certq,JD∩λ+⊆certqO,JD∩λ+. We do this by contraposition. Let q be a UCQ over O for which certq,JD∩λ+⊈certqO,JD∩λ+, i.e., for a tuple of constants b→∈λ+ we have b→∈certq,JD but b→∉certqO,JD. Since b→∉certqO,JD and b→∈λ+, it is easy to see that the algorithm discarded the disjunct qb→=query(M(D),b→) (otherwise, we would trivially derive that b→∈certqb→,JD, and thus b→∈certqO,JD, which is a contradiction to the fact that b→∉certqO,JD). By construction of the algorithm, one can see that the only reason qb→ was discarded is because g→∈certqb→,JD for at least a tuple g→∈λ−. By Proposition 5, one can see that g→∈certqb→,JD implies (COM(D),b→)→(COM(D),g→). By Proposition 4, it follows that each UCQ q′ over O containing tuple b→ in its set of certain answers w.r.t. Σ must contain also tuple g→ in such a set, i.e., b→∈certq′,JD implies g→∈certq′,JD for any UCQ q′ over O. Thus, since b→∈certq,JD, we derive that g→∈certq,JD as well. Now, since g→∈λ− and g→∈certq,JD, this immediately implies that q is not a sound Σ-separation of λ+ and λ− in UCQ, as required. □
We now briefly discuss the running time of the two above algorithms. First, we observe that the running time of the presented algorithms differs depending on which mapping language the input mapping M is formulated. A key difference between the mapping languages GLAV and the special cases GAV and LAV, is in the size of the computed M(D). In GLAV mappings, due to the simultaneous presence of queries involving multiple source predicates in the left-hand side of the mapping assertions, and join existential variables in the right-hand side of the assertions, the set of atoms M(D) can be exponentially large. For example, considering a database D={si(0),si(1)∣1⩽i⩽n} and the mappings M containing the GLAV assertion: {(x1,…,xn)∣s1(x1)∧⋯∧sn(xn)}→{(x1,…,xn)∣∃y.P(x1,y)∧⋯∧P(xn,y)}, the number of atoms occurring in the set M(D) is 2n. Conversely, both in LAV and GAV mappings, M(D) is always polynomially bounded, since the former does not allow for multiple source predicates in the left-hand side of mapping assertions, whereas the latter does not allow for existential variables in the right-hand side of mapping assertions and the arity of ontology predicates is fixed to at most 2.
Furthermore, the running time required to compute M(D) is different in the LAV and GAV cases. Indeed M(D) can always be computed in polynomial time whenever M is a LAV mapping, whereas, in general, already when M is a GAV mapping, since there are CQs in the left-hand side of mapping assertions that need to be evaluated over the database D, it takes exponential time to deterministically compute M(D) (unless PTIME=NP).
As immediate consequences of the above observations, we derive that, in general, the Algorithm 1 (MinCompleteSeparation) runs in exponential time with respect to the size of the input, while it runs in polynomial time whenever the mapping M of the input OBDM system is a LAV mapping. As for the case of the Algorithm 2 (MaxSoundSeparation), since after computing M(D) one needs also to compute the certain answers of each query(M(D),ci→) for all ci→ in the input dataset λ+, and deterministically computing the certain answers of CQs with respect to an OBDM system takes exponential time (unless PTIME=NP), we derive that, in general, the algorithm runs in double exponential time with respect to the size of the input, while it runs in exponential time whenever the mapping M of the input OBDM system is either a GAV or a LAV mapping. This is because M(D) is guaranteed to be of polynomial size whenever M is either a GAV or a LAV mapping (and therefore, also the various CQs query(M(D),ci→) are of polynomial size with respect to the size of the input).
We conclude this section by providing a semantic test for the existence of proper separations and characterizations in UCQ in the OBDM settings. We observe that, in all the cases in which a proper separation exists, it is clear that both algorithms return the same query query(M(D),c1→)∪⋯∪query(M(D),cm→). Therefore, as a direct consequence of both Theorem 4 and Theorem 5, we get the following result.
Corollary 3.
Let Σ=⟨O,S,M,D⟩ be an OBDM specification, and λ+={c1→,…,cm→} and λ− two D-datasets. Either the UCQ qO=query(M(D),c1→)∪⋯∪query(M(D),cm→) is a proper Σ-separation of λ+ and λ− in UCQ, or no proper Σ-separation of λ+ and λ− in UCQ exists.
The combination of Corollary 3 and Proposition 5 allows us to provide the following semantic tests for the existence of proper separations and proper characterizations in UCQ in the OBDM setting, which can be seen as the analogous of the semantic tests given in [7] and [55] for the plain relational database setting and the ontology-enriched query answering setting, respectively.
– SEP test for UCQs in OBDM: given a consistent OBDM system Σ=⟨O,S,M,D⟩ and two D-datasets λ+ and λ−, there exists a proper Σ-separation of λ+ and λ− in UCQ if and only if it is the case that (COM(D),c→)↛(COM(D),b→) for all c→∈λ+ and all b→∈λ−.
– CHAR test for UCQs in OBDM: given a consistent OBDM system Σ=⟨O,S,M,D⟩ and a D-dataset λ+ of arity n, there exists a proper Σ-characterization of λ+ in UCQ if and only if it is the case that (COM(D),c→)↛(COM(D),b→) for all c→∈λ+ and all b→∈dom(D)n∖λ+.
7.The existence problem
We now address the existence problem. First of all, for the scenario under consideration in this paper, the existence problem for both UCQ-minimally complete and UCQ-maximally sound separations (and also characterizations) is trivial, since by Theorems 4 and 5 they always exist. Thus, in this section we only consider the remaining proper case, by defining a variant of the decision problems as defined in [55], where also a mapping in some mapping language LM is given as input.


We also introduce two important special cases of the above decision problems, namely: STSEP(LO, LM, Q) and STCHAR(LO, LM, Q), which are special cases of SEP(LO, LM, Q) and CHAR(LO, LM, Q), respectively, in which the all the input D-datasets are singleton sets (i.e., they consist of just a single tuple).
In what follows, we show that the computational complexity of the above decision problems differ only depending on the mapping language LM adopted. As already discussed in Section 6, a key difference between GLAV and the special cases GAV and LAV is both in the size of the computed M(D), i.e. exponential for GLAV mapping and polynomial for both GAV and LAV mapping, and in the effort required to compute M(D), i.e. polynomial time for LAV mapping and exponential time (unless PTIME=NP) in both GAV and GLAV mapping.
We start by characterizing the computational complexity of SEP and CHAR (and their respective subproblems) in the simplest LAV case, then we address the GAV case, and finally we focus on the most general GLAV case. Interestingly, all the provided matching lower bounds hold even for fixed ontologies O=∅, i.e., ontologies without assertions, and fixed D-datasets containing only a single unary tuple.
Importantly, for the scenario under consideration, from the results of the previous section, the questions in SEP and CHAR can be reformulated equivalently as follows: “is qO=query(M(D),c1→)∪⋯∪query(M(D),cm→) also a sound (and so, a proper) Σ-separation of λ+={c1→,…,cm→} and λ− in UCQ?” and “is qO=query(M(D),c1→)∪⋯∪query(M(D),cm→) also a sound (and so, a proper) Σ-characterization of λ+={c1→,…,cm→} in UCQ?”, respectively.
Theorem 6.
SEP(DL-LiteR, LAV, UCQ) and CHAR(DL-LiteR, LAV, UCQ) are coNP-complete. The lower bounds already hold for STSEP(∅, GAV∩LAV, UCQ) and STCHAR(∅, GAV∩LAV, UCQ).
Proof.
Upper bound: We only mention SEP(DL-LiteR, LAV, UCQ). The CHAR(DL-LiteR, LAV, UCQ) case is similar and therefore not discussed. Given an OBDM system Σ=⟨J,D⟩ with J=⟨O,S,M⟩ in which O is a DL-LiteR ontology and M is a LAV mapping, and two D-datasets λ+={c1→,…,cm→} and λ−, we first compute M(D) in polynomial time (recall that M is a LAV mapping), and therefore also the query qO=query(M(D),c1→)∪⋯∪query(M(D),cm→) which is a UCQ-minimally complete Σ-separation of λ+ and λ−. Then, exactly as illustrated in Theorem 2, we can check in coNP whether query(M(D),c1→)∪⋯∪query(M(D),cm→) is also a sound (and so, a proper) Σ-separation of λ+ and λ− in UCQ.
Lower bound: We start with STSEP(∅, GAV∩LAV, UCQ), and then we address the STCHAR(∅, GAV∩LAV, UCQ) case. The proof of coNP-hardness is by a LOGSPACE reduction from the complement of the 3-colourability problem. We define a fixed OBDM specification J=⟨O,S,M⟩ in which O contains no assertions and whose alphabet consists of an atomic role e and an atomic concept A, S={se,s}, and M consists of the following two GAV∩LAV mapping assertions: {(x1,x2)∣se(x1,x2)}→{(x1,x2)∣e(x1,x2)} and {(x)∣s(x)}→{(x)∣A(x)}, which simply mirrors source predicates se and s to e and A, respectively.
Let G=(V,E) be a finite and undirected graph without loops or isolated nodes, where V={c1,…,cn}. Without loss of generality, we may assume that V≠∅ and that G is connected, i.e., there is a path from c to c′ for any pair of nodes (c,c′)∈V2. Then, we define an S-database DG composed of the following facts:
{se(c,c′)∣(c,c′)∈E}∪{s(c1)}∪{se(x,y)∣x={r,g,b} and y={r,g,b} and x≠y}∪{s(r)}.
Let, moreover,
λ+ and
λ− be the fixed
DG-datasets
λ+={(c1)} and
λ−={(r)}.
Notice that the S-database DG can be constructed in LOGSPACE from an input graph G as above. Let the OBDM system be ΣG=⟨J,DG⟩. We now show that a graph G is not 3-colourable if and only if there exists a proper ΣG-separation of λ+ and λ− in UCQ, thus proving the claimed lower bound.
Claim 2.
Given a graph G, there exists a proper ΣG-separation of λ+ and λ− in UCQ if and only if G is not 3-colourable.
Proof.
First of all, note that COM(DG)={e(c,c′)∣(c,c′)∈E}∪{A(c1)}∪{e(x,y)∣x={r,g,b} and y={r,g,b} and x≠y}∪{A(r)}. We recall that a proper ΣG-separation of λ+ and λ− in UCQ exists if and only if the CQ qG=query(M(DG),(c1)) is also a sound (and so, a proper) ΣG-separation of λ+ and λ− in UCQ.
“Only-if part:” Suppose G=(V,E) is 3-colourable, that is, there exists a function f:V→{r,g,b} such that f(c)≠f(c′) for each (c,c′)∈E. Without loss of generality, we may assume that f(c1)=r (indeed, the existence of f clearly implies the existence of a function f′ with f′(c1)=r and such that f′(c)≠f′(c′) for each (c,c′)∈E holds as well). Consider the extension h of f assigning h(x)=x to each x∈{r,g,b}. It can be readily seen that h consists in a homomorphism witnessing that (COM(DG),(c1))→(COM(DG),(r)), which directly implies that (r)∈certqG,JDG. It follows that qG is not a sound ΣG-separation of λ+ and λ− in UCQ, and therefore no proper ΣG-separation of λ+ and λ− in UCQ exists.
“If part:” Suppose there exists no proper ΣG-separation of λ+ and λ− in UCQ, i.e., the CQ qG is such that (r)∈certqG,JDG. It follows that there exists a homomorphism h witnessing that (COM(DG),(c1))→(COM(DG),(r)). Now, since the graph G is connected and since h(c1)=h(r), by construction of COM(DG) the homomorphism h must necessarily be such that h(c)∈{r,g,b} for each constant c representing a node c∈V. But then, due to the fact that none of e(r,r), e(g,g), and e(b,b) occur in COM(DG), we derive that h is such that h(c)≠h(c′) for each e(c,c′)∈COM(DG), and therefore for each (c,c′)∈E as well. Thus, we can conclude that G is 3-colourable. □
As for the coNP-hardness of STCHAR(∅, GAV∩LAV, UCQ), it is possible to use exactly the same reduction provided above by discarding λ− and considering only λ+={(c1)}. In particular, due to the fact that A(c) and A(r) are the only A-facts occurring in COM(DG), the set of certain answers of the query qG w.r.t. ΣG is always either {(c1)} or {(c1),(r)}, and which one of the two depends on the 3-colourability of G. □
We now turn to consider GAV mappings. We recall that the complexity class Θ2p has many characterizations: Θ2p=PNP[O(log n)]= P with a constant number of rounds of parallel queries to an oracle for a decision problem in NP [12] (we refer the reader to [67] for further characterizations of such complexity class). By a round of parallel queries, it is intended that the Turing machine can ask for polynomially many non-adaptive queries to the NP oracle.
Theorem 7.
SEP(DL-LiteR, GAV, UCQ) and CHAR(DL-LiteR, GAV, UCQ) are Θ2p-complete. The lower bounds already hold for STSEP(∅, GAV, UCQ) and STCHAR(∅, GAV, UCQ).
Proof.
Upper bound: We only mention SEP(DL-LiteR, GAV, UCQ). The CHAR(DL-LiteR, GAV, UCQ) case is similar and therefore not discussed. Given an OBDM system Σ=⟨J,D⟩ with J=⟨O,S,M⟩ in which O is a DL-LiteR ontology and M is a GAV mapping, and two D-datasets λ+={c1→,…,cm→} and λ−, as a first step we compute M(D) in polynomial time with a single round of parallel queries to an NP oracle. More specifically, for each pair of constants (c1,c2)∈dom(D)2 (resp., constant c∈dom(D)) and for each atomic role P (resp., concept A) in the alphabet of O we ask, all together with a single round of parallel queries to an NP oracle, whether P(c1,c2)∈M(D) (resp., A(c)∈M(D)). It is clear that deciding whether P(c1,c2)∈M(D) (resp., A(c)∈M(D)) for a given pair of constants (c1,c2)∈dom(D)2 (resp., constant c∈dom(D)), a GAV mapping M, and a database D is an NP-complete problem because the left-hand side of mapping assertions are CQs [1].
Once obtained M(D) as described above, we construct in polynomial time the UCQ qO=query(M(D),c1→)∪⋯∪query(M(D),cm→). Then, due to Theorem 2, with a second and final round of parallel queries, we can ask with a single query to an NP oracle whether qO is also a sound (and so, a proper) Σ-separation of λ+={c1→,…,cm→} and λ− in UCQ.
Lower bound: We start with STSEP(∅, GAV, UCQ), and then we address the STCHAR(∅, GAV, UCQ) case. The proof of Θ2p-hardness is by a LOGSPACE reduction from the odd clique problem, which is a Θ2p-complete problem [66]. Odd clique is the problem of deciding, given a finite and undirected graph G=(V,E) without loops, whether the maximum clique size of G is an odd number. Without loss of generality, we may assume that E contains at least an edge and that the cardinality of V is an even number (indeed, it is always possible to add fresh isolated nodes to the graph G without changing its maximum clique size).
Given a graph G=(V,E) as above with V={v1,…,vn}, we define an OBDM system ΣG=⟨JG,DG⟩ as follows: JG=⟨O,SG,MG⟩ is an OBDM specification in which O contains no assertions, SG={e,s1,…,sn}, and, for each odd i∈[1,n], the mapping MG has the following two GAV assertions:
{(x)∣∃y1,…,yi .si(x)∧cli}→{(x)∣Ai(x)}{(x)∣∃y1,…,yi+1 .si+1(x)∧cli+1}→{(x)∣Ai(x)}
where
Ai is an atomic concept in the alphabet of
O and, for each natural number
p,
clp is the conjunction of atoms:
clp=⋀{(k,j)∣1⩽k<j⩽p}e(yk,yj)
.
Intuitively, clp asks whether G contains a clique of size p. Finally, DG is the SG-database DG={e(x1,x2)∣(x1,x2)∈E}∪{e(x2,x1)∣(x1,x2)∈E}∪{si(c)∣1⩽i⩽n and i is odd}∪{si(c′)∣2⩽i⩽n and i is even}. Let, moreover, λ+ and λ− be the fixed DG-datasets λ+={(c)} and λ−={(c′)}.
Notice that λ+ and λ− are fixed, whereas the OBDM system ΣG can be constructed in LOGSPACE from an input graph G as above.
The correctness of the reduction is mainly based on the next property:
Claim 3.
Let i∈[1,n] be an odd number. We have that:
Proof.
As for 1, since si(c)∈DG, it is easy to see that the query qi={(x)∣∃y1,…,yi.si(x)∧cli} is such that (c)∈qiDG if and only if G has a clique of size i. Thus, due to the GAV assertion qi→{(x)∣Ai(x)} occurring in MG, we have Ai(c)∈COMG(DG) if and only if G has a clique of size i.
As for 2, since si+1(c′)∈DG, it is easy to see that the query qi+1={(x)∣∃y1,…,yi+1.si+1(x)∧cli+1} is such that (c′)∈qi+1DG if and only if G has a clique of size i+1. Thus, due to the GAV assertion qi+1→{(x)∣Ai(x)} occurring in MG, if G has a clique of size i+1, then Ai(c′)∈COMG(DG). Conversely, suppose that G has not a clique of size i+1. On the one hand, the assertion qi+1→{(x)∣Ai(x)} does not make Ai(c′) true in COMG(DG). On the other hand, since si(c′)∉DG, not even the assertion {(x)∣∃y1,…,yi.si(x)∧cli}→{(x)∣Ai(x)} makes Ai(c′) true in COMG(DG). Thus, Ai(c′)∉COMG(DG). □
With the above property in hand, we can now prove that the maximum clique size of a graph G is an odd number if and only if the CQ qO=query(MG(DG),(c)) is also a sound (and so, a proper) ΣG-separation of λ+ and λ− in UCQ, thus showing the claimed lower bound.
Claim 4.
The maximum clique size of a graph G is an odd number if and only if the CQ qO=query(MG(DG),(c)) is also a sound (and so, a proper) ΣG-separation of λ+ and λ− in UCQ.
Proof.
“Only-if part:” Suppose that the maximum clique size of G is p, where p is an odd number. Due to Claim 3, we have that COMG(DG)={A1(c),A1(c′),A3(c),A3(c′),…,Ap(c)}. Observe that Ap(c′)∉COMG(DG) because G has not a clique of size p+1 by assumption. Thus, qO=query(MG(DG),(c))={(xc)∣∃yc′.ϕO(xc,yc′)}, where ϕO(xc,yc′)=A1(xc)∧A1(yc′)∧A3(xc)∧A3(yc′)∧⋯∧Ap(xc). It is straightforward to verify that (set(ϕO),(xc))→(COMG(DG),(c)) but (set(ϕO),(xc))↛(COMG(DG),(c′)). It follows that certqO,JGDG={(c)}, i.e., qO is a proper ΣG-separation of λ+ and λ− in UCQ.
“If part:” Suppose that the maximum clique size of G is r, where r is an even number. Due to Claim 3, we have that COMG(DG)={A1(c),A1(c′),A3(c),A3(c′),…,Ar−1(c),Ar−1(c′)}. Observe that Ar−1(c′)∈COMG(DG) and Ar+1(c)∉COMG(DG) because by assumption G has a clique of size r but not of size r+1. Thus, qO=query(MG(DG),(c))={(xc)∣∃yc′.ϕO(xc,yc′)}, where ϕO(xc,yc′)=A1(xc)∧A1(yc′)∧A3(xc)∧A3(yc′)∧⋯∧Ar−1(xc)∧Ar−1(yc′). It is straightforward to verify that (set(ϕO),(xc))→(COMG(DG),(c′)). It follows that (c′)∈certqO,JGDG, and therefore qO is not a sound (and so, not a proper) ΣG-separation of λ+ and λ− in UCQ. □
As for the Θ2p-hardness of STCHAR(∅, GAV, UCQ), it is possible to use exactly the same reduction provided above by discarding λ− and considering only λ+={(c)}. In particular, the set of certain answers of the query qO=query(MG(DG),(c)) w.r.t. ΣG is always either {(c)} or {(c),(c′)}, and which one of the two depends on the parity of the maximum clique size of G. □
We now consider the remaining more general case of GLAV mappings.
Theorem 8.
SEP(DL-LiteR, GLAV, UCQ) and CHAR(DL-LiteR, GLAV, UCQ) are Π3p-complete. The lower bounds already hold for STSEP(∅, GLAV, UCQ) and STCHAR(∅, GLAV, UCQ).
The remainder of this section is dedicated to the proof of the above theorem and is organized as follows. We first provide the lower bound proof in Section 7.1, and then we provide a matching upper bound in Section 7.2.
7.1.Proof of Theorem 8: Lower bound
To simplify the presentation of the lower bound proof, we first assume that ontologies may contain also ternary predicates in their alphabet. Then, by simply applying reification we will provide the proof by removing such an assumption. We start with STSEP(∅, GLAV, UCQ), and then we address the STCHAR(∅, GLAV, UCQ) case.
With ternary predicates: The proof of Π3p-hardness is by a LOGSPACE reduction from the complement of the ∃∀∃-3CNF problem. Given a formula ϕ of the form ϕ=∃x→∀y→∃z→.c1∧⋯∧ck, such that ci is a disjunction of exactly three literals for i∈[1,k], ∃∀∃-3CNF is the problem of deciding whether ϕ is satisfiable. It is the prototypical Σ3p-complete [62] problem.
The reduction is as follows. Let ϕ=∃x→∀y→∃z→.c1∧⋯∧ck be an input formula for the ∃∀∃-3CNF problem, where x→=(x1,…,xn), y→=(y1,…,ym), and z→=(z1,…,zp). In what follows, for each i∈[1,k], we denote by vi,1, vi,2, and vi,3 the variable in x→∪y→∪z→ appearing, respectively, in the first, second, and third literal of the clause ci. We build an OBDM system Σϕ=⟨Oϕ,Sϕ,Mϕ,Dϕ⟩ as follows:
– Sϕ={sX,sY1,…,sYm,sa,sb,s1,…,sk}.
– Dϕ is the Sϕ-database consisting of the following facts:
∗ sX(x1,…,xn). So, we have a constant xi for each for each variable xi∈x→;
∗ sYi(0) and sYi(1) for each i∈[1,m]. In this way, a formula of the form ⋀imsYi(yi) has 2m possible assignments, each corresponding to an assignment to the variables y→ in ϕ;
∗ sa(xi,a) for each i∈[1,n];
∗ sb(0,b) and sb(1,b);
∗ for each i∈[1,k], we have 7 different facts of the form si(w1,w2,w3), with wj being either 0 or 1 for j∈[1,3]. These 7 facts represent all the possible assignments that satisfy the clause ci of ϕ. For example, if ϕ contains the clause c3=(¬x2∨¬y5∨z2), then Dϕ would contain the facts s3(0,0,0), s3(0,0,1), s3(0,1,0), s3(0,1,1), s3(1,0,0), s3(1,0,1), s3(1,1,1), and it would not contain the fact s3(1,1,0) corresponding to an assignment that does not satisfy the clause c3.
– Oϕ=∅. The alphabet of Oϕ contains a ternary predicate Pi for each i∈[1,k] and a binary predicates Pab. Informally, Pab will store Pab(0,b) and Pab(1,b), where 0, 1, and b are constants. Moreover, for each i∈[1,n], Pab will store Pa(xi,a), where a is a constant and xi is the constant representing the variable xi in ϕ. The role played by the ternary predicates Pi is twofold. (i) They represent the clauses of ϕ, with x→ as constants coming from Dϕ, each variable y∈y→ replaced with either 0 or 1, and the variables z→ as existential variables generated by a GLAV assertion in Mϕ; (ii) They also represent the 7 possible assignments that satisfy the clause ci.
– Finally, the mapping Mϕ consists of the following GLAV assertions:
∗ mϕ is the GLAV assertion
{x→∪y→∣sX(x1,…,xn)∧⋀i=1msYi(yi)}→{x→∪y→∣∃z1,…,zp.P1(v1,1,v1,2,v1,3)∧⋯∧Pk(vk,1,vk,2,vk,3)}, where x→∪y→=(x1,…,xn,y1,…,ym). Recall that, for each i∈[i,k], we have that vi,1, vi,2, and vi,3 denote, respectively, the variable in x→∪y→∪z→ appearing in the first, second, and third literal of the clause ci;
∗ for i∈[1,k], we have the assertion mi:{(w1,w2,w3)∣si(w1,w2,w3)}→{(w1,w2,w3)∣Pi(w1,w2,w3)};
∗ ma:{(w1,w2)∣sa(w1,w2)}→{(w1,w2)∣Pab(w1,w2)};
∗ mb:{(w1,w2)∣sb(w1,w2)}→{(w1,w2)∣Pab(w1,w2)}.
Intuitively, mϕ populates a total of 2m formulae based on ϕ. These formulae are obtained by assigning all possible combinations of 0 and 1 constants to the variables y→=(y1,…,ym). It is important to notice that in each of these 2m formulae the variables in x→ are always represented by the same constants in Dϕ, while the variables in z→ are represented each time by fresh variables, generated at each application of the mapping assertion corresponding to a combination of 0 and 1 constants for the variables y→ (i.e., the set of variables generated by an application of the assertion mϕ is disjoint from the set of variables generated by another application of the assertion mϕ).
For each i∈[1,k], the assertion mi generates on the predicate Pi all the possible assignments that satisfy the clause ci in the formula ϕ. Finally, the assertions ma and mb are used to generate in Mϕ(Dϕ) the facts Pab(xi,a) for each i=[1,n] and the two facts Pab(0,b) and Pab(1,b), respectively.
Finally, the fixed Dϕ-datasets are λ+={(a)} and λ−={(b)}. Notice that λ+ and λ− are fixed, whereas the OBDM system Σϕ can be constructed in LOGSPACE from an input formula ϕ=∃x→∀y→∃z→.c1∧⋯∧ck for the ∃∀∃-3CNF problem.
We are now going to prove that (COϕMϕ(Dϕ),(a))→(COϕMϕ(Dϕ),(b)) if and only if ϕ is satisfiable. This proves the correctness of the reduction, and therefore that STSEP(∅, GLAV, UCQ) is Π3p-hard. Indeed, according to the semantic test given in Section 6, we have that there exists a proper Σϕ-separation of λ+ and λ− in UCQ if and only if (COϕMϕ(Dϕ),(a))↛(COϕMϕ(Dϕ),(b)). In other words, (COϕMϕ(Dϕ),(a))→(COϕMϕ(Dϕ),(b)) is equivalent to say that there does not exist a proper Σϕ-separation of λ+ and λ− in UCQ.
Claim 5.
(COϕMϕ(Dϕ),(a))→(COϕMϕ(Dϕ),(b)) if and only if ϕ is satisfiable.
Proof.
Since Oϕ=∅, we have that COϕMϕ(Dϕ) and Mϕ(Dϕ) coincide. Notice that, by definition, every function f witnessing that (Mϕ(Dϕ),(a))→(Mϕ(Dϕ),(b)) must be such that f(a)=b. As a consequence, due to the Pab-facts occurring in Mϕ(Dϕ), the function f must associate to each constant xi representing a variable of the formula ϕ either the constant 0 or the constant 1, i.e., for each i∈[1,n] we have that either f(xi)=0 or f(xi)=1.
Now, if ϕ is satisfiable, then it is not hard to verify that there exists an association of the constants x→ with 0 and 1 that satisfy all 2m formulae represented in Mϕ(Dϕ). In particular, for each of these formulae, f also needs to associate to the existential variables z→ generated by the application of mϕ corresponding to that formula the constants 0 and 1 that will satisfy all the clauses of that formula. Thus, if ϕ is satisfiable, then we have that (Mϕ(Dϕ),(a))→(Mϕ(Dϕ),(b)).
Conversely, if ϕ is not satisfiable, then it is not hard to verify that for every possible association made by a function f for the constants x→ there exist at least one of those 2m formulae for which it is not possible to assign to the variables z→ of that formula the constants 0 and 1 that will satisfy all the clauses of that formula. Thus, if ϕ is not satisfiable, then we have that (Mϕ(Dϕ),(a))↛(Mϕ(Dϕ),(b)). □
As for the case of STCHAR(∅, GLAV, UCQ), it is possible to use exactly the same reduction provided above by discarding λ− and considering only λ+={(a)}. In particular, it is immediate to verify that (Mϕ(Dϕ),(a))↛(Mϕ(Dϕ),(c)) for each unary tuple (c) with c being a constant different from b (while whether it is the case that (Mϕ(Dϕ),(a))↛(Mϕ(Dϕ),(b)) depends solely on the satisfiability of ϕ).
We now discuss the necessary changes to be made to the above reduction to work in the presence of only binary predicates (atomic roles) in the ontology alphabet.
Without ternary predicates (only atomic roles): Let ϕ=∃x→∀y→∃z→.c1∧⋯∧ck be an input formula for the ∃∀∃-3CNF problem, where x→=(x1,…,xn), y→=(y1,…,ym), and z→=(z1,…,zp). We build an OBDM system Σϕ=⟨Oϕ,Sϕ,Mϕ,Dϕ⟩ as follows:
– Sϕ={sX,sY1,…,sYm,sa,sb,s1,1,s1,2,s1,3,s2,1,s2,2,s2,3,…,sk,1,sk,2,sk,3}. Differently from the previous case, for each i∈[1,k], we have three binary predicates si,1, si,2, and si,3 instead of a single ternary relation si.
– Dϕ is the Sϕ-database consisting of the following facts:
∗ sX(x1,…,xn);
∗ sYi(0) and sYi(1) for each i∈[1,m];
∗ sb(0,b) and sb(1,b);
∗ for each i∈[1,k], we make use of 7 different constants Ai,1,…,Ai,7. Moreover, for each i∈[1,k] and j∈[1,7], we have three facts of the form si,1(Ai,j,wi,j1), si,2(Ai,j,wi,j2), and si,3(Ai,j,wi,j3) with wi,jl being either 0 or 1 for l∈[1,3]. These 7 constants represent all the possible assignments that satisfy the clause ci of ϕ, and the value assumed by each wi,jl is the value corresponding to the j-th assignment in the l-th position of clause ci. For example, if ϕ contains the clause c3=(¬x2∨¬y5∨z2), then Dϕ would contain the following facts: s3,1(A3,1,0), s3,2(A3,1,0), and s3,3(A3,1,0); s3,1(A3,2,0), s3,2(A3,2,0), and s3,3(A3,2,1); s3,1(A3,3,0), s3,2(A3,3,1), and s3,3(A3,3,0); s3,1(A3,4,0), s3,2(A3,4,1), and s3,3(A3,4,1); s3,1(A3,5,1), s3,2(A3,5,0), and s3,3(A3,5,0); s3,1(A3,6,1), s3,2(A3,6,0), and s3,3(A3,6,1); s3,1(A3,7,1), s3,2(A3,7,1), and s3,3(A3,7,1). It would not contain the facts s3,1(A3,8,1), s3,2(A3,8,1), and s3,3(A3,8,0) corresponding to an assignment that does not satisfy the clause c3.
– Oϕ=∅. The alphabet of Oϕ contains the atomic role Pab and three atomic roles Pi,1, Pi,2, and Pi,3 for each i∈[1,k].
– Finally, the mapping Mϕ consists of the following GLAV assertions:
∗ mϕ is the GLAV assertion
{x→∪y→∣sX(x1,…,xn)∧⋀i=1msYi(yi)}→{x→∪y→∣∃g1,…,gk,z1,…,zp.P1,1(g1,v1,1)∧P1,2(g1,v1,2)∧P1,3(g1,v1,3)∧P2,1(g2,v2,1)∧P2,2(g2,v2,2)∧P2,3(g2,v2,3)∧⋯∧Pk,1(gk,vk,1)∧Pk,2(gk,vk,2)∧Pk,3(gk,vk,3)}, where x→∪y→=(x1,…,xn,y1,…,ym). Recall that, for each i∈[i,k], we have that vi,1, vi,2, and vi,3 denote, respectively, the variable in x→∪y→∪z→ appearing in the first, second, and third literal of the clause ci;
∗ for i∈[1,k], we have the assertions mi,1:{(w1,w2)∣si,1(w1,w2)}→{(w1,w2)∣Pi,1(w1,w2)}, mi,2:{(w1,w2)∣si,2(w1,w2)}→{(w1,w2)∣Pi,2(w1,w2)}, and mi,3:{(w1,w2)∣si,3(w1,w2)}→{(w1,w2)∣Pi,3(w1,w2)};
∗ ma:{(w1,w2)∣sa(w1,w2)}→{(w1,w2)∣Pab(w1,w2)};
∗ mb:{(w1,w2)∣sb(w1,w2)}→{(w1,w2)∣Pab(w1,w2)}.
Finally, exactly as in the previous case of ternary predicates, the fixed Dϕ-datasets are λ+={(a)} and λ−={(b)}. Notice that λ+ and λ− are fixed, whereas the OBDM system Σϕ can be constructed in LOGSPACE from an input formula ϕ=∃x→∀y→∃z→.c1∧⋯∧ck for the ∃∀∃-3CNF problem.
Intuitively, differently from the case of ternary predicates, each of the 2m formulae generated by mϕ is represented by binary predicates P1,1,P1,2,P1,3,…,Pk,1,Pk,2,Pk,3, with the additional freshly introduced existential variables g1,…,gk representing the resulting clauses ci,…,ck of that formula. Thus, for each of the 2m formulae, a function f witnessing that (Mϕ(Dϕ),(a))→(Mϕ(Dϕ),(b)) must associate to each variable gi of that formula one of the 7 constants Ai,1,…,Ai,7. Using analogous arguments as those given in the proof of Claim 5, it is immediate to verify that (Mϕ(Dϕ),(a))→(Mϕ(Dϕ),(b)) if and only if ϕ is satisfiable, from which we derive that STSEP(∅, GLAV, UCQ) is Π3p-hard (observe that Mϕ(Dϕ)=COϕMϕ(Dϕ)). As in the previous case of ternary predicates, for the case of STCHAR(∅, GLAV, UCQ), it is possible to use exactly the same reduction provided above by discarding λ− and considering only λ+={(a)}. Since we always have that (Mϕ(Dϕ),(a))↛(Mϕ(Dϕ),(c)) for each unary tuple (c) with c being a constant different from b (while whether it is the case that (Mϕ(Dϕ),(a))↛(Mϕ(Dϕ),(b)) depends solely on the satisfiability of ϕ), we derive that STCHAR(∅, GLAV, UCQ) is Π3p-hard as well.
7.2.Proof of Theorem 8: Upper bound
First of all, we assume to only deal with consistent OBDM systems Σ. Indeed, given an inconsistent OBDM system Σ=⟨J,D⟩ and two D-datasets λ+ and λ− (resp., a D-dataset λ+) of arity n, we point out that there exists a proper Σ-separation (resp., Σ-characterization) of λ+ and λ− (resp., of λ+) in UCQ if and only if λ+=dom(D)n, where n is the arity of λ+. Since we will provide a Π3p upper bound for the case of consistent OBDM systems and since for an OBDM system Σ=⟨O,S,M,D⟩ such that O is a DL-LiteR ontology and M is a GLAV mapping checking whether Σ is inconsistent can be done in NP using the technique described in the proof of Theorem 1, for simplifying the presentation of the proof we can assume to deal only with consistent OBDM systems.
Recall from the semantic tests given at the end of Section 6 that there exists a proper Σ-separation (resp. Σ-characterization) of λ+ and λ− (resp., of λ+) in UCQ if and only if it is the case that (COM(D),a→)↛(COM(D),b→) for all a→∈λ+ and all b→∈λ− (resp., all b→∈dom(D)n∖λ+). With this observation at hand, we can solve the complements of SEP(DL-LiteR, GLAV, UCQ) and CHAR(DL-LiteR, GLAV, UCQ) in Σ3p using the following intuition: given an OBDM system Σ=⟨O,S,M,D⟩ such that O is a DL-LiteR ontology and M is a GLAV mapping, and given two D-datasets λ+ and λ− (resp., a D-dataset λ+) of arity n, we first guess a tuple a→, a tuple b→, and a function W from dom(D) to Const∪V. Then, we check whether a→∈λ+, b→∈λ− (resp., b→∈dom(D)n∖λ+), W is such that W(a→)=b→ and every constant in dom(D) is mapped to an existing term in COM(D). Finally, we call an oracle for the problem of checking whether W can be extended to a function f witnessing that (COM(D),a→)→(COM(D),b→).
In order to realize the presented intuition, we first introduce some preliminary results that will allow us to simplify the presentation of the problem, as well as some naming conventions that we will adopt for the fresh variables generated when computing COM(D) starting from D.
We start by observing that checking whether (COM(D),a→)→(COM(D),b→) is equivalent to checking whether (COM(D),a→)→((COM(D))′,b′→), where (COM(D))′ is obtained from COM(D) simply by substituting every occurrence of a constant c∈dom(COM(D)) with its fresh copy c′.
Lemma 1.
(COM(D),a→)→(COM(D),b→) if and only if (COM(D),a→)→((COM(D))′,b′→).
Proof.
“Only-if part”: Let h be a homomorphism witnessing (COM(D),a→)→(COM(D),b→), i.e. it holds that: (i) h(a→)=b→ and (ii) α∈COM(D) implies h(α)∈COM(D) for each α∈COM(D). Let h′ be a function such that, for every term t (i.e., either a constant or a variable): (i) if h(t)=c for a constant c, then h′(t)=c′, i.e. h′ assigns to t the copy c′ of c; (ii) if h(t)=v for a variable v, then h′(v)=v, i.e. h′ assigns to t the same variable v. Since h is such that h(a→)=b→, we have that h′(a→)=b′→. Moreover, since α∈COM(D) implies h(α)∈COM(D) for each α∈COM(D), by construction we have that α∈COM(D) implies h′(α)∈(COM(D))′ for each α∈COM(D). Thus, h′ witnesses that (COM(D),a→)→((COM(D))′,b′→).
“If part”: The proof can be obtained by following the same considerations of the “Only-if” part, by switching the roles of the two functions h and h′. □
As a consequence of the above lemma, we can show that it is possible to reduce the problem of verifying whether (COM(D),a→)→(COM(D),b→) to the equivalent problem of verifying whether (COM(D),a→)→(COM(D′),b′→), where D′ is computed from D by substituting every occurrence of a constant c∈dom(D) with its fresh copy c′∈dom(D′). Although strictly not necessary, in the problem of verifying whether (COM(D),a→)→(COM(D),b→) (equivalent to (COM(D),a→)→(COM(D′),b′→)) this simple consideration will allow us to simplify the presentation of the upper bound proof, because we can distinguish between the canonical structure on the left-hand side of the arrow and the canonical structure on the right-hand side of the arrow.
Lemma 2.
(COM(D),a→)→(COM(D),b→) if and only if (COM(D),a→)→(COM(D′),b′→).
Proof.
This is a straightforward consequence of Lemma 1 and the fact that (COM(D))′ and COM(D′) coincide (up to variable renaming). □
In all what follows, given an S-database D and a tuple b→ of constants from dom(D), we will implicitly assume that D′, called the copy of D, represents the S-database obtained from D by substituting every occurrence of a constant c∈dom(D) with its fresh copy c′∈dom(D′), and b′→ represents the copy of the tuple b→. It is clear that both D′ and b′→ can be computed in polynomial time from D and b→.
The following fundamental lemma tells us that, when verifying whether (COM(D),a→)→(COM(D′),b′→), on the left-hand side of the arrow we can actually restrict the attention only at M(D).
Lemma 3.
(COM(D),a→)→(COM(D′),b′→) if and only if (M(D),a→)→(COM(D′),b′→).
Proof.
The “Only-if” part is trivial, since by restricting the homomorphism witnessing (COM(D),a→)→(COM(D′),b′→) to the terms in M(D) we derive an homomorphism witnessing (M(D),a→)→(COM(D′),b′→).
As for the “If” part, let h be a homomorphism witnessing (M(D),a→)→(COM(D′),b′→). Consider any concept inclusion assertion B1⊑B2 (resp., role inclusion assertion R1⊑R2) in O such that M(D)⊧B1(t) for some t∈dom(M(D)) (resp, M(D)⊧R1(t1,t2) for some terms t1,t2∈dom(M(D))). This means that COM(D)⊧B2(t) (resp., COM(D)⊧R2(t1,t2)). Now, since by assumption we have that COM(D′)⊧B1(h(t)) (resp, COM(D′)⊧R1(h(t1),h(t2))) because h is a homomorphism from M(D) to COM(D′), we derive that COM(D′)⊧B2(h(t)) (resp., COM(D′)⊧R2(h(t1),h(t2))). With this observation at hand, it is easy to see that any homomorphism h witnessing (M(D),a→)→(COM(D′),b′→) can be extended to an homomorphism h′ witnessing (COM(D),a→)→(COM(D′),b′→). □
We now introduce some naming conventions we will adopt for the fresh variables generated when computing COM(D) starting from D.
Naming convention for the chase of the database with respect to the mapping: Let M be a GLAV mapping relating a source schema S to an ontology O, and let D an S-database. We call p=(m,hm) a single application of M on D, where m={x→∣∃y→.ϕS(x→,y→)}→{x→∣∃z→.φO(x→,z→)}, with z→=(z1,…,zn), is a mapping assertion in M, and hm is a homomorphism from set(ϕ) to D. We denote by p(D) the set of atoms h′(set(φO)), where h′ extends hm by assigning to the existential variable zi∈z→ the variable zip∈dom(M(D)), for i∈[1,n]. Notice that, up to variable renaming, M(D) coincides with ⋃p∈Pp(D), where P is the set of all the possible single applications of M on D. It is important to notice that, in this way, each variable zip generated when chasing D with respect to M carries in its name both the application p=(m,hm) that generated it and which was the variable zi inside m.
Naming convention for the chase with respect to the ontology: Let M be a GLAV mapping relating a source schema S to an ontology O, let D an S-database, and O be a DL-LiteR ontology. We follow standard conventions for the name given to the freshly introduce variables when computing the chase of M(D) with respect to O (see, e.g. [33]). More specifically, dom(COM(D)) contains all the constants and variables occurring in dom(M(D)) and all the variables of the form tR1,…,Rn, with t∈dom(M(D)), n⩾1, and Ri a basic role for each i∈[1,n], such that:
– there is a basic concept B with M(D)⊧B(t) and O⊧B⊑∃R1, but R′(t,t′)∉M(D) for all t′∈dom(M(D)) and basic role R′ with O⊧R′⊑R1;
– O⊧∃Ri−⊑∃Ri+1 and O⊭Ri−⊑Ri+1, for each i∈[1,n−1].
As an example, suppose that
M(D)={A(t)} for a term
t that is either a constant in
D or a fresh variable introduced when chasing
D with respect to
M, and let
O={A⊑C,C⊑∃R−,∃R⊑∃S}. Then,
COM(D)={A(t),C(t),R(tR−,t),S(tR−,tR−S)}, where
tR− and
tR−S are the fresh variables introduced when chasing
M(D) with respect to
O.
Before illustrating the non-deterministic algorithms for solving the complements of SEP(DL-LiteR, GLAV, UCQ) and CHAR(DL-LiteR, GLAV, UCQ), we introduce a new notion and some fundamental technical results. Let Σ=⟨O,S,M,D⟩ be an OBDM system such that O is a DL-LiteR ontology and M is a GLAV mapping, D be an S-database, a→ be a tuple of constants from dom(D), D′ be the copy of D, and b′→ be a tuple of constants from dom(D′). A partial witnessing function (in short, pwf) of (M(D),a→) on (COM(D′),b′→) is a function W from dom(D) to dom(COM(D′)) such that W(a→)=b′→. We call such function partial because only the constants of M(D) have an assignment to a term in COM(D′), while the variables of M(D) have not been assigned yet. The following lemma follows by definition.
Lemma 4.
(M(D),a→)→(COM(D′),b′→) if and only if there exists a pwf W of (M(D),a→) on (COM(D′),b′→) that can be extended to a function f from dom(M(D)) to dom(COM(D′)) witnessing that (M(D),a→)→(COM(D′),b′→), i.e., such that α∈M(D) implies f(α)∈COM(D′) for each α∈M(D).
We now present a fundamental technical result that will allow us to restrict the attention only to those pwfs W such that the range of the function W contains constants and variables whose names lengths are of polynomial size with respect to the size of the input OBDM system Σ.
Lemma 5.
Let P be the set of all the possible single applications of M on D, and let W be a pwf of (M(D),a→) on (COM(D′),b′→). Then, we have that W can be extended to a function f from dom(M(D)) to dom(COM(D′)) witnessing that (M(D),a→)→(COM(D′),b′→) if and only if the following holds:
– for every single application p∈P of M on D, there is a function fp′ from variables in dom(p(D)) to dom(COM(D′)) such that α∈p(D) implies fp(α)∈COM(D′), where fp=W∪fp′ denotes the function from dom(p(D)) to dom(COM(D′)) such that fp(t)=W(t) if t is a constant and fp(t)=fp′(t) if t is a variable.
Proof.
The proof can be obtained by simply combining these two observations: (i) all the constants in dom(M(D)) are already assigned to a term in dom(COM(D′)) by the function W; (ii) every single application p∈P of M on D produces new variables in M(D) without ever reusing the variables introduced in other applications of the mappings. In other words, the set of all variables produced by a single application p of M on D, and the set of all variables produced by all the other possible single applications p′∈P∖{p} of M on D are disjoint. Thus, a function f extending W and witnessing (M(D),a→)→(COM(D′),b′→) can always be split into many fps functions as in the statement of the lemma, and, vice versa, if the functions fps as in the statement of the lemma exist, then they can be combined into an overall function f witnessing (M(D),a→)→(COM(D′),b′→). □
As announced before, the above lemma has a crucial consequence. In particular, let Σ=⟨O,S,M,D⟩ be an OBDM system. Since the number of atoms in p(D) generated by a single application p of M on D is at most polynomial with respect to the size of M (i.e., it is at most the number of atoms occurring in the longest right-hand side among all m∈M), from the above lemma and due to the forest-shaped form of the canonical structure COM(D′), it is not hard to see that the following holds: if there exists a pwf W of (M(D),a→) on (COM(D′),b′→) that can be extended to a function f from dom(M(D)) to dom(COM(D′)) witnessing that (M(D),a→)→(COM(D′),b′→), then there exists another pwf W′ that can be extended to a function f′ from dom(M(D)) to dom(COM(D′)) witnessing that (M(D),a→)→(COM(D′),b′→) and such that each variable in the range of f′ (and therefore also in the range of W′) has a name length that is bounded by a polynomial in the size of O and M, which implies that the variable can be generated after polynomially many chase steps of M(D′) with respect to O.
We are now finally ready to present the non-deterministic algorithms for solving the complements of SEP(DL-LiteR, GLAV, UCQ) and CHAR(DL-LiteR, GLAV, UCQ). We first concentrate on CHAR(DL-LiteR, GLAV, UCQ) by providing the non-deterministic Algorithm 3 (CharExistence).
Algorithm 3

Notice that the Algorithm 3 (CharExistence) uses an oracle for the auxiliary decision problem CheckTotalExtension, which is the problem of deciding, given an OBDM system Σ=⟨O,S,M,D⟩ and a pwf W of (M(D),a→) on (COM(D′),b′→), whether W can be actually extended to a function f from dom(M(D)) to dom(COM(D′)) witnessing that (M(D),a→)→(COM(D′),b′→).
Lemma 6.
Let Σ=⟨O,S,M,D⟩ be a consistent OBDM system and λ+ be a D-dataset. We have that CharExistence(Σ, λ+) terminates and returns true if and only if there exists a proper Σ-characterization of λ+ in UCQ.
Proof.
Termination of the algorithm is immediate, while its correctness can be obtained by simply combining the semantic test given at the end Section 6 with Lemmata 2, 3, and 4. □
As for the running time, we observe that, due to the discussion after Lemma 5, we can concentrate only on pwfs W whose range contains only constants and variables whose names lengths are of polynomial size with respect to the input OBDM system Σ, and therefore the overall W is of polynomial size with respect to Σ since the number of constants in D is polynomial. Furthermore, we can check in polynomial time whether W is a pwf of (M(D),a→) on (COM(D′),b′→), i.e., whether all the terms in the range of W occur in dom(COM(D′)) as follows. For each term t in the range of W, we compute pt(D′), where pt is the guessed application of M on D′ for the term t (of course, we first need to check whether hm is a homomorphism from the atoms on the left-hand side of m to D′). Starting from the set pt(D′) of atoms, we then iteratively apply the guessed ontology assertions in the sequence ρt for the term t one after the other, each time by applying the considered ontology assertion in a single chase step over all the atoms obtained so far. Finally, we check whether the term t occurs in the overall set of atoms obtained in this way.
Thus, with respect to the size of its input, the overall running time of the non-deterministic Algorithm 3 (CharExistence) is polynomial with an oracle for the decision problem CheckTotalExtension. As a consequence, we derive that the complement of CHAR(DL-LiteR, GLAV, UCQ) is in NP with an oracle in C, i.e., NPC, where C is the computational complexity of CheckTotalExtension. As for the case of SEP(DL-LiteR, GLAV, UCQ), we can use a slight adaptation of the Algorithm 3 (CharExistence), which takes in the input an additional D-dataset λ− and modifies the step 5 of the algorithm by checking b→∈λ− instead of checking b→∉λ+. This means that the complement of SEP(DL-LiteR, GLAV, UCQ) is in NPC as well, where C is the computational complexity of CheckTotalExtension.
To conclude the proof of the upper bound, we are now going to show that CheckTotalExtension is in Π2p (thus, C=Π2p), which gives us the desired Σ3p upper bound for the complements of both CHAR(DL-LiteR, GLAV, UCQ) and SEP(DL-LiteR, GLAV, UCQ), and therefore this will show that both CHAR(DL-LiteR, GLAV, UCQ) and SEP(DL-LiteR, GLAV, UCQ) are in Π3p, as required.
Upper bound for the decision problem CheckTotalExtension
Lemma 7.
CheckTotalExtension is in Π2p.
Proof.
We recall that CheckTotalExtension is the problem of deciding, given an OBDM system Σ=⟨O,S,M,D⟩ and a pwf W of (M(D),a→) on (COM(D′),b′→), whether W can be extended to a function f from dom(M(D)) to dom(COM(D′)) witnessing that (M(D),a→)→(COM(D′),b′→), i.e., such that α∈M(D) implies f(α)∈COM(D′) for each α∈M(D).
By Lemma 5, we can immediately derive the following non-deterministic algorithm to solve the complement of the CheckTotalExtension decision problem:
– Guess a pair p=(m,hm), where m={x→∣∃y→.ϕS(x→,y→)}→{x→∣∃z→.φO(x→,z→)} is a mapping assertion in M, and hm is a function from the variables in x→∪y→ to dom(D);
– Check whether p is an application of m on D, which amounts to check whether m∈M and hm is a homomorphism from set(ϕS) to D (if not, then return false);
– Compute p(D);
– Call an oracle for the decision problem CheckSingleExtension with input Σ, W, p(D);
– If the oracle accepts, then return false; otherwise return true.
Notice that the above non-deterministic algorithm uses an oracle for the auxiliary decision problem CheckSingleExtension, which is the problem of deciding, given an OBDM system Σ=⟨O,S,M,D⟩, a pwf W of (M(D),a→) on (COM(D′),b′→), and a set of atoms p(D) from M(D), whether W can be actually extended to a function f from dom(p(D)) to dom(COM(D′)) such that f is a homomorphism from p(D) to COM(D′), i.e., α∈p(D) implies f(α)∈COM(D′) for each α∈p(D). Notice the difference between the decision problems CheckTotalExtension and CheckSingleExtension. While CheckTotalExtension additionally takes in the input only Σ and W, CheckSingleExtension takes in the input also the set of atoms p(D).
The termination of the algorithm is straightforward. Furthermore, due to Lemma 5 and the definition of the auxiliary decision problem CheckSingleExtension, it is immediate to verify that the above non-deterministic algorithm solves the complement of CheckTotalExtension, i.e., returns true if and only if W cannot be extended to a function f from dom(M(D)) to dom(COM(D′)) such that α∈M(D) implies f(α)∈COM(D′) for each α∈M(D). As for its running time, we observe that the size of the guessed p is clearly polynomial with respect to the size of the input, and both checking whether hm is a homomorphism from set(ϕS) to D, and computing the set p(D) of atoms, given hm, can be performed in polynomial time with respect to the size of the input. As a consequence, we derive that the complement of CheckTotalExtension is in NP with an oracle in C′, i.e., NPC′, where C′ is the computational complexity of CheckSingleExtension. Thus, CheckTotalExtension is in coNPC′. In the following lemma, we are going to show that CheckSingleExtension is in NP (thus, C′=NP), which concludes the proof of the desired Π2p upper bound for the decision problem CheckTotalExtension. □
Upper bound for the decision problem CheckSingleExtension
Lemma 8.
CheckSingleExtension is in NP.
Proof.
Recall that CheckSingleExtension is the problem of deciding, given an OBDM system Σ=⟨O,S,M,D⟩, a pwf W of (M(D),a→) on (COM(D′),b′→), and a set p(D) such that p(D)⊆M(D), whether W can be extended to an homomorphism f from p(D) to COM(D′). In other words, the problem seeks for a function f′ that assign to each variable in p(D) a term occurring in dom(COM(D′)) such that α∈p(D) implies f(α)∈COM(D′) for each α∈p(D), where f=W∪f′ is the function such that f(t)=W(t) is t is a constant, and f(t)=f′(t) if t is a variable.
Obviously, for an homomorphism f from p(D) to COM(D′) to exist, we do not need to generate all the atoms in COM(D′) but we actually need only a number of atoms that is less than or equal the number of atoms in p(D). Furthermore, due to the forest-shaped form of the canonical structure COM(D′), each of such atoms can be generated after polynomially many chase steps of M(D′) with respect to O.
From the above consideration, we can immediately derive the following non-deterministic algorithm to solve the CheckSingleExtension decision problem.
– A′:=∅;
– For each α∈p(D):
∗ Guess a pair pα′=(m,hm) and a sequence ρα of ontology assertions in O. Here, m={x→∣∃y→.ϕS(x→,y→)}→{x→∣∃z→.φO(x→,z→)} is a mapping assertion in M and hm is a function from the variables in x→∪y→ to dom(D′);
∗ Check whether hm is a homomorphism from set(ϕS) to D′ (if not, then return false);
∗ Compute pα′(D′) and set A′:=A′∪pα′(D′);
∗ Let ρα=(o1,…,on);
∗ For each i←1,…,n:
∗ End For
– End For
– Guess a function f′ from the variables in dom(p(D)) to dom(A′);
– Let f=W∪f′ be the function from dom(p(D)) to dom(A′) such that f(t)=W(t) if t is a constant and f(t)=f′(t) if t is a variable;
– If f consists in a homomorphism from p(D) to A′, then return true; otherwise return false.
In a nutshell, for each atom α∈p(D), the algorithm generates a set Aα′ of atoms in COM(D′) by first computing the guessed application pα′ of M on D′, and then by iteratively applying the guessed ontology assertions in the sequence ρα one after the other, each time by applying the considered ontology assertion in a single chase step over all the atoms obtained so far. Finally, the algorithm checks whether the given W can be extended to a homomorphism from p(D) to A′, where A′=⋃α∈p(D)Aα′ is the set of all the atoms obtained as above.
The termination and the correctness of the algorithm are straightforward. It is indeed immediate to verify that the above non-deterministic algorithm solves CheckSingleExtension, i.e., returns true if and only if W can be extended to an homomorphism f from p(D) to COM(D′).
As for its running time, as already observed, we can restrict the attention only to those atoms of COM(D′) that can be generated after polynomially many chase steps of M(D′) with respect to O. Thus, for each α∈p(D), both the guessed pα′ and the guessed sequence ρα are of polynomial size with respect to the input, which implies that the overall number of atoms in A′ is of polynomial size with respect to the input. Furthermore, checking whether hm is a homomorphism from set(ϕS) to D′, computing the set pα′(D′) of atoms, applying in sequence the ontology assertions in ρα in single chase steps, and checking whether f is a homomorphism from p(D) to A′ (i.e., whether α∈p(D) implies f(α)∈A′ for each α∈p(D)) are all steps that can be carried out in polynomial time with respect to the size of the input. This means that the above non-deterministic algorithm runs in polynomial time with respect to the size of the input, and therefore that CheckSingleExtension is in NP, as required. □
8.Conclusion and future work
In this paper, we have studied logical separability in OBDM. As a first contribution, we have illustrated a general framework for separability in OBDM, by also proposing natural relaxations of the classical separability notion (called here proper separation). In the general envision of separability as a tool for providing global post-hoc explanations of black-box models, we argue that such relaxations (especially the best approximations) are crucial in order to always be able to provide meaningful explanations even when proper separations do not exist. As a second contribution, by instantiating the general framework with the most common languages used in OBDM, we have provided a comprehensive study of three computational problems associated with the framework, namely Verification, Computation, and Existence. For the decision problems related to Verification and Existence, we have provided tight complexity results, whereas for the Computation problem we have devised two algorithms for computing the two forms of best approximated separations considered in this paper, thus proving they always exist.
We conclude the paper by discussing some interesting avenues for future work that deserve more investigation.
More expressive scenarios It would be interesting to study extensions of the scenario considered in this paper for the computational problems. For example, one may consider more expressive target query languages that go beyond UCQ, in order to capture proper separations in more cases. Natural candidates for this are UCQ≠, i.e., UCQ with inequalities, First-order logic, and EQL-Lite [16]. However, differently from our case, by extending the considered scenario with one of these query languages, adopting or not the UNA makes a difference.
As other interesting extensions of the considered scenario, one may investigate highly expressive ontology languages, such as SHIQ [36] or even SROIQ [35], where the separability task has not yet been studied even in the ontology-enriched query answering setting (i.e., without considering mapping assertions).
Strong separability In [37], separability comes into two flavours: weak separability and strong separability. In weak separability, which is the one we addressed in this paper, the requirement on the negative examples is that none of them is included in the set of certain answers of the separating query. On the other hand, in strong separability, the requirement on the negative examples is that all of them are included in the set of the certain answers of the negation of the separating query. Thus, a natural problem to be addressed in our considered OBDM scenario is strong separability, by considering relaxations also in this case.
Quantitative metrics for best approximations In this work, we have defined best approximations of the proper separation notion by adopting the set-inclusion metric. Another common choice that would be interesting to investigate is the cardinality criteria. Moreover, for a more fine-grained usage of separability as a tool for explanation, it would be natural to assign weights to both positive and negative examples, and to consider such weights when computing best approximations of proper separations.
Restricted signature A possible constraint that can be imposed when finding a separating query is that the query expression uses only a specific subset of the predicates available in the alphabet of the ontology O. This may be important to meet some users’ requirements regarding the separating query, as for example a user may ask for a separating query that does not make use of a specific concept. The separating task under restricted signature has been studied in [39] in the ontology-enriched query answering setting, in the particular case of expressive ontology languages, such as ALC or ALCO. Typically, the computational complexity of checking for a proper separation increases under the restricted signature constraint. Thus, another notable direction is to study separability in the considered OBDM scenario under the restricted signature constraint.
Intelligible queries A delicate question from an end-user perspective is the number of atoms involved in each of the disjuncts of the separating queries. While under both GAV and LAV mappings our algorithms presented for the computation problem ensure that this number of atoms is “only” polynomially related to the size of the mapping and the database, the same is not true in the presence of GLAV mappings. In particular, it remains an interesting open question whether or not, under GLAV mappings, there are cases in which separations (or their best approximated versions) must necessarily be of exponential size with respect to the size of the mapping and the database.
More generally speaking, the separating queries may sometimes be very hard to understand from an end-user perspective. Thus, it would be natural to consider also the length of each disjunct, as well as the number of disjuncts, as additional parameters when considering approximations. This requires to consider novel definitions and techniques that may allow obtaining, from end users’ perspectives, more intelligible (approximated) separating queries.
Implementation Finally, we mention that we are currently implementing the algorithms and techniques proposed in this paper using the OBDM engine Mastro [14]. The implementation we are working on follows the recently introduced Human-in-the-loop Artificial Intelligence (HitAI) paradigm [69]. By running some experiments with a first prototype in real-world settings, we observed as the above-mentioned issues for future work turn out to be crucial, especially the ones concerning intelligible queries and quantitative metrics.



