
A survey on knowledge-aware news recommender systems
Abstract
News consumption has shifted over time from traditional media to online platforms, which use recommendation algorithms to help users navigate through the large incoming streams of daily news by suggesting relevant articles based on their preferences and reading behavior. In comparison to domains such as movies or e-commerce, where recommender systems have proved highly successful, the characteristics of the news domain (e.g., high frequency of articles appearing and becoming outdated, greater dynamics of user interest, less explicit relations between articles, and lack of explicit user feedback) pose additional challenges for the recommendation models. While some of these can be overcome by conventional recommendation techniques, injecting external knowledge into news recommender systems has been proposed in order to enhance recommendations by capturing information and patterns not contained in the text and metadata of articles, and hence, tackle shortcomings of traditional models. This survey provides a comprehensive review of knowledge-aware news recommender systems. We propose a taxonomy that divides the models into three categories: neural methods, non-neural entity-centric methods, and non-neural path-based methods. Moreover, the underlying recommendation algorithms, as well as their evaluations are analyzed. Lastly, open issues in the domain of knowledge-aware news recommendations are identified and potential research directions are proposed.
1.Introduction
In the past two decades, there has been a shift in individuals’ news consumption, from traditional media, such as printed newspapers or radio and TV news broadcasts, to online media platforms, in the form of news websites and aggregation services, or social media. News platforms use a form of a recommender system to help users navigate through the overwhelming amount of news published daily by suggesting relevant articles based on their interests and reading behavior. Recommender systems have proven successful over time in numerous domains [124], ranging from music [31,106], movies [7,110], or books recommendation [36,62,77], to e-commerce [141,142,149], travel and tourism [15], or research paper recommendation [5].
In comparison to these domains, news recommendation poses additional challenges which hinder a direct transfer of traditional recommendation techniques [132]. Firstly, the relevance of news changes quickly within short periods of time and is highly dependent on the time sensitiveness and popularity of articles [84,120]. Secondly, articles may be semantically related and users’ interests evolve dynamically over time, meaning that it is not trivial to accurately capture the preferences of individual users [120]. Thirdly, common limitations of recommender systems (i.e. the cold-start problem, data sparsity, scalability), are further intensified by the greater item churn of news [39], the fact that usually user profiles are constrained to a single session [44], and that their feedback is typically collected implicitly, from their reading behavior rather than explicitly provided during a session [101]. Additionally, news articles contain a large number of knowledge entities and common sense knowledge, which are not incorporated in conventional news recommendation methods [170].
Enhancing classic information retrieval and recommendation methods with external information from knowledge bases has been proposed as a potential solution for some of the aforementioned shortcomings of recommender systems in the news domain. Knowledge graphs are directed, labeled heterogeneous graphs which describe real-world entities and their interrelations [126]. Knowledge-aware recommender systems inject information contained in knowledge graphs or domain-specific ontologies to capture information and reveal patterns that are not contained directly in an item’s features [66]. In the case of news recommendation, such knowledge-enhanced models have been developed to capture the semantic meaning and relatedness of news, remove ambiguity, handle named entities, extend text-level information with common sense knowledge, discover knowledge-level connections between news, and overcome cold-start and data sparsity issues.
Previous works provide overviews of this field from two directions. On the one hand, surveys such as [66] or [59], focus on knowledge-aware recommender systems applied to a variety of domains, such as movies, books, music, or products. Although a few of the discussed models come from the news domain, none of these works extensively review how external knowledge can be used to enhance news recommendation. On the other hand, a vast number of surveys analyze the news recommendation problem from various angles, including challenges and algorithmic approaches [11,14,47,84,94,95,120,132], performance comparison in online news recommendation challenges [43,44], user profiling [67], news features-based methods [129], or impact on content diversity [114]. However, the focus of these studies is not on the use of external knowledge resources. In contrast to existing studies, this survey focuses on categorizing and examining knowledge-aware news recommender systems, developed either specifically for or evaluated also on the news domain, as a solution for enhancing recommendations and overcoming limitations of traditional recommendation models. The analysis of such systems covers both a review of the algorithmic approaches used for computing recommendations, as well as a comparison of evaluation methodologies and a discussion of limitations and research gaps.
The contributions of the paper are threefold:
1. We propose a new taxonomy of knowledge-aware news recommender systems. The recommendation approaches are classified into non-neural and neural-based methods, where the former category further distinguishes between entity-centric and path-based methods.
2. This survey aims to provide a comprehensive review of recommender systems for the news domain which use knowledge bases as external sources of information. For each category of models, we provide a detailed analysis of the representative models, including relevant comparisons and descriptions of the algorithms, as well as of the evaluation methodologies used.
3. We examine the limitations of existing models and open issues in the field of knowledge-aware news recommender systems, and we identify eight potential future research directions in terms of comparability of evaluations, scalability of systems, explainability and fairness of results, multilingual and multi-modal news recommenders, multi-task learning for recommendation, sequential and timely recommendations, and changing user preferences.
The rest of the article is structured as follows. Section 2 introduces recommender systems and outlines challenges specific to the news domain, while Section 3 outlines the methodology used in this survey, including the search strategy, the sources, the inclusion and exclusion criteria, as well as the study execution process. Section 4 covers related work in news and knowledge-aware recommender systems. Section 5 introduces and defines commonly used notations and concepts, and analyses different aspects of knowledge-aware news recommenders. Section 6 classifies and discusses knowledge-aware news recommender systems, whereas Section 7 investigates various evaluation approaches adopted by the different models. Section 8 discusses open issues identified in the field. We close with a short summary in Section 9.
2.Challenges in news recommendation
Recommender systems consist of techniques that filter information and generate recommendations of items deemed potentially interesting for users, based on their preferences and past behavior, in order to help individuals overcome information overload [136]. User’s preferences are learned using either explicit (e.g. ratings) or implicit (e.g. browsing history) feedback [79]. Recommender systems are generally categorized into collaborative filtering, content-based, and hybrid methods, based on the underlying algorithm. Collaborative filtering systems recommend items liked in the past by users with similar preferences to the current user [1]. In content-based algorithms, the recommendations depend only on the user’s past ratings of items, meaning that the suggested items will have similar characteristics to the ones preferred in the past by the current user [1]. Hybrid models combine one or more types of recommendation approaches to alleviate the weaknesses of a single technique, such as the cold-start problem (which refers to the difficulty in the computation of the recommendations for new items, without ratings, or new users, without a profile) or the over-specialization issue (i.e. the lack of diversity and serendipity in results) [18].
The unique characteristics of news not only distinguish them from items in domains such as online retail, movies, music, or tourism, where recommender systems have already proven successful, but also impede the straightforward application of conventional recommendation algorithms to the task of news recommendation. A large quantity of news is published every day, with articles being continuously updated. Such a large volume of data, spread over short periods of time, combined with the unstructured format of news articles, requires more complex analyses and heavier computations [94]. In addition, the news is characterized by short shelf lives and high item churn, as their relevance highly depends on the recency of articles, since users prefer reading about the latest events that took place [39,94]. A topic’s popularity also significantly influences the importance of an article, as stories can become quickly outdated and lose relevance when they are superseded by “breaking news” [84]. For example, while readers might be concerned with news about the elections in a country for multiple days or even weeks, they will be less likely to be interested in the results of a tennis match a week after a tournament has finished.
Furthermore, the user’s interests evolve over time as individuals display both short-term and long-term preferences. On the one hand, individuals display long-term interests in certain topics, motivated by their socio-economic and personal background, such as a user being interested in climate change for several years [3,67]. On the other hand, highly popular news might affect a user’s short-term interest, which changes more rapidly, within a short time span [3]. For example, a user might read several news articles related to GameStops’s short squeeze after browsing the “latest news” section of a website that announced that Robinhood has limited the buying and trading of GameStop stocks.
In addition to the previously described challenges, in the news domain, users are usually not required to sign in and create profiles in order to read articles.
Another related challenge is that the users rarely provide explicit feedback in terms of likes and ratings, and, unlike for, e.g., online retail, there is no difference between looking at an item and buying an item. In turn, this consumption behavior means that their profiles are either limited to a single session or tracked through browser cookies, and that feedback is gathered implicitly by analyzing the clicks stored in logs [43,44]. Overall, these characteristics of users in the news domain pose an additional challenge for creating an accurate user profile for the recommendation algorithms. Additionally, the lack of feedback on news articles and the small amount of data available for user profiling further amplifies the cold-start and data sparsity problems of recommender systems [84,120].
Furthermore, users often read multiple news stories in a sequence [132]. Although sequential consumption is also characteristic of music items, the major difference lies in the fact that in the news domain readers do not want items to be repeated multiple times in a row, as may be the case with songs. Instead, they prefer being recommended either updates on ongoing stories, or completely different articles [132].
News articles often describe events that occur in the world, which can be represented in terms of named entities that indicate what, when, where the event happened, as well as who was involved [94].
Additionally, news recommendations can also be subjected to over-specialization issues as users are being suggested articles semantically similar to the ones already read, but published in different sources and written using terms that are related through semantic relations, such as synonymy or antonymy [95,120]. In turn, over-specialized news suggestions can reduce the diversity and novelty of the content being shown to the readers, by decreasing both their exposure to diversified information from various sources, as well as their likelihood of discovering new content that is not highly similar or related to the previously consumed articles [95]. Over time, the over-personalization of news recommenders might trap users into filter bubbles, namely states in which the recommended articles are concentrated only on a certain standpoint, thus narrowing the readers’ perspective and reducing their freedom of choice regarding the news content they consume [123].
Another significant challenge for the news domain is the existence of fake news, namely fabricated articles that mimic true news media content, but whose information lacks credibility and accuracy, and aims to propagate misinformation [89]. In the context of news recommendation, this can be represented as a second dimension, namely trustworthiness, which is orthogonal to the actual recommendation fit [68], and which does not exist in other fields, such as movie or music recommendation. By working with large volumes of data whose credibility has not been checked, news recommendation algorithms can contribute to the spread of fake content from unreliable sources [113].
3.Methodology
As aforementioned, this survey aims to provide a comprehensive review of knowledge-aware news recommender systems. The following subsections will describe the methodology used for conducting the study. More specifically, we firstly present our search strategy, including the platforms and queries used to retrieve relevant publications. Afterwards, we discuss the criteria for including and excluding papers from our study, followed by the description of the selection process.
3.1.Search strategy
The search strategy of our survey consists in defining a set of queries for retrieving relevant publications from a list of sources. The results are then de-duplicated, as explained in the following paragraphs.
3.1.1.Search queries
We defined two queries, targeting the task of (Q1) news recommendation and the usage of (Q2) external knowledge, in order to collect relevant literature. Table 1 illustrates the search strings used for each of the two queries. Keywords meant to capture (Q2) external knowledge include multiple terms referring to widely used sources of knowledge, such as knowledge graphs or ontologies. As such, the results of query (Q2) are given by the union of the results of the corresponding search strings. Since we are interested only in news recommender systems that use a form of external knowledge, the final query used in the publications’ search process represents the intersection of queries (Q1) and (Q2).
Table 1
Search strings used in the search process
| Query | Search strings |
| (Q1) news recommendation | news recommend* |
| (Q2) external knowledge | knowledge base*, knowledge graph*, ontolog*, linked data*, semantic* |
3.1.2.Sources
The following bibliographic databases and archives constitute the sources used for the literature search: (i) DBLP11 (ii) ACM Digital Library22 (iii) IEEE Xplore33 (iv) Science Direct44 (v) Springer Link55 (vi) Web of Science66
3.1.3.De-duplication
The results collected from the previously specified sources are then merged and de-duplicated in a threefold process. Firstly, for all the publications retrieved during the keyword-based search, we gather the associated bibtex files produced by each of the digital libraries and store them using the Zotero77 bibliographic tool, which also performs automatic detection of duplicates based on the papers’ metadata. Secondly, we serialize as a spreadsheet the retrieved publications and their metadata, including title, DOI, abstract, authors, publication venue, and date. Lastly, we use the spreadsheet to perform manual de-duplication of the papers which could not be detected by the bibliographic tool due to large differences in their metadata, such as the publication venue which can be reported by some digital libraries as the conference venue and referred to by others as Lecture Notes in Computer Science (LNCS). The manually de-duplicated results of the keyword-based search constitute the final list of papers used for selecting the relevant literature in the next step.
Table 2
Selection inclusion and exclusion criteria
| Criteria | Inclusion Criteria (IC) | Exclusion Criteria (EC) | |
| C1 | Publication date | The paper is published between 2008 and 2020. | The paper is published before 2008 or after 2020. |
| C2 | Language | The paper is written in English. | The paper is written in a language different than English. |
| C3 | Publication type | The paper has been peer reviewed (e.g. conference or workshop proceedings, journal paper, book chapter). | The paper has not been peer reviewed (e.g. theses, books, technical reports, (extended) abstracts, talks, presentations, tutorials). |
| The paper is a primary study. | The paper is a secondary study (e.g. systematic literature review, survey). | ||
| C4 | Accessibility | The paper’s content can be accessed from a technical university (e.g. University of Mannheim) without additional payment. | The paper’s content cannot be accessed from a technical university (e.g. University of Mannheim) without additional payment. |
| C5 | Duplicate | If the same system and results are presented in multiple publications of the same study (e.g. conference and journal paper), the most recent version of the study will be included. | Studies for which a newer or more complete version exists. |
| C6 | Recommender system scope | The paper presents a recommendation system applied only in the news domain, or in multiple domains, including the news one. | The paper presents a recommendation system which is not applied in the news domain. |
| The paper presents a system or algorithm mainly aimed at item recommendation. | The paper presents a system or algorithm which is not mainly aimed at item recommendation (e.g. an algorithm for improving the diversity of recommendations generated by another system). | ||
| C7 | Use of external knowledge | The paper presents a system that uses external knowledge from a knowledge base. | The paper presents a system that does not use external knowledge from a knowledge base. |
| C8 | Interaction of Recommendation Model and External Knowledge Source | The external knowledge source is used to enhance the performance and accuracy of the news recommender system. | The external knowledge source and recommender system do not jointly target news recommendation (e.g. knowledge graph construction, where the new graph is evaluated on the downstream task of recommendation using an existing recommender system). |
| C9 | Recommender system evaluation | The paper presents a recommender system whose performance is evaluated on the task of news recommendation. | The paper only describes the theoretical idea of a recommender system or its implementation, but lacks an evaluation of the proposed system on the task of news recommendation. |
3.2.Selection strategy
The publications retrieved during the keyword-based search need to be further filtered in order to eliminate false positives, which are irrelevant for the current survey. Consequently, a pre-defined set of inclusion criteria (Section 3.2.1) are applied to the retrieved papers in two stages, as described in Section 3.2.2.
3.2.1.Selection criteria
The list of inclusion criteria displayed in Table 2 was developed based on the goals of the survey in order to filter out irrelevant publications. Each criterion is composed of both an inclusion criterion (IC) and an exclusion criterion (EC). A paper needs to fulfill all inclusion criteria to be selected for the study.
3.2.2.Selection process
The study selection process is composed of two phases.88 Firstly, relevant papers are pre-filtered based on their metadata. More specifically, the validity of criteria C1-C4 is assessed by examining the publications’ language, publishing year, venue, type, keywords, title and abstract. The validity of the remaining criteria is also checked if the information contained in the metadata allows it. Papers not fulfilling all of these criteria are excluded from the rest of the study. Papers whose relevance cannot be determined solely from the metadata will be kept until the next stage of the selection process. In the second phase, the fulfillment of criteria C5-C9 is checked using the complete content of the pre-filtered publications. The papers meeting all the requirements of this phase will be included in the final set of publications for the survey. Table 3 shows the number of papers remaining after different stages of the selection process.
Table 3
Number of papers in different phases of the selection process
| Phase | Number of remaining papers |
| Keyword-based search | 717 |
| De-duplication | 681 |
| Pre-filtering on metadata | 64 |
| Filtering on content | 40 |
4.Related work
This section gives an overview of surveys published in the areas of news recommendation and knowledge-aware recommender systems.
4.1.News recommender systems
Several surveys on news recommender systems and corresponding issues have been conducted. A comparison and evaluation of content-based news recommenders are performed in [11]. Borges and Lorena [14] first provide a high-level overview of recommender systems in general, including similarity measures and evaluation metrics, followed by an in-depth analysis of six models applied in the news domain. A more general overview and comparison of the mechanisms and algorithms used by news recommendation approaches, as well as corresponding strengths and weaknesses, is provided by Dwivedi and Arya [47].
Özgöbek et al. [120] identify the challenges specific to the news domain and discuss twelve recommendation models according to the targeted problems, without considering evaluation approaches. In contrast to these studies, Karimi et al. [84] provide a comprehensive review of news recommender systems, not only by taking into account a large number of challenges and algorithmic approaches proposed as a solution, but also by discussing approaches and datasets used in evaluating such systems, as well as proposing future research directions from the perspectives of algorithms and data, and the aspect of evaluation methodologies.
Li et al. [94] review issues characterizing the field of personalized news recommendation and investigate existing approaches from the perspectives of data scalability, user profiling, as well as news selection and ranking. Additionally, the authors conduct an empirical study on a collection of news articles gathered from two news websites in order to examine the influence of different methods of news clustering, user profiling, and feature representation on personalized news recommendation. More recently, Li and Wang [95] analyzed state-of-the-art technologies proposed for personalized news recommendation, by classifying them according to seven addressed news characteristics, namely data sparsity, cold-start, rich contextual information, social information, popularity effect, massive data processing, and privacy problems. Furthermore, they discuss the advantages and disadvantages of different kinds of data used in personalized news recommendation, as well as open issues in the field [95].
In comparison to the previous general studies, Harandi and Gulla [67] investigate and categorize approaches used for user profiling in news recommendation according to the problems addressed and the types of features used. Additionally, Qin and Lu [129] survey feature-based news recommendation techniques, which they categorize into location-based, time-based (i.e. further classified into real-time and session-based), and event-based methods.
Lastly, Feng et al. [52] conduct a systematic literature review of research published in the area of news recommendation in the past two decades. They firstly classify and discuss challenges from this domain according to the three main types of recommendation techniques. Various recommendation frameworks are then categorized according to application domain, such as social media-based, semantics-based, and mobile-based systems. Even though Feng et al. [52] briefly review a small number of semantic-based recommenders, their analysis is limited to older models, and does not include any of the newer approaches of the past five years. Furthermore, the authors briefly examine evaluation approaches and datasets used, before discussing which of the numerous challenges of news recommendation have been addressed by the surveyed recommenders [52].
Although these surveys provide comprehensive overviews of news recommendation methods, domain-specific challenges, and evaluation methodologies, they do not discuss knowledge-aware models or the latest state-of-the-art recommendation methods. In contrast, our survey focuses solely on news recommender systems that incorporate external knowledge to enhance the recommendations and to overcome the limitations of conventional recommendation techniques.
4.2.Knowledge-aware recommender systems
Knowledge graphs, a type of directed heterogeneous networks, describe real-world entities (represented as nodes) and multiple kinds of relations between them (represented as edges), either spanning multiple domains (e.g. Freebase [12], DBpedia [92], YAGO [151], Wikidata [167], Microsoft Satori [10]) or focusing on a particular field (e.g. Bio2RDF [6]) [49,126]. In addition, such graphs can capture higher-order relations connecting entities with several related attributes [66].
This strong representation ability of knowledge graphs has attracted the attention of the research community working on developing and improving recommender systems for several reasons. Firstly, using knowledge graphs as side information in recommendation models can help diminish common limitations, such as data sparsity and the cold-start problem [66]. Secondly, the precision of recommendations can be improved by extracting latent semantic connections between items, while the diversity of results can be increased by extending the user’s preferences taking into account the variety of relations between items encoded in a knowledge graph [59,183]. Another advantage of using knowledge graphs as background information is improving the explainability of recommendations, to ensure trustworthy recommendation systems, by considering the connections between a user’s previously liked items and the generated suggestions, represented as paths in the knowledge graph [183].
Guo et al. [66] provide a detailed review and analysis of knowledge graph-based recommender systems, which are classified into three categories, according to the strategy employed for utilizing the knowledge graph, namely embedding-based, path-based and unified methods. In addition to comparing the algorithms used by the three types of methods, the authors also analyze how knowledge graphs are used to create explainable recommendations. Lastly, the survey clusters relevant works according to their application and introduces the datasets commonly used for evaluation in each category [66].
Recent advancements in deep learning techniques for graph data, in the form of Graph Neural Networks (GNN) [183,196], have given rise to new knowledge-aware, deep recommender systems. Gao et al. [59] are the first to provide a comprehensive overview of Graph Neural Network-based Knowledge-Aware Deep Recommender (GNN-KADR) systems, in which they analyze recommendation techniques, discuss how challenges such as scalability or personalization are addressed, and briefly summarize the domain-specific datasets and metrics used for evaluation, before suggesting a number of directions for future research.
Gao et al. [59] categorize GNN-KADRs depending on the type of graph neural network components used for recommendation. More specifically, graph neural networks are comprised of an aggregator, that combines the feature information of a node’s neighborhood to obtain the context representation, and an updater, which uses this contextual information together with the input information for a given graph node in order to compute its new embedding. According to Gao et al. [59], aggregators are divided into relation-unaware (i.e. the relation information between nodes is not encoded in the context representation) and relation-aware aggregators (i.e. the information contained in different relations is considered in the context representation). The latter category is further split into relation-aware subgraph aggregator and relation-aware attentive aggregator, depending on how the relations in the knowledge graph are modeled in the framework [59]. The first subcategory creates multiple subgraphs for each relation type found in a node’s neighborhood graph, while the second encodes the semantic information contained in the edges of the knowledge graph using weights which measure how related different knowledge triples are to the target node [59]. Similarly, updaters are also categorized into three clusters, namely context-only updaters (i.e. only the node’s context representation is used to produce its new embedding), single-interaction updaters (i.e. both the target node’s current embedding, as well as its context representation are used to obtain its updated representation), and multi-interaction updaters (i.e. different binary operators combine multiple single-interaction updaters), where the first two groups of updaters are more often encountered [59].
GNN-based recommender systems are investigated also by Wu et al. [183], who classify the recommendation models based on whether the models consider the item’s ordering (i.e. general vs. sequential methods) and on the type of information used (i.e. without side information, social network-enhanced, and knowledge graph-enhanced). According to the proposed taxonomy of Wu et al. [183], knowledge-aware models can be found only in the group of general recommender systems. In this category, four representative recommendation frameworks are examined from the aspects of graph simplification, multi-relation propagation, and user integration.
The research commentary of Sun et al. [155] consists of an extensive, systematic survey of recent advancements in recommender systems that use side information. The models, mostly hybrid techniques, are analyzed from two perspectives. On the one hand, Sun et al. [155] categorize the models according to the evolution of fundamental methodological approaches into memory-based and model-based frameworks, where the latter category is further split into latent factor models, representation learning models and deep learning models. On the other hand, the recommender systems are classified based on the evolution of side information used for recommendation, into models using structural data and models using non-structural data. The first group includes information in the form of flat features, network features, feature hierarchies, and knowledge graphs, whereas the second consists of text, image, and video features [155].
In the surveys discussed above, knowledge-aware news recommender systems are rarely analyzed. In comparison to these works, the current survey focuses on the investigation of approaches for injecting external knowledge only into the news recommendation model. To this end, it provides a categorization and an extensive overview of the knowledge-aware recommender systems developed either for or evaluated also in the news domain.
5.Definitions and categorization
This section firstly introduces and defines commonly used concepts and notations. Afterwards, it provides an overview of knowledge-aware news recommender systems according to multiple criteria.
5.1.Definitions
Firstly, a minimal set of concepts and notations referred to in the rest of the article are defined. Bold uppercase characters denote matrices, while bold lowercase characters generally indicate vectors. The notations used throughout this article are illustrated in Table 4, unless specified otherwise.
Table 4
Commonly used notations
| Notations | Descriptions |
| Set size | |
| ⊙ | Element-wise product |
| ⊕ | Vector concatenation |
| ∗ | Convolution operation |
| Hyperbolic tangent function | |
| Nonlinear transformation function | |
| Transpose of matrix X | |
| A knowledge graph | |
| Concept i in the ontology | |
| or knowledge graph | |
| Entity i in | |
| Neighbours of entity | |
| k | Dimension of knowledge graph embedding |
| Embedding of entity | |
| Embedding of relation r in | |
| Profile of user i | |
| Profile of item j | |
| Set of users | |
| Set of items | |
| M | The number of users in |
| N | The number of items in |
| User u’s probability of interacting with item v | |
| d | Dimension of a feature vector |
| Feature vector of user | |
| Feature vector of item | |
| Trainable weight matrices and vectors | |
| Trainable bias vectors |
Definition 1.
An ontology is defined as a set of k ontology concepts [78]:
In the recent years, knowledge graphs comprising a large number of instances have been developed and utilized also in news recommender systems.
Definition 2.
A knowledge graph (KG)
In the scope of this paper, we consider concepts in knowledge graphs
Definition 3.
The semantic neighborhood of a concept
5.2.Categorization of knowledge-aware news recommender systems
Knowledge-aware news recommendation models can be investigated according to multiple criteria, ranging from the used knowledge resource to target function types or addressed challenges.
5.2.1.Types of recommendation techniques
News recommendation systems generally adopt one of the three main techniques for predicting whether a user will interact with a certain article, namely content-based, collaborative filtering, and hybrid. However, content-based approaches are the most widely used in the field of news recommendation [84].
5.2.2.Knowledge base
The knowledge resources used by knowledge-aware recommender systems can be grouped into domain ontologies and knowledge graphs. In the remainder of the paper, these will be referred to as knowledge bases (KB), if the type of resource is not explicitly specified. The former category can be further split into self-constructed ontologies – built either from combining smaller domain ontologies or subsets of large knowledge bases (e.g. DBpedia [92], Hudong encyclopedia [177]) or directly from news articles (i.e. financial domain ontology using information from Yahoo! Finance [78]) – and controlled vocabularies used in the news domain, such as the IPTC News Codes99 [160].
In the latter category, one can distinguish between open source and commercial knowledge graphs. In the first subgroup, cross-domain knowledge graphs such as Wikidata, DBpedia, and Freebase are widely used in news recommender systems. Freebase [12] was initially launched by Metaweb in 2007, and later acquired by Google in 2010, before being shut down in 2015 [126]. The latest version of Freebase, available at Google’s Data Dumps1010 has been estimated to contain 1.9 billion triples [63]. Wikidata [167], a collaboratively edited knowledge graph, containing several language editions of Wikipedia, as well as data previously contained in Freebase [126], consists of 92 million items1111 and over 1174 million statements.1212 DBpedia [92] is a knowledge graph built by extracting structured data from various language versions of Wikipedia, and contains in its most recent and largest version, DBpedia Largest Diamond, 220 million entities and 1.45 billion triples.1313
WordNet [111], a large English lexicon containing nouns, verbs, adjectives, and adverbs grouped into synsets (i.e. sets of synonyms), which are further interconnected via semantic relations of antonymy, hyponymy, meronymy, troponomy, or entailment, is often used in knowledge-aware news recommender systems for word sense disambiguation. More specifically, each word in WordNet is associated with a set of senses, which denote the set of possible meanings that the word might have. For example, the noun “Jupiter” can refer to either the planet in the solar system or the supreme god of the Romans. WordNet 3.01414 contains 117,659 synsets and 206,941 word-sense pairs.
In the subgroup of commercial knowledge bases, Satori [10], the knowledge graph proposed by Microsoft, is the most often used one, especially by recent deep learning-based news recommender systems. Although very little information about the data contained in Satori is publicly available, it was estimated to contain in 2012 approximately 300 million entities and 800 million relations [126].
5.2.3.Structure of knowledge base
News recommendation models use knowledge bases by exploiting their different structures in order to extract either semantic, structural, or both types of information. A few knowledge-aware news recommender systems exploit only the semantic information contained in a knowledge graph or ontology, by extracting concepts or entities that appear in a news article, which will be denoted as concepts/entities only models for the rest of this article. A larger share of models however enriches the basic set of knowledge entities by expanding it with the neighborhoods of extracted entities in the knowledge graph and by considering the paths and relationships between entities (denoted as entities + paths). Another method for enhancing the set of concepts or entities extracted from a knowledge base is by taking into account its structure, namely the different types of relations between nodes in an ontology, such as synonymy or hyponymy relationships in semantic lexicons, or the distances between concepts, entities or classes (denoted as concepts + KB structure or entities + KB structure). Differently from these categories of models, the newer deep-learning-based recommendation techniques exploit simultaneously both the semantic and the structural information encoded in knowledge graphs, by means of knowledge graph embeddings (denoted as entities + KG structure).
5.2.4.Target function
Two main target functions can be distinguished in news recommendation models, namely click-through rate (CTR) prediction and item ranking. Models classified in the first group aim to predict the probability that the user will click on the target article, whereas methods in the second group recommend the top N most similar articles to the articles previously read by the user.
5.2.5.Addressed challenge
In addition to enhancing the accuracy of recommendations, knowledge-aware news recommender systems aim to address different challenges of the news domain or limitations posed by conventional recommendation techniques. Several news articles, written in different manners, using semantically related terms, can describe the same piece of news, and numerous words have different meanings depending on the context in which they are used. While humans can easily distinguish ambiguous words, or words connected via certain semantic relations, such as synonyms, this constitutes a challenge for recommendation models using text representations. Knowledge-aware recommender systems propose to remove such ambiguity from text by representing an article using only disambiguated knowledge entities or concepts from a controlled vocabulary, instead of all the terms. In turn, this leads to faster computations, since the model is required to consider a limited number of concepts or entities, which is significantly smaller than the total number of words contained in an article. Moreover, the semantic meaning of news, as well as the semantic relatedness of concepts (i.e. news describing similar or related concepts might indicate different interests of a user) can be captured by further considering the relations between the different concepts found in an article.
News articles contain a large number of named entities, used to denote information regarding the events described, such as the location, actors involved, time, or what the event refers to. However, named entities are not taken into account in traditional text-based recommendation models. In contrast, knowledge-aware techniques handle named entities by extracting them from the text and enriching them with external information encoded in knowledge graphs. Furthermore, using external information for recommendation can help overcome the data sparsity and cold-start problems, as articles can be connected using relations in the knowledge graph between the entities extracted from text, such that new items without user feedback can also be included in the recommendations.
Moreover, injecting external knowledge into the recommendation model has three additional benefits. Firstly, it extends text-level information with common sense knowledge which is encoded in knowledge graphs but cannot be extracted only from an article’s text. For example, a user reading the titles of the news articles in Fig. 1 will probably know that Elon Musk and Robinhood were participants in the GameStop short squeeze event that affected GameStop, or that the New York Stock Exchange is located on Wall Street. However, a text-based recommendation model does not possess such common knowledge information. Additionally, using external information also helps the model discover latent knowledge-level connections between the news, such as the fact that the two snippets in the example from Fig. 1 are connected, although they do not appear related when considering only the words in their titles. Lastly, exploiting the knowledge-level and semantic connections between news can improve the diversity of recommendations, as the model learns to avoid recommending articles that are too semantically similar, even if they are published in different sources and have different writing styles.
![Illustration of a knowledge graph-enhanced news recommender system (reproduced from [170]).](https://ip.ios.semcs.net:443/media/sw/2024/15-1/sw-15-1-sw222991/sw-15-sw222991-g001.jpg)
6.Knowledge-aware news recommendation models
Table 5
Overview of knowledge-aware news recommendation approaches. We present the model’s category, abbreviated name, publishing year, type of recommendation technique, external knowledge resource and its used structures, target function, and challenges addressed by injecting external knowledge in the recommendation model. “Accuracy” is not explicitly mentioned as a challenge, as all discussed models aim to improve recommendations on this measure. The following abbreviations are used: NNECM = Non-Neural, Entity-Centric Methods, NNPM = Non-Neural, Path-Based Methods, NM = Neural Methods, RS = Recommender System, CB = Content-Based, CF = Collaborative Filtering, H = Hybrid, DO = Domain Ontology
| Category | Model | Year | RS type | KB | KB structure | Target function | Addressed challenge |
| NNECM | Semantic context-aware recommendation [21,23] | 2008 | H | DO (IPTC + Wikipedia) | entities + paths | Item ranking | Capture semantic relatedness of concepts |
| Social tags enriched recommendations [24] | 2008 | CB | Wordnet, Wikipedia DO (IPTC + Wikipedia) | entities + paths | Item ranking | Data sparsity, cold-start problem | |
| Semantic relatedness [60] | 2009 | CB | DO | entities + paths | Item ranking | Capture semantic relatedness of concepts | |
| RSR [78] | 2010 | CB | DO | entities + paths | Item ranking | Capture semantic meaning, faster computations, eliminate ambiguity | |
| CF-IDF [64] | 2011 | CB | DO | concepts/entities only | Item ranking | – | |
| Hybrid context-aware recommendation [23] | 2011 | H | DO (IPTC + Wikipedia) | entities + paths | Item ranking | Data sparsity, cold-start problem | |
| RSR 2 [55] | 2012 | CB | DO | entities + paths | Item ranking | Capture semantic meaning, faster computations, eliminate ambiguity | |
| SF-IDF [26] | 2012 | CB | WordNet | concepts/entities only | Item ranking | Capture semantic meaning | |
| SF-IDF+ [112] | 2013 | CB | WordNet | entities + paths | Item ranking | Capture semantic relationships between synsets | |
| Bing-SF-IDF [71] | 2013 | CB | WordNet | entities + paths | Item ranking | Handle knowledge entities | |
| Bing-SF-IDF+ [28] | 2015 | CB | WordNet | entities + paths | Item ranking | Capture semantic meaning | |
| Agarwal and Singhal [2] | 2014 | CB | DO (IPTC) | concepyts/entities only | Item ranking | – | |
| OF-IDF [133] | 2015 | CB | DO | entities + paths | Item ranking | Eliminate ambiguity | |
| CF-IDF+ [40] | 2018 | CB | DO | entities + paths | Item ranking | Handle relationship types between concepts | |
| Bing-CF-IDF+ [17] | 2019 | CB | DO | entities + paths | Item ranking | Handle knowledge entities | |
| Bing-CSF-IDF+ [161] | 2020 | CB | DO, WordNet | entities + paths | Item ranking | Capture semantic meaning, handle knowledge entities |
Table 5
(Continued)
| Category | Model | Year | RS type | KB | KB structure | Target function | Addressed challenge |
| NNPM | ePaper [105] | 2008 | CB | IPTC News Codes | concepts + KB structure | Item ranking | – |
| Magellan [45] | 2011 | CB | DO | concepts + KB structure | Item ranking | – | |
| SS [26] | 2012 | CB | WordNet | concepts + KB structure | Item ranking | Capture semantic meaning | |
| BingSS [27] | 2013 | CB | WordNet | concepts + KB structure | Item ranking | Handle knowledge entities | |
| OBSM [130] | 2013 | CB | Ontologies based on DBpedia and Hudong | concepts + KB structure | Item ranking | Eliminate ambiguity | |
| Kumar and Kulkarni [88] | 2013 | CB | Wikipedia | concepts + KB structure | Item ranking | – | |
| Werner and Cruz [179] | 2013 | CB | DO | concepts + KB structure | Item ranking | – | |
| BKSport [117] | 2016 | H | DO | concepts + KB structure | Item ranking | Capture semantic meaning | |
| SED [83] | 2019 | CB | Freebase | entities + KB structure | Item ranking | Cold-start problem |
Table 5
(Continued)
| Category | Model | Year | RS type | KB | KB structure | Target function | Addressed challenge |
| NM | CETR [193] | 2017 | CF | Wikidata | entities + KG structure | CTR | Extend text-level information |
| Colombo-Mendoza et al. [35] | 2018 | H | DO | entities + KG structure | Item ranking | – | |
| DKN [170] | 2018 | CB | Microsoft Satori | entities + KG structure | CTR | Extract knowledge-level news connections, extend text-level information with common sense | |
| Gao et al. [58] | 2018 | CB | KG | entities + KG structure | CTR | Extract knowledge-level news connections | |
| RippleNet [168] | 2018 | CB | Microsoft Satori | entities + KG structure | CTR | Data sparsity, cold-start problem | |
| RippleNet-agg [169] | 2019 | CB | Microsoft Satori | entities + KG structure | CTR | Data sparsity, cold-start problem | |
| MKR [172] | 2019 | CB | Microsoft Satori | entities + KG structure | CTR Item ranking | Data sparsity, cold-start problem | |
| IGNN [128] | 2019 | CB | Wikipedia | entities + KG structure | CTR | Mine high-order connectivity of users and news | |
| Saskr [33] | 2019 | CB | News-specific KG | entities + KG structure | CTR | Extract knowledge-level news connections, diversity, cold-start problem, handle knowledge entities | |
| KRED [100] | 2020 | CB | Microsoft Satori | entities + KG structure | CTR | Handle knowledge entities | |
| TEKGR [91] | 2020 | CB | Microsoft Satori | entities + KG structure | CTR | Handle knowledge entities, capture topical relatedness between news | |
| KCNR [176] | 2020 | CB | Douban | entities + KG structure | CTR | Handle knowledge and content factors | |
| KG-RWSNM [188] | 2020 | H | Wikidata | entities + KG structure | CTR | Extract deep semantic features from news | |
| MUKG [152] | 2020 | CB | Microsoft Satori | entities + KG structure | CTR | Data sparsity, cold-start problem Mine high-order interactions between item and entities | |
| CAGE [145] | 2020 | CB | Wikidata | entities + KG structure | CTR | Include semantic-level structural information between articles in session-based recommendation |
Knowledge-aware news recommendation systems can be classified into different categories based on how external knowledge is injected in the recommendation model, on the used structures of the knowledge base, as well on how latent representations of users and articles are computed. Our proposed taxonomy, illustrated in Fig. 2, distinguishes between the methods based on how the latent representations are generated from entities and/or concepts in a knowledge base, i.e., Non-Neural Methods and methods based on neural networks (Section 6.3). We further split Non-Neural Methods into Entity-Centric (Section 6.1) and Path-Based (Section 6.2), depending on whether the recommendation approach defines the similarity between users and news articles based on distances between the concepts or entities from the knowledge base. To support readers reviewing the literature, the surveyed models are listed in Table 5 according to the aforementioned criteria.
Fig. 2.
The categorization of knowledge-aware news recommender systems. We divide existing frameworks into three categories, based firstly on how latent representations of user and news article profiles are generated, and secondly, on the type of similarity measure used.
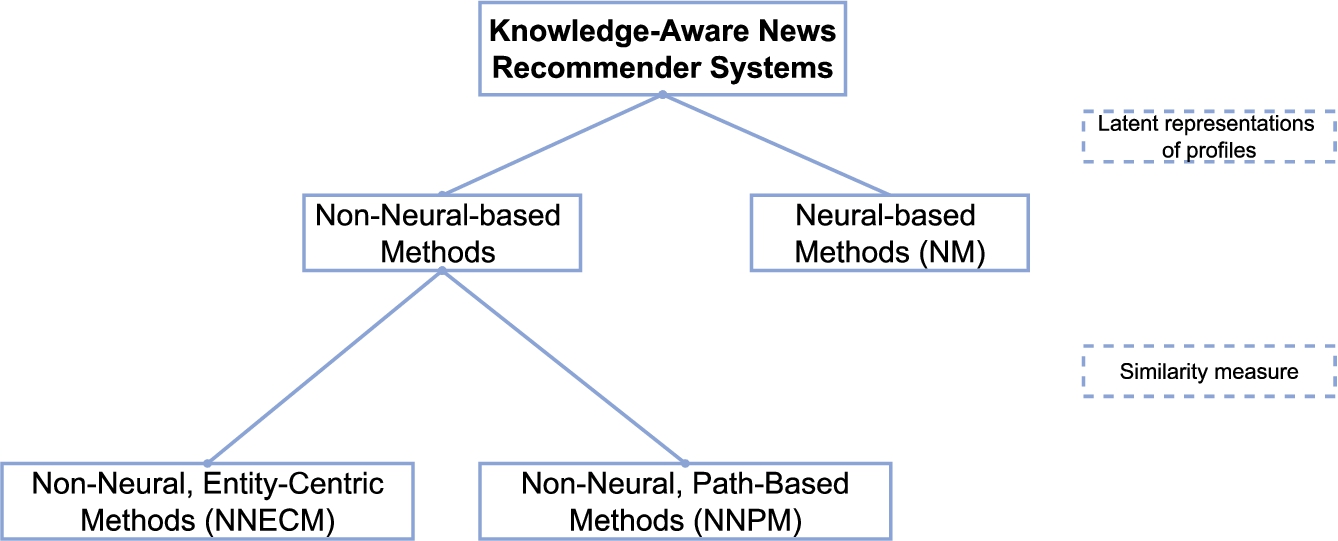
Factorization models constitute some of the state-of-the-art recommendation techniques in various fields [9,87,147], and have already been adopted in the area of news recommendation [131,185]. Moreover, latent factor models have also been adapted to support knowledge graphs in hybrid knowledge-aware recommendation engines [30,146,154,191]. Nonetheless, as it can be observed from Table 5, factorization models are rarely used by knowledge-aware news recommender systems. More specifically, only one model from the 39 surveyed ones uses matrix factorization (see Section 6.3). Hence, we have not added a dedicated subcategory for such methods to our taxonomy.
Recommenders based on factorization models are collaborative filtering-based approaches. However, this recommendation technique is the least adopted one in the domain of news recommendation [132]. Raza et al. [132] have shown that content-based methods are the most widely used recommendation techniques in this field, followed by hybrid approaches. This phenomenon can be explained by the challenges faced by recommender systems in the news domain, explained in Section 2, such as the lack of explicit feedback (i.e. ratings), or limited amount of data available for user profiling. In turn, this affects collaborative-filtering approaches such as factorization models, which rely on a large amount of information regarding the user-item interactions in order to generate accurate recommendations.
Comparison with existing taxonomies Several taxonomies have already been proposed for general knowledge-aware recommender systems. Gao et al. [59] categorize GNN-based knowledge-aware deep recommender systems based on the different types of the two basic components of the graph embedding module, namely the aggregator and the updater. In comparison to the work of Gao et al. [59], in the current survey, we neither limit our analysis to knowledge-aware deep news recommenders, nor to those based necessarily on GNNs. Hence, there is no overlap between the two taxonomies.
Another categorization of knowledge graph-based recommender systems divides models into different categories based on how they utilize the knowledge graph information, namely into embedding-based methods, path-based methods, and unified methods [66]. Embedding-based methods encode the knowledge graph information by means of knowledge graph embeddings and directly use it to enhance the representations of users or items. This category is further split into models that construct knowledge graphs of items and their relations, extracted from a dataset or external knowledge base, and those that build user-item graphs, in which the users, items, and their attributes form the graph’s nodes, while user-related and attribute-related relations constitute the edges [66]. In our survey, this category overlaps with the neural-based models, which use a form of knowledge graph embedding, as it will be explained in Section 6.3. However, we do not further differentiate between neural-based recommenders depending on how the underlying knowledge graph is created.
Guo et al.’s [66] second category of path-based methods includes those recommenders that leverage connectivity patterns of entities in the user-item graph. In this context, this category has similarities with our proposed non-neural, path-based methods. However, in our case, the connectivity patterns are exploited from any source of structured knowledge base and are not restricted to user-item graphs.
The third category proposed by Guo et al. [66], namely unified methods, incorporates models that combine the first two types of techniques by leveraging both the connectivity information, as well as the semantic representation of entities and relations. This class, containing the RippleNet [168] and RippleNet-agg [169] models, overlaps again with our neural-based methods due to the neural nature of latent representations used to profile items and users.
Lastly, Sun et al. [155] classify recommender systems on two dimensions. The first dimension is concerned with the recommendation technique and differentiates between memory-based methods, latent factor models, representation learning models, and deep learning models. The second dimension focuses on the type of side information used, namely structural data (i.e. flat, network, hierarchical features, and knowledge graphs) and non-structural data, in the form of text, image, and video features. According to this categorization scheme, models classified by Sun et al. [155] under deep learning methods that use knowledge graphs as side information would correspond to neural-based methods in our taxonomy.
The following subsections analyze the knowledge-aware recommender systems presented in Table 5 according to the taxonomy introduced above. For each category of models, the overall framework, as well as representative models are investigated.
6.1.Entity-centric methods (non-neural)
Recommender systems classified in this category represent the profiles of users and news articles using latent representations generated from concepts and/or entities in a knowledge base using non-neural methods. Generally, such representations are computed using a Vector Space Model [140], most often variants of the Term Frequency-Inverse Document Frequency (TF-IDF) model [139], modified to take into consideration side information from a knowledge base. The similarity between articles and the preference of a user for a candidate article are determined using different semantic or non-semantic similarity metrics.
6.1.1.Overall framework
Non-neural, entity-centric methods first create a vector representation of both the target article and the user profile, where the latter consists of the user’s reading history. Afterwards, the models compute the similarity between the two representations and recommend a list of the top N articles whose similarity scores exceed a predefined threshold. As such, the majority of techniques listed here adopt a content-based recommendation approach. We analyze these systems in terms of three differentiating factors:
– Profile representation. The representation of the items and users determines which kind of semantic information is incorporated in the model.
– Weighting scheme. Several weighting approaches are used to measure the importance of the components used to represent the news articles.
– Similarity metric. The recommendation is based on the similarity of target articles to the articles from the user’s profile, which is calculated using a variety of methods.
6.1.2.Representative models
In this subsection, we discuss 12 representative non-neural, entity-centric recommendation techniques.
Cantandor et al. [21,23] developed a semantic context-aware recommendation model which aims to contextualize the users’ interests, such that the model learns to ignore preferences that are out of focus in a particular session, and to place a higher importance on those that are in the semantic scope of the ongoing user activity. The profiles of both user and news articles are described using semantic concepts from a domain ontology, as
A personalized content retrieval approach assigns a relevance measure
Following the construction of the runtime context, Cantandor et al. [23] introduce a semantic preference spreading strategy which expands the user’s initial preferences through semantic paths towards other concepts in the ontology. This contextual activation of user preferences constitutes an approximation of conditional probabilities. According to this formulation, the probability that concept
Consequently, the semantic spreading mechanism requires weighting every semantic relation r in the ontology with a value
The context-aware personalized recommendation model computes the relevance measure of an item v for user u using the expanded profiles of the user and the article, in the following way:
The weights spreading strategy addresses both the cold-start and the data sparsity problems, whereas incorporating contextual information captures the changing utility of a news article to a user based on temporary circumstances. While this model applies to single users, Cantandor et al. [23] also employ a hybrid context-aware recommendation technique which exploits the connections between users and concepts to discover relations among users in a collaborative fashion. The goal, in this case, is to leverage partial similarities between users with similar preferences in a focused domain, but who are globally dissimilar. On a high level, the strategy is accomplished by clustering users according to layers of preferences shared among them. Hence, the user similarities depend on sub-profiles, which increase the likelihood of extracting conjunctions of rare preferences.
Semantic Communities of Interest are derived from the users’ relations at different semantic levels [23]. More specifically, each ontology concept
Cantandor et al. [23] propose two recommendation models that use the extracted latent communities of interests among users. On the one hand, model UP computes a unique ranked list of news articles based on the similarities between news and all semantic clusters, meaning that it compares a user’s interests to those of the other users and utilizes these user-user similarities to weight preferences for candidate articles. As such, the preference score of article v to user u is computed using Eq. (5):
Here
On the other hand, model UP-q generates recommendations separately for each layer by computing a ranked list for each semantic cluster. The preference between user and target article is calculated as follows:
The same context-aware and multi-facet, group-oriented hybrid recommendations are also adopted by Cantandor et al. [24] to generate social tags enriched recommendations. The authors expand the original user profiles with personal tag clouds collected from two websites (Flickr and del.icio.us). The extracted tags are incorporated into the ontological user profiles by mapping them to ontology concepts.
Concept Frequency – Inverse Document Frequency (CF-IDF) [64] constitutes a variant of the TF-IDF weighting scheme that uses concepts instead of terms in order to represent news articles. In the framework proposed by Goossen et al. [64], the profile of a user u consists of a set of q concepts from an ontology, namely
In the CF-IDF recommender, each user’s interests are represented as a vector of CF-IDF weights
The CF-IDF weights are computed similarly to TF-IDF weights. Firstly, the Concept Frequency
A major difference between the TF-IDF and CF-IDF lies in the fact that the latter considers only the ontology concepts contained in the text, instead of all the terms. Therefore, it assigns a larger value to the concepts deemed more important, and results in faster computations, as it considers a smaller amount of elements during similarity computations. In turn, this also implies that CF-IDF can assign a single representation to multi-word expressions (e.g. “Elon Musk” is one concept), compared to TF-IDF which would compute an embedding for each word individually (e.g. for “Elon” and for “Musk”). Consequently, if the concepts are disambiguated, CF-IDF can handle ambiguous terms, in contrast to TF-IDF.
The Synset Frequency – Inverse Document Frequency (SF-IDF) approach of Capelle et al. [26] modifies the TF-IDF weighting scheme to take into account the semantic meaning of terms in a text. In comparison to CF-IDF, Capelle et al. [26] represent the user’s and article’s profile as sets of WordNet synsets of the terms appearing in the news article. Mathematically, the news item’s profile is represented as:
The synsets in both profiles are weighted using SF-IDF weights, obtained from TF-IDF by replacing terms with synsets s, i.e.
However, SF-IDF yields a limited understanding of the semantics of news. Therefore, SF-IDF+ [112] additionally considers the semantic relationships between synsets in order to overcome this drawback. This is achieved by extending a set of synsets
Hence, the item’s and user’s profiles, v and u, are extended according to Eqs (13) and (14), respectively.
Furthermore, SF-IDF+ not only uses extended synsets instead of synsets, as is the case for the SF-IDF model, but also assigns different weights
A similar strategy to the one proposed in SF-IDF+ is also adopted by CF-IDF+ [40], an extension of the original CF-IDF model in which the initial set of identified concepts is expanded with related neighbors. Nonetheless, a shortcoming of the SF-IDF+ recommendation model is not being able to take into consideration named entities, which are prevalent in news articles. Thus, Capelle et al. [28] proposed Bing-SF-IDF+, a method which extends the SF-IDF+ technique with named entity similarities computed using Bing page counts. The main assumption made by the authors is that the likelihood of two entities being similar is directly proportional to the amount of times they co-occur on websites [28]. The Bing-SF-IDF+ similarity score combines two elements, namely the Bing component which measures the similarity between pairs of named entities,1515 and the SF-IDF+ component which computes the similarity between synsets.
The SF-IDF+ profiles and weights are built and calculated according to Eqs (12)-(15). For the Bing component, new user and item profiles are built using sets of named entities extracted from the text with a named entity recognizer, denoted as follows:
Subsequently, the Bing search engine is used to compute the page count
The SF-IDF+ similarity
This approach of enhancing semantics-driven recommender systems with named entity similarities using the Bing page counts are prototypical also for other models, such as Bing-SF-IDF [71], Bing-CF-IDF+ [17], or Bing-CSF-IDF+ [161].
An approach combining CF-IDF and SF-IDF, which aims to address the ambiguity problem by representing news articles using key concepts, synonyms, and synsets from a domain ontology, is represented by the OF-IDF method proposed by Ren et al. [133]. In this case, a news article is described in terms of key concepts contained in a financial domain ontology. Additionally, the lexical representation of a concept is disambiguated by enriching it with its corresponding synset retrieved from WordNet. Similar to CF-IDF, the concepts in the article’s profiles are weighted using an Ontology Frequency-Inverse Domain Frequency scheme. Thus, the article can be represented as a vector of OF-IDF weights
In Eq. (22),
In Eq. (23), the vectors
The semantic relatedness model of Getahun et al. [60] compares two articles
In comparison to item profiles of models such as CF-IDF (Eq. (8)), in Eq. (24) the total number of concepts appearing in an article’s profile is represented by the number of distinct concepts
The enclosure similarity between two concepts
The Ranked Semantic Recommendation (RSR) [78] model is based on the assumption that reading an article containing a certain concept expands the user’s knowledge not only in that particular concept, but also in the concepts related to it. This notion is captured by assigning a rank to each concept from an ontology. For example, a user reading news about a concept represented by the class instance Robinhood might also be interested in his CEO Vladimir Tenev or in the GameStop short squeeze event. Since these instances are in a direct relation to Robinhood, the ranks of all three should be increased. Similarly, if a user firstly reads an article containing instances Robinhood and Elon Musk, then accesses news about Open AI, a related concept instance to Elon Musk, but not to Robinhood, the rank of Elon Musk should be increased, while that of Robinhood should be decreased. Therefore, the rank of a concept aims to account for the user’s changing interests.
Each concept
Another assumption underlying RSR [78] is that the more articles containing concept
The final rank of every concept in the user’s extended profile, denoted
A min-max normalization is applied to the extended user profile to ensure that the ranks are in the range
The Ranked Semantic Recommendation 2 (RSR 2) [55] model improves RSR by considering, in addition to the concepts appearing in the unread news articles, also the concepts related to them. Following the previous example, this means that if a candidate news contains the concept instance Elon Musk, the model will also use related concept instances such as Open AI, SpaceX, Tesla, Inc., or Neuralink to represent the article. Thus, the original article profile is extended by the set of related concepts, namely
Another difference to RSR is that RSR2 uses different weight values to determine the concepts’ ranks. The rank of a concept in the extended article representation
6.1.3.Summary
Non-neural, entity-centric news recommendation techniques are summarized in terms of three aspects:
– Profile representation. Each model constructs two profiles, one representing the unread target article, and the other characterizing the user’s interests, as an aggregation of the articles from his reading history. CF-IDF uses concepts extracted from the news and contained in a domain ontology to represent articles. RSR and RSR2 also use ontological concepts, as well as concepts related to them in the ontology. In comparison, models such as SF-IDF or OF-IDF, use synsets of terms or concepts enriched with associated synonym sets from semantic lexicons to avoid ambiguity. Another approach, used by SF-IDF+, additionally takes into account relationships between synsets, by extending the original vector representation with concepts referred to by semantic relations characterizing the synsets from the initial profile. Lastly, Bing-SF-IDF+ further improves the technique by including named entities into the vector representations.
– Weighting scheme. The majority of models discussed in this section employ a variant of the TF-IDF weighting scheme, modified to incorporate concepts or synsets instead of terms. SF-IDF+ refines the weighting model by assigning different weights to each semantic relation connecting a concept to its semantically related synset. In addition to using SF-IDF+ weights to measure the importance of concepts in a news article, the Bing-SF-IDF+ model computes Bing similarity scores for the user and item profiles based on the page rank-based PMI co-occurrence measure of the named entity pairs contained in the two profiles. In contrast, semantic context-aware techniques use weights in the range
– Similarity metric. Cosine similarity is often employed to determine the preference of a user for an unread news article in context-aware models, as well as in models using a variant of the TF-IDF model. The latter category extends the similarity measure with the Bing similarity metric when named entities are taken into account through Bing page counts. Hybrid semantic context-aware models use a weighted combination of cluster-based cosine similarities to determine the news-user similarity. In contrast, RSR-based models compute the article relevance as the ratio of the sum of concepts ranks from the item and user profiles.
6.2.Path-based methods (non-neural)
The profiles of users and news articles in non-neural, path-based recommendation methods are represented using concepts or entities from a knowledge base. Similar to the models in the previous section, some of the recommendations approaches classified here generate latent representations of these concepts or entities using non-neural methods. However, in contrast to non-neural, entity-centric recommenders, path-based ones define the user-item and item-item similarities using metrics that take into account the distance between concepts and/or entities from the knowledge base.
6.2.1.Overall framework
The majority of methods in this category represent a news article as a set of tuples consisting of the concepts contained in an ontology and their corresponding weights. Formally, this can be written as
– Profile representation. Different kinds of semantic information can be included in the users’ and items’ representations.
– Weighting scheme. The concepts comprising the user and news profiles are weighted using different strategies to measure their importance.
– Similarity metric. The similarity between two news articles is computed using several distance measures.
6.2.2.Representative models
In the following, we investigate six representative recommendation techniques for this category.
ePaper [105,148] weighs the ontology concepts denoting the user’s interests according to the user’s implicit feedback. More specifically, the weight of a concept
Three types of partial matches between concepts were defined by Maidel et al. [105] based on hierarchical distance. A perfect match is obtained if the same concept appears in both profiles and at the same hierarchical level. For example, both the news and the user profile contain the concept ‘artificial intelligence’, found at level 1 in the ontology. However, if a concept occurs only in one of the profiles, while its parent or child is included in the other profile, a close match is reached. In this case, one can further differentiate between cases when the user’s concept (e.g. artificial intelligence) is more general than the article’s concept (e.g. deep learning), and those in which the user’s interest is more specific (e.g. user concept is graph neural networks and item concept is deep learning). Lastly, a weak match occurs if the concepts from the two profiles are two levels apart in the hierarchy, such as the user being interested in graph neural networks, whereas the article contains the concept artificial intelligence. Analogous to the previous match type, two cases are determined by the profile containing the more general concept.
A similarity score
A different approach is adopted in Magellan [45], which uses a Weighted Term Frequency scheme to determine the importance of a candidate news article to a monitored domain. Magellan extracts named entities from news to represent the articles and operates on their corresponding concepts from an ontology. According to the weighting scheme, the importance of concepts is determined by their centrality and prestige [99] in the ontology. The main assumption underlying the measure of centrality is that the more relations a concept has to other concepts, the higher is its importance in the given domain. Hence, the concept with the highest out-degree, namely the largest number of accumulative out-going connections, is considered the top-ranked individual. Subsequently, the importance of the remaining concepts depends on the distance, measured in the number of hops, and the strength of the relations
The centrality score ensures that concepts with shorter and stronger connections to the top-ranked concept will be assigned higher importance than those situated further away in the ontology or having weaker relations. The centrality weight is complemented by the prestige of a concept in the ontology, a method that ranks the concepts based on their incoming relations. The more a concept is referred to via different relations by another concept (i.e. the larger its in-degree), the higher its prestige in the ontology. Consequently, the final importance score of a concept is computed as the product of centrality and prestige (denoted as rank in Eq. (30)), weighted by a constant value α assigned to the top-ranked concept:
The final weight
Similar to SF-IDF, the Semantic Similarity (SS) recommendation model [26] represents a news item using the WordNet synsets of the terms it contains, as shown in Eqs (10) and (11). Recommendations are generated by comparing the similarity of the synsets in the unread news article to the synsets of all the articles previously read by the user. For this purpose, firstly a vector containing all combinations of synsets from the target article and the union of synsets from the user profile is constructed as follows:
Furthermore, a subset is created from V for all pairs of synsets sharing the same part-of-speech (POS):
The final similarity score of an unread article is given by the sum of all combinations’ similarity rank
The WordNet taxonomy constitutes a hierarchy of “is-a” relationships between its nodes which, in turn, constitute synsets. As such, Capelle et al. [26] propose five semantic similarity measures to calculate the similarity rank
The two remaining metrics, of Leacock and Chodorow [90]
Similar to Bing-SF-IDF+, BingSS [27] extends the semantic lexicon-driven SS recommendation model by taking into account named entities. The semantic similarity formula from Eq. (33) is modified to take into account only the set of synset pairs
Lastly, the Bing and the SS components are combined in the final BingSS similarity score using a weighted average with predefined weight α:
OBSM, the ontology-based similarity model proposed by Rao et al. [130], uses a TF-IDF weighting scheme for the concepts in the user and news profiles. The similarity between two concepts
The similarity between the profile of a target news article and user is computed in the following way [130]:
According to Eq. (44), two concepts
In contrast to the previous models, SED, the entity shortest distance over knowledge graphs algorithm proposed by Joseph and Jiang [83], defines item-item similarity as the shortest distance between the subgraphs consisting of named entities extracted from news articles. The approach is threefold [83]. Firstly, all named entities contained in every news article are extracted and linked to the corresponding nodes in a knowledge graph. Secondly, in the subgraph generation phase, each news article is represented as a subgraph containing the linked nodes from the knowledge graph associated with the previously extracted named entities. These subgraphs are expanded with outgoing relations from the L-hop neighborhood of each node discovered using a breadth-first search strategy.
The shortest distance between two entities over the knowledge graph represents the shortest path length between the corresponding nodes, mathematically denoted as
Lastly, the similarity between the two articles is computed as the pair-wise shortest distance over the union of their subgraphs [83], as shown in Eq. (46).
This method provides a symmetric average minimum row-wise distance which places higher importance on the entity pairs with the highest likelihood of co-occurrence in news article. Additionally, a weighted shortest distance between the articles could be used by weighting the edges of the subgraphs and computing the sum of all the weights of the traversed edges [83]. For the weighted SED algorithm, different weighting schemes could be used, including the relation weighting scheme, which assigns edge weights based on the number of shared neighbors of two entity nodes from an article.
6.2.3.Summary
Non-neural, path-based knowledge-aware news recommender systems are summarized from the following perspectives:
– Profile representation. Various types of representations are used to construct the profiles of users and news articles. On the one hand, ePaper, Magellan, and OBSM use ontological concepts, SS represents items and users in terms of WordNet synsets, while BingSS additionally considers named entities. On the other hand, SED represents profiles in terms of subgraphs consisting of named entities extracted from news articles.
– Weighting scheme. Concepts in the item and user profiles are weighted to encode their importance. However, there is not one unique weighting scheme employed by all the models in this category. ePaper weights concepts based on the number of user clicks on articles containing them, while OBSM uses classic TF-IDF weights. Magellan weights concepts based on their importance in an ontology computed using social network measures and their frequency in news articles. SS-based methods assign weights based on the information content of nodes or the lengths of paths between pairs of nodes in a semantic lexicon. In contrast, SED does not represent the user or item profile in terms of concept sets, but as subgraphs of named entities from a knowledge graph.
– Similarity metric. The majority of models previously discussed use a type of distance measure to directly calculate the similarity between two news articles. On the one hand, methods such as ePaper or OBSM focus on the hierarchical distance between the concepts contained in the items’ profile. The SS-based models use different functions that either take into account the information content of a node in the knowledge base, or the path lengths between nodes. On the other hand, SED views article similarity as the degree to which the subgraphs representing news articles overlap. In comparison, Magellan uses a combination of distance measure and term frequency to determine the importance of named entities from news articles and corresponding ontology concepts to a domain and to rank candidate articles accordingly.
6.3.Neural network-based methods
In recent years, the rapid advancements in the field of deep learning have also led to a paradigm shift in the domain of news recommendation. State-of-the-art knowledge-aware recommendation models combine latent representations of news articles, generated using neural networks, with external information contained in knowledge graphs, encoded by means of knowledge graph embeddings, defined below.
Definition 4.
Given a dimensionality
6.3.1.Overall framework
Frameworks classified in this category generally use a knowledge distillation process to incorporate side information in their recommendations. Firstly, named entities are extracted from news articles using a named entity recognizer. Secondly, these are connected to their corresponding nodes in a knowledge graph using an entity linking mechanism. Thirdly, one or multiple subgraphs are constructed using the linked entities, their relations, and neighbors from the knowledge graph. Afterwards, the obtained graphs are projected into a continuous, lower-dimensional space to compute a representation for their nodes and edges. Thus, these models use both the structural and semantic information encoded in knowledge graphs to represent news. Figure 3 exemplifies this process.
Fig. 3.
Illustration of the knowledge distillation process used by neural-based recommendation models (reproduced from [170]).
![Illustration of the knowledge distillation process used by neural-based recommendation models (reproduced from [170]).](https://ip.ios.semcs.net:443/media/sw/2024/15-1/sw-15-1-sw222991/sw-15-sw222991-g003.jpg)
In contrast to models from the previous categories, the neural-based recommenders we reviewed for this survey predict the probability that a user will click on a target article, namely the click-through rate. We consider several factors underlying these recommendation models:
– Recommendation model input. Usually, the input to the recommendation model consists of an unread news article and the user’s reading history. However, various elements, including textual information and knowledge entities can be combined to represent users and items.
– Knowledge graph embedding model. Several models can be used to compute node embeddings for the knowledge graph entities [38,173].
– Components of recommender system. The systems’ architecture consists of multiple deep-learning models, each aiming to capture different aspects characterizing the news items, user’s preferences, and interactions among users and news.
– Aggregation of knowledge-level and text-level components. Another distinguishing factor is constituted by the way in which the outputs of different components of the recommendation model are aggregated to predict the click-through probability for a candidate article.
6.3.2.Representative models
The architectures of 11 neural-based news recommendation frameworks are discussed in this section.
The Collaborative Entity Topic Ranking (CETR) [193] model combines matrix factorization, topic modeling, and knowledge graph embeddings in a collaborative fashion to alleviate the data sparsity problem and the limitations of word-level topic models on very infrequent words appearing in news articles. The model joins together three modules, the first modeling the user’s reading behavior, the second performing entity-level topic analysis of news, and the last computing representations of the knowledge graph entities.
The user behavior component takes as input the user-news interaction matrix Y, defined as follows:
Definition 5.
The user-item interaction matrix
The user-item interaction matrix is factorized into a matrix U of user features and a matrix V of news latent features. The factorization method, a Bayesian Personalised Ranking (BPR) model [134], uses a sigmoid function to characterize the probability of observing a triplet
In the following step, topic analysis is conducted at the entity level, where entities belonging to the same topic are sampled from a Gaussian distribution [193]. The third module learns knowledge graph embeddings with the TransR model [98]. The probability of observing a quadruple
DKN, the deep knowledge-aware network proposed by Wang et al. [170], was the first architecture to fuse neural network-based text-level and knowledge-level representations of news using an attention module. The input to the recommendation model is constituted by the user’s click history and one candidate news article. Each article t is represented by its title. In turn, the article’s title is composed of a sequence of words,
Definition 6.
The context of an entity e is defined as the set of its immediate neighbours in the knowledge graph [170]:
The inner-circle in Fig. 4 exemplifies this concept. DKN takes as input the embedding of GameStop short squeeze to represent the entity, as well as its context, denoted by neighbors and associated relations, such as USA (country), or Elon Musk, Robinhood, r/WallStreetBets (participant).
Fig. 4.
Illustration of ripple sets of GameStop short squeeze in Wikidata. The concentric circles indicate ripple sets with different hops. The fading blue signifies decreasing relatedness between the center and the neighboring entities (reproduced from [168]).
![Illustration of ripple sets of GameStop short squeeze in Wikidata. The concentric circles indicate ripple sets with different hops. The fading blue signifies decreasing relatedness between the center and the neighboring entities (reproduced from [168]).](https://ip.ios.semcs.net:443/media/sw/2024/15-1/sw-15-1-sw222991/sw-15-sw222991-g004.jpg)
One of the input elements to the recommendation model is constituted by the embedding of an entity’s context, defined in the following manner.
Definition 7.
The context embedding of entity e is defined as the average of the embeddings of its contextual entities [170]:
The first level in DKN’s architecture is represented by a knowledge-aware convolutional neural network (KCNN), namely the convolutional neural network (CNN) framework proposed by Kim [85] for sentence representation learning extended to incorporate symbolic knowledge in the text representations. Firstly, the entity embeddings
Secondly, the matrices containing word embeddings
The word-aligned KCNN applies multiple filters of varying sizes to extract patterns from the titles of news, followed by max-over-time pooling and concatenation of features to obtain the final representation
Additionally, DKN employs an attention network to capture the diverse interests of users in different news topics by dynamically aggregating a user’s history according to the current candidate article [170]. The second level of the DKN framework concatenates the embeddings of a target news
Given the normalized attention weights, a user i’s embedding with respect to the target article
Lastly, DKN [170] predicts the click probability of user i for news article
The recommendation model of Gao et al. [58] learns semantic-level and knowledge-level representations of news by adjusting the DKN architecture to use a fine-grained word-level description of news, obtained with a self-attention mechanism, instead of a topic-level representation given by the KCNN component. The user’s click history and a candidate piece of news constitute the model’s input. The framework consists of four-level self-attention modules [58]. Firstly, a word-level self-attention component computes the semantic-level and knowledge-level representation of articles using pre-trained embeddings of news tags and transformed pre-trained embeddings of entities extracted from a knowledge graph and their context, similar to DKN. The attention weight measuring the impact of each word in the news representation is computed as follows:
Secondly, the item-level attention model computes the final representation of news article
The attention weights of words are calculated as shown in Eq. (56), while those of entities and context can be computed analogously.
Thirdly, the user-level self-attention module computes the final representation of the user i’s history
Fourthly, the vector representation of the user and the target news article are combined using a multi-head attention module [163] with ten parallel attention layers. Lastly, the output of the fourth module is passed through a fully connected layer to calculate the user’s probability of clicking the candidate article.
A different approach is constituted by RippleNet [168], an end-to-end framework that propagates user preferences along the edges of a knowledge graph. RippleNet takes as input a candidate news article and the user’s historical set of interests
Definition 8.
Giving the knowledge graph
Definition 9.
The k-hop ripple set of a user u is the set of knowledge triples whose head entities are
The user’s interests in certain entities are extended from the initial set along the edges of the knowledge graph, as shown in Fig. 4. The further the hop, the weaker the user’s potential preference in the corresponding ripple set becomes since entities that are too distant from the user’s initial interests might introduce noise in the recommendations. This behavior is exemplified in Fig. 4 by the fading color of the concentric circles denoting ripple sets. The closer a neighboring entity is to the center seed, the more related the two are assumed to be. In practice, this is controlled by the number H of hops considered [170].
In the first step, RippleNet calculates the probability
The 1-order response
Equations (60) and (61) theoretically illustrate the preference propagation mechanism of RippleNet, through which the user’s interests are spread from the initial set
An inward aggregation version of this model, denoted RippleNet-agg, was later proposed by Wang et al. [169] to extract high-order structural proximity information among entities in a knowledge graph. In comparison to the outward propagation model, this variant uses biases to aggregate and inject the ripple sets’ information in an entity’s representation. More specifically, the importance of a relation
In RippleNet-agg, higher-order proximity information is captured by encoding the ripple sets in the final prediction function at the item-end, compared to the user-end, as it was the case in the original RippleNet model. To this end, the topological proximity structure of a news article v is defined as the linear combination of its one-hop samples ripple set
Lastly, the representations of the entity v and its neighborhood
Although the aggregation function in Eq. (62) is represented by the sum operation followed by a nonlinear transformation σ, this could be replaced by a
In contrast to previous models, the Multi-task feature learning approach for Knowledge graph Recommendation (MKR) [172] uses the knowledge embedding task to assist the recommendation one. The model is trained in an end-to-end fashion by optimizing the two components alternately, with different frequencies. The two components are connected by cross&compress units to learn high-order interactions between entities in the knowledge graph and items from the recommender systems sharing features in non-task-specific latent spaces. MKR aims to improve the generalization of predictions by using a multi-task learning environment.
MKR is composed of three modules. The recommendation component uses as input two raw feature vectors u and v of the user and article. The latent features of the user are extracted using an L-layer multilayer perceptron (MLP) as shown in Eq. (63), where
The features of news article v are computed using L cross&compress units, as follows:
The module outputs the probability of user u clicking on candidate news v, computed using a nonlinear function which takes as input latent features of the user
The goal of the KGE module is to learn the vector representation of the tail entity of triples in the knowledge graph. For a triple
The two task-specific modules are connected using cross&compress units which adaptively control the weights of knowledge transfer between the two tasks. The unit takes as input an article v and a corresponding entity e from the knowledge graph. The cross operation constructs a cross-feature matrix
Afterwards, the compress operation projects the cross features matrix back into the latent feature spaces
Although such units are able to extract high-order interactions between items and entities from the two distinct tasks, Wang et al. [172] only employ them in the model’s lower layers for two main reasons. On the one hand, the transferability of features decreases as tasks become more distinct in higher layers. On the other hand, both item and user features, as well as entity and relation features blend together in deeper layers of the framework, which deems them unsuitable for sharing as they lose explicit association.
The Interaction Graph Neural Network (IGNN) [128] aims to improve previous neural-based recommenders by enhancing the learning process of news and user representations with collaborative signals extracted from user-item interactions. This is achieved using two graphs: a knowledge graph for modeling news-news connections, and a user-item interaction graph.
The knowledge-based component jointly learns knowledge-level and semantic-level representations of news, similar to KCNN. More specifically, the embedding matrices of words, entities, and contextual entities are stacked before applying multiple filters and a max-pooling layer to compute the representation of news. In contrast to DKN, in IGNN the embeddings of entities and context, obtained with TransE [13], are not projected into the word vector space before stacking. However, as observed by Wang et al. [170], this simpler approach disregards the fact that the word and entity embeddings are learned using distinct models, and hence, are situated in different feature spaces. In turn, this means that all three types of embeddings need to have the same dimensionality in order to be fed through the convolutional layer. Nonetheless, this might be detrimental in practice, if the ideal vector sizes for the word and entity representations differ.
Higher-order latent collaborative information from the user-item interactions is extracted using embedding propagation layers that integrate the message passing mechanism of GNNs [128] using the IDs of the user and candidate news as input. This strategy is based on the assumption that if several users read the same two news articles, this is an indication of collaborative similarity between the pair of news, which can then be exploited to propagate information between users and news. The propagation layers inherit the two main components of GNNs, namely message passing and message aggregation. The former passes the information from news
The latter component aggregates the information propagated from the user’s neighborhood with the current representation of the user, before passing it through a LeakyReLU transformation function, namely
The KCNN results in a content-based representation of news and of users, where the latter is the result of a mean pooling function applied to the embeddings of the user’s previously read articles. Similarly, the k propagation layers result in another k representations of user and news. Lastly, the inner product between the final user and news representations, obtained by concatenating the two kinds of embeddings, is used to determine the user’s preference for the candidate news.
In addition to using side information to extract latent interactions among news, the Self-Attention Sequential Knowledge-aware Recommendation system (Saskr) [33] also considers the order in which users interact with the news. The sequence of interactions of a user with a group of news articles can reveal additional preferences, as it is generally assumed that users will read news deemed more relevant in the beginning of a session, and those in which they are less interested towards the end. Saskr combines sequential-aware with knowledge-aware modeling, both built as an encoder-decoder framework, to predict the article most likely to be clicked next by a user. The model’s input is constituted by a chronologically ordered sequence of L items read by the user,
The encoder of the sequential-aware component of Saskr is composed of an embedding layer, followed by multi-head self-attention and a feed-forward network. The embedding layer projects an article’s body in a d-dimensional latent space, by combining, for each piece of news i, its article embedding
The article’s embedding can be obtained in two ways. On the one hand, it can be computed as the sum of the pre-trained embeddings of its words, weighted by the corresponding TF-IDF weights, as
These representations are then fed into a multi-head self-attention module [163], to obtain the intermediate vector
Given the embedding
The knowledge-aware module uses external knowledge from a knowledge graph to detect connections between news. The knowledge-searching encoder extracts entities from the body of articles and links them to predefined entities in a knowledge graph for disambiguation purposes. The set of identified entities is additionally expanded with 1-hop neighboring entities. The contextual entities are embedded using word embeddings pre-trained with a directional skip-gram model [150]. The resulting contextual-entity embedding matrix
The final recommendation score for candidate news article
Liu et al. [100] propose a Knowledge-aware Representation Enhancement model for news Documents (KRED) – a new method for creating knowledge-enhanced representations of news for multiple downstream tasks, such as news recommendation, news popularity prediction or local news detection, trained using a multi-task learning strategy. A document vector
In Eq. (73),
The next, context embedding layer encodes the dynamic context of entities from a news article, determined by their position, frequency, and category. The entity’s position in the article (i.e. in the title or body) is encoded using a bias vector
The entities’ representations are aggregated into a single vector in the information distillation layer, by means of an attention mechanism that takes into account both the context-enhanced entity vectors and the original embedding of an article to compute its final representation. More specifically, the attention weights
The knowledge-aware document vector
In addition to injecting external knowledge into the recommendation model, the Topic-Enriched Knowledge Graph Recommendation System (TEKGR) [91] improves items’ representation by exploiting the topical relations among the news. This is based on the assumption that even if two news share knowledge entities in which the user might be interested, they may belong to different topics, which are not all relevant for the reader. TEKGR, constructed of three layers, takes as input a user’s click history and a candidate article. News articles are represented by their titles.
Firstly, the KG-based news modeling layer is composed of three encoders and outputs a vector representation for each given article. The word-level news encoder learns news representations using their titles without considering latent knowledge features. The first layer of the encoder projects the titles’ sequence of words into a lower-dimensional space, while the bidirectional GRU (Bi-GRU) layer encodes the contextual information of a news title. Bi-GRU obtains the hidden state of an article by concatenating the outputs of the forward and backward gated recurrent units (GRUs) [91]. This is followed by an attention layer which extracts more informative features from the vector representations by giving higher importance to more relevant words. Hence, the final representation of news article
The knowledge encoder extracts topic information from the news titles through three layers [91]. The concept extraction layer links each news title with corresponding concepts in a knowledge graph using an “is-a” relation. Afterwards, the concept embedding layer maps the extracted concepts to a high-dimensional vector space, while the self-attention network computes a weight for each word in the news title according to the associated concept and topic. For example, in the news title from Fig. 1, Elon Musk will have a higher attention weight in relation to the entrepreneur, than with the programmer, concept. The layer’s output is then concatenated with the news embedding vectors obtained from the word-level encoder.
The third, KG-level news encoder firstly performs a knowledge distillation process. The resulting subgraph is enriched with 2-hop neighbors of the extracted entities, as well as with topical information distilled by the knowledge encoder [91]. Therefore, not only are knowledge entities from the text disambiguated and their contextual information is taken into account but also adding topical relations among entities decreases data sparsity by connecting nodes not previously related in the knowledge graph. The topic and knowledge-aware news representation vector are computed with a graph neural network [171]. The final news embeddings are obtained by concatenating the word-level and KG-level representations.
Secondly, the attention layer computes the final user embedding by dynamically aggregating each clicked news with respect to the candidate news. This step is accomplished as in DKN, by feeding the concatenated embedding vectors of the user’s click history and the candidate news into a DNN. Lastly, the user’s probability of clicking on the target article is computed in the scoring layer using the dot product of the user’s and article’s feature vectors.
CAGE [144, 145] (Context Aware Graph Embedding) is another framework based on neural networks which performs session-based news recommendation by building a knowledge graph of the articles for enriching its semantic meaning, and refining the article embeddings with the help of a graph convolutional network. Textual-level article embeddings are generated using pre-trained word embedding models, such as word2Vec [108] or Glove [127]. The representation of an article j is a matrix of word vectors
In the next step, the words
The textual-level and semantic-level article embeddings are concatenated and integrated with user features to obtain the final article embedding
6.3.3.Summary
Neural-based news recommendation systems are summarized by focusing on four distinguishing aspects:
– Recommendation model input. These methods use the user’s news interaction history and a candidate article as input. The user’s interaction history is most often represented by previously clicked items. In such cases, the user profile is created by aggregating the representations of the individual articles from the click history. In contrast, CETR uses a user-item interaction matrix to represent the connection between users and news, and to generate collaborative recommendations. Similarly, RippleNet computes recommendations using the matrix of implicit feedback and a knowledge graph. Furthermore, the majority of models use a combination of word-level and entity-level representations of articles, based usually on their titles. The entities directly extracted from the news articles are further enriched with contextual information from the knowledge graph, in the form of k-hop neighbors, where the maximum number of hops considered represents one of the model’s hyperparameters. Furthermore, Saskr is the only model to take into account the order in which a user interacts with a sequence of news articles.
– Knowledge graph embedding model. Several approaches for embedding knowledge graph entities have been identified in the surveyed frameworks. Recommenders such as CETR, DKN, IGNN, KRED, or CAGE use TransE [13], TransH [178], TransR [98], or TransD [80] to compute knowledge graph embeddings. MKR uses a combination of MLP and cross&compress units, while Saskr embeds knowledge entities with pre-trained word embeddings. More recently, TEKGR adopts a GNN for deriving entity embeddings.
– Components of recommender system. With the exception of CETR, which uses a combination of matrix factorization, topic analysis, and KGE models, the other systems are based on various combinations of neural networks. MKR uses a combination of MLPs and cross&compress units to train two components for the tasks of recommendation and knowledge graph embedding, while IGNN fuses KCNN for content-based representation of news with a message-passing GNN that captures collaborative signals among the news. CAGE combines a CNN for textual-level embeddings with a GCN to compute refined article representations. All the remaining models use a type of attention mechanism. For example, DKN combines KCNN used for news representation with a DNN-based attention layer. Gao et al.’s model [58] incorporates only self-attention modules at all three levels – word, item and user – and employs another multi-head attention layer followed by a fully-connected layer for the final prediction. Similarly, Saskr is composed only of multi-head self-attention and fully connected layers. TEKGR and KRED combine attention modules with different types of GNNs. KRED uses a KGAT to aggregate the embeddings of an entity with those of its neighbors, followed by the attention mechanism of the Transformer [163] used for assigning different weights for each entity and for computing the article’s final embedding. TEKGR combines attention with Bi-GRU in the word-level encoder, and with KGE in the knowledge encoder. Additionally, it incorporates a GNN in the KG-level news encoder.
– Aggregation of knowledge-level and text-level components. As previously observed, the attention mechanism is widely used in models such as DKN, KRED, or TEKGR, to dynamically aggregate the outputs of different model components or the representations of individual modules at intermediate steps in the framework. A simpler strategy is adopted in IGNN, where the content-based and collaborative representations of news and users are concatenated before computing the final prediction. In comparison, MKR uses cross&compress units at the lower levels of its model to transfer similar latent features between the two task-specific components.
7.Evaluation approaches
This section analyses approaches used for evaluating the surveyed knowledge-aware news recommender systems, as well as potential limitations concerning the reproducibility and comparability of experiments.
7.1.Evaluation methodologies
The type of evaluation methodology depends on the target function of the recommendation models and the user data. In this context, the surveyed recommender systems were typically evaluated either through offline experiments based on historical data, through online studies on real-world websites, or in laboratory studies. Frameworks based on an item-ranking target function usually use an online setting or laboratory experiment. In these scenarios, participants are asked to annotate news articles recommended to them by the model based on their relevance to the user’s profile. In turn, the user profile is either created during the experiment or predefined and assigned to the participants by the evaluators. Once the annotations are obtained, the performance of the model is evaluated by comparing the predicted recommendations against the truth values provided by the annotators. In contrast, systems that target the click-through rate are evaluated through experiments in an offline setting, using data comprising of logs representing users’ historical interactions with sets of news.
Table 6 provides an overview of evaluation settings in terms of datasets and metrics used. As it can be observed there, all models are evaluated using different types of information retrieval accuracy measures, such as precision, recall, F1-score, or specificity. The performance of some of the more recent, neural-based systems is also evaluated in terms of rank-based measures, such as Normalized Discounted Cumulative Gain, Hit Rate, or Mean Reciprocal Rank. Generally, these metrics are computed at different positions in the recommendation list to observe the recommender’s performance based on the length of the results list. Moreover, for non-neural, entity-centric methods, the authors use statistical hypothesis tests, such as the Student’s t-test, to measure the significance of the experimental results.
Table 6
Overview of evaluation settings. We list the model’s category and abbreviated name, datasets used, and reported evaluation metrics and setup information. The abbreviations used in the table are the following: Eval. = Evaluation, Acc = Accuracy, P = Precision, R = Recall, F1 = F1-score, NDGC = Normalized Discounted Cumulative Gain, RMSE = Root Mean Square Error, MAE = Mean Absolute Error, ROC = Receiver Operating Characteristic, PR curves = Precision-Recall curves, AUC = Area Under the Curve, NDPM = Normalized Distance-Based Performance measure, HR = Hit Rate, MRR = Mean Reciprocal Rank, Kappa = Kappa statistics, Student’s t-test = One-tailed two-sample paired Student t-test, ESI-RR = Expected Self-Information with Rank and Relevance-sensitivity [56], EILD-RR = Expected Intra-List Diversity with Rank and Relevance sensitivity [162], PROCS = processing steps, DS = data split, PARAMS = parameters, All available = PROCS + DS + PARAMS + CODE
| Category | Model | Dataset(s) | Metric(s) | Eval. setup information |
| NNECM | Semantic aware context recommendation [21,23] | News@hand | P@K | PROCS, DS |
| Social tags enriched recommendations [24] | News@hand | Relevance | PROCS, DS | |
| Semantic relatedness [60] | Unknown source | P, R, F1 | – | |
| RSR [78] | Unknown source | Acc, P, R, Spec | – | |
| CF-IDF [64] | Reuters | ROC, PR curves, Kappa | DS | |
| Hybrid context-aware recommendation [23] | News@hand | P@K | PROCS, DS | |
| RSR 2 [55] | Unknown source | Acc, P, R, Spec | DS | |
| SF-IDF [26] | Reuters | Acc, P, R, F1, Spec, t-test | DS | |
| SF-IDF+ [112] | Reuters | Acc, P, R, F1, Spec, t-test | DS, PARAMS | |
| Bing-SF-IDF [71] | Reuters | Acc, P, R, F1, Spec, Kappa | DS, PARAMS | |
| Bing-SF-IDF+ [28] | Reuters | Acc, P, R, F1, Spec, Kappa | DS, PARAMS | |
| Agarwal and Singhal [2] | BBC, CNBC, Times of India | P, R, F1 | PROCS, PARAMS | |
| OF-IDF [133] | News database [72] | P, R, F1, runtime | DS | |
| CF-IDF+ [40] | Reuters | P, R, F1, ROC, AUC, Kappa | PROCS, DS, PARAMS | |
| Bing-CF-IDF+ [17] | Reuters | P, R, F1, ROC, Kappa | PROCS, DS, PARAMS | |
| Bing-CSF-IDF+ [161] | Reuters | F1, Kappa, Student’s t-test | PROCS, DS | |
| NNPM | ePaper [105] | The Jerusalem Post | NDPM, MAE | PROCS, DS, PARAMS |
| Magellan [45] | Unknown source | Acc, R | – | |
| SS [26] | Reuters | Acc, P, R, F1, Spec, t-test | DS | |
| BingSS [27] | Reuters | Acc, P, R, F1, Spec | DS, PARAMS | |
| OBSM [130] | New York Times, Sina News | P, R, F1 | DS | |
| Kumar and Kulkarni [88] | CNN news | R | PROCS, DS, PARAMS | |
| Werner and Cruz [179] | Unknown source | P, R, F1 | PROCS, PARAMS | |
| BKSport [117] | Sky Sports, ESPN, Yahoo Sports | P | PROCS, DS, PARAMS | |
| SED [83] | CNREC | P, R, F1 | PROCS, DS, PARAMS |
Table 6
(Continued)
| Category | Model | Dataset(s) | Metric(s) | Eval. setup information |
| NM | CETR [193] | Hupu News | R@K | PROCS, DS, PARAMS |
| Colombo-Mendoza et al. [35] | Unknown source | P, R, F1 | PROCS | |
| DKN [170] | Bing News | F1, AUC | All available | |
| Gao et al. [58] | Unknown source | AUC, NDCG@K | DS, PARAMS | |
| RippleNet [168] | Bing News | P@K, R@K, F1@K, AUC, Acc | All available | |
| RippleNet-agg [169] | Bing News | P@K, R@K, F1@K, AUC, Acc | All available | |
| MKR [172] | Bing News | Acc, AUC, P@K, R@K | All available | |
| IGNN [128] | DC, Adressa | R@K, NDCG@K | PROCS, DS, PARAMS | |
| Saskr [33] | Eastday Toutiao | HR@K, MRR | PROCS, DS | |
| KRED [100] | Microsoft News | AUC, NDCG@K, HR@K, ACC, F1-macro | All available | |
| TEKGR [91] | Bing News, Adressa | F1, AUC | PROCS, DS, PARAMS | |
| KCNR [176] | Sogou News | R@K, NDCG@K | PROCS, DS, PARAMS | |
| KG-RWSNM [188] | AUC, P, R, F1 | PROCS, PARAMS | ||
| MUKG [152] | Bing News | AUC, Acc, P@K, R@K | PROCS, DS, PARAMS | |
| CAGE [145] | Adressa | HR@K, MRR@K, HR@K, ESI-RR@K, EILD-RR@K | PROCS, DS, PARAMS |
7.2.Evaluation datasets
In comparison to the relatively uniform usage of evaluation metrics, the type of datasets used for evaluation varies significantly among recommender systems. The majority of non-neural models can be clustered into two groups, depending on the dataset used for their evaluation. As shown in Table 6, semantic-aware context recommenders are evaluated using the News@hand architecture described in [22]. Most of the remaining models are incorporated in the Hermes News Portal [54]. The authors of a few of the path-based, non-neural recommender systems construct their own datasets using news articles collected from websites such as the New York Times, or Sina News,1616 CNN,1717 Sky Sports,1818 ESPN,1919 or Yahoo Sports.2020 Joseph and Jiang [83] developed CNREC2121 for evaluating SED. CNREC is a dataset providing articles similarity and annotations for pairs of items showing the extent to which they are considered a good recommendation.
Table 7
Overview of evaluation datasets. We list the model’s category and abbreviated name, the dataset’s source, language, time frame, as well as the number of users, items, and interactions. An entry annotated with “*” denotes that the statistics were approximated by us based on the data provided by the authors. The abbreviations used in the table are the following: # = number of, N/A = not applicable
| Category | Model | Data source | Language | Time frame | #Users | #Items | # Logs/Interactions |
| NNECM | Semantic aware context recommendation [21,23] | BBC, CNN, New York Times, Washington Post | English | 01/01/2008-01/03/2008 | 16 | 9,698 | N/A |
| Social tags enriched recommendations [24] | BBC, CNN, New York Times, Washington Post | English | 01/01/2008-01/03/2008 | 20 | 9,698 | N/A | |
| Semantic relatedness [60] | CNN, BBC, USA Today, L.A. Times, Reuters | English | Unknown | N/A | 158 | N/A | |
| Synthetic data | Unknown | N/A | N/A | 100 | N/A | ||
| RSR [78] | Unknown | Unknown | Unknown | 5 | Unknown | 1500 * | |
| CF-IDF [64] | Reuters | English | Unknown | 19 | 100 | 1900 * | |
| Hybrid context-aware recommendation [23] | BBC, CNN, New York Times, Washington Post | English | 01/01/2008-01/03/2008 | 20 | 9,698 | N/A | |
| RSR 2 [55] | Unknown | Unknown | Unknown | 5 | 300 | 1500 * | |
| SF-IDF [26] | Reuters | English | Unknown | 19 | 100 | 1900 | |
| SF-IDF+ [112] | Reuters | English | Unknown | N/A | 100 | N/A | |
| Bing-SF-IDF [71] | Reuters | English | Unknown | N/A | 100 | N/A | |
| Bing-SF-IDF+ [28] | Reuters | English | Unknown | N/A | 100 | N/A | |
| Agarwal and Singhal [2] | BBC, CNBC, Times of India | Unknown | Unknown | Unknown | Unknown | Unknown | |
| OF-IDF [133] | Unknown | Unknown | 2010 | 33 | 1823 | 3600 | |
| CF-IDF+ [40] | Reuters | English | Unknown | N/A | 100 | N/A | |
| Bing-CF-IDF+ [17] | Reuters | English | Unknown | N/A | 100 | N/A | |
| Bing-CSF-IDF+ [161] | Reuters | English | Unknown | N/A | 100 | N/A | |
| NNPM | ePaper [105] | The Jerusalem Post | English | 4 days | 57 | Unknown | 4,731 * |
| Magellan [45] | Unknown | Unknown | 09/2010-01/2011 | N/A | Unknown | N/A | |
| SS [26] | Reuters | English | Unknown | 19 | 100 | 1900 | |
| BingSS [27] | Reuters | English | Unknown | N/A | 100 | N/A | |
| OBSM [130] | New York Times | English | 2006-2007 | 581 | 6,000 | 232,400 * | |
| Sina News | Chinese | Unknown | 581 | Unknown | 232,400 * | ||
| Kumar and Kulkarni [88] | CNN | English | Unknown | Unknown | Unknown | Unknown | |
| Werner and Cruz [179] | Unknown | Unknown | Unknown | 10 | 70 | 700 * | |
| BKSport [117] | Sky Sports, ESPN, Yahoo Sorts | English | Unknown | Unknown | 100 | Unknown | |
| SED [83] | Unknown | English | 25/08/2014-28/08/2014 | N/A | 300 | N/A |
Table 7
(Continued)
| Category | Model | Data source | Language | Time frame | #Users | #Items | # Logs/Interactions |
| NM | CETR [193] | Hupu News | Chinese | Unknown | 3,118 | 9,684 | 132,713 |
| Colombo-Mendoza et al. [35] | Bolsa de Madrid | Spanish | Unknown | 10 | 20 | 200 * | |
| DKN [170] | Bing News | Unknown | 16/10/2016-11/08/2017 | 141,487 | 535,145 | 1,025,192 | |
| Gao et al. [58] | Unknown | Unknown | 19/03/2018-31/03/2018 | 26,224 | 13,285 | 1,498,862 | |
| RippleNet [168] | Bing News | Unknown | 16/10/2016-11/08/2017 | 141,487 | 535,145 | 1,025,192 | |
| RippleNet-agg [169] | Bing News | Unknown | 16/10/2016-11/08/2017 | 141,487 | 535,145 | 1,025,192 | |
| MKR [172] | Bing News | Unknown | 16/10/2016-11/08/2017 | 141,487 | 535,145 | 1,025,192 | |
| IGNN [128] | DC | Unknown | Unknown | 10,000 | 6,385 | 116,225 | |
| Adressa | Norwegian | 2017 | 640,503 | 20,428 | 3,101,991 | ||
| Saskr [33] | Eastday Toutiao | Chinese | 30/10/2018-13/11/2018 | 6960 | 108,684 | 861,996 | |
| KRED [100] | Microsoft News | Unknown | 15/01/2019-28/01/2019 | 665,034 | 24,542 | 1,590,092 | |
| TEKGR [91] | Bing News | Unknown | 16/10/2016-11/08/2017 | 141,487 | 535,145 | 1,025,192 | |
| Adressa | Norwegian | 2017 | 561,733 | 11,207 | 2,286,835 | ||
| KCNR [176] | Sogou News | Chinese | 19/03/2019-26/03/2019 | 91,924 | 197,649 | 2,927,430 | |
| 31,738 | 41,012 | 1,300,380 | |||||
| KG-RWSNM [188] | Unknown | 28/09/2012-29/10/2012 | 1,776,950 | Unknown | Unknown | ||
| MUKG [152] | Bing News | Unknown | 16/10/2016-11/08/2017 | 141,148 | 535,145 | 1,025,192 | |
| CAGE [145] | Adressa | Norwegian | 2017 | 314,000 | 13,000 | 2,648,000 |
The datasets used to evaluate neural-based frameworks consist of user interaction logs gathered from websites such as Bing News,2222 Microsoft News,2323 Hupu,2424 Eastday Toutiao,2525 Sogou News,2626 or the Weibo dataset [192]. An exception is constituted by IGNN, TEKGR, and CAGE, evaluated on the different subsets or versions of the Adressa dataset. Adressa [65] is an event-based dataset comprising of click log data collected from a Norwegian news portal. Although the Adressa dataset is often used in evaluating deep learning-based news recommender systems [73,74,122,197], it is not used by any other of the surveyed knowledge-aware models.
As it can be further observed in Table 7, which summarizes the statistics of the used evaluation datasets, the number of users and items contained in these datasets varies widely. Non-neural models are evaluated on small datasets, usually with less than 1000 articles, with the exception of the semantic contextualization systems, tested with nearly 10,000 items. In contrast, neural-based methods are mostly evaluated on over 1 million click logs from more than 100,000 users and items.
Another critical finding is that in many cases, datasets are not described clearly enough. In a fourth of the cases, the data source is not specified. Moreover, the language of the dataset is rarely mentioned explicitly. While the language can easily be deduced from monolingual news websites, this does not hold true for international news platforms, leading to an unknown language in more than half of the cases.
7.3.Reproducibility and comparability of experiments
Table 6 also lists the type of information provided by each model with regards to the evaluation setup. Replicating experiments requires not only access to the data used, but also knowledge of how the data was split and processed for training and evaluation, and which values were used for the different parameters and hyperparameters of the model. Moreover, differences in the models’ implementation, especially of neural-based models, can further influence the results obtained when reproducing experiments. Hence, access to the original implementation constitutes an important factor for the comparability and reproducibility of results.
However, as it can be observed in the last column of Table 6, only 5 out of the 40 surveyed papers provide all this information. For both sub-categories of non-neural models, generally only the data split and some of the parameters or processing steps are specified. Even when some processing steps are explained in the paper, not enough details are provided regarding how procedures such as named entity recognition or entity linking were performed. Moreover, systems in these categories each propose their own evaluation setups, without following a uniform procedure.
In contrast, most papers describing a neural-based framework offer extensive details regarding their evaluation settings and model architecture. This phenomenon could be explained in two ways. On the one hand, since all neural-based models are deep learning architectures, hyperparameters play a central role in their performance. On the other hand, most of the approaches in this family have been published in the recent past, and there has been a trend in the recent years in the academic community to make implementation details available when publishing a research paper in order to facility reproducibility.
Nonetheless, important aspects which would increase the comparability of experiments are still neglected in some works. Often, the entity extraction and linking processes are not thoroughly explained, meaning that if no implementation details are available, it would be impossible to reproduce the exact steps of the original experiments. Nonetheless, all the previously discussed knowledge-aware news recommender systems use a form of named entity recognition and linking in order to identify entities and concepts in the news articles and to map them to a knowledge base. However, almost none of the papers explicitly mention how these steps are performed and implemented. Other important steps required by any news recommender system, such as general text pre-processing, which can heavily influence the data representation, and ultimately, the generated recommendations, are also not discussed. In addition to the recommendation module itself, such steps constitute important dimensions that may differ between systems, and in turn, choices in their design and implementation may lead to great differences in performance. In Saskr, for example, the authors offer few details on the construction of the news-specific knowledge graph used, and no specification of the news data source.
Table 8
Overview of evaluated features and components. We report the model’s category and abbreviated name, the features evaluated and the components evaluated during an ablation study, if one was conducted. The abbreviations used in the table are the following: dim. = dimension, emb. = embedding, init. = initialization, # = number of
| Category | Model | Eval. feats. | Ablation study |
| NNECM | Semantic aware context recommendation [21,23] | – | model components |
| Social tags enriched recommendations [24] | – | – | |
| Semantic relatedness [60] | – | – | |
| RSR [78] | threshold value | – | |
| CF-IDF [64] | threshold value | – | |
| Hybrid context-aware recommendation [23] | – | model components | |
| RSR 2 [55] | – | – | |
| SF-IDF [26] | – | – | |
| SF-IDF+ [112] | – | – | |
| Bing-SF-IDF [71] | threshold value | – | |
| Bing-SF-IDF+ [28] | threshold value | – | |
| Agarwal and Singhal [2] | |||
| OF-IDF [133] | – | – | |
| CF-IDF+ [40] | |||
| Bing-CF-IDF+ [17] | threshold value, Bing similarity parameters | – | |
| Bing-CSF-IDF+ [161] | threshold value, Bing similarity parameters | – | |
| NNPM | ePaper [105,148] | matching parameters, #user ratings, user profile init., concept weights | – |
| Magellan [45] | – | – | |
| SS [26] | – | – | |
| BingSS [27] | threshold value, Bing similarity parameters | – | |
| OBSM [130] | – | – | |
| Kumar and Kulkarni [88] | vector dim. | – | |
| Werner and Cruz [179] | – | similarity metric, recommendation algorithm | |
| BKSport [117] | – | semantic similarity, content similarity | |
| SED [83] | length expansion radius, entity screening, context words, edge weighting schema, distance measure, disconnected nodes penalty | – |
Table 8
(Continued)
| Category | Model | Eval. feats. | Ablation study |
| NM | CETR [193] | – | – |
| Colombo-Mendoza et al. [35] | – | network-based feature learning algorithm, similarity metric | |
| DKN [170] | word & entity emb. dim., #filters, window size | knowledge & attention component, KGE model, transformation function | |
| Gao et al. [58] | user profile length, #keywords | – | |
| RippleNet [168] | ripple set size, #hops, emb. dim. regularization weight | – | |
| RippleNet-agg [169] | aggregator, ripple set depth, neighbourhood sampling size, emb. dim. | – | |
| MKR [172] | KG size, RS training frequency, emb. dim. | cross&compress units, multi-task learning | |
| IGNN [128] | emb. dim., #emb. propagation layers | emb. propagation layers | |
| Saskr [33] | emb. layer init., article emb. strategy, sequence length, #targets, weight factor | – | |
| KRED [100] | base document vector, training strategy | layers (incl. knowledge component) | |
| TEKGR [91] | #hops | encoder types | |
| KCNR [176] | user’s click history length | preference prediction module, k-hop neighbour information | |
| KG-RWSNM [188] | – | social network component, entity information | |
| MUKG [152] | – | data sparsity, recommender system module | |
| CAGE [145] | entity emb. dim. | KGE model, KG removal |
Another significant factor to be considered in the evaluation and comparison of recommender systems is how different model features and components affect its performance. All of the surveyed papers compare their knowledge-aware news recommendation models against baselines which do not incorporate side information in order to illustrate the gains of a knowledge-enhanced system. In addition to evaluating a model against baselines and state-of-the-art systems, it is also necessary to understand the effect of different features and modules on the recommender’s performance. To this end, the choice of knowledge resource is critical for a knowledge-aware model. However, none of the papers compare their model’s performance using different knowledge bases to determine the extent to which the resource itself influences results.
As it can be seen in Table 8, only 6 out of 16 papers describing non-neural, entity-centric systems evaluate their model’s parameters. In these cases, the threshold values determining which articles are suggested to the user are empirically tested. In the case of non-neural, path-based recommenders, only the authors of ePaper [105], BingSS [27], Kumar and Kulkarni [88] and SED [83] evaluate the influence of different parameters or user profile initialization on the model’s performance. In comparison, the evaluation of neural-based systems involves parameters sensitivity analysis, as well as experiments with different initialization, training or embedding strategies. Such extensive experiments could also be influenced by the type of models, since neural network architectures comprise of several components, and are more sensitive to hyperparameters and design choices than models from the first two categories.
An additional finding is that few works perform an ablation study to determine the contribution of each component to the overall system. In the case of semantic-aware context recommenders, the authors analyze variants of the model obtained by removing either the contextualization of user preferences, the extension of user and news profiles, or both. Werner and Cruz [179] investigate different similarity metrics and recommendation techniques, while BKSport’s authors examine the performance of the recommender when taking into account only semantic similarities, only content similarities, or both. Colombo-Mendoza et al. [35] similarly experiment with two network-based feature learning algorithms and different similarity metrics. Wang et al. [170] remove not only the knowledge component during the ablation study, but also experiments with different types of knowledge graph embedding models. Additionally, DKN’s performance was tested using different transformation functions, as well as with and without the attention module. The authors of MKR evaluate the contribution of its cross&compress units by replacing them with different modules, while those of IGNN examine the effectiveness of the embedding propagation layers by comparing different model variants which use them either to enhance the news, the user, or both representations. Lee et al. evaluate the improvements of using side information in TEKGR by analyzing the effect of its KG-level and knowledge encoders. Similarly, KRED’s authors conduct an ablation study in which they remove each of KRED’s entity representation, context embedding and information distillation layers. KCNR’s performance is analyzed with and without the user preference prediction module, and the influence of the preference propagation in the knowledge graph by considering different k-hop neighbor information. KG-RWSNM’s authors perform an ablation study on the impact of the social network information, while MUKG’s recommender performance is examined given varying degrees of data sparsity. Lastly, Sheu and Li [145] examine CAGE’s performance without the knowledge graph or with different knowledge graph embedding models.
7.4.Summary
Overall, this investigation of evaluation approaches shows that there is no unified evaluation methodology to produce comparable experiments. Moreover, the datasets used for evaluation are freely chosen by the authors, and there is no clear benchmark set of datasets used by all the systems. Although an effort has been made in recent years to provide more details on the evaluation setup, model architectures and choice of parameters, there is often still too little information specified for critical processing steps. In conclusion, we argue that only some of the most recent, neural-based approaches could be replicated given the available data, whereas the remaining methods cannot be reproduced in accordance to the original implementations. In this context, knowledge-aware news recommendation models lack reproducibility and comparability, standards which have been strongly encouraged in other fields of machine learning.
8.Open issues and future directions
Existing works have already established a strong foundation for knowledge-aware news recommender systems. In this section, we firstly discuss which fundamental challenges of news recommendation have already been addressed by knowledge-aware models, then identify and elaborate on several open issues in the field, and propose promising research directions.
In addition to general challenges for recommender systems, such as the cold-start, data sparsity, personalization, diversity, or privacy issues [143], news recommenders systems face additional domain-specific challenges, as explained in Section 2. Data sparsity and cold-start problems have clearly been addressed by the injection of external information from a knowledge base into the recommendation module, as such information enriches the initial data available about items and users. Similarly, the news consumption behavior and the lack of explicit feedback have also been tackled by enriching initial user profile information gathered from click logs of read news articles with related information about entities or concepts identified in the respective articles and contained in a knowledge base. Although recommendation diversity has been explicitly addressed only in one of the discussed models, using knowledge graphs to extract knowledge-level connections between news can improve diversity compared to solely text-based recommenders by taking into account relations between news that stem from second or third-order related neighbors of extracted entities.
However, the backbone of knowledge-aware recommender systems is represented by the recognition and disambiguation of named entities in the articles, a plain task for humans, but difficult for automatic systems. While knowledge representations obtained from identified entities in the text have been claimed to provide a solution for many shortcomings of traditional recommender systems, this is only true if such entities have been firstly disambiguated correctly and knowledge about them has been created and stored in knowledge bases. In turn, this passes the problem to the entity linking and knowledge graph construction components, which are most often not thoroughly discussed by the existing works, as shown in Section 7.3. Moreover, these components themselves are being subjected to the same challenges of resolving ambiguities and discovering knowledge-level connections as a knowledge-unaware recommender system. If such knowledge is extracted automatically, the problem is pushed further down the pipeline, whereas if human experts are involved, the challenge becomes how to create structured knowledge in the face of the high churn of the news domain. Overall, these problems have not been tackled in the existing literature, although they pose significant problems for deploying a high-performing system as an effective solution in the real world. Therefore, we strongly believe that future research should not only be concerned with achieving increased performance on benchmark datasets while ignoring the additional challenges that a real-world application of the recommender system would pose, but should instead also try to address these open questions.
Several challenges have only been partly addressed by the surveyed works. For example, recommenders that construct user and item profiles based on ontological concepts take into account a smaller amount of data than those that use the full-text of news articles. Therefore, computations are faster and the negative effect of the large volume of data characterizing news recommendations is diminished. However, as it will be explained in Section 8.2, it remains unclear what is the impact of utilizing complete, large-scale knowledge graphs as side information. Similarly, the issue of sequential news consumption has only been addressed by Saskr and CAGE, although it constitutes an important characteristic of news recommendation in general which has already been addressed by non-knowledge-aware recommenders [4,125,197].
Nevertheless, a large number of news-specific challenges are not yet tackled by knowledge-aware news recommender systems. Issues related to the fairness of recommendation, such as over-specialization and bias or fake news, which constitute central challenges and avenues for research nowadays are not addressed in any of the surveyed papers. Similarly, neural knowledge-aware recommenders focus on the short-term interests of users and do not take into consideration their long-term preferences. Lastly, the influence of using knowledge bases, which often might not be frequently updated, on the timely recommendation of news with short shelf lives has so far not been investigated.
In the remainder of this section we elaborate on the identified open issues and propose future research directions.
8.1.Comparability of evaluations
Zhang et al. [194] have observed that the entire field of recommender systems lacks a unified evaluation methodology or benchmark datasets, which are common, e.g. in the domains of computer vision or natural language processing to ensure a fair comparison of models. A similarly troubling finding with regards to the reproducibility of research published in the area of recommender systems has been discussed by Dacrema et al. [37]. The authors compared numerous works published in recent years at prestigious conferences in the domain of neural, collaborative filtering-based recommendation approaches and found that less than a half could be reproduced. Moreover, the majority of the proposed methods were equally good or even outperformed by simpler methods, due to methodological issues such as the choice of baselines, propagation of weak baselines, or the poor tuning of these baselines [37].
The findings of Section 7.3 have shown that currently, knowledge-aware news recommender systems also hardly produce comparable experiments. While neural-based methods have a higher degree of reproducibility, the other models do not provide enough details on their evaluation methodology in order to be accurately replicated and verified. Another important observation is that none of the deep learning models have been compared against recommenders from the non-neural approaches. Nonetheless, comparability of evaluations is essential for benchmarking different models, which in turn, drives advancements in the field. Therefore, we argue that the field of knowledge-aware news recommender systems needs a stricter and more unified evaluation approach, including common benchmark datasets, clear processing steps, unification of evaluation metrics, usage of comparable resources and hyperparameters of pre-trained models, and ablation studies.
Need for Benchmark Datasets. As it is common in other fields of machine learning, we believe that a set of benchmark datasets is needed to compare and contrast news recommenders. Such datasets should address all downstream tasks in the field of news recommendation, such as click-through rate or popularity prediction. Moreover, benchmark datasets should cover a wide range of sizes. Since scalability constitutes a key factor for a good news recommender, evaluating models on datasets of various sizes would prove to what extent a system could be used in real-world scenarios. Furthermore, benchmark datasets should have clearly defined splits for training, testing, and validation. This requirement is necessary to prevent each author from creating randomized test splits, which cannot be replicated. Wu et al. [182] have recently constructed MIND, a large-scale dataset for news recommendation containing click logs of 1 million users on English articles from Microsoft News. Similar efforts have already been conducted in other fields. Datasets such as MNIST or ImageNet in computer vision, or SQuAD in natural language processing, are already widely used for comparing models in their respective domains. With the creation of Open Graph Benchmark, the GNN community has recently undertaken a similar effort in creating a set of benchmark datasets from varying domains and sizes [75]. Lastly, we have shown in Section 7.3 that the surveyed recommender systems cannot be accurately reproduced and faithfully compared to each other, partially due to the wide range of different knowledge graphs and similar resources used, as well as to the lack of information regarding the construction, processing, and usage of such external resources. In this context, a standard benchmark dataset should also contain a range of knowledge resources, such as knowledge graphs and ontologies, in order to truly allow for a full and fair comparison of knowledge-aware news recommender techniques.
Ensure Reproducibility. In addition to evaluating on the same datasets, with the same data splits, it is necessary to establish a stricter criterion for describing the evaluation methodology in order to ensure replicability of experiments. This means that detailed information of all processing steps, from general text pre-processing, to named entity recognition and linking, or the creation of news-specific knowledge graphs, should be provided to ensure that the experimental setup can be accurately reproduced at all steps. Moreover, underlying assumptions should be clearly stated, and all design choices regarding the hyperparameter optimization strategy should be reported. In case benchmark datasets are not used, the datasets on which the experiments are performed should be made publicly available. Lastly, as suggested in [37], the source code of all proposed models, including baselines, should be published using persistent repositories and ensuring that the reproduction steps are easy to follow by other users (e.g. software requirements, scripts for executing all steps of the pipeline and experiments are readily available).
Unification of Evaluation Metrics. The majority of papers already use the same information retrieval and rank-based metrics to evaluate their models. Nevertheless, every model should be evaluated using the same set of measures, which requires standardizing a set of evaluation metrics for each downstream application. Additionally, if the metrics consider the position of a recommendation in the results list, the same set of ranks should be applied throughout all modes being benchmarked.
Usage of Comparable Resources and Hyperparameters of Pre-trained Models. When comparing models against each other, authors should use the same external resources in as far as possible given the recommendation framework. For example, the same knowledge graph or ontology should be used to ensure that the knowledge resource itself does not influence the results on the downstream task. Similarly, in case pre-trained models, such as word or knowledge graph embeddings, are used, the same parameters (e.g. dimension of embedding vector) should be used by all analyzed models.
Ablation Studies. Furthermore, ablation studies should be performed for each newly proposed model to investigate the contribution of each component to the whole system. While this holds true for any recommender system, for knowledge-aware techniques it is essential to test the influence of the knowledge component, as done, for example, in DKN’s evaluation. Another interesting experiment would be to investigate the effect of the knowledge resource itself on the recommender’s performance, by injecting external knowledge, for example, from different knowledge graphs [166].
As discussed above, while natural language processing methods, in particular entity recognition and linking, play a crucial role in processing new texts, their effect is rarely documented. In the realm of ablation studies, we would encourage to investigate those effects more thoroughly (e.g. by exploiting different entity linking methods), and to also investigate interaction effects between the natural language processing methods, recommendation methods, and the knowledge resource used.
Overall, all these steps would ensure that models are not only fairly and transparently compared against each other without great variations in parameter settings, but would also indicate whether the improvement of a new model over the state-of-the-art results is determined by the system’s architecture, or simply, by a better-tuned set of hyperparameters. Similar studies that can serve as an example for the field of news recommendation have been conducted for graph neural networks [48] or knowledge graph embeddings [138].
Lastly, we believe that a comparison between non-neural and neural-based knowledge-aware news recommender systems is needed to compare and understand the strengths and weaknesses of all existing approaches for incorporating external knowledge into news recommendations.
8.2.Scalability of news recommenders
The continuously increasing amount of news published daily, as well as the growing number of online news readers and their desire to receive news content in a timely manner [132] constitute a constant challenge for any news recommender system, which requires scalability in order to be applied in real-world scenarios. Several techniques, ranging from fast clustering to dimensionality reduction, have been proposed to address the scalability issue. For example, Li et al. [93] proposed a scalable news recommender system which firstly clusters news articles based on their content in order to reduce the amount of similarity computations required for personalized recommendation. A combination of three approaches has been adopted by Das et al. [39] to improve the scalability of a recommender system dealing with millions of users and articles from Google News. A MinHash-based user clustering algorithm and Probabilistic Latent Semantic Indexing [70], both adapted for large-scale dataset scalability using the MapReduce framework [41], were employed by Das et al. [39] to cluster dynamic news datasets. These methods were combined with an item covisitation technique for extracting user-item relations to generate personalized news recommendations.
However, the injection of external information in the recommender systems further enlarged the scale of the datasets that need to be processed by the model, particularly in the case of frameworks using knowledge graphs as side information. As shown in Sections 6.2 and 6.3, such models obtain scalability using subgraphs, constructed by sampling fixed-sized neighborhoods. While this approach ensures that the recommendation model scales arbitrarily regardless of the size of the full graph, by not considering the entire graph at once, it is possible to ignore relevant neighbors of a node when gathering its contextual information. Hence, the sampling strategy used for defining a node’s neighborhood during subgraph construction influences the efficiency of the model. Overall, it can be concluded that knowledge-aware news recommender systems ensure scalability by sacrificing knowledge graph completeness. In this context, a promising research direction would be to investigate how to balance scalability and knowledge graph completeness in each downstream application scenario. To this end, we believe that an analysis of the effect of sampling strategy and neighborhood size on the robustness of the system and quality of the recommendations, as performed in [169], should be conducted for a larger variety of recommenders.
8.3.Explainability of recommendations
Providing explanations for the results generated by a recommender system helps users to understand why a certain item has been recommended to them by the model. In turn, this can increase the users’ trust in the system. For example, LISTEN, a model designed to explain rankings generated by a news recommendation model [158], explains the ranking of recommendations by identifying the most important features contributing to the current ranking and providing them to the user in a human interpretable form. The importance of features is determined by disrupting their values, one at a time, and observing how the change affects the ranking. In this case, a significant feature value will substantially change the ranking [158].
Although the workings and outputs of deep learning-based recommender systems are intricate and often not easily interpretable by non-expert users, attention mechanisms have recently alleviated the lack of interpretability of neural models. Attention weights not only provide insights into the inner functioning of a system but also serve as explanations for which features in a user’s or item’s profiles have contributed to the model’s recommendation. In this context, the Dynamic Explainable Recommender was designed by Chen et al. [32] to increase the accuracy of user modeling by taking into account the dynamic nature of user’s preferences, while providing recommendation explanations. More specifically, the model utilizes time-aware gated recurrent units to encode the user’s dynamic preferences and sentence-level convolutional neural networks to represent items based on the information captured in their reviews. The review information of different items is combined using a personalized attention mechanism, which learns the relevant pieces of information from a review according to the user’s current preferences, thus being able to explain the generated recommendations tailored to the user’s current state [32]. A different approach for balancing the accuracy and explainability of recommendations was adopted by Gao et al. [57], who built a rating prediction model using an attentive multi-view learning framework based on an explainable deep hierarchy. An attention mechanism connects adjacent views denoting different levels of features representing a user’s profile. Personalized explanations are generated from these multi-level features using a constrained tree node selection solved with dynamic programming [57].
Incorporating knowledge graph information into recommender systems has been used not only to improve recommendation accuracy, but also to increase the explainability of results, as paths capturing user-items interactions in the knowledge graph could illustrate which semantic relations and entities contribute to a particular recommendation given the input user profile [76,175,186]. As such, reasoning over the knowledge graph can reveal possible user interests and provide explanations for why a certain article has been recommended to the reader. Another means of using a knowledge graph to provide users with human-readable explanations for a recommender’s prediction was proposed by Ma et al. [104]. Their method learns inductive rules from an item-centric knowledge graph, which encodes items associations in the form of multi-hop relational patterns. The induced rules are incorporated in the recommendation module to address the cold start problem and provide explainability.
A growing number of recent news recommenders employ graph neural networks as components in the framework. However, these deep learning models are often seen as black-box models, whose interpretability is concealed to regular users. The GNNExplainer proposed by Ying et al. [190] is a model-agnostic approach for explaining predictions of any GNN-based model. The method takes as input a trained GNN and a prediction and generates an explanation in the form of a compact subgraph of the input graph and a small subset of node features with the highest impact on the given prediction. Computing explanations require optimizing the subgraph structure, such that its mutual information with the GNN’s prediction is maximized. Given the increasing usage of graph neural networks in news recommender systems, the GNNExplainer could be used to provide explanations for knowledge-aware news recommendations.
Hitherto, to the best of our knowledge, an explainable knowledge-aware news recommender system has not yet been designed. Providing explanations for online news readers remains thus an open problem. Therefore, we believe this is a noteworthy avenue which should be explored in future research.
8.4.Fairness of recommendations
Nowadays, news recommender systems have an increasing influence over people’s lives, by controlling which articles a reader is exposed to. This has raised concerns about biases that might be amplified by such systems. Yao and Huang [189] identified two types of biases inherent in recommender systems, namely observation bias, and population imbalance bias.
Observation bias is determined by feedback loops that prevent the model from learning how to predict items that are dissimilar to the previously recommended or consumed ones [51]. Content-based recommenders generate suggestions that are similar to the ones in the user’s history, while collaborative filtering systems recommend items liked by similar users. In both cases, the model learns to make predictions based on its past actions, since users cannot provide feedback for items that are not recommended to them, thus reinforcing the recommender’s algorithmic behavior [51]. In the context of news recommendation, observation bias has given rise to the hypothesis that readers become trapped inside filter bubbles – states in which they are exposed only to the news that supports or amplify their opinions [123]. In turn, this might lead, in the long run, to opinion polarization and self-radicalization of individuals through online media [119].
Bias stemming from imbalanced data is a systematic bias caused by societal or historical discrimination, which occurs when different categories of users are represented in unequal proportions in the data used for training a recommender system [189]. For example, population imbalance bias would occur if a recommender would suggest technology news mainly to men and cooking articles to women.
Several techniques have been designed for fair recommender systems in general. For example, Beutel et al. [8] proposed using pairwise comparisons as a metric for measuring the ranking fairness of a recommender system. Moreover, they introduce a pairwise regularization method to improve the model’s fairness property during training. Burke et al. [19] identify multiple stakeholders of a recommender system and distinguish between different types of fairness depending on the corresponding stakeholder group, namely consumer-centered, provider-centered, or both. The authors propose using the concept of balanced neighborhoods combined with a sparse linear model to obtain a desirable trade-off between fairness of results and personalization of recommendations [19].
Wu et al. [181] proposed using decomposed adversarial learning and orthogonality regularization to diminish unfairness caused by the biases of sensitive user attributes, such as gender, in news recommendation. More specifically, during training, the model learns two types of user embeddings: bias-aware ones that capture biases encoded in sensitive attributes describing the user’s behaviors, and bias-free ones that capture attribute-independent information related to the user’s interests. Adversarial learning is used to ensure that the bias-free embeddings do not contain information from the sensitive user attributes, while orthogonality regularization ensures that the two types of representations are orthogonal to each other. Lastly, fairness-aware news recommendations are computed using only the bias-free user embeddings [181].
Symeonidis et al. [156] propose a popularity-based and a distance-based novelty-aware matrix factorization technique to address the problem of filter bubbles created by recommender systems. Novelty-aware matrix factorization introduces in the classic regularized matrix factorization model a soft constraint that controls how new items are being recommended. In the popularity-based recommendation setting, the novelty of an item is defined as the inverse of its popularity, with items being more novel the fewer people are aware of them. In the case of distance-based recommendations, an item is considered novel if the topic category to which it belongs does not comprise many other items with which the user has already interacted in the past [156]. However, this approach focuses on systems based on matrix factorization, which are not used by knowledge-aware news recommender systems, as discussed previously.
In the field of news recommendation, Gharahighehi et al. [61] address the news recommendation task from a multi-stakeholder perspective and adopt a hypergraph learning method in order to take into account multiple stakeholders and counteract the negative effect of popularity bias on the recommendations. The stakeholders involved in the news recommendation scenario and their interactions are modeled by means of a hypergraph, thus enabling the direct computation of the relatedness between different stakeholders, represented as vertices of the hypergraph. Moreover, the authors introduce a temporal-aware learning approach which dynamically updates the weights given to the different stakeholders in order to increase recommendation fairness [61].
However, these methods have been developed for traditional recommender systems and do not consider biases that might stem from the knowledge resource used as side information. Moreover, none of the surveyed models investigates whether filter bubbles arise when using external knowledge resources for recommendations. Hence, given the importance of these topics, investigating how fairness can be incorporated into knowledge-aware news recommender systems, as well as examining if filter bubbles are created and how their effect can be diminished, represent promising directions for future works in this field.
Another related problem is that of fake news, which can be propagated by recommender systems using news data whose credibility has not been verified. In this context, numerous fake news detection algorithms have already been proposed [103,164,165]. Additionally, knowledge graphs can also be used to detect whether the news is fabricated [46,121,157]. Nonetheless, none of the surveyed works is concerned with the potential propagation of fake news by the recommender system or ways to mitigate it. Therefore, we conclude that incorporating a fake news detection module, potentially based on knowledge graphs, represents an important avenue for research that would contribute to reducing the spread of fake news and misinformation by knowledge-aware news recommendation algorithms.
8.5.Multilingual and multi-modal news recommendation
Today, online news comes in various shapes. Next to online newspapers, internet users increasingly consume their news in the form of podcasts or videos, most often using a mix of text, audio, and video modalities [116]. Given that observation, multi-modal recommendation methods are likely to gain more traction but are rarely observed so far [132]. Here, knowledge-based recommenders would be an interesting opportunity, since knowledge-based content representations and multi-modal knowledge graphs [102] could be used to form links between news present in different modalities. Moreover, given the strong trend of neural recommendation methods in the field, multi-modal embedding models [115,159] could be an interesting pathway towards developing such recommendation techniques [153].
Multi-lingual news consumption is also quite frequent. According to a study from 2014, 36% of all internet users in the European Union “frequently” and even 81% “occasionally” consume news and information online in more than one language [42]. While many knowledge graphs are inherently multi-lingual, and the use of identifiers for concepts and entities can help to bridge the gap between documents in different languages, all of the approaches surveyed in this document are monolingual. Like multilingual neural language models can be applied to the task of cross-lingual news recommendation [180], we also foresee the development of knowledge-based multi-lingual news recommenders.
8.6.Multi-task learning for recommendation
Multi-task learning [29] is a transfer learning-based paradigm which aims to exploit similarities across different tasks in order to improve the generalization performance of a model. The model is trained for multiple related tasks in parallel and domain-specific information is transferred between tasks to prevent overfitting on a single downstream application [195]. This approach has proven successful in numerous applications, ranging from computer vision to speech recognition and natural language processing [137].
Multi-task learning has also been employed by recommender systems from different domains [118]. In the case of recommender systems using knowledge graphs as side information, the quality of recommendation might be negatively affected by missing facts in the knowledge graph as the user’s preferences may be ignored if they are not captured by existing entities and relations. Recent works have shown that jointly learning a model for both recommendation and knowledge graph completion can result in improved recommendations [25,96]. Similarly, in the field of knowledge-aware news recommendation, Wang et al. [172] have used this paradigm to jointly train a model for the tasks of news recommendation and knowledge graph embedding, while Liu et al. [100] jointly trained a knowledge-aware representation enhancement model for news documents on a variety of tasks, ranging from item recommendation to local news prediction.
Taking into account the advantages of the multi-task learning paradigm, we believe that utilizing transfer knowledge from tasks such as entity classification or link prediction for knowledge-aware news recommendation is a promising direction to pursue in the future.
8.7.Sequential and timely recommendations
Readers consume news in sequences and prefer updates about ongoing and developing stories, rather than repeated or highly similar articles. Taking into account sequential dependencies between articles has been addressed in news recommendation generally by means of recurrent neural networks (RNNs) [125]. More recent approaches combine RNNs with attention modules. For example, Zhu et al. [197] use an attention-based RNN as a sequential information extractor that can automatically model the dynamic history sequential features used to represent a user’s clicked articles, while Bai et al. [4] use a combination of RNNs and attention to build a sequence-aware, user-based collaborative filtering recommender system. However, knowledge-aware sequential news recommender systems have been rarely proposed so far. In this context, we believe that enhancing existing sequential news recommenders with side information from a knowledge base is an interesting research avenue towards tackling this problem.
In addition to consuming articles sequentially, readers prefer recent and up-to-date news. Not only does an article’s relevance diminish over time, but the news is constantly updated and superseded by more popular pieces of information. In turn, this means that recommendations that are based not only on the text content of news, but also on knowledge entities and side information, need to ensure the timeliness of the information contained in external knowledge bases. However, many large knowledge graphs quickly become outdated and do not contain the latest information about world events [50].
In this context, one approach to address this issue is the inclusion of temporal constraints to model the limited validity of knowledge base items determined by the dynamic nature of events described in the news. Among the existing recommender systems, the ones included in the Hermes News Portal [17,26–28,40,55,64,71,112,161] support knowledge base updates. More specifically, the Hermes framework not only provides the functionality for specifying temporal constraints of news items, but it also incorporates updates to the knowledge base based on event rules, meant to reflect changes of real-world events [53]. A similar strategy of updating the ontology used for recommendation is adopted in Magellan [45], in which erroneous statements or outdated facts are removed from the ontology if the lifespan of the corresponding relations in the ontology – updated with every repetition in a news story – are not refreshed for a certain period of time. Another technology that could be adopted by news recommenders based on ontologies is tOWL [109], namely an extension of the OWL Description Logic language used to model ontologies. tOWL enables temporal representations through the introduction of time points and relations between them, as well as timeslices that can represent complex temporal aspects, such as process state transitions [109].
Furthermore, we encourage a shift from static towards temporal knowledge graphs that capture temporal dynamics of entities and the relations [81] between them. This could help knowledge-aware news recommenders overcome the problem that the validity of any facts contained in static knowledge graphs is constrained to a specific time period. Temporal knowledge graphs have gained traction in the latest years in the field of recommender systems. For example, Xiao et al. [187] proposed a temporal knowledge graph, which is incrementally constructed from user-item interactions and related auxiliary information, and used for recommendation. Similarly, Mezni [107] leverages a temporal knowledge graph to build a time-aware recommender system for service recommendation. Therefore, we believe that using temporal knowledge graphs is not only a potential solution to ensure the timeliness of external data injected in the recommendation module, but also a highly promising direction for future research in the field of knowledge-aware news recommendation.
8.8.Changing user preferences
In addition to preferring timely news, readers also have preferences that evolve over time. On the one hand, short-term preferences are determined by current trends, popularity, and context of certain news and events, such as the local elections in a country. On the other hand, long-term preferences evolve more slowly and are motivated by socio-economic and personal factors, such as an interest in climate change [67]. However, as it can be observed from Section 6.3, neural knowledge-aware news recommender systems learn single representations of users that do not differentiate between the two types of user interests. In turn, this can be detrimental for the generated recommendations, as users might not only want to see news regarding the latest events, but also read articles related to their long-term interests.
The LSTUR model proposed by An et al. [3] takes into account both kinds of preferences when constructing user profiles. More specifically, long-term representations are given by the embeddings of user IDs, while short-term preferences are captured from the users’ recently browsed news using a GRU. The two representations can either be concatenated to obtain the final user representation, or the long-term user representation can be used to initialize the hidden state of the GRU network for the short-term representation module [3].
Another approach has been proposed by Hu et al. [73]. Their model, GNewsRec, uses a GNN on a heterogeneous user-news-topic graph to learn the user’s long-term interest encoded as high-order relationships between users, items, and topics in the graph. To capture the short-term user preferences, the authors employ an attention-based long short-term memory [69] on the user’s reading history.
Given the existing research already conducted to account for changing user interests in news recommendation, we believe that incorporating techniques that are able to differentiate between short-term and long-term user preferences in knowledge-aware news recommenders is a pathway worth pursuing to ensure diversity of recommendations and user satisfaction.
9.Conclusion
In this survey paper, we have extensively reviewed knowledge-aware news recommender systems. We propose a new taxonomy for classifying existing recommenders, based on how the latent representations are generated for the users’ and articles’ profiles using concepts and entities from a knowledge base, as well as on the type of similarity metric used. According to the classification scheme, we categorize knowledge-aware news recommender systems into non-neural and neural-based frameworks, with the former category further divided into entity-centric and path-based methods. Representative models from each category are summarized and thoroughly analyzed. Moreover, we discuss and compare evaluation approaches used by existing publications and identify limitations in terms of comparability and reproducibility of experiments. Lastly, we identify and examine open issues in the field and propose future research directions that could drive progress in this domain. We hope this survey can serve as a comprehensive overview of knowledge-aware news recommender systems, clarifying key aspects of the field and uncovering open problems and corresponding promising directions to pursue in future studies.
Notes
8 The corresponding spreadsheets for both phases are available at: https://docs.google.com/spreadsheets/d/11NxjctjgQ5sAbbA2g2vKgqyUigg4t6S_H98-VsHJDWQ/edit?usp=sharing.
15 The Bing similarity is comparable to the Normalized Google Distance [34].
Acknowledgements
The work presented in this paper has been conducted in the ReNewRS project, which is funded by the Baden-Württemberg Stiftung in the Responsible Artificial Intelligence program. The publication of this article was funded by the Ministry of Science, Research and the Arts Baden-Württemberg and the University of Mannheim.
Acronyms
Bi-GRU | Bidirectional Gated Recurrent Unit, 56 |
BPR | Bayesian Personalised Ranking, 49 |
CNN | Convolutional Neural Network, 49, 57, 58 |
CTR | Click-Through Rate, 31 |
DNN | Deep Neural Network, 50, 57, 58 |
GCN | Graph Convolutional Network, 57, 58 |
GNN | Graph Neural Networks, 28, 33, 34, 54, 58, 67, 69, 72 |
GNN-KADR | Graph Neural Network-based Knowledge-Aware Deep Recommender, 28 |
GRU | Gated Recurrent Unit, 56, 57, 72 |
KB | Knowledge Base, 30, 31 |
KCNN | Knowledge-aware Convolutional Neural Network, 49, 50, 54, 58 |
KG | Knowledge Graph, 29, 31, 56–58, 63 |
KGE | Knowledge Graph Embedding, 47, 53, 58 |
MLP | Multilayer Perceptron, 53, 58 |
PMI | Point-Wise Mutual Information, 40 |
POS | Part-Of-Speech, 44 |
RNN | Recurrent Neural Network, 71 |
TF-IDF | Term Frequency-Inverse Document Frequency, 36, 38, 39, 42, 43, 47, 55 |
References
[1] | G. Adomavicius and A. Tuzhilin, Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions, IEEE Transactions on Knowledge and Data Engineering 17: (6) ((2005) ), 734–749. doi:10.1109/TKDE.2005.99. |
[2] | S. Agarwal and A. Singhal, Handling skewed results in news recommendations by focused analysis of semantic user profiles, in: 2014 International Conference on Reliability Optimization and Information Technology (ICROIT), IEEE, (2014) , pp. 74–79. doi:10.1109/ICROIT.2014.6798295. |
[3] | M. An, F. Wu, C. Wu, K. Zhang, Z. Liu and X. Xie, Neural news recommendation with long-and short-term user representations, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum and L. Màrquez, eds, Association for Computational Linguistics., Florence, Italy, (2019) , pp. 336–345. doi:10.18653/v1/P19-1033. |
[4] | B. Bai, G. Zhang, Y. Lin, H. Li, K. Bai and B. Luo, CSRN: Collaborative sequential recommendation networks for news retrieval, 2020, preprint, arXiv:2004.04816. |
[5] | J. Beel, B. Gipp, S. Langer and C. Breitinger, Research-paper recommender systems: A literature survey, International Journal on Digital Libraries 17: (4) ((2016) ), 305–338. doi:10.1007/s00799-015-0156-0. |
[6] | F. Belleau, M.-A. Nolin, N. Tourigny, P. Rigault and J. Morissette, Bio2RDF: Towards a mashup to build bioinformatics knowledge systems, Journal of biomedical informatics 41: (5) ((2008) ), 706–716. doi:10.1016/j.jbi.2008.03.004. |
[7] | J. Bennett and S. Lanning, The Netflix prize, in: Proceedings of KDD Cup and Workshop, Vol. 2007: , New York, NY, USA, (2007) , p. 35, http://brettb.net/project/papers/2007%20The%20Netflix%20Prize.pdf. |
[8] | A. Beutel, J. Chen, T. Doshi, H. Qian, L. Wei, Y. Wu, L. Heldt, Z. Zhao, L. Hong, E.H. Chi et al. Fairness in recommendation ranking through pairwise comparisons, in: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Association for Computing Machinery, New York, NY, United States, (2019) , pp. 2212–2220. doi:10.1145/3292500.3330745. |
[9] | P. Bhargava, T. Phan, J. Zhou and J. Lee, Who, what, when, and where: Multi-dimensional collaborative recommendations using tensor factorization on sparse user-generated data, in: Proceedings of the 24th International Conference on World Wide Web, International World Wide Web Conferences Steering Committee, Florence, Italy, (2015) , pp. 130–140. doi:10.1145/2736277.2741077. |
[10] | Bing Index Team, 2013, Understand your world with bing, https://blogs.bing.com/search/2013/03/21/understand-your-world-with-bing/. |
[11] | T. Bogers and A. Van den Bosch, Comparing and evaluating information retrieval algorithms for news recommendation, in: Proceedings of the 2007 ACM Conference on Recommender Systems, RecSys’07, Association for Computing Machinery, New York, NY, USA, (2007) , pp. 141–144. doi:10.1145/1297231.1297256. |
[12] | K. Bollacker, C. Evans, P. Paritosh, T. Sturge and J. Taylor, Freebase: A collaboratively created graph database for structuring human knowledge, in: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, SIGMOD’08, Association for Computing Machinery, New York, NY, USA, (2008) , pp. 1247–1250. doi:10.1145/1376616.1376746. |
[13] | A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston and O. Yakhnenko, Translating embeddings for modeling multi-relational data, in: Proceedings of the 26th International Conference on Neural Information Processing Systems, NIPS’13, Vol. 2: , (2013) , pp. 1–9, https://dl.acm.org/doi/abs/10.5555/2999792.2999923. |
[14] | H.L. Borges and A.C. Lorena, A survey on recommender systems for news data, in: Smart Information and Knowledge Management, E. Szczerbicki and N.T. Nguyen, eds, Studies in Computational Intelligence, Vol. 260: , Springer, (2010) , pp. 129–151. doi:10.1007/978-3-642-04584-4_6. |
[15] | J. Borràs, A. Moreno and A. Valls, Intelligent tourism recommender systems: A survey, Expert Systems with Applications 41: (16) ((2014) ), 7370–7389. doi:10.1016/j.eswa.2014.06.007. |
[16] | G. Bouma, Normalized (pointwise) mutual information in collocation extraction, in: Proceedings of GSCL, Vol. 30: , (2009) , pp. 31–40, https://svn.spraakdata.gu.se/repos/gerlof/pub/www/Docs/npmi-pfd.pdf. |
[17] | E. Brocken, A. Hartveld, E. de Koning, T. van Noort, F. Hogenboom, F. Frasincar and T. Robal, Bing-CF-IDF+: A semantics-driven news recommender system, in: LNCS, Vol. 11483: , (2019) , pp. 32–47. doi:10.1007/978-3-030-21290-2_3. |
[18] | R. Burke, Hybrid recommender systems: Survey and experiments, User modeling and user-adapted interaction 12: (4) ((2002) ), 331–370. doi:10.1023/A:1021240730564. |
[19] | R. Burke, N. Sonboli and A. Ordonez-Gauger, Balanced neighborhoods for multi-sided fairness in recommendation, in: Proceedings of the 1st Conference on Fairness, Accountability and Transparency, S.A. Friedler and C. Wilson, eds, Proceedings of Machine Learning Research, Vol. 81: , PMLR, (2018) , pp. 202–214, https://proceedings.mlr.press/v81/burke18a.html. |
[20] | H. Cai, V.W. Zheng and K.C.-C. Chang, A comprehensive survey of graph embedding: Problems, techniques, and applications, IEEE Transactions on Knowledge and Data Engineering 30: (9) ((2018) ), 1616–1637. doi:10.1109/TKDE.2018.2807452. |
[21] | I. Cantador, A. Bellogín and P. Castells, Ontology-based personalised and context-aware recommendations of news items, in: 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Vol. 1: , IEEE, (2008) , pp. 562–565. doi:10.1109/WIIAT.2008.204. |
[22] | I. Cantador, A. Bellogín and P. Castells, News@hand: A semantic web approach to recommending news, in: Adaptive Hypermedia and Adaptive Web-Based Systems. AH 2008, W. Nejdl, J. Kay, P. Pu and E. Herder, eds, Lecture Notes in Computer Science, Vol. 5149: , Springer, (2008) , pp. 279–283. doi:10.1007/978-3-540-70987-9_34. |
[23] | I. Cantador, P. Castells and A. Bellogín, An enhanced semantic layer for hybrid recommender systems: Application to news recommendation, International Journal on Semantic Web and Information Systems (IJSWIS) 7: (1) ((2011) ), 44–78. doi:10.4018/jswis.2011010103. |
[24] | I. Cantador, M. Szomszor, H. Alani, M. Fernández and P. Castells, Enriching ontological user profiles with tagging history for multi-domain recommendations, in: International Workshop on Collective Semantics: Collective Intelligence and the Semantic Web, CISWeb 2008, A. Yannis, K. Yiannis, S. Steffen and V. Athena, eds, CEUR Workshop Proceedings, Vol. 351: , (2008) , pp. 5–19, http://hdl.handle.net/10486/665406. |
[25] | Y. Cao, X. Wang, X. He, Z. Hu and T.-S. Chua, Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences, in: The World Wide Web Conference, WWW’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 151–161. doi:10.1145/3308558.3313705. |
[26] | M. Capelle, F. Frasincar, M. Moerland and F. Hogenboom, Semantics-based news recommendation, in: Proceedings of the 2nd International Conference on Web Intelligence, Mining and Semantics, WIMS’12, Association for Computing Machinery, New York, NY, USA, (2012) , pp. 1–9. doi:10.1145/2254129.2254163. |
[27] | M. Capelle, F. Hogenboom, A. Hogenboom and F. Frasincar, Semantic news recommendation using wordnet and bing similarities, in: Proceedings of the 28th Annual ACM Symposium on Applied Computing, SAC’13, Association for Computing Machinery, New York, NY, USA, (2013) , pp. 296–302. doi:10.1145/2480362.2480426. |
[28] | M. Capelle, M. Moerland, F. Hogenboom, F. Frasincar and D. Vandic, Bing-SF-IDF+ a hybrid semantics-driven news recommender, in: Proceedings of the 30th Annual ACM Symposium on Applied Computing, SAC’15, Association for Computing Machinery, New York, NY, USA, (2015) , pp. 732–739. doi:10.1145/2695664.2695700. |
[29] | R. Caruana, Multitask learning, Machine learning 28: (1) ((1997) ), 41–75. doi:10.1023/A:1007379606734. |
[30] | R. Catherine and W. Cohen, Personalized recommendations using knowledge graphs: A probabilistic logic programming approach, in: Proceedings of the 10th ACM Conference on Recommender Systems, RecSys’16, Association for Computing Machinery, New York, NY, USA, (2016) , pp. 325–332. doi:10.1145/2959100.2959131. |
[31] | O. Celma, Music recommendation, in: Music Recommendation and Discovery, Springer, (2010) , pp. 43–85. doi:10.1007/978-3-642-13287-2_3. |
[32] | X. Chen, Y. Zhang and Z. Qin, Dynamic explainable recommendation based on neural attentive models, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33: , (2019) , pp. 53–60. doi:10.1609/aaai.v33i01.330153. |
[33] | Q. Chu, G. Liu, H. Sun and C. Zhou, Next news recommendation via knowledge-aware sequential model, in: Chinese Computational Linguistics. CCL 2019, M. Sun, X. Huang, H. Ji, Z. Liu and Y. Liu, eds, Lecture Notes in Computer Science, Vol. 11856: , Springer, Cham, (2019) , pp. 221–232. doi:10.1007/978-3-030-32381-3_18. |
[34] | R.L. Cilibrasi and P.M.B. Vitanyi, The Google similarity distance, IEEE Transactions on Knowledge and Data Engineering 19: (3) ((2007) ), 370–383. doi:10.1109/TKDE.2007.48. |
[35] | L.O. Colombo-Mendoza, J.A. García-Díaz, J.M. Gómez-Berbís and R. Valencia-García, A deep learning-based recommendation system to enable end user access to financial linked knowledge, in: Hybrid Artificial Intelligent Systems. HAIS 2018, J.F. de Cos, J.R. Villar, E.A. de la Cal, A. Herrero, H. Quintián, J.A. Sáez and E. Corchado, eds, Lecture Notes in Computer Science, Vol. 10870: , Springer, (2018) , pp. 3–14. doi:10.1007/978-3-319-92639-1_1. |
[36] | R.G. Crespo, O.S. Martínez, J.M.C. Lovelle, B.C.P. García-Bustelo, J.E.L. Gayo and P.O. De Pablos, Recommendation system based on user interaction data applied to intelligent electronic books, Computers in Human Behavior 27: (4) ((2011) ), 1445–1449. doi:10.1016/j.chb.2010.09.012. |
[37] | M.F. Dacrema, S. Boglio, P. Cremonesi and D. Jannach, A troubling analysis of reproducibility and progress in recommender systems research, ACM Transactions on Information Systems (TOIS) 39: (2) ((2021) ), 1–49. doi:10.1145/3434185. |
[38] | Y. Dai, S. Wang, N.N. Xiong and W. Guo, A survey on knowledge graph embedding: Approaches, applications and benchmarks, Electronics 9: (5) ((2020) ), 750. doi:10.3390/electronics9050750. |
[39] | A.S. Das, M. Datar, A. Garg and S. Rajaram, Google news personalization: Scalable online collaborative filtering, in: Proceedings of the 16th International Conference on World Wide Web, WWW’07, Association for Computing Machinery, New York, NY, USA, (2007) , pp. 271–280. doi:10.1145/1242572.1242610. |
[40] | E. de Koning, F. Hogenboom and F. Frasincar, in: News Recommendation with CF-IDF+, Vol. 10816: , (2018) , pp. 170–184. doi:10.1007/978-3-319-91563-0_11. |
[41] | J. Dean and S. Ghemawat, MapReduce: Simplified data processing on large clusters, Communications of the ACM 51: (1) ((2008) ), 107–113. doi:10.1145/1327452.1327492. |
[42] | Directorate-General for Communications Networks, Content and Technology (European Commission), The Gallup Organization. User language preferences online. Analytical Report, 2014, https://op.europa.eu/en/publication-detail/-/publication/7e48e109-2809-4616-b0e5-666a4884af11. |
[43] | D. Doychev, A. Lawlor, R. Rafter and B. Smyth, An analysis of recommender algorithms for online news, in: CLEF 2014 Conference and Labs of the Evaluation Forum: Information Access Evaluation Meets Multilinguality, Multimodality and Interaction, 15-18 September 2014, L. Cappellato, N. Ferro, M. Halvey and W. Kraaij, eds, Sheffield, United Kingdom, (2014) , pp. 177–184, http://ceur-ws.org/Vol-1180/CLEF2014wn-Newsreel-DoychevEt2014.pdf. |
[44] | D. Doychev, R. Rafter, A. Lawlor and B. Smyth, News recommenders: Real-time, real-life experiences, in: User Modeling, Adaptation and Personalization. UMAP 2015, F. Ricci, K. Bontcheva, O. Conlan and S. Lawless, eds, Lecture Notes in Computer Science, Vol. 9146: , Springer, (2015) , pp. 337–342. doi:10.1007/978-3-319-20267-9_28. |
[45] | B. Drury, J.J. Almeida and M.H.M. Morais, Magellan: An adaptive ontology driven “breaking financial news” recommender, in: 6th Iberian Conference on Information Systems and Technologies (CISTI 2011), IEEE, (2011) , pp. 1–6, https://ieeexplore.ieee.org/abstract/document/5974288. |
[46] | Y. Dun, K. Tu, C. Chen, C. Hou and X. Yuan, KAN: Knowledge-aware attention network for fake news detection, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35: , (2021) , pp. 81–89, https://ojs.aaai.org/index.php/AAAI/article/view/16080. |
[47] | S.K. Dwivedi and C. Arya, A survey of news recommendation approaches, in: 2016 International Conference on ICT in Business Industry & Government (ICTBIG), IEEE, (2016) , pp. 1–6. doi:10.1109/ICTBIG.2016.7892681. |
[48] | V.P. Dwivedi, C.K. Joshi, T. Laurent, Y. Bengio and X. Bresson, Benchmarking graph neural networks, 2020, arXiv preprint arXiv:2003.00982. |
[49] | L. Ehrlinger and W. Wöß, Towards a definition of knowledge graphs, in: Joint Proceedings of the Posters and Demos Track of the 12th International Conference on Semantic Systems – SEMANTiCS2016 and the 1st International Workshop on Semantic Change & Evolving Semantics (SuCCESS’16) Co-Located with the 12th International Conference on Semantic Systems (SEMANTiCS 2016), Leipzig, Germany, September 12–15, 2016, CEUR Workshop Proceedings, Vol. 1695: , CEUR-WS, (2016) , pp. 1–4, http://ceur-ws.org/Vol-1695/paper4.pdf. |
[50] | M. Färber, F. Bartscherer, C. Menne and A. Rettinger, Linked data quality of dbpedia, freebase, opencyc, Wikidata, and Yago, Semantic Web 9: (1) ((2017) ), 77–129. doi:10.3233/SW-170275. |
[51] | G. Farnadi, P. Kouki, S.K. Thompson, S. Srinivasan and L. Getoor, A fairness-aware hybrid recommender system, 2018, arXiv preprint arXiv:1809.09030. |
[52] | C. Feng, M. Khan, A.U. Rahman and A. Ahmad, News recommendation systems-accomplishments, challenges & future directions, IEEE Access 8: ((2020) ), 16702–16725. doi:10.1109/ACCESS.2020.2967792. |
[53] | F. Frasincar, J. Borsje and F. Hogenboom, Personalizing news services using semantic web technologies, in: E-Business Applications for Product Development and Competitive Growth: Emerging Technologies, IGI Global, (2011) , pp. 261–289. doi:10.4018/978-1-60960-132-4.ch013. |
[54] | F. Frasincar, J. Borsje and L. Levering, A semantic web-based approach for building personalized news services, International Journal of E-Business Research (IJEBR) 5: (3) ((2009) ), 35–53. doi:10.4018/jebr.2009082103. |
[55] | F. Frasincar, W. IJntema, F. Goossen and F. Hogenboom, A semantic approach for news recommendation, in: Business Intelligence Applications and the Web: Models, Systems and Technologies, IGI Global, (2012) , pp. 102–121. doi:10.4018/978-1-61350-038-5.ch005. |
[56] | P.M. Gabriel De Souza, D. Jannach and A.M. Da Cunha, Contextual hybrid session-based news recommendation with recurrent neural networks, IEEE Access 7: ((2019) ), 169185–169203. doi:10.1109/ACCESS.2019.2954957. |
[57] | J. Gao, X. Wang, Y. Wang and X. Xie, Explainable recommendation through attentive multi-view learning, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33: , (2019) , pp. 3622–3629. |
[58] | J. Gao, X. Xin, J. Liu, R. Wang, J. Lu, B. Li, X. Fan and P. Guo, Fine-grained deep knowledge-aware network for news recommendation with self-attention, in: 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), IEEE, (2018) , pp. 81–88. doi:10.1109/WI.2018.0-104. |
[59] | Y. Gao, Y.-F. Li, Y. Lin, H. Gao and L. Khan, Deep learning on knowledge graph for recommender system: A survey, 2020, preprint, arXiv:2004.00387. |
[60] | F. Getahun, J. Tekli, R. Chbeir, M. Viviani and K. Yetongnon, Relating RSS news/items, in: Web Engineering. ICWE 2009, M. Gaedke, M. Grossniklaus and O. Díaz, eds, Lecture Notes in Computer Science, Vol. 5648: , Springer, (2009) , pp. 442–452. doi:10.1007/978-3-642-02818-2_36. |
[61] | A. Gharahighehi, C. Vens and K. Pliakos, Fair multi-stakeholder news recommender system with hypergraph ranking, Information Processing & Management 58: (5) ((2021) ), 102663. doi:10.1016/j.ipm.2021.102663. |
[62] | S. Givon and V. Lavrenko, Predicting social-tags for cold start book recommendations, in: Proceedings of the Third ACM Conference on Recommender Systems, RecSys’09, Association for Computing Machinery, New York, NY, USA, (2009) , pp. 333–336. doi:10.1145/1639714.1639781. |
[63] | Google, Freebase data dumps, 2021, https://developers.google.com/freebase/data. |
[64] | F. Goossen, W. IJntema, F. Frasincar, F. Hogenboom and U. Kaymak, News personalization using the CF-IDF semantic recommender, in: Proceedings of the International Conference on Web Intelligence, Mining and Semantics, WIMS’11, Association for Computing Machinery, New York, NY, USA, (2011) , pp. 1–12. doi:10.1145/1988688.1988701. |
[65] | J.A. Gulla, L. Zhang, P. Liu, Ö. Özgöbek and X. Su, The adressa dataset for news recommendation, in: Proceedings of the International Conference on Web Intelligence, WI’17, Association for Computing Machinery, New York, NY, USA, (2017) , pp. 1042–1048. doi:10.1145/3106426.3109436. |
[66] | Q. Guo, F. Zhuang, C. Qin, H. Zhu, X. Xie, H. Xiong and Q. He, A survey on knowledge graph-based recommender systems, IEEE Transactions on Knowledge and Data Engineering ((2020) ). doi:10.1109/TKDE.2020.3028705. |
[67] | M. Harandi and J.A. Gulla, Survey of user profiling in news recommender systems, in: INRA@ RecSys, (2015) , pp. 20–26, http://ceur-ws.org/Vol-1542/paper3.pdf. |
[68] | T. Hassan, Trust and trustworthiness in social recommender systems, in: Companion Proceedings of the 2019 World Wide Web Conference, WWW’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 529–532. doi:10.1145/3308560.3317596. |
[69] | S. Hochreiter and J. Schmidhuber, Long short-term memory, Neural Computation 9: (8) ((1997) ), 1735–1780. doi:10.1162/neco.1997.9.8.1735. |
[70] | T. Hofmann, Latent semantic models for collaborative filtering, ACM Transactions on Information Systems (TOIS) 22: (1) ((2004) ), 89–115. doi:10.1145/963770.963774. |
[71] | F. Hogenboom, M. Capelle and M. Moerland, News recommendation using semantics with the Bing-SF-IDF approach, in: Advances in Conceptual Modeling. ER 2013, J. Parsons and D.K.W. Chiu, eds, Lecture Notes in Computer Science, Vol. 8697: , Springer, (2013) , pp. 160–169. doi:10.1007/978-3-319-14139-8_18. |
[72] | F. Hogenboom, D. Vandic, F. Frasincar, A. Verheij and A. Kleijn, A query language and ranking algorithm for news items in the hermes news processing framework, Science of Computer Programming 94: ((2014) ), 32–52. doi:10.1016/j.scico.2013.07.018. |
[73] | L. Hu, C. Li, C. Shi, C. Yang and C. Shao, Graph neural news recommendation with long-term and short-term interest modeling, Information Processing & Management 57: (2) ((2020) ), 102142. doi:10.1016/j.ipm.2019.102142. |
[74] | L. Hu, S. Xu, C. Li, C. Yang, C. Shi, N. Duan, X. Xie and M. Zhou, Graph neural news recommendation with unsupervised preference disentanglement, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, (2020) , pp. 4255–4264. doi:10.18653/v1/2020.acl-main.392. |
[75] | W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta and J. Leskovec, Open graph benchmark: Datasets for machine learning on graphs, Advances in neural information processing systems 33: ((2020) ), 22118–22133, https://proceedings.neurips.cc/paper/2020/hash/fb60d411a5c5b72b2e7d3527cfc84fd0-Abstract.html. |
[76] | X. Huang, Q. Fang, S. Qian, J. Sang, Y. Li and C. Xu, Explainable interaction-driven user modeling over knowledge graph for sequential recommendation, in: Proceedings of the 27th ACM International Conference on Multimedia, MM’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 548–556. doi:10.1145/3343031.3350893. |
[77] | Z. Huang, W. Chung, T.-H. Ong and H. Chen, A graph-based recommender system for digital library, in: Proceedings of the 2nd ACM/IEEE-CS Joint Conference on Digital Libraries, JCDL’02, Association for Computing Machinery, New York, NY, USA, (2002) , pp. 65–73. doi:10.1145/544220.544231. |
[78] | W. IJntema, F. Goossen, F. Frasincar and F. Hogenboom, Ontology-based news recommendation, in: Proceedings of the BT/ICDT Workshops, EDBT’10, Association for Computing Machinery, 2010th edn, New York, NY, USA, (2010) , pp. 1–6. doi:10.1145/1754239.1754257. |
[79] | D. Jannach, M. Zanker, A. Felfernig and G. Friedrich, Recommender Systems: An Introduction, Cambridge University Press, (2010) . |
[80] | G. Ji, S. He, L. Xu, K. Liu and J. Zhao, Knowledge graph embedding via dynamic mapping matrix, in: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Association for Computational Linguistics, (2015) , pp. 687–696. doi:10.3115/v1/P15-1067. |
[81] | S. Ji, S. Pan, E. Cambria, P. Marttinen and S.Y. Philip, A survey on knowledge graphs: Representation, acquisition, and applications, IEEE Transactions on Neural Networks and Learning Systems 33: (2) ((2021) ), 494–514. doi:10.1109/TNNLS.2021.3070843. |
[82] | J.J. Jiang and D.W. Conrath, Semantic similarity based on corpus statistics and lexical taxonomy, in: Proceedings of the 10th Research on Computational Linguistics International Conference, The Association for Computational Linguistics and Chinese Language Processing (ACLCLP), (1997) , pp. 19–33, https://aclanthology.org/O97-1002. |
[83] | K. Joseph and H. Jiang, Content based news recommendation via shortest entity distance over knowledge graphs, in: Companion Proceedings of the 2019 World Wide Web Conference, WWW’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 690–699. doi:10.1145/3308560.3317703. |
[84] | M. Karimi, D. Jannach and M. Jugovac, News recommender systems–survey and roads ahead, Information Processing & Management 54: (6) ((2018) ), 1203–1227. doi:10.1016/j.ipm.2018.04.008. |
[85] | Y. Kim, Convolutional neural networks for sentence classification, in: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), A. Moschitti, B. Pang and W. Daelemans, eds, Association for Computational Linguistics., Doha, Qatar, (2014) , pp. 1746–1751. doi:10.3115/v1/D14-1181. |
[86] | T.N. Kipf and M. Welling, Semi-supervised classification with graph convolutional networks, in: 5th International Conference on Learning Representations (ICLR-17), (2016) , arXiv:1609.02907. |
[87] | Y. Koren, R. Bell and C. Volinsky, Matrix factorization techniques for recommender systems, Computer 42: (8) ((2009) ), 30–37. doi:10.1109/MC.2009.263. |
[88] | S. Kumar and M. Kulkarni, Graph based techniques for user personalization of news streams, in: Proceedings of the 6th ACM India Computing Convention, Compute’13, Association for Computing Machinery, New York, NY, USA, (2013) . doi:10.1145/2522548.2523129. |
[89] | D.M.J. Lazer, M.A. Baum, Y. Benkler, A.J. Berinsky, K.M. Greenhill, F. Menczer, M.J. Metzger, B. Nyhan, G. Pennycook, D. Rothschild, M. Schudson, S.A. Sloman, C.R. Sunstein, E.A. Thorson, D.J. Watts and J. Zittrain, The science of fake news, Science 359: (6380) ((2018) ), 1094–1096. doi:10.1126/science.aao2998. |
[90] | C. Leacock and M. Chodorow, Combining local context and WordNet similarity for word sense identification, 1998. |
[91] | D. Lee, B. Oh, S. Seo and K.-H. Lee, News recommendation with topic-enriched knowledge graphs, in: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM’20, Association for Computing Machinery, New York, NY, USA, (2020) , pp. 695–704. doi:10.1145/3340531.3411932. |
[92] | J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P.N. Mendes, S. Hellmann, M. Morsey, P. Van Kleef, S. Auer and C. Bizer, Dbpedia–a large-scale, multilingual knowledge base extracted from Wikipedia, Semantic Web 6: (2) ((2015) ), 167–195. doi:10.3233/SW-140134. |
[93] | L. Li, D. Wang, T. Li, D. Knox and B. Padmanabhan, Scene: A scalable two-stage personalized news recommendation system, in: Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’11, Association for Computing Machinery, New York, NY, USA, (2011) , pp. 125–134. doi:10.1145/2009916.2009937. |
[94] | L. Li, D.-D. Wang, S.-Z. Zhu and T. Li, Personalized news recommendation: A review and an experimental investigation, Journal of Computer Science and Technology 26: (5) ((2011) ), 754. doi:10.1007/s11390-011-0175-2. |
[95] | M. Li and L. Wang, A survey on personalized news recommendation technology, IEEE Access 7: ((2019) ), 145861–145879. doi:10.1109/ACCESS.2019.2944927. |
[96] | Q. Li, X. Tang, T. Wang, H. Yang and H. Song, Unifying task-oriented knowledge graph learning and recommendation, IEEE Access 7: ((2019) ), 115816–115828. doi:10.1109/ACCESS.2019.2932466. |
[97] | D. Lin et al. An information-theoretic definition of similarity, in: Proceedings of the Fifteenth International Conference on Machine Learning, ICML’98, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, (1998) , pp. 296–304. doi:10.5555/645527.657297. |
[98] | Y. Lin, Z. Liu, M. Sun, Y. Liu and X. Zhu, Learning entity and relation embeddings for knowledge graph completion, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, Vol. 29: , AAAI Press, (2015) , pp. 2181–2187, https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/viewPaper/9571. |
[99] | B. Liu, Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Data-Centric Systems and Applications, Springer, (2007) . doi:10.1007/978-3-642-19460-3. |
[100] | D. Liu, J. Lian, S. Wang, Y. Qiao, J.-H. Chen, G. Sun and X. Xie, KRED: Knowledge-aware document representation for news recommendations, in: Fourteenth ACM Conference on Recommender Systems, Association for Computing Machinery, New York, NY, USA, (2020) , pp. 200–209. doi:10.1145/3383313.3412237. |
[101] | J. Liu, P. Dolan and E.R. Pedersen, Personalized news recommendation based on click behavior, in: Proceedings of the 15th International Conference on Intelligent User Interfaces, IUI’10, Association for Computing Machinery, New York, NY, USA, (2010) , pp. 31–40. doi:10.1145/1719970.1719976. |
[102] | Y. Liu, H. Li, A. Garcia-Duran, M. Niepert, D. Onoro-Rubio and D.S. Rosenblum, MMKG: Multi-modal knowledge graphs, in: The Semantic Web. ESWC 2019, P. Hitzler, M. Fernández, K. Janowicz, A. Zaveri, V. Gray, A.J.G. ad Lopez, A. Haller and K. Hammar, eds, Lecture Notes in Computer Science, Vol. 11503: , Springer, (2019) , pp. 459–474. doi:10.1007/978-3-030-21348-0_30. |
[103] | K.-C. Lo, S.-C. Dai, A. Xiong, J. Jiang and L.-W. Ku, All the wiser: Fake news intervention using user reading preferences, in: Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Association for Computing Machinery, New York, NY, USA, (2021) , pp. 1069–1072. doi:10.1145/3437963.3441696. |
[104] | W. Ma, M. Zhang, Y. Cao, W. Jin, C. Wang, Y. Liu, M. Ma and X. Ren, Jointly learning explainable rules for recommendation with knowledge graph, in: The World Wide Web Conference, WWW’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 1210–1221. doi:10.1145/3308558.3313607. |
[105] | V. Maidel, P. Shoval, B. Shapira and M. Taieb-Maimon, Evaluation of an ontology-content based filtering method for a personalized newspaper, in: Proceedings of the 2008 ACM Conference on Recommender Systems, RecSys’08, Association for Computing Machinery, New York, NY, USA, (2008) , pp. 91–98. doi:10.1145/1454008.1454024. |
[106] | J. McInerney, B. Lacker, S. Hansen, K. Higley, H. Bouchard, A. Gruson and R. Mehrotra, Explore, exploit, and explain: Personalizing explainable recommendations with bandits, in: Proceedings of the 12th ACM Conference on Recommender Systems, RecSys’18, Association for Computing Machinery, New York, NY, USA, (2018) , pp. 31–39. doi:10.1145/3240323.3240354. |
[107] | H. Mezni, Temporal knowledge graph embedding for effective service recommendation, IEEE Transactions on Services Computing ((2021) ). doi:10.1109/TSC.2021.3075053. |
[108] | T. Mikolov, I. Sutskever, K. Chen, G.S. Corrado and J. Dean, Distributed representations of words and phrases and their compositionality, in: Proceedings of the 26th International Conference on Neural Information Processing Systems, NIPS’13, Vol. 2: , (2013) , pp. 3111–3119, https://proceedings.neurips.cc/paper/2013/hash/9aa42b31882ec039965f3c4923ce901b-Abstract.html. |
[109] | V. Milea, F. Frasincar and U. Kaymak, tOWL: A temporal web ontology language, IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) 42: (1) ((2011) ), 268–281. doi:10.1109/TSMCB.2011.2162582. |
[110] | B.N. Miller, I. Albert, S.K. Lam, J.A. Konstan and J. Riedl, MovieLens unplugged: Experiences with an occasionally connected recommender system, in: Proceedings of the 8th International Conference on Intelligent User Interfaces, IUI’03, Association for Computing Machinery, New York, NY, USA, (2003) , pp. 263–266. doi:10.1145/604045.604094. |
[111] | G.A. Miller, WordNet: A lexical database for English, Communications of the ACM 38: (11) ((1995) ), 39–41. doi:10.1145/219717.219748. |
[112] | M. Moerland, F. Hogenboom, M. Capelle and F. Frasincar, Semantics-based news recommendation with SF-IDF+, in: Proceedings of the 3rd International Conference on Web Intelligence, Mining and Semantics, WIMS’13, Association for Computing Machinery, New York, NY, USA, (2013) , pp. 1–8. doi:10.1145/2479787.2479795. |
[113] | S. Mohseni, E. Ragan and X. Hu, Open issues in combating fake news: Interpretability as an opportunity, 2019, arXiv preprint arXiv:1904.03016. |
[114] | J. Möller, D. Trilling, N. Helberger and B. van Es, Do not blame it on the algorithm: An empirical assessment of multiple recommender systems and their impact on content diversity, Information, Communication & Society 21: (7) ((2018) ), 959–977. doi:10.1080/1369118X.2018.1444076. |
[115] | H. Mousselly-Sergieh, T. Botschen, I. Gurevych and S. Roth, A multimodal translation-based approach for knowledge graph representation learning, in: Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, Association for Computational Linguistics, (2018) , pp. 225–234. doi:10.18653/v1/S18-2027. |
[116] | N. Newman, R. Fletcher, A. Schulz, S. Andi, C.T. Robertson and R.K. Nielsen, Reuters Institute Digital News Report 2021. Reuters Institute for the Study of Journalism, 2021, https://reutersinstitute.politics.ox.ac.uk/digital-news-report/2021. |
[117] | Q.M. Nguyen, T.T. Nguyen and T.D. Cao, Semantic-based recommendation method for sport news aggregation system, in: Research and Practical Issues of Enterprise Information Systems. CONFENIS 2016, A. Tjoa, L. Xu, M. Raffai and N. Novak, eds, Lecture Notes in Business Information Processing, Vol. 268: , Springer, (2016) , pp. 32–47. doi:10.1007/978-3-319-49944-4_3. |
[118] | X. Ning and G. Karypis, Multi-task learning for recommender system, in: Proceedings of 2nd Asian Conference on Machine Learning, M. Sugiyama and Q. Yang, eds, Proceedings of Machine Learning Research, Vol. 13: , Tokyo, Japan, PMLR, (2010) , pp. 269–284, http://proceedings.mlr.press/v13/ning10a/ning10a.pdf. |
[119] | K. O’Hara and D. Stevens, Echo chambers and online radicalism: Assessing the Internet’s complicity in violent extremism, Policy & Internet 7: (4) ((2015) ), 401–422. doi:10.1002/poi3.88. |
[120] | Ö. Özgöbek, J.A. Gulla and R.C. Erdur, A survey on challenges and methods in news recommendation, in: Proceedings of the 10th International Conference on Web Information Systems and Technologies – Volume 2: WEBIST, (2014) , pp. 278–285. doi:10.5220/0004844202780285. |
[121] | J.Z. Pan, S. Pavlova, C. Li, N. Li, Y. Li and J. Liu, Content based fake news detection using knowledge graphs, in: The Semantic Web – ISWC 2018. ISWC 2018, D. Vrandečić, K. Bontcheva, M.C. Suárez-Figueroa, V. Presutti, I. Celino, M. Sabou, L.-A. Kaffee and E. Simperl, eds, Lecture Notes in Computer Science, Vol. 11136: , Springer, (2018) , pp. 669–683. doi:10.1007/978-3-030-00671-6_39. |
[122] | Y. Pang, J. Tong, Y. Zhang and Z. Wei, DACNN: Dynamic attentive convolution neural network for news recommendation, in: Proceedings of the 2020 5th International Conference on Mathematics and Artificial Intelligence, ICMAI 2020, Association for Computing Machinery, New York, NY, USA, (2020) , pp. 161–166. doi:10.1145/3395260.3395292. |
[123] | E. Pariser, The Filter Bubble: What the Internet Is Hiding from You, Penguin, UK, (2011) . |
[124] | D.H. Park, H.K. Kim, I.Y. Choi and J.K. Kim, A literature review and classification of recommender systems research, Expert systems with applications 39: (11) ((2012) ), 10059–10072. doi:10.1016/j.eswa.2012.02.038. |
[125] | K. Park, J. Lee and J. Choi, Deep neural networks for news recommendations, in: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, CIKM’17, Association for Computing Machinery, New York, NY, USA, (2017) , pp. 2255–2258. doi:10.1145/3132847.3133154. |
[126] | H. Paulheim, Knowledge graph refinement: A survey of approaches and evaluation methods, Semantic Web 8: (3) ((2017) ), 489–508. doi:10.3233/SW-160218. |
[127] | J. Pennington, R. Socher and C.D. Manning, Glove: Global vectors for word representation, in: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, (2014) , pp. 1532–1543. doi:10.3115/v1/D14-1162. |
[128] | Y. Qian, P. Zhao, Z. Li, J. Fang, L. Zhao, V.S. Sheng and Z. Cui, Interaction graph neural network for news recommendation, in: Web Information Systems Engineering – WISE 2019. WISE 2020, R. Cheng, N. Mamoulis, Y. Sun and X. Huang, eds, Lecture Notes in Computer Science, Vol. 11881: , Springer, (2019) , pp. 599–614. doi:10.1007/978-3-030-34223-4_38. |
[129] | J. Qin and P. Lu, Application of news features in news recommendation methods: A survey, in: Data Science. ICPCSEE 2020, P. Qin, H. Wang, G. Sun and Z. Lu, eds, Communications in Computer and Information Science, Vol. 1258: , Springer, (2020) , pp. 113–125. doi:10.1007/978-981-15-7984-4_9. |
[130] | J. Rao, A. Jia, Y. Feng and D. Zhao, Personalized news recommendation using ontologies harvested from the web, in: Web-Age Information Management. WAIM 2013, J. Wang, H. Xiong, Y. Ishikawa, J. Xu and J. Zhou, eds, Lecture Notes in Computer Science, Vol. 7923: , Springer, (2013) , pp. 781–787. doi:10.1007/978-3-642-38562-9_79. |
[131] | S. Raza and C. Ding, News recommender system considering temporal dynamics and news taxonomy, in: 2019 IEEE International Conference on Big Data (Big Data), IEEE, (2019) , pp. 920–929. doi:10.1109/BigData47090.2019.9005459. |
[132] | S. Raza and C. Ding, News recommender system: A review of recent progress, challenges, and opportunities, Artificial Intelligence Review 55: ((2021) ), 749–800. doi:10.1007/s10462-021-10043-x. |
[133] | R. Ren, L. Zhang, L. Cui, B. Deng and Y. Shi, Personalized financial news recommendation algorithm based on ontology, Procedia Computer Science 55: ((2015) ), 843–851. doi:10.1016/j.procs.2015.07.151. |
[134] | S. Rendle, C. Freudenthaler, Z. Gantner and L. Schmidt-Thieme, BPR: Bayesian personalized ranking from implicit feedback, in: Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, UAI’09, AUAI Press, Arlington, Virginia, USA, (2012) , https://dl.acm.org/doi/abs/10.5555/1795114.1795167. |
[135] | P. Resnik, Using information content to evaluate semantic similarity in a taxonomy, in: Proceedings of the 14th International Joint Conference on Artificial Intelligence – Volume 1, IJCAI’95, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, (1995) , https://dl.acm.org/doi/abs/10.5555/1625855.1625914. |
[136] | F. Ricci, L. Rokach and B. Shapira, Recommender systems: Introduction and challenges, in: Recommender Systems Handbook, F. Ricci, L. Rokach and B. Shapira, eds, Springer, Boston, MA, (2015) , pp. 1–34. doi:10.1007/978-1-4899-7637-6_1. |
[137] | S. Ruder, An overview of multi-task learning in deep neural networks, 2017, arXiv preprint arXiv:1706.05098. |
[138] | D. Ruffinelli, S. Broscheit and R. Gemulla, You can teach an old dog new tricks! On training knowledge graph embeddings, in: International Conference on Learning Representations, (2019) , https://openreview.net/pdf?id=BkxSmlBFvrs. |
[139] | G. Salton and C. Buckley, Term-weighting approaches in automatic text retrieval, Information processing & management 24: (5) ((1988) ), 513–523. doi:10.1016/0306-4573(88)90021-0. |
[140] | G. Salton, A. Wong and C.-S. Yang, A vector space model for automatic indexing, Communications of the ACM 18: (11) ((1975) ), 613–620. doi:10.1145/361219.361220. |
[141] | J.B. Schafer, J. Konstan and J. Riedl, Recommender systems in e-commerce, in: Proceedings of the 1st ACM Conference on Electronic Commerce, EC’99, Association for Computing Machinery, New York, NY, USA, (1999) , pp. 158–166. doi:10.1145/336992.337035. |
[142] | J.B. Schafer, J.A. Konstan and J. Riedl, E-commerce recommendation applications, Data mining and knowledge discovery 5: (1–2) ((2001) ), 115–153. doi:10.1023/A:1009804230409. |
[143] | B. Shao, X. Li and G. Bian, A survey of research hotspots and frontier trends of recommendation systems from the perspective of knowledge graph, Expert Systems with Applications 165: ((2021) ), 113764. doi:10.1016/j.eswa.2020.113764. |
[144] | H.-S. Sheu, Z. Chu, D. Qi and S. Li, Knowledge-guided article embedding refinement for session-based news recommendation, IEEE Transactions on Neural Networks and Learning Systems (2021), 1–7. doi:10.1109/TNNLS.2021.3084958. |
[145] | H.-S. Sheu and S. Li, Context-aware graph embedding for session-based news recommendation, in: RecSys 2020: Fourteenth ACM Conference on Recommender Systems, R.L.T. Santos, L.B. Marinho, E.M. Daly, L. Chen, K. Falk, N. Koenigstein and E.S. de Moura, eds, ACM, New York, NY, USA, (2020) , pp. 657–662. doi:10.1145/3383313.3418477. |
[146] | C. Shi, Z. Zhang, P. Luo, P.S. Yu, Y. Yue and B. Wu, Semantic path based personalized recommendation on weighted heterogeneous information networks, in: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, CIKM’15, Association for Computing Machinery, New York, NY, USA, (2015) , pp. 453–462. doi:10.1145/2806416.2806528. |
[147] | Y. Shi, M. Larson and A. Hanjalic, Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges, ACM Computing Surveys (CSUR) 47: (1) ((2014) ), 1–45. doi:10.1145/2556270. |
[148] | P. Shoval, V. Maidel and B. Shapira, An ontology-content-based filtering method, International Journal of Information Theories and Applications 15: (4) ((2008) ), 300–314, http://hdl.handle.net/10525/88. |
[149] | B. Smith and G. Linden, Two decades of recommender systems at amazon.com, IEEE internet computing 21: (3) ((2017) ), 12–18. doi:10.1109/MIC.2017.72. |
[150] | Y. Song, S. Shi, J. Li and H. Zhang, Directional skip-Gram: Explicitly distinguishing left and right context for word embeddings, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), (2018) , pp. 175–180. doi:10.18653/v1/N18-2028. |
[151] | F.M. Suchanek, G. Kasneci and G. Weikum, Yago: A core of semantic knowledge, in: Proceedings of the 16th International Conference on World Wide Web, WWW’07, Association for Computing Machinery, New York, NY, USA, (2007) , pp. 697–706. doi:10.1145/1242572.1242667. |
[152] | J. Sun, B. Shagar and M.D. Masum, MUKG: Unifying multi-task and knowledge graph method for recommender system, in: 2020 2nd International Conference on Image Processing and Machine Vision, IPMV 2020, Association for Computing Machinery, New York, NY, USA, (2020) , pp. 14–21. doi:10.1145/3421558.3421561. |
[153] | R. Sun, X. Cao, Y. Zhao, J. Wan, K. Zhou, F. Zhang, Z. Wang and K. Zheng, Multi-modal knowledge graphs for recommender systems, in: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM’20, Association for Computing Machinery, New York, NY, USA, (2020) , pp. 1405–1414. doi:10.1145/3340531.3411947. |
[154] | Y. Sun, J. Han, X. Yan, P.S. Yu and T. Wu, PathSim: Meta path-based top-k similarity search in heterogeneous information networks, Proceedings of the VLDB Endowment 4: (11) ((2011) ), 992–1003. doi:10.14778/3402707.3402736. |
[155] | Z. Sun, Q. Guo, J. Yang, H. Fang, G. Guo, J. Zhang and R. Burke, Research commentary on recommendations with side information: A survey and research directions, Electronic Commerce Research and Applications 37: ((2019) ), 100879. doi:10.1016/j.elerap.2019.100879. |
[156] | P. Symeonidis, L. Coba and M. Zanker, Counteracting the filter bubble in recommender systems: Novelty-aware matrix factorization, Intelligenza Artificiale 13: (1) ((2019) ), 37–47. doi:10.3233/IA-190017. |
[157] | A. Tchechmedjiev, P. Fafalios, K. Boland, M. Gasquet, M. Zloch, B. Zapilko, S. Dietze and K. Todorov, ClaimsKG: A knowledge graph of fact-checked claims, in: The Semantic Web – ISWC 2019. ISWC 2019, C. Ghidini, O. Hartig, M. Maleshkova, V. Svátek, I. Cruz, A. Hogan, J. Song, M. Lefrançois and F. Gandon, eds, Lecture Notes in Computer Science, Vol. 11779: , Springer, (2019) , pp. 309–324. doi:10.1007/978-3-030-30796-7_20. |
[158] | M. ter Hoeve, A. Schuth, D. Odijk and M. de Rijke, Faithfully explaining rankings in a news recommender system, 2018, arXiv preprint arXiv:1805.05447. |
[159] | S. Thoma, A. Rettinger and F. Both, Towards holistic concept representations: Embedding relational knowledge, visual attributes, and distributional word semantics, in: The Semantic Web – ISWC 2017, ISWC 2017, C. d’Amato, M. Fernandez, V. Tamma, F. Lecue, P. Cudré-Mauroux, J. Sequeda, C. Lange and J. Heflin, eds, Lecture Notes in Computer Science, Vol. 10587: , Springer, (2017) , pp. 694–710. doi:10.1007/978-3-319-68288-4_41. |
[160] | R. Troncy, Bringing the IPTC news architecture into the semantic web, in: The Semantic Web – ISWC 2008. ISWC 2008, A. Sheth, A. Staab, M. Dean, M. Paolucci, D. Maynard, T. Finin and K. Thirunarayan, eds, Lecture Notes in Computer Science, Vol. 5318: , Springer, (2008) , pp. 483–498. doi:10.1007/978-3-540-88564-1_31. |
[161] | L.H. van Huijsduijnen, T. Hoogmoed, G. Keulers, E. Langendoen, S. Langendoen, T. Vos, F. Hogenboom, F. Frasincar and T. Robal, Bing-CSF-IDF+: A semantics-driven recommender system for news, in: New Trends in Databases and Information Systems. ADBIS 2020, J. Darmont, B. Novikov and R. Wrembel, eds, CCIS of Communications in Computer and Information Science, Vol. 1259: , Springer, (2020) , pp. 143–153. doi:10.1007/978-3-030-54623-6_13. |
[162] | S. Vargas and P. Castells, Rank and relevance in novelty and diversity metrics for recommender systems, in: Proceedings of the Fifth ACM Conference on Recommender Systems, RecSys’11, Association for Computing Machinery, New York, NY, USA, (2011) , pp. 109–116. doi:10.1145/2043932.2043955. |
[163] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser and I. Polosukhin, Attention is all you need, in: Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, (2017) , pp. 5998–6008, https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html. |
[164] | N. Vo and K. Lee, The rise of guardians: Fact-checking url recommendation to combat fake news, in: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR’18, Association for Computing Machinery, New York, NY, USA, (2018) , pp. 275–284. doi:10.1145/3209978.3210037. |
[165] | N. Vo and K. Lee, Standing on the shoulders of guardians: Novel methodologies to combat fake news, in: Disinformation, Misinformation, and Fake News in Social Media, K. Shu, S. Wang, D. Lee and H. Liu, eds, Lecture Notes in Social Networks, Springer, (2020) , pp. 183–210. doi:10.1007/978-3-030-42699-6_10. |
[166] | M.M. Voit and H. Paulheim, Bias in knowledge graphs – an empirical study with movie recommendation and different language editions of DBpedia, in: 3rd Conference on Language, Data and Knowledge (LDK 2021), D. Gromann, G. Sérasset, T. Declerck, J.P. McCrae, J. Gracia, J. Bosque-Gil, F. Bobillo and B. Heinisch, eds, Open Access Series in Informatics (OASIcs), Vol. 93: , Dagstuhl, Germany, Schloss Dagstuhl – Leibniz-Zentrum für Informatik, (2021) , pp. 14:1–14:13. doi:10.4230/OASIcs.LDK.2021.14. |
[167] | D. Vrandečić and M. Krötzsch, Wikidata: A free collaborative knowledgebase, Communications of the ACM 57: (10) ((2014) ), 78–85. doi:10.1145/2629489. |
[168] | H. Wang, F. Zhang, J. Wang, M. Zhao, W. Li, X. Xie and M. Guo, Ripplenet: Propagating user preferences on the knowledge graph for recommender systems, in: Proceedings of the 27th ACM International Conference on Information and Knowledge Management, CIKM’18, Association for Computing Machinery, New York, NY, USA, (2018) , pp. 417–426. doi:10.1145/3269206.3271739. |
[169] | H. Wang, F. Zhang, J. Wang, M. Zhao, W. Li, X. Xie and M. Guo, Exploring high-order user preference on the knowledge graph for recommender systems, ACM Transactions on Information Systems 37: (3) ((2019) ), 1–26. doi:10.1145/3312738. |
[170] | H. Wang, F. Zhang, X. Xie and M. Guo, DKN: Deep knowledge-aware network for news recommendation, in: Proceedings of the 2018 World Wide Web Conference, WWW’18, International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, (2018) , pp. 1835–1844. doi:10.1145/3178876.3186175. |
[171] | H. Wang, F. Zhang, M. Zhang, J. Leskovec, M. Zhao, W. Li and Z. Wang, Knowledge-aware graph neural networks with label smoothness regularization for recommender systems, in: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 968–977. doi:10.1145/3292500.3330836. |
[172] | H. Wang, F. Zhang, M. Zhao, W. Li, X. Xie and M. Guo, Multi-task feature learning for knowledge graph enhanced recommendation, in: The World Wide Web Conference, WWW’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 2000–2010. doi:10.1145/3308558.3313411. |
[173] | Q. Wang, Z. Mao, B. Wang and L. Guo, Knowledge graph embedding: A survey of approaches and applications, IEEE Transactions on Knowledge and Data Engineering 29: (12) ((2017) ), 2724–2743. doi:10.1109/TKDE.2017.2754499. |
[174] | X. Wang, X. He, Y. Cao, M. Liu and T.-S.C. Kgat, Knowledge graph attention network for recommendation, in: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD’19, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 950–958. doi:10.1145/3292500.3330989. |
[175] | X. Wang, D. Wang, C. Xu, X. He, Y. Cao and T.-S. Chua, Explainable reasoning over knowledge graphs for recommendation, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33: , (2019) , pp. 5329–5336. doi:10.1609/aaai.v33i01.33015329. |
[176] | Z. Wang, W. Ma, M. Zhang, W. Chen, J. Xu, Y. Liu and S. Ma, Incorporating knowledge and content information to boost news recommendation, in: Natural Language Processing and Chinese Computing. NLPCC 2020, X. Zhu, M. Zhang, Y. Hong and R. He, eds, Lecture Notes in Computer Science, Vol. 12430: , Springer, (2020) , pp. 443–456. doi:10.1007/978-3-030-60450-9_35. |
[177] | Z. Wang, Z. Wang, J. Li and J.Z. Pan, Building a large scale knowledge base from Chinese wiki encyclopedia, in: The Semantic Web. JIST 2011, J.Z. Pan, H. Chen, H.-G. Kim, J. Li, Z. Wu, I. Horrocks, R. Mizoguchi and Z. Wu, eds, Lecture Notes in Computer Science, Vol. 7185: , Springer, (2011) , pp. 80–95. doi:10.1007/978-3-642-29923-0_6. |
[178] | Z. Wang, J. Zhang, J. Feng and Z. Chen, Knowledge graph embedding by translating on hyperplanes, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 28: , (2014) , https://ojs.aaai.org/index.php/AAAI/article/view/8870. |
[179] | D. Werner and C. Cruz, A method to manage the precision difference between items and profiles: In a context of content-based recommender system and vector space model, in: 2013 International Conference on Signal-Image Technology Internet-Based Systems, IEEE, (2013) , pp. 337–344. doi:10.1109/SITIS.2013.62. |
[180] | C. Wu, F. Wu, T. Qi and Y. Huang, Empowering news recommendation with pre-trained language models, in: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Association for Computing Machinery, New York, NY, USA, (2021) . doi:10.1145/3404835.3463069. |
[181] | C. Wu, F. Wu, X. Wang, Y. Huang and X. Xie, Fairrec: Fairness-aware news recommendation with decomposed adversarial learning, Proceedings of the AAAI Conference on Artificial Intelligence 35: (5) ((2021) ), 4462–4469. https://ojs.aaai.org/index.php/AAAI/article/view/16573. |
[182] | F. Wu, Y. Qiao, J.-H. Chen, C. Wu, T. Qi, J. Lian, D. Liu, X. Xie, J. Gao, W. Wu and M. Zhou, MIND: A large-scale dataset for news recommendation, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, (2020) , pp. 3597–3606. doi:10.18653/v1/2020.acl-main.331. |
[183] | S. Wu, W. Zhang, F. Sun and B. Cui, Graph neural networks in recommender systems: A survey, 2020, arXiv preprint arXiv:2011.02260. |
[184] | Z. Wu and M. Palmer, Verb semantics and lexical selection, in: Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics, ACL’94, Association for Computational Linguistics, USA, (1994) , pp. 133–138. doi:10.3115/981732.981751. |
[185] | Z. Xia, S. Xu, N. Liu and Z. Zhao, Hot news recommendation system from heterogeneous websites based on bayesian model, The Scientific World Journal (2014), 2014. doi:10.1155/2014/734351. |
[186] | Y. Xian, Z. Fu, S. Muthukrishnan, G. De Melo and Y. Zhang, Reinforcement knowledge graph reasoning for explainable recommendation, in: Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Association for Computing Machinery, New York, NY, USA, (2019) , pp. 285–294. doi:10.1145/3331184.3331203. |
[187] | C. Xiao, L. Sun and W. Ji, Temporal knowledge graph incremental construction model for recommendation, in: Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, X. Wang, R. Zhang, Y.K. Lee, L. Sun and Y.S. Moon, eds, Vol. 12317: , Springer, (2020) , pp. 352–359. doi:10.1007/978-3-030-60259-8_26. |
[188] | J. Yang, J. Wan, Y. Wang and Y. Mao, Social network-based news recommendation with knowledge graph, in: 2020 IEEE International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Vol. 1: , IEEE, (2020) , pp. 1255–1260. doi:10.1109/ICIBA50161.2020.9276847. |
[189] | S. Yao and B. Huang, Beyond parity: Fairness objectives for collaborative filtering, in: Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, (2017) , pp. 2925–2934. doi:10.5555/3294996.3295052. |
[190] | Z. Ying, D. Bourgeois, J. You, M. Zitnik and J.L. Gnnexplainer, Generating explanations for graph neural networks, Vol. 32, 2019, pp. 9240–9251. doi:10.5555/3454287.3455116. |
[191] | X. Yu, X. Ren, Y. Sun, B. Sturt, U. Khandelwal, Q. Gu, B. Norick and J. Han, Recommendation in heterogeneous information networks with implicit user feedback, in: Proceedings of the 7th ACM Conference on Recommender Systems, RecSys’13, Association for Computing Machinery, New York, NY, USA, (2013) , pp. 347–350. doi:10.1145/2507157.2507230. |
[192] | J. Zhang, B. Liu, J. Tang, T. Chen and J. Li, Social influence locality for modeling retweeting behaviors, in: Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, IJCAI’13, AAAI Press, (2013) . doi:10.5555/2540128.2540526. |
[193] | K. Zhang, X. Xin, P. Luo and P. Guot, Fine-grained news recommendation by fusing matrix factorization, topic analysis and knowledge graph representation, in: 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE, (2017) , pp. 918–923. doi:10.1109/SMC.2017.8122727. |
[194] | S. Zhang, L. Yao, A. Sun and Y. Tay, Deep learning based recommender system: A survey and new perspectives, ACM Computing Surveys (CSUR) 52: (1) ((2019) ), 1–38. doi:10.1145/3285029. |
[195] | Y. Zhang and Q. Yang, A survey on multi-task learning, IEEE Transactions on Knowledge and Data Engineering ((2017) ). doi:10.1109/TKDE.2021.3070203. |
[196] | J. Zhou, G. Cui, Z. Zhang, C. Yang, Z. Liu, L. Wang, C. Li and M. Sun, Graph neural networks: A review of methods and applications, AI Open 1: ((2020) ), 57–81. doi:10.1016/j.aiopen.2021.01.001. |
[197] | Q. Zhu, X. Zhou, Z. Song, J. Tan and L. Guo, Dan: Deep attention neural network for news recommendation, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33: , AAAI Press, Honolulu, Hawaii, USA, (2019) , pp. 5973–5980. doi:aaai.v33i01.33015973 |


