
MADLINK: Attentive multihop and entity descriptions for link prediction in knowledge graphs
Abstract
Knowledge Graphs (KGs) comprise of interlinked information in the form of entities and relations between them in a particular domain and provide the backbone for many applications. However, the KGs are often incomplete as the links between the entities are missing. Link Prediction is the task of predicting these missing links in a KG based on the existing links. Recent years have witnessed many studies on link prediction using KG embeddings which is one of the mainstream tasks in KG completion. To do so, most of the existing methods learn the latent representation of the entities and relations whereas only a few of them consider contextual information as well as the textual descriptions of the entities. This paper introduces an attentive encoder-decoder based link prediction approach considering both structural information of the KG and the textual entity descriptions. Random walk based path selection method is used to encapsulate the contextual information of an entity in a KG. The model explores a bidirectional Gated Recurrent Unit (GRU) based encoder-decoder to learn the representation of the paths whereas SBERT is used to generate the representation of the entity descriptions. The proposed approach outperforms most of the state-of-the-art models and achieves comparable results with the rest when evaluated with FB15K, FB15K-237, WN18, WN18RR, and YAGO3-10 datasets.
1.Introduction
Knowledge Graphs (KGs) have recently gained attention for representing structured knowledge about a particular domain. Since its advent, the Linked Open Data (LOD) cloud11 has constantly been growing containing many KGs about numerous different domains such as government, scholarly data, biomedical domain, etc. Apart from facilitating the inter-connectivity and interoperability of datasets in LOD cloud, KGs have been used in a variety of applications based on Machine Learning and Natural Language Processing (NLP) such as entity linking [18], question answering [5], recommender systems [60], etc. Some KGs are automatically generated from heterogeneous resources such as text, images, etc., whereas others are manually-curated. These KGs consist of huge amounts of facts in the form of entities (nodes) and relations (edges) between them. Also, the KGs contain facts in which the entities are connected to literals, i.e., text, numbers, images, etc. However, one of the major challenges is that KGs are sparse and often incomplete as the links between the entities are missing. To overcome these challenges, predicting the missing links between the entities is necessary.
Fig. 1.
An excerpt of the graph structure from DBpedia.
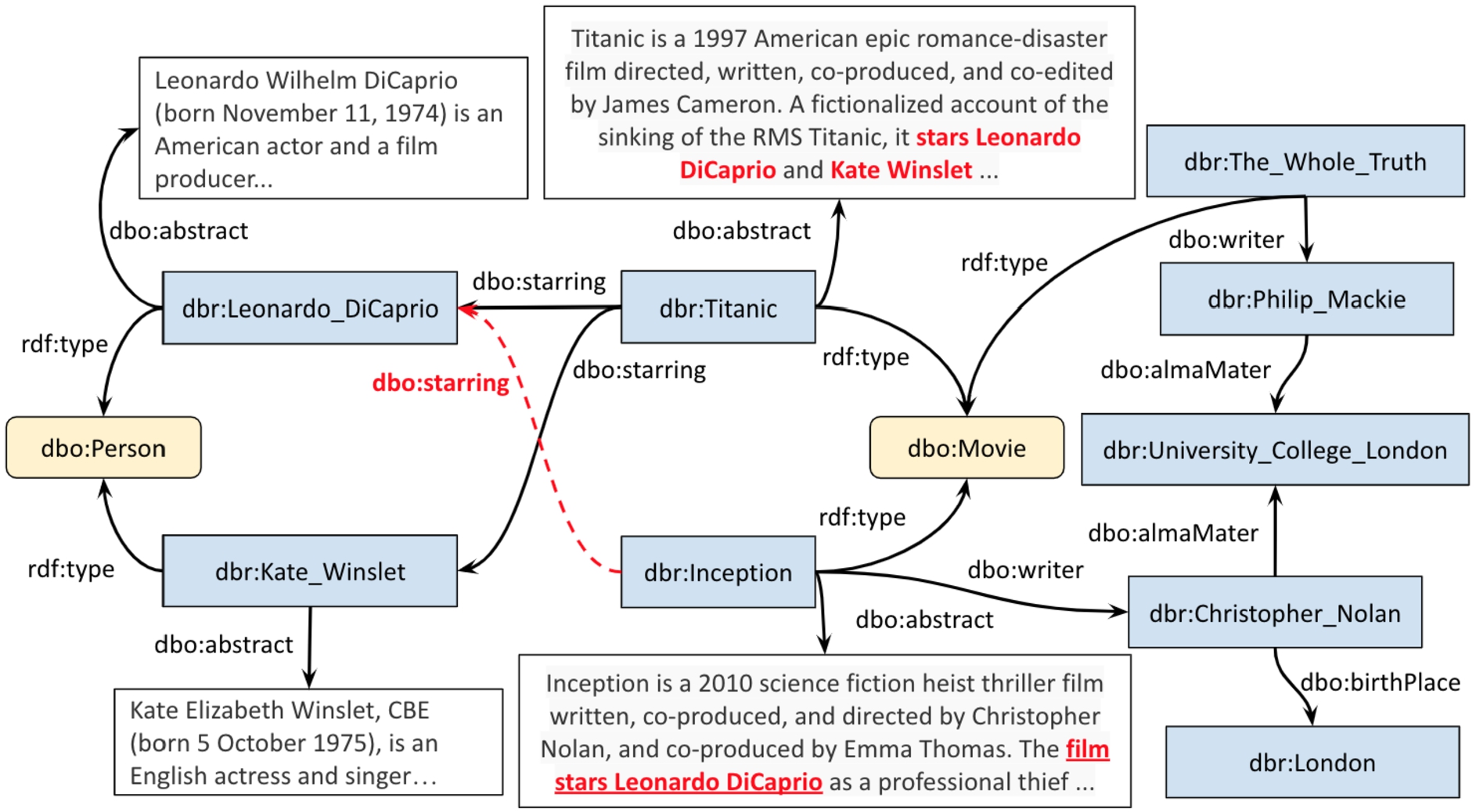
Link prediction is a fundamental task that aims to estimate the likelihood of the existence of edges (links) based on the current observed structure of a graph [63]. To-date many algorithms for generating KG embeddings have been proposed for the task of link prediction. Most of the state-of-the-art (SOTA) embedding models learn the vectors of the entities and relations from the triple information [6,19,21,50,55], i.e., only consider one hop information, whereas a very few of them explicitly take into account the neighbourhood information of an entity in the KG [14,38]. Also, only a handful of them consider the literal information available in the KGs [8,15,34,51,54].
The textual description of the entities in the KGs contains rich semantic information and the graph structure provides the contextual information of the entity from the neighboring nodes. The graph given in Fig. 1 contains information about some entities from DBpedia [1] and the relations between them. The textual entity description is given by the property dbo:abstract. In this graph, the information that dbr:Leonardo_DiCaprio and dbr:Kate_Winslet acted in the movie dbr: Titanic is given by the property dbo:starring. However, the dbo:starring information is missing for the movie dbr:Inception. But this information about dbo:starring is available in the textual entity description of the movie dbr:Inception given by the relation dbo:abstract which states ‘The film stars Leonardo DiCaprio as a professional thief.’ Therefore, the information present in the textual entity description plays a vital role in predicting the missing links.
On the other hand, as shown in Fig. 1, the movies dbr:Inception and dbr:The_Whole_Truth are written by dbr:Christopher_Nolan and dbr:Philip_Mackie respectively, as given by the relation dbo:writer. Also, both these writers have attended the same university dbr:University _College_London. Therefore, the movies dbr: Inception and dbr:The_Whole_Truth are similar in terms of being written by writers who went to the same university. This information from the graph is obtained by 2-hops starting from both source entities dbr:Inception and dbr:The_Whole_Truth and is given by
Primarily, link prediction is the task of predicting the head or tail entities in a triple in a KG. However, triple classification, i.e., the task of finding if a given triple is valid or not in a KG is also considered as link prediction as it determines the validity of links between two entities. This work proposes a novel method, MADLINK, which improves the task of link prediction by combining the graph walks and textual entity descriptions to better capture the semantics of entities and relations. The model also incorporates contextual information about the relations in the triples. MADLINK adapts the seq2seq [45] encoder-decoder architecture with attention layer to obtain a cumulative representation of the paths extracted for each entity from the KG. On the other hand, SBERT [37] has been used to extract the latent representations of the entity descriptions provided as natural language text. DistMult [57] is used as a base model to calculate the score of a triple for head or tail prediction.
The effectiveness of the model is evaluated with the benchmark datasets FB15K [6], FB15K-237 [47], WN18 [6], WN18-RR [12], and YAGO3-10 [12] against different SOTA models with and without entity descriptions. The results show that MADLINK outperforms most of the SOTA models whereas achieves comparable results with the rest. The main contributions of this paper are:
– A path selection approach is introduced by exploiting the importance of a relation w.r.t. an entity in the KG.
– The textual entity descriptions is combined with the contextual information of the entities extracted from the paths for better representation of entities and relations in KGs.
– An end-to-end attention based encoder-decoder framework is proposed to generate better representation of the paths of entities, relations as well as entity descriptions for the link prediction task.
The rest of the paper is organised as follows. To begin with, a review of the related work is provided in Section 2, followed by the problem formulation in Section 3. Section 4 accommodates the outline of the proposed approach followed by experimental results in Section 5. Finally, Section 6 concludes the paper with a brief discussion on future directions.
2.Related work
A large variety of KG embedding approaches have been proposed for the task of link prediction, such as
Translation-based models In TransE, given a triple
Semantic Matching Models (SME) SME is based on semantic matching using neural network architectures. Given a triple
Neural Network Based Models (NTN) NTN represents an entity using the average of the word embeddings in the entity name. ConvE uses 2D convolutional layers to learn the embeddings of the entities and relations in which the head entity and the relation embeddings are reshaped and concatenated which serves as an input to the convolutional layer. The resulting feature map tensor is then vectorized and projected into a k-dimensional space and matched with the tail embeddings using logistic sigmoid function minimizing the cross-entropy loss. In ConvKB, each triple
Path based models PTransE extends TransE by introducing a path based translation model. GAKE considers the contextual information in the graph by considering the path information starting from an entity. RDF2Vec uses random walks to consider the graph structure and applies word embedding model on the paths to learn the embeddings of the entities and the relations. However, the prediction of head or tail entities with RDF2Vec is non trivial because it is based on language modeling approach. PConvKB model extends the ConvKB model by exploiting the path information of the KGs. Additionally, it uses an attention mechanism to measure the local importance in relation paths.
Literal based models Another set of algorithms improve KG embeddings by taking into account different kinds of literals such as numeric, text or image literals and a detailed analysis of the methods is provided in [16].
Text based models DKRL extends TransE [6] by incorporating the textual entity descriptions in the model. The textual entity descriptions are encoded using a continuous bag-of-words approach as well as a deep convolutional neural network based approach. The energy function of the model is defined by
Other methods such as TransEA [51] and KBLRN [15] incorporate numeric literals into their embedding spaces. Also, MKBE is a multi-modal KG embedding model which includes the numeric, text and image literals present in KGs into their embedding spaces. However, in the aforementioned models the neighborhood node structure is not considered together with the textual entity descriptions to learn the embedding models. Therefore, this study proposes a novel model, MADLINK, which includes the contextual structural information as well as the entity descriptions into the embedding space for the task of Knowledge Graph Completion (KGC) using link prediction.
3.Problem formulation
Given a KG
– RQ1: Does the contextual information of entities and relations in a KG help in the task of link prediction?
– RQ2: What is the impact of incorporating textual entity descriptions in a KG for the task of link prediction?
4.MADLINK model
This section comprises a detailed step-wise description of the proposed model and the training approach. The model consists of two parts: (i) structural and (ii) textual representation. Path selection forms the primary step of the structural representation whereas textual representation is the encoding of the textual entity descriptions.
4.1.Path selection
A directed path in a directed labelled graph is a sequence of edges connecting a sequence of distinct vertices. Given a KG G, a path can be defined as
4.1.1.Predicate Frequency – Inverse Triple Frequency (PF-ITF)
In order to extract the contextual information related to an entity, paths consisting of l-hops are generated for each node. The properties are selected at each hop of the path using PF-ITF. Also, the cycles present in the KGs are straightened and considered as a flat path. Given a KG G, the predicate frequency of outgoing edges is given by
Next, the relations per entity are ranked based on the PF-ITF score. The PF-ITF value increases proportionally with the number of outgoing edges of an entity w.r.t. a relation and is offset by the total number of triples containing the relation which helps to adjust the relations which appear more frequently in general. The highest PF-ITF score of a relation w.r.t. an entity indicates that the triples containing this relation have more information content compared to the rest. Based on the ranks, top-n relations are selected for each entity. Thereafter, paths are generated for the entities in the KG and crawled iteratively until
4.2.Textual representation
The textual descriptions of an entity provide semantic information. These descriptions are of variable length and are often short, i.e., less than or equal to 3 words. The textual entity descriptions are encoded into a vector representation. Also, an enormous amount of text data is available outside the KGs which can be leveraged for better representation of the entities. The static pre-trained language models such as Word2Vec [26], GloVe [33], etc. as well as the contextual embedding model such as BERT [13] have been extensively used to generate latent representations of Natural Language Text. BERT applies transformers which is an attention-based mechanism to learn contextual relations between the words and/or sub-words in a text. The transformer encoder reads the entire sequence of words at once which allows the model to learn the context of a word based on its surroundings.
Sentence-BERT (SBERT) [37] is a modification of BERT which provides more semantically meaningful sentence embeddings using Siamese and triplet networks. As mentioned in [37], independent sentence embeddings are not computed in BERT. The semantically similar sentences cannot be compared using cosine similarity. Therefore, sentence embeddings are obtained by averaging the outputs to derive a fixed-size vector [36,58]. This is similar to average word embeddings generated by static models such as GloVe. However, it is also observed by the authors in [37] that the average BERT embeddings perform worse than average GloVe embeddings for various tasks, such as textual similarity, Wikipedia Sections Distinction, etc. SBERT model tackles all the above mentioned problems.
SBERT fine-tunes the BERT model using the siamese and triplet networks to update the weights such that the resulting sentence embeddings are semantically meaningful and semantically similar sentences appear closer to each other in the embedding space. It is fine-tuned with a 3-way softmax classifier objective function for one epoch. The two input sentences (say u and v) to the SBERT model are passed through the BERT model followed by a pooling layer namely, CLS-token, MEAN-strategy, and MAX-strategy are appended on top of it. This pooling layer enables the generation of a fixed-size representation for the input sentences. It is then concatenated with the element-wise difference and multiplied with a trainable weight, W, and is optimized using cross-entropy loss. In order to encode the semantics, the twin network is fine-tuned on Semantic Textual Similarity data. SBERT model is first trained on Wikipedia via BERT and then fine-tuned on Natural Language Inference (NLI) data. NLI is a collection of 1,000,000 sentence pairs created by combining The Stanford Natural Language Inference (SNLI)22 and Multi-Genre NLI (MG.NLI) datasets.
Also, [37] shows that the sentence embeddings generated by SBERT outperform BERT for SentEval toolkit, which is popularly used to evaluate the quality of sentence embeddings. In this work, the sentence embeddings from the pre-trained SBERT model which are fine-tuned with SNLI and STS datasets, are extracted. It follows the same approach as followed in [37] for SentEval. Therefore, two sentences are not required as input to obtain the sentence embeddings. In this work, the input to the SBERT model is only the entity descriptions. The similar entities in the KG should have similar textual entity descriptions and hence the embedding obtained for the entity descriptions should exhibit similar characteristics. SBERT is designed to minimize the distance between two semantically similar sentences in the embedding space. Therefore, SBERT is leveraged in this work, to obtain similar encoding of the entity descriptions for similar entities. Also, the authors of [37] fine-tune Roberta with the same approach as SBERT and the result shows that the performance of SRoberta and SBERT are almost similar for different tasks and they outperform their respective base models. Furthermore, SBERT outperforms SRoberta in some of the tasks [37]. Also, the model used in this work is SBERT-SNLI-STS-base model which outperforms SRoberta-SNLI-STS-base model as shown in [37].
The sentence embeddings obtained from SBERT model lose the domain-specific knowledge as it is trained and fine-tuned with two different datasets. Therefore, these sentence embeddings generated by SBERT perform better for a wide variety of tasks. In this work, to encode the textual description of the entities in a KG, the default pooling method of SBERT model, i.e., the MEAN pooling has been used and the entire entity description is considered as one sentence. The fine-tuning of the original BERT model with the textual entity descriptions from both the datasets has not been performed because the original BERT model is trained with Wikipedia and these textual entity descriptions are the abstracts of the Wikipedia articles. Therefore, further fine-tuning would have resulted in overfitting. Since SBERT is already fine-tuned with SNLI data, we opted for this model.
4.3.Encoder – decoder framework
In this work, a sequence-to-sequence (seq2seq) learning-based encoder-decoder model [45] is adapted to learn the representation of the path vectors in the KGs, the description vectors as well as the relation vectors. Figure 2 depicts the encoder-decoder architecture to generate the path embeddings.
Fig. 2.
Encoder – decoder framework for paths.
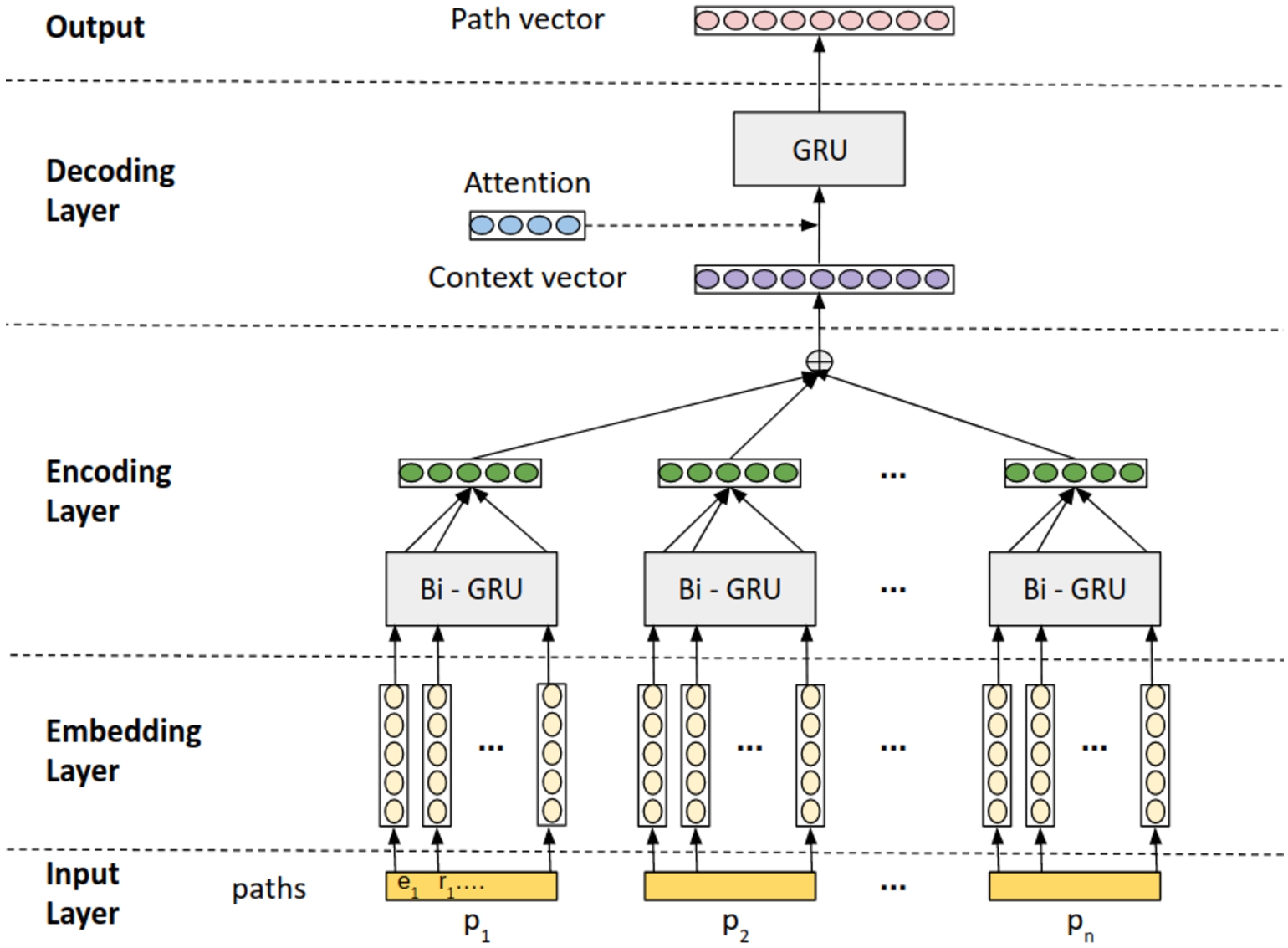
Encoder The encoder aims at encoding the entire input sequence into a fixed length vector called a context vector. A path
Self-attention An attention mechanism allows a neural network to focus on a subset of its inputs or features and is given by,
Fig. 3.
Illustration of the attention for a path in predicting the ‘dbo:musicComposer’ for the movie Inception.
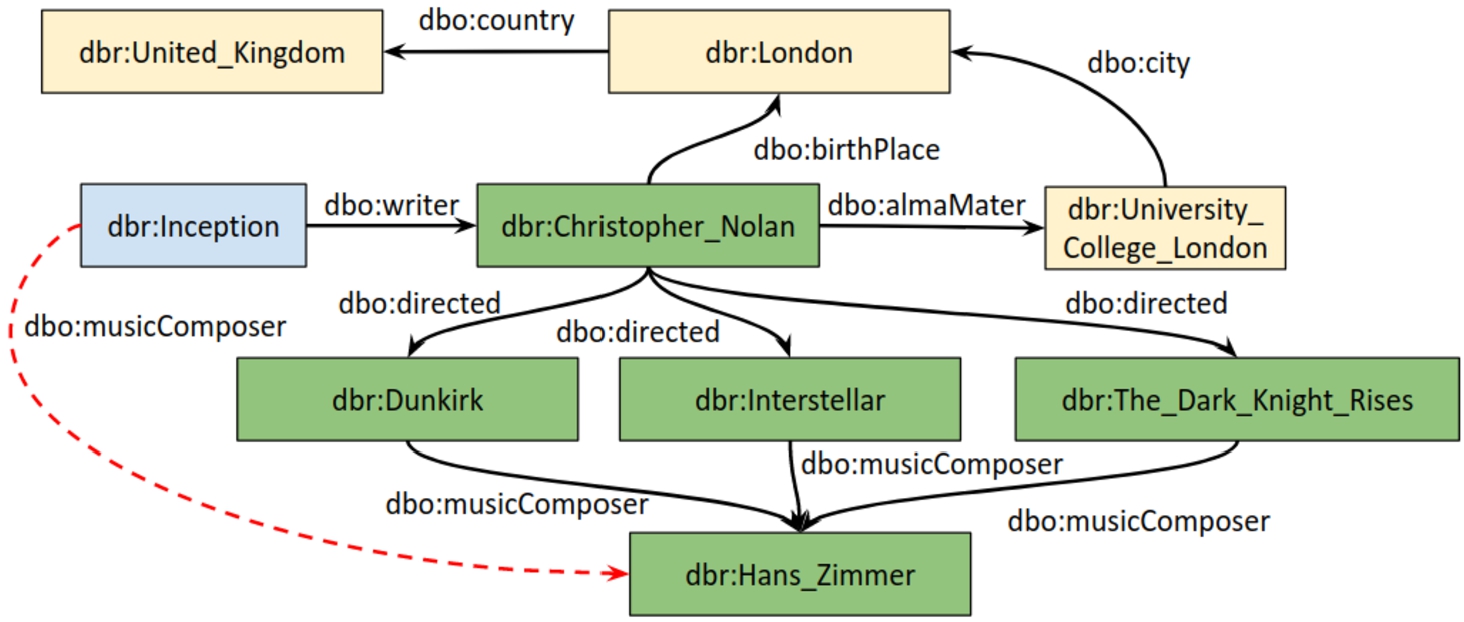
As the attention mechanism, the scaled dot product self attention [49] is used because it is much faster and is more space-efficient. Queries and keys of dimension
In terms of the MADLINK model, for a given word or relation x the above equation can be rewritten as,
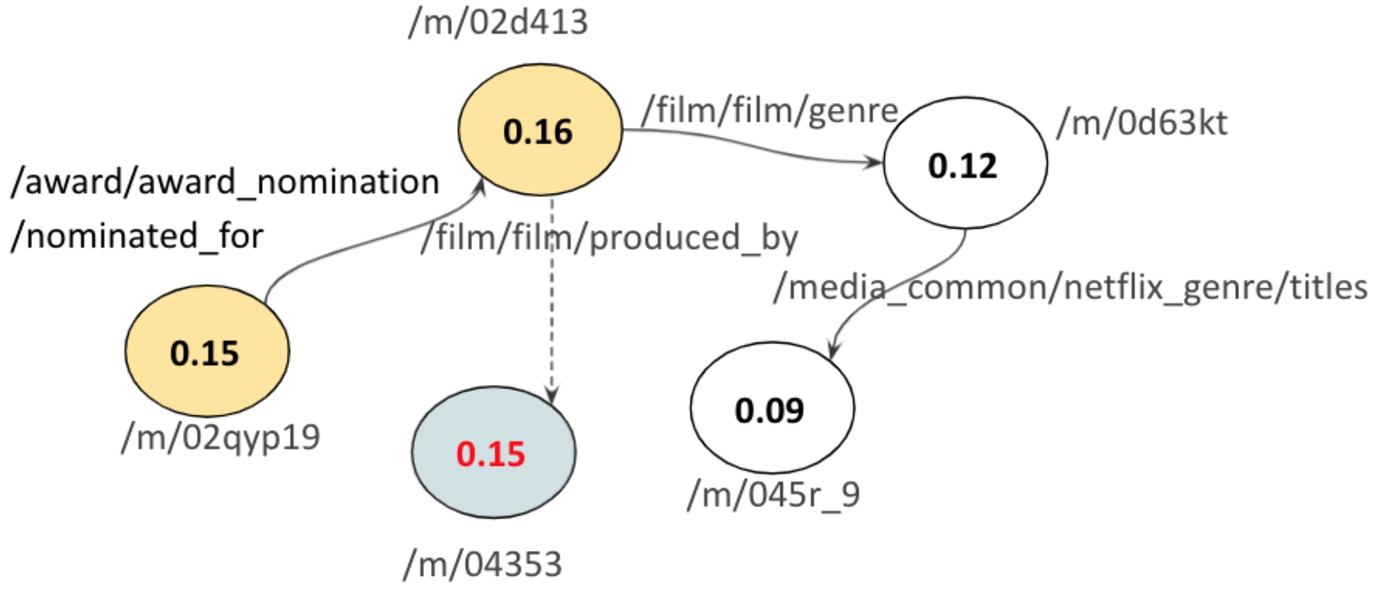
Fig. 4.
Illustration of the attention weights for an excerpt from FB15k.
Decoder The attention layer forms a bridge between the path embeddings and the input path sequences. The decoder network is initialized with the attention weights and the context vector which is then fed to a layer of GRU to obtain the final Path Vector for each entity. Therefore, this Path Vector gives a representation of the entity. Figure 2 illustrates the encoder-decoder architecture used in the paper.
The main advantage of using this seq2seq based encoder-decoder in the MADLINK architecture is that it can generate output sequence after seeing the entire input. The attention mechanism allows focusing on specific parts of the input automatically to help generate a useful encoding, even for longer input. Therefore, the proposed MADLINK model looks into all the input paths for a certain entity, focuses on the specific parts of the input, and then generates an encoding for the entity.
Fig. 5.
Overall architecture of the MADLINK model.
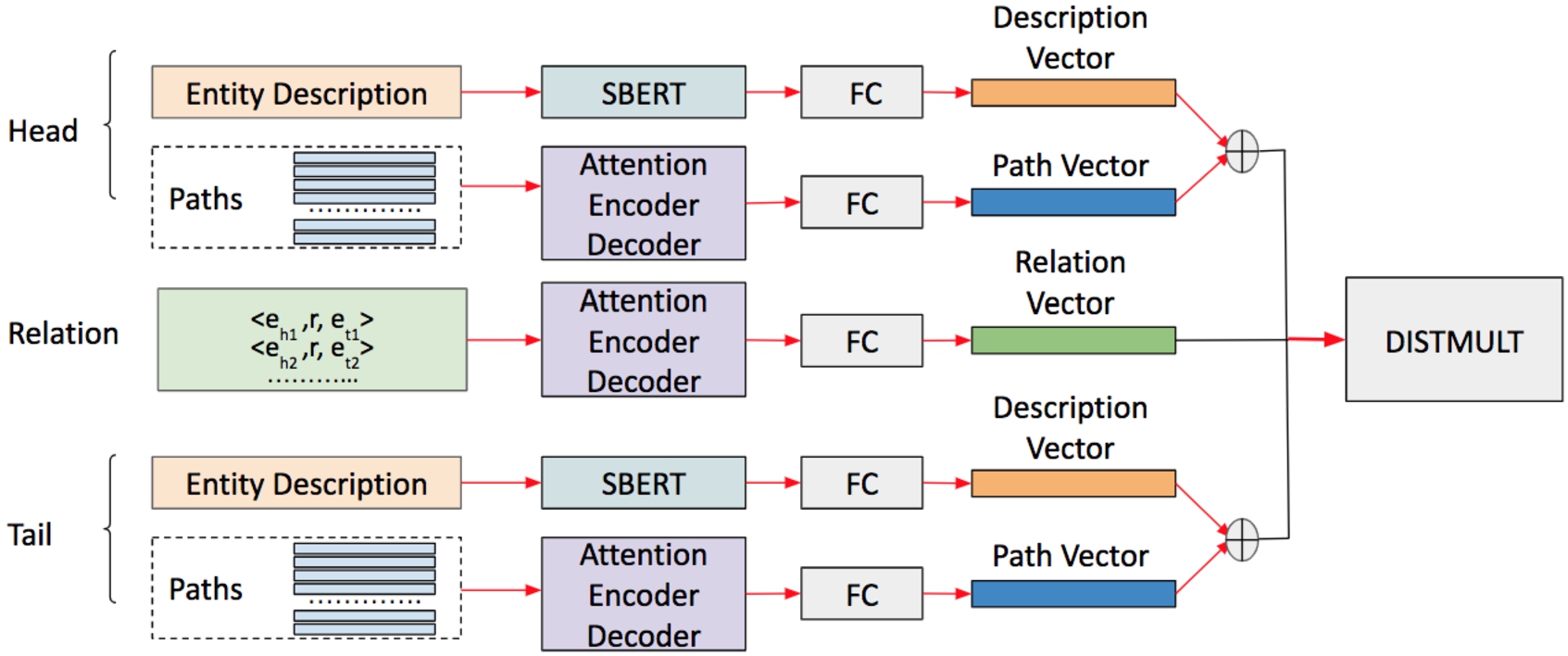
4.4.Overall training
Given a triple
In this work, DistMult is used as the final scoring function of the model. The model uses a simplification of bilinear interaction between the entities and the relations. DistMult model uses the trilinear dot product as a scoring function
5.Experiments and results
This section discusses the benchmark datasets and the experiments conducted for showing the feasibility of MADLINK and its empirical evaluation on two KGC tasks, namely, link prediction, i.e., head or tail prediction and triple classification.
Table 1
Statistics of the benchmark datasets
| Datasets | FB15K | FB15K-237 | WN18 | WN18RR | YAGO3-10 |
| #Entities | 14,951 | 14,541 | 40,943 | 40,943 | 123,182 |
| #Relations | 1,345 | 237 | 18 | 11 | 37 |
| #Entities with Description | 14,515 | 14,541 | 40,943 | 40,943 | 107,326 |
| Train set | 483,142 | 272,115 | 141,441 | 86,834 | 1,079,040 |
| Test Set | 59,071 | 20,466 | 5,000 | 3,134 | 5,000 |
| Valid Set | 50,000 | 17,535 | 5,000 | 3,034 | 5,000 |
5.1.Datasets
The statistics of the datasets FB15K, FB15K-237, WN18, WN18RR, and YAGO3-10 used for the purpose of the evaluation are provided in Table 1. FB15K is a dataset extracted from large scale cross-domain KG, Freebase [4]. As mentioned in [12,47], FB15K has 80.9% test leakage, i.e., a large number of test triples are obtained by inverting the triples of the test set. For example, <Republic, /government/form_of_government/countries, Paraguay> is a triple from the training set of FB15K and its inverse <Paraguay,
YAGO3-10 [12] is extracted from the large scale cross-domain KG, YAGO [43]. It consists of those entities having at least 10 relations in YAGO. The authors state that the majority of triples in YAGO are the properties of people such as citizenship or gender. The poor performance of the inverse model ConvE [12] on YAGO3-10 implies that it is free from test leakage [39]. Therefore, it is observed, that most of the recent KG embedding models designed for the task of link prediction are evaluated on the FB15k-237 and WN18RR instead of FB15k and WN18. However, the proposed model MADLINK has been evaluated on all the aforementioned 5 benchmark datasets. Besides, MADLINK model uses textual entity descriptions along with the structural information of entities.
5.2.Experimental setup
In the path selection process, the following parameters are used: number of hops 4, and number of paths per entity 1000. The hyper-parameters used in the MADLINK model are as follows: the dimension of SBERT vectors 1024, a learning rate of the encoder – decoder framework 0.001, batch size 100, loss margin 1, dropout 0.5. In the pre-processing step of the textual entity description, only punctuation removal is done. The experiments with MADLINK have been performed on an Ubuntu 16.04.5 LTS system with 503GiB RAM. The training with DistMult, SBERT, and the encoder-decoder framework is performed with TITAN X (Pascal) GPU.
5.3.Hyper-parameter optimization
The hyper-parameter optimization is performed using grid search as provided in [10] and the hyper-parameters are selected with the best performance on the validation dataset. For all the benchmark datasets, the search space provided in Table 2 and the hyper-parameters used are provided in Table 3. Adam optimizer is used for the base model.
Table 2
Hyper-parameter search space for MADLINK
| Hyper-parameters | Range |
| Batches | |
| Epochs | |
| Embedding Size | |
| Eta (η) | |
| Loss | Multiclass NLL |
| Regularizer Type | |
| Regularizer ( | |
| Optimizer param ( | |
| Optimizer param ( |
Table 3
Optimized hyper-parameters used in the training of MADLINK
| Parameters | FB15K | FB15K-237 | WN18 | WN18RR | YAGO3-10 |
| Batches | 64 | 64 | 64 | 64 | 100 |
| Embedding Size | 150 | 150 | 150 | 150 | 150 |
| Epochs | 1000 | 1000 | 1000 | 1000 | 1000 |
| Learning Rate ( | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| Regularizer | L3 | L3 | L3 | L3 | L3 |
| Regularizer ( | 1e–4 | 1e–4 | 1e–5 | 1e–5 | 1e–4 |
| Optimizer param ( | 0.001 | 0.001 | 0.01 | 0.01 | 0.001 |
| Optimizer param ( | 1e–3 | 1e–3 | 1e–3 | 1e–3 | 1e–3 |
| Loss | Multiclass NLL | Multiclass NLL | Multiclass NLL | Multiclass NLL | Multiclass NLL |
5.4.Link prediction
Formally, link Prediction is a sub-task of KGC which aims at predicting the missing head
Evaluation metrics Following the model in [6] the evaluation metrics used are as follows: (1) Mean Reciprocal Rank (MRR) is the average of the reciprocal ranks of the correct entities, and (2) Hits@k is the proportion of the correct entities in top-k predictions. To evaluate most of the embedding models, negative sampling is used to generate corrupted triples by removing either the head or the tail entity. In doing so, some of the generated corrupted triples might actually occur in the KG and should be considered as a valid triple. Therefore, all the triples which are true and are present in the training, test, and validation set are removed from the corrupted triples set and is termed as ‘filtered’ setting in the evaluation. Also, the triples containing unseen entities are removed from the test and the validation sets.
Baselines The effectiveness of the proposed model, MADLINK, is illustrated by comparing with the following baseline models. These baselines are selected based on the diversity of the nature of the embedding models such as translation-based, neural network-based, textual entity description-based, rotational-based, etc.
– TransE [6] is a translation-based embedding model.
– DistMult [57] is bilinear diagonal model.
– ConvE [12] is a CNN-based embedding model.
– ConvKB [29] is also a CNN-based embedding model in which each triple is represented by a 3-column matrix which is then fed to a convolution layer to generate different feature maps. These feature maps are then concatenated into a single feature vector representing the input triple.
– DKRL [54] and Jointly (ALSTM) [56] are textual entity description-based embedding models. The former uses a CNN approach, whereas the latter uses an LSTM.
– RotatE [44] is a model which defines each relation as a rotation from the source to the target entity in the complex vector space. The authors propose a self adversarial negative sampling technique for the model.
– HypER [2] uses a hyper network to generate 1D relation specific vectors convolutional filter weights for each relation which is then used by another network to enable weight sharing across layers.
– R-GCN [41] is a relation aware Graph Convolutional Network, in which the encoder learns the latent representation of the entities and the decoder is a tensor factorization model exploiting these representations for the task of link prediction.
– QuatE [61]. In Quaternion embeddings, hyper complex-valued embeddings with three imaginary components, are utilized to represent entities. Relations are modelled as rotations in the quaternion space.
– MDE [40] (Multiple Distance Embedding model) is a framework to collaboratively combine variant latent distance-based terms by using a limit-based loss and by learning independent embedding vectors. It uses a neural network model that allows the mapping of nonlinear relations between the embedding vectors and the expected output of the score function.
– TuckER [3] model is based on Tucker decomposition of the third-order binary tensor of triples. Tucker decomposition factorizes a tensor into a core tensor multiplied by a matrix along with each mode.
– KG-BERT [59] and Multi-task BERT [22] are the two models which exploit the working principle of the contextual language model BERT to predict missing links in a KG.
– BLP-TransE is one of the models proposed in Inductive Entity Representations from Text via link prediction [11], in which entity representations are generated from their textual entity descriptions using BERT and different KG embedding models such as TransE, DistMult, etc., are used on top of it for the task of link prediction.
– LiteralE [23] is a literal embedding model which uses DistMult, ConvE, and ComplEx as the base model. The main model is based on numeric literal which is easily extendable with text and image literal.
– SSP [52], the Semantic Space Projection (SSP) model jointly learns from the symbolic triples and textual descriptions which uses TransE as the base model. It follows the principle that triple embedding is considered always as the main procedure and textual descriptions must interact with triples in order to learn better representation. Therefore, triple embedding is projected onto a semantic subspace such as a hyperplane to allow strong correlation by adopting quadratic constraint.
5.4.1.Results
The proposed model MADLINK is compared against the aforementioned baseline models on the 5 benchmark datasets FB15k, FB15K-237, WN18, WN18RR, and YAGO3-10 as depicted in Tables 4, 5, and 6. In these tables, MADLINK1 represents the results of the experiments in which the entities without textual entity descriptions are removed, whereas MADLINK2 represents the results of the experiments containing all the entities in the datasets.
Table 4
Comparison of MADLINK results with the textual entity description-based baseline models on the 4 benchmark datasets1
| Models | MRR | Hits@1 | Hits@3 | Hits@10 |
| FB15K-237 | ||||
| DKRL | 0.19 | 0.11 | 0.167 | 0.215 |
| Jointly(ALSTM) | 0.21 | 0.19 | 0.21 | 0.258 |
| KG-BERT | 0.237 | 0.144 | 0.26 | 0.427 |
| Multitask-BERT | 0.267 | 0.172 | 0.298 | 0.458 |
| BLP-TransE | 0.195 | 0.113 | 0.213 | 0.363 |
| MADLINK1 | 0.347 | 0.252 | 0.38 | 0.529 |
| MADLINK2 | 0.341 | 0.249 | 0.377 | 0.52 |
| WN18RR | ||||
| DKRL | 0.112 | 0.05 | 0.146 | 0.288 |
| Jointly(ALSTM) | 0.21 | 0.112 | 0.156 | 0.31 |
| KG-BERT | 0.219 | 0.095 | 0.243 | 0.497 |
| Multitask-BERT | 0.331 | 0.203 | 0.383 | 0.597 |
| BLP-TransE | 0.285 | 0.135 | 0.361 | 0.580 |
| MADLINK1 | 0.477 | 0.438 | 0.479 | 0.549 |
| MADLINK2 | 0.471 | 0.43 | 0.469 | 0.535 |
| FB15K | ||||
| DKRL | 0.311 | 0.192 | 0.359 | 0.548 |
| Jointly(ALSTM) | 0.345 | 0.21 | 0.412 | 0.65 |
| SSP | – | – | – | 0.771 |
| MADLINK1 | 0.712 | 0.722 | 0.788 | 0.81 |
| MADLINK2 | 0.69 | 0.714 | 0.78 | 0.798 |
| WN18 | ||||
| DKRL | 0.51 | 0.31 | 0.542 | 0.61 |
| Jointly(ALSTM) | 0.588 | 0.388 | 0.596 | 0.77 |
| SSP | – | – | – | 0.932 |
| MADLINK1 | 0.95 | 0.898 | 0.911 | 0.96 |
| MADLINK2 | 0.944 | 0.88 | 0.9 | 0.9 |
| YAGO3-10 | ||||
| DKRL | 0.19 | 0.119 | 0.234 | 0.321 |
| Jointly(ALSTM) | 0.22 | 0.296 | 0.331 | 0.41 |
| MADLINK1 | 0.538 | 0.457 | 0.580 | 0.68 |
| MADLINK2 | 0.528 | 0.447 | 0.573 | 0.67 |
1The results marked in bold are the best results and the underlined ones are the second best.’-’ is provided if the corresponding results are not available in the respective papers.
5.4.2.Comparison with textual entity description-based baseline models
It is to be noted that, out of the above-mentioned baselines, DKRL, Jointly(ALSTM), KG-BERT, Multitask-BERT, and BLP-TransE use textual entity descriptions as to their features for link prediction. Therefore, these models form the primary baseline for our proposed model MADLINK as shown in Table 4. For FB15K-237 dataset, MADLINK1 outperforms the SOTA models for all the metrics with an improvement of 8% for MRR and Hits@1, 8.2% for Hits@3, and 7.1% for Hits@10 better than the best baseline model Multitask-BERT. Both DKRL and Jointly(ALSTM) models have the same experimental setup as MADLINK2 variant, in which the models are trained on datasets that contain entities without text descriptions. MADLINK2 variant outperforms DKRL with an increase of 15.1% on MRR, 13.1% on Hits@1, 21% on Hits@3, and 30.5% on Hits@10. Also, the proposed model outperforms the Jointly(ALSTM) model by 13.1% increase on MRR, 5.9%, 16.7%, and 26.2% on Hits@1, Hits@3, and Hits@10 respectively. For WN18RR, MADLINK outperforms the baseline models with considerable improvement with all the metrics except for Hits@10. Multi-task BERT model performs best for the WN18RR dataset for Hits@10, whereas for other metrics MADLINK outperforms the same model with an improvement of 14.6% on MRR, 23.5% on Hits@1, and 9.6% on Hits@3. Furthermore, both the variants of MADLINK considerably outperform all the baseline models DKRL, Jointly(ALSTM), KG-BERT, and BLP-TransE.
The models KG-BERT, Multitask-BERT, and BLP-TransE have not been evaluated on FB15k, WN18 due to test leakage problem in the original papers [59]. Therefore, MADLINK is compared against the DKRL and Jointly(ALSTM) models. It is noted that both the MADLINK variants significantly outperform both the text-based baseline models for all the metrics. Similarly, for YAGO3-10 dataset, both the MADLINK variants show major improvement from both the baselines.
It is to be noted that all the aforementioned text-based KG embedding models, such as DKRL, and Jointly (ALSTM), exploit the structural information of the KG in form of triples explicitly together with the textual entity descriptions. However, KG-BERT and Multitask-BERT use the triple information implicitly as the triples are considered as input sentences to the BERT model. On the other hand, in BLP-TransE, the textual entity and relation representations are provided as input to the TransE model in form of triple inputs. Therefore, the results infer that the textual entity descriptions together with the structural information captured via the paths in the MADLINK model capture better semantics of the KG for the task of link prediction.
Table 5
Comparison of MADLINK results with the structure-based baseline models on FB15k-237 and WN18RR datasets
| Models | MRR | Hits@1 | Hits@3 | Hits@10 |
| FB15K-237 | ||||
| TransE | 0.31 | 0.22 | 0.35 | 0.5 |
| DistMult | 0.247 | 0.161 | 0.27 | 0.426 |
| ConvE | 0.26 | 0.19 | 0.28 | 0.38 |
| ConvKB | 0.23 | 0.15 | 0.25 | 0.40 |
| RotatE | 0.298 | 0.205 | 0.328 | 0.480 |
| HypER | 0.341 | 0.252 | 0.376 | 0.520 |
| R-GCN | 0.228 | 0.128 | 0.25 | 0.419 |
| QuatE | 0.311 | 0.221 | 0.342 | 0.495 |
| MDE | 0.344 | – | – | 0.531 |
| TuckER | 0.358 | 0.266 | 0.394 | 0.544 |
| MADLINK1 | 0.347 | 0.252 | 0.38 | 0.529 |
| MADLINK2 | 0.341 | 0.249 | 0.377 | 0.52 |
| WN18RR | ||||
| TransE | 0.22 | 0.03 | 0.37 | 0.54 |
| DistMult | 0.438 | 0.424 | 0.442 | 0.478 |
| ConvE | 0.45 | 0.42 | 0.47 | 0.520 |
| ConvKB | 0.39 | 0.33 | 0.42 | 0.48 |
| RotatE | 0.476 | – | – | 0.571 |
| HypER | 0.465 | 0.436 | 0.477 | 0.465 |
| R-GCN | 0.39 | 0.338 | 0.431 | 0.49 |
| QuatE | 0.481 | 0.436 | 0.5 | 0.564 |
| MDE | 0.458 | – | – | 0.56 |
| TuckER | 0.47 | 0.443 | 0.482 | 0.526 |
| MADLINK1 | 0.477 | 0.438 | 0.479 | 0.549 |
| MADLINK2 | 0.471 | 0.43 | 0.469 | 0.535 |
Table 6
Comparison of MADLINK results with the structure-based baseline models on FB15k, WN18, and YAGO3-10 datasets
| Models | MRR | Hits@1 | Hits@3 | Hits@10 |
| FB15K | ||||
| TransE | 0.63 | 0.5 | 0.73 | 0.85 |
| DistMult | 0.432 | 0.302 | 0.498 | 0.68 |
| ConvE | 0.5 | 0.42 | 0.52 | 0.66 |
| ConvKB | 0.65 | 0.55 | 0.71 | 0.82 |
| RotatE | 0.797 | – | – | 0.884 |
| HypER | 0.790 | 0.734 | 0.829 | 0.885 |
| R-GCN | 0.69 | 0.6 | 0.72 | 0.8 |
| QuatE | 0.77 | 0.7 | 0.821 | 0.878 |
| MDE | 0.652 | – | – | 0.857 |
| TuckER | 0.795 | 0.741 | 0.833 | 0.892 |
| MADLINK1 | 0.712 | 0.722 | 0.788 | 0.81 |
| MADLINK2 | 0.69 | 0.714 | 0.78 | 0.798 |
| WN18 | ||||
| TransE | 0.66 | 0.44 | 0.88 | 0.95 |
| DistMult | 0.755 | 0.615 | 0.891 | 0.94 |
| ConvE | 0.93 | 0.91 | 0.94 | 0.95 |
| RotatE | 0.949 | – | – | 0.959 |
| HypER | 0.951 | 0.947 | 0.955 | 0.958 |
| R-GCN | 0.71 | 0.61 | 0.88 | 0.932 |
| QuatE | 0.949 | 0.941 | 0.954 | 0.96 |
| MDE | 0.871 | – | – | 0.956 |
| TuckER | 0.953 | 0.949 | 0.955 | 0.958 |
| MADLINK1 | 0.95 | 0.898 | 0.911 | 0.96 |
| MADLINK2 | 0.944 | 0.88 | 0.9 | 0.9 |
| YAGO3-10 | ||||
| TransE | 0.51 | 0.41 | 0.57 | 0.67 |
| DistMult | 0.354 | 0.262 | 0.4 | 0.537 |
| ConvE | 0.4 | 0.33 | 0.42 | 0.53 |
| ConvKB | 0.3 | 0.21 | 0.34 | 0.5 |
| HypER | 0.533 | 0.455 | 0.58 | 0.678 |
| R-GCN | 0.12 | 0.06 | 0.113 | 0.211 |
| TuckER | 0.427 | 0.331 | 0.476 | 0.609 |
| MADLINK1 | 0.538 | 0.457 | 0.58 | 0.68 |
| MADLINK2 | 0.528 | 0.447 | 0.573 | 0.67 |
5.4.3.Comparison with structure-based baseline models
The proposed model MADLINK is compared with the baseline KG embedding models such as TransE, DistMult, ConvE, ConvKB, RotatE, HypER, R-GCN, QuatE, MDE, and TuckER, that consider the triple information to generate the latent representation of the entities for the task of link prediction in KGs. The results are shown in Table 5 on FB15k-237 and WN18RR and Table 6 on FB15k, WN18, and YAGO3-10 datasets.
MADLINK achieves the second best results after TuckER for FB15k-237 on MRR, Hits@1, and Hits@3 metrics, whereas for Hits@10, TuckER performs slightly better with an improvement of 1.5% over MADLINK. On the other hand, for WN18RR, MADLINK achieves the second best result for MRR, Hits@1, and Hits@3 after TuckER. The latter performs marginally better than MADLINK with an improvement of 0.7% on MRR, 0.5% on Hits@1, 0.3% on Hits@3. However, MADLINK performs better than TuckER for Hits@10 by 2.3%. RotatE performs the best for Hits@10 amongst the mentioned baseline models and its performance is 2.2% better than MADLINK.
TuckER model outperforms all the baseline models as well as MADLINK for FB15k. However, for the YAGO3-10 dataset, MADLINK outperforms the TuckER model with an improvement of 11.1% on MRR, 12.6% on Hits@1, 10.4% on Hits@3, and 7.1% on Hits@10. Additionally, MADLINK outperforms all the other baseline models and achieves SOTA results for the YAGO3-10 dataset over all the metrics. For WN18, TuckER performs better than all the baseline models and MADLINK for all the metrics except for Hits@10.
Additionally, MADLINK outperforms its base model DistMult for all the metrics in all the datasets. For FB15K-237, there is an improvement of 10% in MRR, 9.1%, 11%, and 10.3% in Hits@1, Hit@3, and Hits@10 respectively. Similarly, for FB15K, a considerable increase of 28% in MRR, 42% in Hits@1, 29% in Hits@3, and 13% in Hits@10 have been achieved. On the other hand, for WN18, MADLINK shows a rise of 19.5% in MRR, 28.3% in Hits@1, and 2% for both Hits@3 and Hits@10. Also, for WN18RR similar increment of the results has been achieved with an increment of 3.9% in MRR, 1.4% in Hits@1, 3.7% in Hits@3, and 4.5% in Hits@10. Identical improvement has also been obtained for the YAGO3-10 dataset with an improvement of an average of 17.55% overall the evaluation metrics with an increase of 18.4% in MRR, 19.5% in Hits@1, 18%, and 14.3% in Hits@3, and Hits@10 respectively.
Also, from the results of Hits@k, for all the datasets it can be inferred that MADLINK correctly ranks many true triples in top-k as it achieves SOTA results for FB15K-237, WN18RR, WN18, and YAGO3-10 whereas comparable results for FB15K. Furthermore, MADLINK works better for the datasets without the reverse relations such as FB15K-237 and WN18RR as compared to FB15K and WN18 because in this work directed paths are considered and not undirected edges. However, in this work, the evaluation metric Mean Rank (MR) has not been used because it is sensitive to outliers as mentioned in other related work [31].
MADLINK has also been compared with LiteralE [23], which uses numerical literal to predict the missing links. The results shown in Table 7 illustrate that MADLINK performs better than LiteralE. Additionally for FB15k-237, MADLINK performs better than LiteralE variant with both numeric and text data. It is to be mentioned that, the results of DistMult variant of LiteralE is considered in Table 7 for a fair comparison with MADLINK as both of them use DistMult.
Table 7
Comparison of MADLINK with LiteralE on FB15k-237, FB15k, and YAGO3-10
| Models | MRR | Hits@1 | Hits@3 | Hits@10 |
| FB15K-237 | ||||
| LiteralE (Numeric+Text) | 0.32 | 0.234 | – | 0.488 |
| LiteralE (Numeric) | 0.317 | 0.232 | 0.348 | 0.483 |
| MADLINK | 0.347 | 0.252 | 0.38 | 0.529 |
| FB15k | ||||
| LiteralE (Numeric) | 0.676 | 0.589 | 0.733 | 0.825 |
| MADLINK | 0.712 | 0.722 | 0.788 | 0.81 |
| YAGO3-10 | ||||
| LiteralE (Numeric) | 0.479 | 0.4 | 0.525 | 0.627 |
| MADLINK | 0.538 | 0.457 | 0.580 | 0.68 |
The main advantage of MADLINK over the structure-based baseline models is that link prediction can be performed for unpopular entities in a KG, i.e., the entities without any relations or less number of relations associated with them. This is because MADLINK considers the textual entity descriptions of the entities apart from the structural information. Similarly, since it considers the structural information of the entities in the forms of paths, therefore, missing links can be predicted for entities having triple information but without textual entity descriptions.
Therefore, it can be concluded that the path information of the entities when coupled with the textual entity descriptions in KGs provide better results in link prediction which is further analysed in Section 5.6.
Table 8
Triple classification (accuracy in %)
| Models | FB15K | FB15K-237 | WN18 | WN18RR |
| TransE | 82.9 | 75.6 | 87.6 | 74 |
| DistMult | – | 73.9 | – | 80.4 |
| ConvE | 87.3 | 78.2 | 95.4 | 78.3 |
| ConvKB | 87.9 | 80.1 | 96.4 | 79.1 |
| Jointly(ALSTM) | 91.5 | – | 97.8 | – |
| PConvKB | 89.5 | 82.1 | 97.6 | 80.3 |
| MADLINK | 92.1 | 82.8 | 98 | 81.2 |
5.5.Triple classification
Triple Classification is the task of determining if a given triple is correct or not. It is a binary classification task, where a given triple
However, for MADLINK a Convolutional Neural Network (CNN) binary classifier has been used on top of the embeddings of entities and relations obtained from the model. The classifier is trained with positive triples from the training set and negative triples obtained from the negative sampling model. The test set is also complemented with negative examples for proper evaluation. Triple Classification for all 4 datasets has also been compared against all the above mentioned SOTA models along with PConvKB [20]. PConvKB is an embedding model that incorporates relation paths locally and globally which are then passed through a convolutional neural model. The results are depicted in Table 8. The proposed model achieves the SOTA results with an improvement of 0.2% to 0.8% over the SOTA models for all the benchmark datasets. Furthermore, the accuracy of triple classification for the YAGO3-10 dataset is 80.1% but it has not been provided in Table 8 because of the lack of results from the SOTA models.
5.6.Ablation study
This section discusses the analysis of different features considered in the MADLINK model for the task of link prediction.
5.6.1.Impact of only textual entity description
The impact of only the textual entity description without the structural information for the task of link prediction has been evaluated along with the triples. The latent representation of the textual entity descriptions is obtained using SBERT vectors. The results as depicted in Table 9 show that it outperforms the base model DistMult for all the datasets. It is observed that the improvement for WN18 and WN18RR is very small compared to the other datasets. This is due to the fact that both the datasets contain 5780 entities for which the length of the textual entity description is less than or equal to five providing much less information. However, Table 4 shows textual entity descriptions together with path information exhibits considerable improvement in link prediction.
Table 9
Impact of textual entity descriptions in MADLINK (without path information)
| Datasets | Models | MRR | Hits@1 | Hits@3 | Hits@10 |
| FB15K | DistMult | 0.432 | 0.302 | 0.498 | 0.68 |
| MADLINK | 0.481 | 0.348 | 0.512 | 0.692 | |
| FB15K-237 | DistMult | 0.2471 | 0.161 | 0.271 | 0.426 |
| MADLINK | 0.249 | 0.179 | 0.279 | 0.431 | |
| WN18 | DistMult | 0.755 | 0.615 | 0.891 | 0.94 |
| MADLINK | 0.758 | 0.618 | 0.895 | 0.943 | |
| WN18RR | DistMult | 0.438 | 0.424 | 0.442 | 0.478 |
| MADLINK | 0.439 | 0.425 | 0.448 | 0.48 | |
| YAGO3-10 | DistMult | 0.354 | 0.262 | 0.4 | 0.537 |
| MADLINK | 0.361 | 0.267 | 0.411 | 0.54 |
5.6.2.Impact of only structural information
The results depicted in Table 10 illustrate the impact of using only the structural information of the KGs in form of paths. The number of paths increases exponentially with the number of hops, for e.g., in FB15k, the average neighbour for each node is 30, therefore, the total number of possible paths of 4 hops would be 810,000. PF-ITF is used to filter out the uncommon relations which in turn reduces the number of paths. As mentioned earlier, 1000 paths with 4 hops are selected for each entity because the relevant contextual information w.r.t. the starting node decreases with more hops. Also, when the walk reaches a dead end, i.e., a node without any outgoing edges, the walk ends in that dead-end node, even if the maximum hops is not reached. However, there could be more than 1000 paths starting from a certain node in which the first 3 hops consist of the same entities and relations. But this does not provide any meaningful insight into the source code. Therefore, amongst the paths, we restrict the paths with the same sequence to a maximum of 30. For example, any path starting with this
The results in Table 10 show that the MADLINK model with only the structural information outperforms the base model DistMult for all the metrics across all the 5 benchmark datasets. Additionally, MADLINK with only structural information works slightly better than MADLINK with only textual entity descriptions for WN18 and WN18RR datasets. Therefore, it can be inferred that the neighbourhood information is well captured for these two datasets in the paths.
Table 10
Impact of structural information in MADLINK (without textual entity description)
| Datasets | Models | MRR | Hits@1 | Hits@3 | Hits@10 |
| FB15K | DistMult | 0.432 | 0.302 | 0.498 | 0.68 |
| MADLINK | 0.477 | 0.328 | 0.498 | 0.682 | |
| FB15K-237 | DistMult | 0.2471 | 0.161 | 0.271 | 0.426 |
| MADLINK | 0.249 | 0.169 | 0.273 | 0.426 | |
| WN18 | DistMult | 0.755 | 0.615 | 0.891 | 0.94 |
| MADLINK | 0.758 | 0.63 | 0.898 | 0.947 | |
| WN18RR | DistMult | 0.438 | 0.424 | 0.442 | 0.478 |
| MADLINK | 0.44 | 0.426 | 0.45 | 0.482 | |
| YAGO3-10 | DistMult | 0.354 | 0.262 | 0.4 | 0.537 |
| MADLINK | 0.365 | 0.262 | 0.42 | 0.542 |
Table 11
Impact of attention mechanism in MADLINK
| Datasets | Models | MRR | Hits@1 | Hits@3 | Hits@10 |
| FB15K | MADLINK (w/o Attn.) | 0.48 | 0.388 | 0.502 | 0.701 |
| MADLINK (with Attn.) | 0.51 | 0.412 | 0.591 | 0.758 | |
| FB15K-237 | MADLINK (w/o Attn.) | 0.331 | 0.211 | 0.35 | 0.498 |
| MADLINK (with Attn.) | 0.347 | 0.252 | 0.38 | 0.529 | |
| WN18 | MADLINK (w/o Attn.) | 0.92 | 0.822 | 0.85 | 0.91 |
| MADLINK (with Attn.) | 0.95 | 0.898 | 0.911 | 0.96 | |
| WN18RR | MADLINK (w/o Attn.) | 0.412 | 0.401 | 0.411 | 0.509 |
| MADLINK (with Attn.) | 0.477 | 0.438 | 0.479 | 0.549 | |
| YAGO3-10 | MADLINK (w/o Attn.) | 0.411 | 0.331 | 0.524 | 0.623 |
| MADLINK (with Attn.) | 0.461 | 0.372 | 0.580 | 0.68 |
5.6.3.Influence of attention in the network
To analyse the impact of the attention mechanism in encoding the path vectors, experiments have been conducted without the attention layer as depicted in Table 11. The result depicts that there is an improvement in all the evaluation metrics for all the datasets if MADLINK is used with the attention mechanism. Therefore, with an improvement of an average of 5% over Hits@10 for FB15K, WN18, and YAGO3-10 as well as 3.1% for FB15K-237 and 1.4% for WN18RR, it can be seen that the attention mechanism helps in identifying the important entities and relations in a path for the task of link prediction.
6.Conclusion and future work
In this paper, a novel approach has been proposed for combining the contextual structural information of an entity from the KGs as well as textual entity descriptions in the embedding space to address the problem of KG completion using link prediction and triple classification. Moreover, an attention-based encoder-decoder approach is introduced to measure the importance of paths. Experimental results show that MADLINK achieves the SOTA results for the textual entity description-based embedding models for the link prediction task on all the 5 benchmark datasets. Furthermore, MADLINK outperforms most of the baseline models whereas it achieves comparable results with the rest. In this paper, two major research questions are formulated and presented in Section 3. The answers to these questions are given as follows:
– RQ1: Does the contextual information of entities and relations in a KG help in the task of link prediction?
∗ The contextual information of the entities and the relations in a KG are captured by generating paths using random walks. Also, the attention mechanism on the encoder-decoder model helps in identifying the important entities within a path. Handling the path information separately (as shown in Table 10) in the MADLINK model yields better results than the base model DistMult which uses only the triple information.
– RQ2: What is the impact of incorporating textual entity descriptions in a KG for the task of link prediction?
∗ The latent representations of the textual entity descriptions are generated using the SBERT model. The impact of the textual entity descriptions in the link prediction task is dependent on the length of textual information available for the corresponding entities. It can be observed from the results of MADLINK as depicted in Table 9 that link prediction works better for FB15k and FB15k-237 compared to WN18 and WN18RR. This is because Freebase entities have detailed and longer text descriptions than WordNet entities. Also, only the textual description-based variant of MADLINK outperforms the base model DistMult for all the 5 benchmark datasets. Therefore, the textual entity descriptions play an important role in the task of link prediction in KGs.
The obtained results suggest that the impact of the textual entity description and the contextual structural information is different for different KGs. However, the combination of contextual structural information together with the textual entity descriptions in the MADLINK model outperforms all the text-based KG embedding models.
In future work the following research directions will be considered to further improve the model:
– Explore the translational embedding models such as TransR to learn the initial embeddings of the entities and relations.
– Explore the different scoring functions such as ConvE, translational models, etc. for the base model to analyze the embeddings for the link prediction task.
– Use different multi-hop strategies to generate the context information.
– Multiple text literals available for the entities in the KGs as labels, summary, comments, etc. can also be incorporated in the model. Also for relations, relation name labels can be considered as the textual description.
– Include explicit external text information such as from Wikipedia into the model.
Notes
References
[1] | S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak and Z.G. Ives, DBpedia: A nucleus for a web of open data, in: The Semantic Web, 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, November 11–15, 2007, K. Aberer, K. Choi, N.F. Noy, D. Allemang, K. Lee, L.J.B. Nixon, J. Golbeck, P. Mika, D. Maynard, R. Mizoguchi, G. Schreiber and P. Cudré-Mauroux, eds, Lecture Notes in Computer Science, Vol. 4825: , Springer, (2007) , pp. 722–735. |
[2] | I. Balazevic, C. Allen and T.M. Hospedales, Hypernetwork knowledge graph embeddings, in: Artificial Neural Networks and Machine Learning – ICANN 2019 – 28th International Conference on Artificial Neural Networks, Proceedings – Workshop and Special Sessions, Munich, Germany, September 17–19, 2019, I.V. Tetko, V. Kurková, P. Karpov and F.J. Theis, eds, Lecture Notes in Computer Science, Vol. 11731: , Springer, (2019) , pp. 553–565. doi:10.1007/978-3-030-30493-5_52. |
[3] | I. Balazevic, C. Allen and T.M. Hospedales, TuckER: Tensor factorization for knowledge graph completion, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3–7, 2019, K. Inui, J. Jiang, V. Ng and X. Wan, eds, Association for Computational Linguistics, (2019) , pp. 5184–5193. doi:10.18653/v1/D19-1522. |
[4] | K.D. Bollacker, R.P. Cook and P. Tufts, Freebase: A shared database of structured general human knowledge, in: Proceedings of the Twenty-Second AAAI Conference on Artificial Intelligence, Vancouver, British Columbia, Canada, July 22–26, 2007, AAAI Press, (2007) , pp. 1962–1963, http://www.aaai.org/Library/AAAI/2007/aaai07-355.php. |
[5] | A. Bordes, S. Chopra and J. Weston, Question answering with subgraph embeddings, in: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, a Meeting of SIGDAT, a Special Interest Group of the ACL, Doha, Qatar, October 25–29, 2014, A. Moschitti, B. Pang and W. Daelemans, eds, ACL, (2014) , pp. 615–620. |
[6] | A. Bordes, N. Usunier, A. García-Durán, J. Weston and O. Yakhnenko, Translating embeddings for modeling multi-relational data, in: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a Meeting Held, Lake Tahoe, Nevada, United States, December 5–8, 2013, C.J.C. Burges, L. Bottou, Z. Ghahramani and K.Q. Weinberger, eds, (2013) , pp. 2787–2795, https://proceedings.neurips.cc/paper/2013/hash/1cecc7a77928ca8133fa24680a88d2f9-Abstract.html. |
[7] | A. Bordes, J. Weston, R. Collobert and Y. Bengio, Learning structured embeddings of knowledge bases, in: Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2011, San Francisco, California, USA, August 7–11, 2011, W. Burgard and D. Roth, eds, AAAI Press, (2011) , http://www.aaai.org/ocs/index.php/AAAI/AAAI11/paper/view/3659. |
[8] | M. Chen, Y. Tian, K. Chang, S. Skiena and C. Zaniolo, Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment, in: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, July 13–19, 2018, J. Lang, ed., ijcai.org, (2018) , pp. 3998–4004. doi:10.24963/ijcai.2018/556. |
[9] | K. Cho, B. van Merrienboer, Ç. Gülçehre, D. Bahdanau, F. Bougares, H. Schwenk and Y. Bengio, Learning phrase representations using RNN encoder-decoder for statistical machine translation, in: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, a Meeting of SIGDAT, a Special Interest Group of the ACL, Doha, Qatar, October 25–29, 2014, A. Moschitti, B. Pang and W. Daelemans, eds, ACL, (2014) , pp. 1724–1734. |
[10] | L. Costabello, S. Pai, C.L. Van, R. McGrath, N. McCarthy and P. Tabacof, AmpliGraph: A Library for Representation Learning on Knowledge Graphs, 2019. |
[11] | D. Daza, M. Cochez and P. Groth, Inductive entity representations from text via link prediction, in: WWW ’21: The Web Conference 2021, Virtual Event, Ljubljana, Slovenia, April 19–23, 2021, J. Leskovec, M. Grobelnik, M. Najork, J. Tang and L. Zia, eds, ACM/IW3C2, (2021) , pp. 798–808. doi:10.1145/3442381.3450141. |
[12] | T. Dettmers, P. Minervini, P. Stenetorp and S. Riedel, Convolutional 2D knowledge graph embeddings, in: Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2–7, 2018, S.A. McIlraith and K.Q. Weinberger, eds, AAAI Press, (2018) , pp. 1811–1818, https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17366. |
[13] | J. Devlin, M. Chang, K. Lee and K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (2019) . |
[14] | J. Feng, M. Huang, Y. Yang and X. Zhu, GAKE: Graph aware knowledge embedding, in: COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference: Technical Papers, Osaka, Japan, December 11–16, 2016, N. Calzolari, Y. Matsumoto and R. Prasad, eds, ACL, (2016) , pp. 641–651, https://aclanthology.org/C16-1062/. |
[15] | A. García-Durán and M. Niepert, KBlrn: End-to-end learning of knowledge base representations with latent, relational, and numerical features, in: Proceedings of the Thirty-Fourth Conference on Uncertainty in Artificial Intelligence, UAI 2018, Monterey, California, USA, August 6–10, 2018, A. Globerson and R. Silva, eds, AUAI Press, (2018) , pp. 372–381, http://auai.org/uai2018/proceedings/papers/149.pdf. |
[16] | G.A. Gesese, R. Biswas, M. Alam and H. Sack, A survey on knowledge graph embeddings with literals: Which model links better literal-ly?, Semantic Web 12: (4) ((2021) ), 617–647. doi:10.3233/SW-200404. |
[17] | S. Guo, Q. Wang, B. Wang, L. Wang and L. Guo, SSE: Semantically smooth embedding for knowledge graphs, IEEE Transactions on Knowledge and Data Engineering ((2017) ). |
[18] | J. Hoffart, M.A. Yosef, I. Bordino, H. Fürstenau, M. Pinkal, M. Spaniol, B. Taneva, S. Thater and G. Weikum, Robust disambiguation of named entities in text, in: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, John McIntyre Conference Centre, Edinburgh, UK, 27–31 July 2011, A Meeting of SIGDAT, a Special Interest Group of the ACL, ACL, (2011) , pp. 782–792, https://aclanthology.org/D11-1072/. |
[19] | G. Ji, K. Liu, S. He and J. Zhao, Knowledge graph completion with adaptive sparse transfer matrix, in: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, USA, February 12–17, 2016, D. Schuurmans and M.P. Wellman, eds, AAAI Press, (2016) , pp. 985–991, http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/11982. |
[20] | N. Jia, X. Cheng and S. Su, Improving knowledge graph embedding using locally and globally attentive relation paths, in: Advances in Information Retrieval – 42nd European Conference on IR Research, ECIR 2020, Proceedings, Part I, Lisbon, Portugal, April 14–17, 2020, J.M. Jose, E. Yilmaz, J. Magalhães, P. Castells, N. Ferro, M.J. Silva and F. Martins, eds, Lecture Notes in Computer Science, Vol. 12035: , Springer, (2020) , pp. 17–32. doi:10.1007/978-3-030-45439-5_2. |
[21] | Y. Jia, Y. Wang, H. Lin, X. Jin and X. Cheng, Locally adaptive translation for knowledge graph embedding, in: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, USA, February 12–17, 2016, D. Schuurmans and M.P. Wellman, eds, AAAI Press, (2016) , pp. 992–998, http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12018. |
[22] | B. Kim, T. Hong, Y. Ko and J. Seo, Multi-task learning for knowledge graph completion with pre-trained language models, in: Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8–13, 2020, D. Scott, N. Bel and C. Zong, eds, International Committee on Computational Linguistics, (2020) , pp. 1737–1743. |
[23] | A. Kristiadi, M.A. Khan, D. Lukovnikov, J. Lehmann and A. Fischer, Incorporating literals into knowledge graph embeddings, in: The Semantic Web – ISWC 2019 – 18th International Semantic Web Conference, Proceedings, Part I, Auckland, New Zealand, October 26–30, 2019, C. Ghidini, O. Hartig, M. Maleshkova, V. Svátek, I.F. Cruz, A. Hogan, J. Song, M. Lefrancoiş and F. Gandon, eds, Lecture Notes in Computer Science, Vol. 11778: , Springer, (2019) , pp. 347–363. doi:10.1007/978-3-030-30793-6_20. |
[24] | Y. Lin, Z. Liu, H. Luan, M. Sun, S. Rao and S. Liu, Modeling relation paths for representation learning of knowledge bases, in: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, September 17–21, 2015, L. Màrquez, C. Callison-Burch, J. Su, D. Pighin and Y. Marton, eds, The Association for Computational Linguistics, (2015) , pp. 705–714. doi:10.18653/v1/D15-1082. |
[25] | Y. Lin, Z. Liu, M. Sun, Y. Liu and X. Zhu, Learning entity and relation embeddings for knowledge graph completion, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, January 25–30, 2015, B. Bonet and S. Koenig, eds, AAAI Press, (2015) , pp. 2181–2187, http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9571. |
[26] | T. Mikolov, K. Chen, G. Corrado and J. Dean, Efficient estimation of word representations in vector space, in: 1st International Conference on Learning Representations, ICLR 2013, Workshop Track Proceedings, Scottsdale, Arizona, USA, May 2–4, 2013, Y. Bengio and Y. LeCun, eds, (2013) , http://arxiv.org/abs/1301.3781. |
[27] | G.A. Miller, WordNet: An Electronic Lexical Database, MIT press, (1998) . |
[28] | D.Q. Nguyen, T.D. Nguyen, D.Q. Nguyen and D.Q. Phung, A novel embedding model for knowledge base completion based on convolutional neural network, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, New Orleans, Louisiana, USA, June 1–6, 2018, M.A. Walker, H. Ji and A. Stent, eds, Vol. 2: (Short Papers), Association for Computational Linguistics, (2018) , pp. 327–333. doi:10.18653/v1/n18-2053. |
[29] | D.Q. Nguyen, T.D. Nguyen, D.Q. Nguyen and D.Q. Phung, A novel embedding model for knowledge base completion based on convolutional neural network, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, New Orleans, Louisiana, USA, June 1–6, 2018, M.A. Walker, H. Ji and A. Stent, eds, Vol. 2: (Short Papers), Association for Computational Linguistics, (2018) , pp. 327–333. doi:10.18653/v1/n18-2053. |
[30] | M. Nickel, L. Rosasco and T.A. Poggio, Holographic embeddings of knowledge graphs, in: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, USA, February 12–17, 2016, D. Schuurmans and M.P. Wellman, eds, AAAI Press, (2016) , pp. 1955–1961, http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12484. |
[31] | M. Nickel, L. Rosasco and T.A. Poggio, Holographic embeddings of knowledge graphs, in: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, USA, February 12–17, 2016, D. Schuurmans and M.P. Wellman, eds, AAAI Press, (2016) , pp. 1955–1961, http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12484. |
[32] | M. Nickel, V. Tresp and H. Kriegel, A three-way model for collective learning on multi-relational data, in: Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, USA, June 28–July 2, 2011, L. Getoor and T. Scheffer, eds, Omnipress, (2011) , pp. 809–816, https://icml.cc/2011/papers/438_icmlpaper.pdf. |
[33] | J. Pennington, R. Socher and C.D. Manning, Glove: Global vectors for word representation, in: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, a Meeting of SIGDAT, a Special Interest Group of the ACL, Doha, Qatar, October 25–29, 2014, A. Moschitti, B. Pang and W. Daelemans, eds, ACL, (2014) , pp. 1532–1543. doi:10.3115/v1/d14-1162. |
[34] | P. Pezeshkpour, L. Chen and S. Singh, Embedding multimodal relational data for knowledge base completion, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31–November 4, 2018, E. Riloff, D. Chiang, J. Hockenmaier and J. Tsujii, eds, Association for Computational Linguistics, (2018) , pp. 3208–3218. doi:10.18653/v1/D18-1359. |
[35] | G. Pirrò, Explaining and suggesting relatedness in knowledge graphs, in: The Semantic Web – ISWC 2015 – 14th International Semantic Web Conference, Proceedings, Part I, Bethlehem, PA, USA, October 11–15, 2015, M. Arenas, Ó. Corcho, E. Simperl, M. Strohmaier, M. d’Aquin, K. Srinivas, P. Groth, M. Dumontier, J. Heflin, K. Thirunarayan and S. Staab, eds, Lecture Notes in Computer Science, Vol. 9366: , Springer, (2015) , pp. 622–639. |
[36] | Y. Qiao, C. Xiong, Z. Liu and Z. Liu, Understanding the Behaviors of BERT in Ranking, CoRR, (2019) , http://arxiv.org/abs/1904.07531. |
[37] | N. Reimers and I. Gurevych, Sentence-BERT: Sentence embeddings using Siamese BERT-networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3–7, 2019, K. Inui, J. Jiang, V. Ng and X. Wan, eds, Association for Computational Linguistics, (2019) , pp. 3980–3990. doi:10.18653/v1/D19-1410. |
[38] | P. Ristoski and H. Paulheim, RDF2Vec: RDF graph embeddings for data mining, in: Proceedings, Part I, The Semantic Web – ISWC 2016–15th International Semantic Web Conference, Kobe, Japan, October 17–21, 2016, P. Groth, E. Simperl, A.J.G. Gray, M. Sabou, M. Krötzsch, F. Lécué, F. Flock̈ and Y. Gil, eds, Lecture Notes in Computer Science, Vol. 9981: , (2016) , pp. 498–514. doi:10.1007/978-3-319-46523-4_30. |
[39] | A. Rossi, D. Barbosa, D. Firmani, A. Matinata and P. Merialdo, Knowledge graph embedding for link prediction: A comparative analysis, ACM Trans. Knowl. Discov. Data 15: (2) ((2021) ), 14:1–14:49. doi:10.1145/3424672. |
[40] | A. Sadeghi, D. Graux, H.S. Yazdi and J. Lehmann, MDE: Multiple distance embeddings for link prediction in knowledge graphs, in: ECAI 2020 – 24th European Conference on Artificial Intelligence, Including 10th Conference on Prestigious Applications of Artificial Intelligence (PAIS 2020), Santiago de Compostela, Spain, 29 August – 8 September 2020, G.D. Giacomo, A. Catalá, B. Dilkina, M. Milano, S. Barro, A. Bugarín and J. Lang, eds, Frontiers in Artificial Intelligence and Applications, Vol. 325: , IOS Press, (2020) , pp. 1427–1434. doi:10.3233/FAIA200248. |
[41] | M.S. Schlichtkrull, T.N. Kipf, P. Bloem, R. van den Berg, I. Titov and M. Welling, Modeling relational data with graph convolutional networks, in: The Semantic Web – 15th International Conference, ESWC 2018, Proceedings, Heraklion, Crete, Greece, June 3–7, 2018, A. Gangemi, R. Navigli, M. Vidal, P. Hitzler, R. Troncy, L. Hollink, A. Tordai and M. Alam, eds, Lecture Notes in Computer Science, Vol. 10843: , Springer, (2018) , pp. 593–607. doi:10.1007/978-3-319-93417-4_38. |
[42] | R. Socher, D. Chen, C.D. Manning and A.Y. Ng, Reasoning with neural tensor networks for knowledge base completion, in: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a Meeting Held, Lake Tahoe, Nevada, United States, December 5–8, 2013, C.J.C. Burges, L. Bottou, Z. Ghahramani and K.Q. Weinberger, eds, (2013) , pp. 926–934. |
[43] | F.M. Suchanek, G. Kasneci and G. Weikum, Yago: A core of semantic knowledge, in: Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff, Alberta, Canada, May 8–12, 2007, C.L. Williamson, M.E. Zurko, P.F. Patel-Schneider and P.J. Shenoy, eds, ACM, (2007) , pp. 697–706. doi:10.1145/1242572.1242667. |
[44] | Z. Sun, Z. Deng, J. Nie and J. Tang, RotatE: Knowledge graph embedding by relational rotation in complex space, in: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6–9, 2019, OpenReview.net, (2019) , pp. 6–9, https://openreview.net/forum?id=HkgEQnRqYQ. |
[45] | I. Sutskever, O. Vinyals and Q.V. Le, Sequence to sequence learning with neural networks, in: Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, Quebec, Canada, December 8–13 2014, Z. Ghahramani, M. Welling, C. Cortes, N.D. Lawrence and K.Q. Weinberger, eds, (2014) , pp. 3104–3112, https://proceedings.neurips.cc/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html. |
[46] | Y. Tay, L.A. Tuan, M.C. Phan and S.C. Hui, Multi-task neural network for non-discrete attribute prediction in knowledge graphs, in: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, CIKM 2017, Singapore, November 06–10, 2017, E. Lim, M. Winslett, M. Sanderson, A.W. Fu, J. Sun, J.S. Culpepper, E. Lo, J.C. Ho, D. Donato, R. Agrawal, Y. Zheng, C. Castillo, A. Sun, V.S. Tseng and C. Li, eds, ACM, (2017) , pp. 1029–1038. doi:10.1145/3132847.3132937. |
[47] | K. Toutanova and D. Chen, Observed versus latent features for knowledge base and text inference, in: Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality, (2015) . |
[48] | T. Trouillon, J. Welbl, S. Riedel, É. Gaussier and G. Bouchard, Complex embeddings for simple link prediction, in: Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19–24, 2016, M. Balcan and K.Q. Weinberger, eds, JMLR Workshop and Conference Proceedings, Vol. 48: , JMLR.org, (2016) , pp. 2071–2080, http://proceedings.mlr.press/v48/trouillon16.html. |
[49] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser and I. Polosukhin, Attention is all you need, in: Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, December 4–9, 2017, I. Guyon, U. von Luxburg, S. Bengio, H.M. Wallach, R. Fergus, S.V.N. Vishwanathan and R. Garnett, eds, (2017) , pp. 5998–6008, https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html. |
[50] | Z. Wang, J. Zhang, J. Feng and Z. Chen, Knowledge graph embedding by translating on hyperplanes, in: Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, Québec, Canada, July 27–31, 2014, C.E. Brodley and P. Stone, eds, AAAI Press, (2014) , pp. 1112–1119, http://www.aaai.org/ocs/index.php/AAAI/AAAI14/paper/view/8531. |
[51] | Y. Wu and Z. Wang, Knowledge graph embedding with numeric attributes of entities, in: Proceedings of the Third Workshop on Representation Learning for NLP, Rep4NLP@ACL 2018, Melbourne, Australia, July 20, 2018, I. Augenstein, K. Cao, H. He, F. Hill, S. Gella, J. Kiros, H. Mei and D. Misra, eds, Association for Computational Linguistics, (2018) , pp. 132–136. doi:10.18653/v1/W18-3017. |
[52] | H. Xiao, M. Huang, L. Meng and X. Zhu, SSP: Semantic space projection for knowledge graph embedding with text descriptions, in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, California, USA, February 4–9, 2017, S. Singh and S. Markovitch, eds, AAAI Press, (2017) , pp. 3104–3110. |
[53] | R. Xie, Z. Liu, H. Luan and M. Sun, Image-embodied knowledge representation learning, in: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19–25, 2017, C. Sierra, ed., ijcai.org, (2017) , pp. 3140–3146. |
[54] | R. Xie, Z. Liu and M. Sun, Representation learning of knowledge graphs with hierarchical types, in: Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, 9–15 July, S. Kambhampati, ed., IJCAI/AAAI Press, New York, NY, USA, (2016) , pp. 2965–2971, http://www.ijcai.org/Abstract/16/421. |
[55] | S. Xiong, W. Huang and P. Duan, Knowledge graph embedding via relation paths and dynamic mapping matrix, in: Advances in Conceptual Modeling – ER 2018 Workshops Emp-ER, MoBiD, MREBA, QMMQ, SCME, Proceedings, Xi’an, China, October 22–25, 2018, C. Woo, J. Lu, Z. Li, T.W. Ling, G. Li and M. Lee, eds, Lecture Notes in Computer Science, Vol. 11158: , Springer, (2018) , pp. 106–118. doi:10.1007/978-3-030-01391-2_18. |
[56] | J. Xu, X. Qiu, K. Chen and X. Huang, Knowledge graph representation with jointly structural and textual encoding, in: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19–25, 2017, C. Sierra, ed., ijcai.org, (2017) , pp. 1318–1324. doi:10.24963/ijcai.2017/183. |
[57] | B. Yang, W. Yih, X. He, J. Gao and L. Deng, Embedding entities and relations for learning and inference in knowledge bases, in: 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings, San Diego, CA, USA, May 7–9, 2015, Y. Bengio and Y. LeCun, eds, (2015) , http://arxiv.org/abs/1412.6575. |
[58] | Z. Yang, Z. Dai, Y. Yang, J.G. Carbonell, R. Salakhutdinov and Q.V. Le, XLNet: Generalized autoregressive pretraining for language understanding, in: Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, December 8–14, 2019, H.M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E.B. Fox and R. Garnett, eds, (2019) , pp. 5754–5764. |
[59] | L. Yao, C. Mao and Y. Luo, KG-BERT: BERT for Knowledge Graph Completion, CoRR, (2019) , http://arxiv.org/abs/1909.03193. |
[60] | F. Zhang, N.J. Yuan, D. Lian, X. Xie and W. Ma, Collaborative knowledge base embedding for recommender systems, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17, 2016, B. Krishnapuram, M. Shah, A.J. Smola, C.C. Aggarwal, D. Shen and R. Rastogi, eds, ACM, (2016) , pp. 353–362. doi:10.1145/2939672.2939673. |
[61] | S. Zhang, Y. Tay, L. Yao and Q. Liu, Quaternion knowledge graph embeddings, in: Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, December 8–14, 2019, H.M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E.B. Fox and R. Garnett, eds, (2019) , pp. 2731–2741. |
[62] | Z. Zhang, J. Cai, Y. Zhang and J. Wang, Learning hierarchy-aware knowledge graph embeddings for link prediction, in: The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, the Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, the Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7–12, 2020, AAAI Press, (2020) , pp. 3065–3072, https://ojs.aaai.org/index.php/AAAI/article/view/5701. |
[63] | P. Zhao, C.C. Aggarwal and G. He, Link prediction in graph streams, in: 32nd IEEE International Conference on Data Engineering, ICDE 2016, Helsinki, Finland, May 16–20, 2016, IEEE Computer Society, (2016) , pp. 553–564. doi:10.1109/ICDE.2016.7498270. |


