
RelTopic: A graph-based semantic relatedness measure in topic ontologies and its applicability for topic labeling of old press articles
Abstract
Graph-based semantic measures have been used to solve problems in several domains. They tend to compare semantic entities in order to estimate their similarity or relatedness. While semantic similarity is applicable to hierarchies or taxonomies, semantic relatedness is adapted to ontologies. In this work, we propose a novel semantic relatedness measure, named
1.Introduction
Fig. 1.
Excerpt of Le Matin.

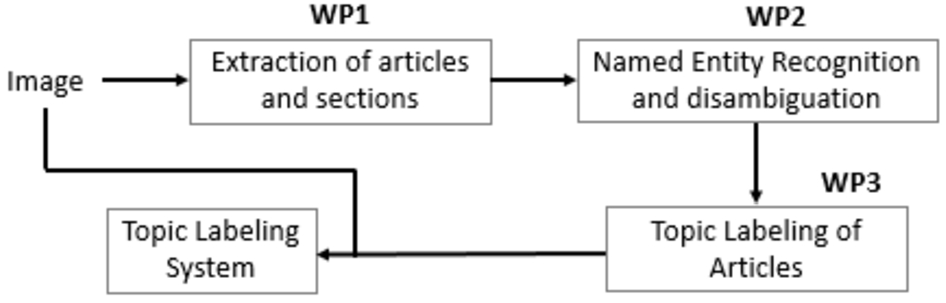
This article presents the works accomplished as part of the ASTURIAS11 project in the domain of cultural heritage. The main goal of ASTURIAS is to thematically and automatically organize a collection of old press articles with a set of topics (e.g., Politics, Art, Sport, Science, Etc.). One of the specific features of old press is that it does not offer thematic entries (see Fig. 1). Articles appear and follow one another without a thematic logic. Under these conditions, it remains a tedious task to query sources that report the same events from different points of view in different areas of the newspaper. The scientific challenge is to propose robust approaches for the analysis of texts that are noisy due to the imperfect process of automatic transcription of images into electronic texts. These approaches need also to be multi-thematic, and robust to linguistic evolution over the centuries. The ambition of the ASTURIAS project (whose workflow appears in Fig. 2) is to study the digitization process from end to end of the processing chain: WP1 – from newspaper images, automatically analyze sections, articles and texts; WP2 – extract named entities from these elements; WP3 – Topic labeling and hyperlinking the articles based on the analysis made in WP1 and the named entities extracted in WP2.
Fig. 2.
The pipeline of the project ASTURIAS.
Our work’s main goal is to propose a framework that permits automatic labeling of old press articles (WP3). This framework tends to replace humans with software for labeling a vast number of articles that would require too much human effort to do it manually. The task of labeling documents according to their topics has traditionally been addressed either by using classifiers for assigning to the articles a set of predefined topics (e.g., [8,39]), or by topic detection methods (e.g., probabilistic latent semantic analysis (pLSA) [22], latent Dirichlet allocation (LDA) [2]), which generate topics from textual resources [39]. The main advantage of the first approach is generating clean, and formally-defined research topics [39]. This approach is recommended when a good characterization of the research topics within a domain is available [39]. However, the second approach suffers from a significant limitation of generating topics from scratch leading to noisier and less interpretable results [39].
In this study, we propose applying graph-based semantic relatedness measures that permit assessment of the semantic relatedness of topics in topic ontologies with articles’ content. Graph-based semantic measures have been used to solve problems in a broad range of domains such as Natural Language Processing (e.g., [16]), Information Retrieval (e.g., [17]), Knowledge Engineering (e.g., [14]), Semantic Web and Linked Data (e.g., [9]) and Bioinformatics (e.g., [18]). They are considered essential tools for designing numerous algorithms in which semantics matters [19]. A graph-based semantic measure is a mathematical tool used to estimate the strength of the semantic interaction between entities (concepts or instances) based on the analysis of ontologies [19]. Thus, the application of this measure is strongly dependent on the availability of an ontology that represents the application domain. Two main categories of graph-based semantic measures are distinguished: (1) similarity measures adapted to taxonomies and (2) relatedness measures adapted to semantic graphs composed of different types of relationships [19]. Building semantic relatedness measures is a challenging and important research issue since they have to consider several kinds of relations and not only the taxonomic ones [30]. In the literature, apart from Hirst and St-Onge’s measure [21], there have been relatively few attempts to develop relatedness measures [30,34]. Most efforts are directed to design similarity measures such as [25,26,35,37]. For comparing ontological entities, graph-based measures are classified into two basic approaches: path-based, which compare the concepts according to properties of paths in graphs, and node-based, that use properties of concepts in the ontology graph for comparing concepts. However, these approaches suffer from different limitations.
The major contribution of this work is the design and evaluation of a semantic relatedness measure, named
The remainder of this paper is organized as follows: the research problem is specified in Section 2. Section 3 considers the main related works. In Section 4, we discuss our semantic relatedness measure
2.Problem definition
To define our research problem, a fundamental hypothesis is considered that articles are represented by a set of “not ambiguous” named entities (e.g. person, organization, product and location) extracted from open data sources (coming from WP2 of the ASTURIAS project, as shown in Fig. 2). Thus, the research problem can be defined as follows: given a corpus of articles A, a set of named entities N (represented by a set of URIs) that are collected from A (WP2), and a topical structure T, we want to find the most relevant topics described in T that label
1. Construction of the topical structure as a predefined set of topics: it takes as input N, i.e. the set of disambiguated named entities, and constructs T, i.e. a convenient topical structure based on N.
2. Named entity-topic mapping process as a relevance assessment: this process is performed for each
3. Ranking and selection of most relevant topics as a topic labeling process: takes as input the relatedness values of n and t,
3.Related works
This section outlines the following related works: graph-based semantic measures, semantic relatedness measures, topic ontologies, and ontology-based labeling of articles.
3.1.Graph-based semantic measures
For comparing ontological entities, graph-based measures are classified into two basic approaches: path-based and node-based. In path-based approaches, concepts are compared according to properties of paths in graphs. The most common property is the shortest path that connects nodes in a given ontology. The shorter the path is, the higher the similarity is. Rada’s measure is an example of similarity measures adapted to taxonomies:
Although, Leacock and Chodorow’s measure is an example of this category which is designed for WordNet [25]:
In this category of measures, Hirst and St-Onge’s measure, that considers the non-taxonomic links, quantifies the weight between two concepts as follows [21]:
Concerning the node-based approaches, they use properties of concepts in the ontology graph for comparing concepts. The most common property is the Information Content (
Resnik’s measure uses the Information Content of the
3.2.Semantic relatedness measures
This section outlines significant works in the literature that addressed the design of semantic relatedness measures. However, these measures are strongly dependent on textual resources. Mazuel and Sabouret [30] have proposed a semantic relatedness measure that evaluates the semantic relatedness of two concepts by considering the object properties in ontologies. They differed between two different types of paths. First, the single-relation path in which all the edges have the same type (e.g., hierarchical relations). Second, the mixed-relation path in which different types of relations (hierarchical and non-hierarchical) are involved. The proposed semantic relatedness measure is composed of three main tasks: (1) consider a set of patterns given in [21] to filter the paths which are not semantically correct; (2) use of the information-theoretic definition of semantic similarity given in [37] to weight the hierarchical edges in the graph; (3) compute the weight of non-hierarchical edges. Finally, the relatedness measure is the sum of these tasks. Another work to cite is a context-vector approach proposed in the biomedical domain [27,34]. This approach aims to compute the semantic relatedness between pair of concepts in the Unified Medical Language System (UMLS).44 The context-vector approach is based on a Gloss Overlaps (i.e., number of shared words in the definitions of two concepts) approach relied on the WordNet55 dictionary [3]. The gloss vector approach combines the definitions of concepts with co-occurrence data in a given corpus (e.g., clinical reports). Every word in the definition is replaced by its context vector from the co-occurrence data and relatedness is calculated as the cosine of the angle between the two vectors. Due to the limitation of semantic relations provided in WordNet (is-a, part-of), the context-vector approach extended the construction of concept definitions by using different relations in the UMLS.
3.3.Topic ontologies
Topic ontologies are considered a special type of ontologies. Their purpose is to identify the “themes” necessary to describe the knowledge structure of an application domain [46]. A topic ontology is represented as a set of topics that are interconnected using semantic relations. Two main types of topic ontologies are defined: simple, and general [28]. The simple topic ontologies are composed of topics linked by hierarchical relations. Meanwhile, in general topic ontologies, transverse relations are included to link different topics in a non-hierarchical scheme. Topic ontologies are being increasingly used in various domains such as semantic matching [45], topic labeling [1], topic modeling [41], evaluating topical search [28] and classification of research articles [38].
The most commonly known approaches for building topic ontologies are the keyword-based construction approaches, which are based mainly on text mining and information retrieval techniques [28,39]. However, these approaches are not efficient, hard, and time-consuming to construct an ontology from a large corpus of documents [28]. In the literature, few works have been found about building topic ontologies from knowledge graphs (e.g., [6]) or Web sources (e.g., [33]). In [6], building topic-specific ontologies from open knowledge graphs such as ConceptNet [43] is presented. A query-based interactive approach is applied for extracting entities and relations from the knowledge graph. Three main phases are defined in this approach: construction of the central taxonomy, ontology enrichment, and ontology cleaning. Another approach to cite is Klink-2 [33], which generates ontologies of research topics [38] by integrating multiple web sources. In particular, Klink-2 analyses networks of research entities (including papers, authors, venues, and technologies) to infer three main types of semantic relationships. For instance, the hierarchical relationships between two entities, which can occur in a set of documents, are inferred by considering the similarity between the distributions of co-occurring keywords and their string similarity. Besides, this approach handles the ambiguity of keywords that are associated with a set of noisy relationships.
3.4.Labeling articles using topic ontologies
As a considerable related work, we present the CSO Classifier, an ontology-driven classifier of scholarly articles [39] according to the Computer Science Ontology (CSO) [38]. CSO includes 14K semantic topics and 162K relationships.66 The CSO Classifier takes as input the text from the metadata associated with a scholarly article (title, abstract, and keywords) and returns a list of CSO research topics. The selection of topics is performed in three steps: (1) identify all topics in the ontology that are explicitly mentioned, or referred, in the paper; (2) identify semantically related topics, that may not be explicitly referred in the article, by utilizing part-of-speech tagging and world embeddings; the word embeddings are used to compute the semantic similarity between the terms in the document and the CSO concepts; (3) enrich the results by including super-areas topics according to CSO.
4.Our semantic relatedness measure
In this section, we propose a hybrid graph-based semantic relatedness measure within topic ontologies. As a contribution to the community of approaches that tend to overcome the limitations of existing measures (e.g., [30]), we designed our measure as a combination of path-based, and node-based approaches. Thus, we comprehensively consider the semantic properties of nodes and edges:
– Weighting of edges: to differentiate between hierarchical and non-hierarchical relations regarding the properties of the paths. This semantic property aims to overcome the limitation of considering all edges equivalent in path-based approaches.
– Weighting and Correlation of nodes: to consider semantic properties of concepts independently from textual resources. The weighting and computing the correlation of a concept aim to measure its neighborhood and coverage in the ontology graph respectively [20]. The application of such semantic properties can overcome the limitation of dependency of texts in node-based approaches.
4.1.Topic ontologies as semantic graphs
For the application of graph-based semantic measures, there is a need to represent ontologies as graphs using a graph-based formalism. In semantic graphs associated to general topic ontologies, we denote topics and instances as nodes and different types of relationships (hierarchical and non-hierarchical) as edges.
Definition 1.
We define the semantic graph associated to a general topic ontology as a directed weighted graph
Definition 2.
The set of neighbours
Definition 3.
The set of hypernyms
Definition 4.
A path
Definition 5.
The length of a path
Definition 6.
The distance
Definition 7.
The size of a semantic graph
4.2.Design of Rel Topic
For designing
4.2.1.Weight allocation for nodes
Inspired by the information-content measures [36,37], that outlined the adequacy of the log function for node weighting [30], we propose the weight allocation for nodes based on this function. In addition, we took advantage of the neighborhood of nodes, and we differentiate between weights for topics and weights for instances. Concerning the topics, weights are formally defined by
1.
2.
4.2.2.Weight allocation for edges
Based on the diversity of relations within the general topic ontologies, the allocation of weights for edges depends mainly on the relations types. Therefore, we consider a static weight allocation which reflects the “strength” of a given relation type [23,30]. Two main types of relations are recognized:
– Hierarchical relations: subclassOf and instance of which are classified as vertical relations with a
– Non-hierarchical: part/whole relations (e.g., part of, has part) and general relations (e.g., facet of, field of work, practiced by, used by). This type of relation is considered being informative and the cost of this edge must be low [30]. Based on the experimentation, the non-hierarchical relations are given a cost
4.2.3.Computation of the degree centrality for nodes
The Degree Centrality of a node is considered as a basic indicator for studying networks and is defined as the number of adjacencies [32]. It corresponds to how much surface the node is correlated to in the whole domain of interest [20]. The degree measure is formally defined, for unweighted graphs, by
In our work, we take advantage of this measure to quantify the degree centrality of topics and instances. We consider that the degree centrality of an instance is related to the degree centrality of its hypernym node(s). More precisely, for every path
1.
2.
4.2.4.Semantic distance computation
In order to estimate the relatedness of two nodes
4.2.5.Semantic relatedness computation
In this section, we present the computation of the semantic relatedness between instances and topics within topic ontologies. Given two elements in a given topic ontology, an instance
5.Topic-OPA: A topic ontology for modeling topics of old press articles
In this study,
Generally, knowledge graphs are very large and contain many entities that are too general or specific to be successfully used as topics for topic labeling [6]. Meanwhile, they can be leveraged to build with moderate efforts small to medium-sized meaningful topic ontologies. As a knowledge graph, we selected Wikidata. It is a free and open knowledge graph and acts as central storage for the structured data of its Wikimedia sister projects, including Wikipedia, Wiktionary, and others [13]. Wikidata stores more than 402 million statements about over 45 million entities [29]. Today, more than 60 million items are described. The data model of Wikidata is based on a directed, labeled graph where entities are connected by edges that are labeled by “properties” [5]. Thus, the system distinguishes two main types of entities: items and properties. Items are uniquely identified by a “Q” followed by a number, such as Paris (Q90). Properties describe detailed characteristics of an item and represented by a “P” followed by a number, such as instance of (P31). Entities are represented by URIs (e.g., http://www.wikidata.org/entity/Q90 for Paris and http://www.wikidata.org/entity/P31 for instance of). In the following, we discuss the ontology definition, specification, requirements, and development.
5.1.Ontology definition
Topic-OPA is defined as a general topic ontology by considering instances and mapping to knowledge graphs [12].
Definition 8.
We define a general topic ontology, in which instances and mapping to knowledge graphs are considered, by
– T the set of topic concepts,
– I the set of instances,
– R the set of predicates: {subClassOf, instance of, part of, use, related by, etc.},
– E the set of relationships:
∗
∗
– ϕ the mapping of T and R to entities in a knowledge graph K.
5.2.Ontology specification and requirements
The ontology specification specifies the purpose and the scope of the topic ontology. Concerning the purpose, Topic-OPA is intended to be used as a knowledge base for a topic labeling system in the domain of old press articles. Regarding the scope, Topic-OPA is application-based domain-dependent ontology. For example, given a corpus of articles of the year 1920, Topic-OPA is constructed from all the disambiguated named entities representing these articles.
For the requirements [44], Topic-OPA has a functional requirement that requires the definition of two different schemes in the ontology: hierarchical and non-hierarchical.
– Hierarchical scheme: consists of hierarchical relations such as subClassOf that permit the inference of knowledge in the ontology graph.
– Non-hierarchical scheme: involves non-hierarchical relations such as related, part of, used by, etc. that have an important implication in the semantic relationships between the concepts.
Besides, Topic-OPA has a non-functional requirement that considers data traceability and scalability by mapping the concepts and the relations of Topic-OPA to entities in open knowledge graphs such as Wikidata.
5.3.Ontology development: SPARQL-based approach
This section discusses a SPARQL-based approach that aims to harvest topic ontologies from open knowledge graphs. A main requirement for this approach is that the domain application is represented by a set of disambiguated named entities. The proposed approach is composed of three main phases: (1) construction of the hierarchical scheme, (2) construction of the non-hierarchical scheme and (3) ontology enrichment. In this study, the ontology development phases are applied in Wikidata.
5.3.1.Building the hierarchical scheme: Bottom-up approach
The hierarchical scheme of Topic-OPA, which represents the taxonomy of topic concepts, can be formally defined by
Definition of the most specific topic concepts At this phase, a SELECT SPARQL query, relying mainly on N and the Knowledge graph K, is applied to define
Meanwhile, for the named entities that are instances of Human (Q5), which is a very general topic, applying the property occupation (P106) is required to fetch more specific topic concepts. In the following, the syntax of q is presented. We denote by entityId, the Wikidata ID of the named entity which is extracted from the URI.

As an example, let us consider a named entity
Extraction of hierarchies The aim of this phase is to build the taxonomy of topic concepts H. The building process starts from the most specific to the most general concepts. For this purpose, a CONSTRUCT SPARQL query

Thereafter, examples of triples extracted based on
5.3.2.Building the non-hierarchical scheme
The non-hierarchical scheme of Topic-OPA can be formally defined by


The results obtained by executing
5.3.3.Ontology enrichment
In this phase, an ontology enrichment process is performed based on
6.The topic labeling process
This section defines the topic labeling process, which is based mainly on
6.1.Named entities as instances of topic-OPA
The named entities are categorized in: persons, locations, organizations and products. For the labeling process, we are interested mainly in: persons, organizations and products. The named entities of the type locations will be used in further works to contextualize the articles. The disambiguated named entities will be assigned as Topic-OPA instances and thereby be added as nodes to the ontology graph. Although, the instance of relations are added as hierarchical edges to the graph. Concerning the named entities associated to locations, they will be used later for contextualizing the articles (e.g., regional, local and international news).
For adding the instances, we took advantage of the properties instance of (P31) and occupation (P106) in Wikidata to select the appropriate classes in Topic-OPA (for the same reason explained in Section 5.3.1). For example, in Wikidata, John Simon (Q352) is an instance of Human (Q5) and related, by field of occupation (P245), to politician, jurist and lawyer. Therefore, in Topic-OPA, John Simon is instance of Politician ⊓ Jurist ⊓ Lawyer.
6.2.Instance-topic mapping: Classification of topics
Let us consider the article
6.3.Ranking and selection of labeling topics
The ranking and selection of labeling topics is accomplished based on the results of the instance-topic mapping process. For
1. Eliminate the non relevant concepts based on three criteria:
(a) Level of abstraction: remove most abstract topic concepts such as, Entity, Occurrent and Knowledge, by considering their depths. In Topic-OPA, these concepts’ depths are less than the average of the depths of all the topic concepts.
(b) Hypernyms of named entities: remove the topic concepts that are hypernyms of the named entities. For instance, by referring to
(c) Hyponyms of general concepts: remove the topic concepts that are hyponyms of Person, Organization, Product and Location. For instance, by referring to
2. Compute the most common topic concepts
3. Compute the size of
4. If
5. Otherwise, if
6. Define two strategies to rank
(a) The relatedness-guided strategy is composed of:
i. Ranking the topic concepts
ii. Selecting the topic concept(s)
(b) The centrality-guided strategy is composed of:
i. Computing the degree centrality of
ii. Ranking the topic concepts
iii. Selecting the topic concept(s)
7. Finally, compute the topic labeling set of
Fig. 3.
Example of articles from Le Matin.

Fig. 4.
Example of articles from the selected corpus of Le Matin.

Fig. 5.
Example of named entities extracted from

7.Use-case: Le Matin
In this section, we present a case study for labeling the old French newspaper Le Matin. For this purpose,
7.1.Topic-OPA of Le Matin
For Building Topic-OPA representing Le Matin, a set of
Fig. 6.
Excerpt of Topic-OPA around the concept Politics.
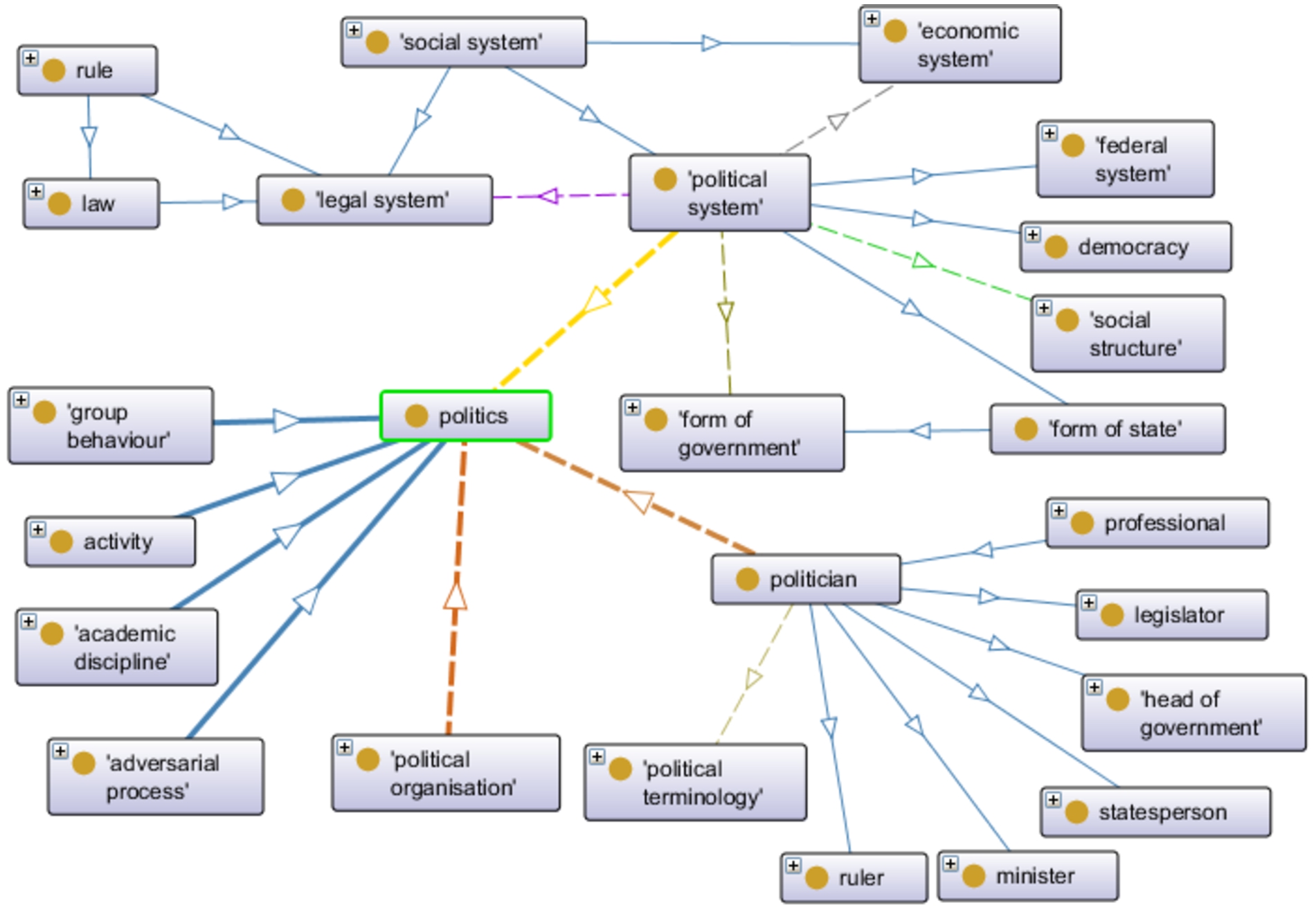
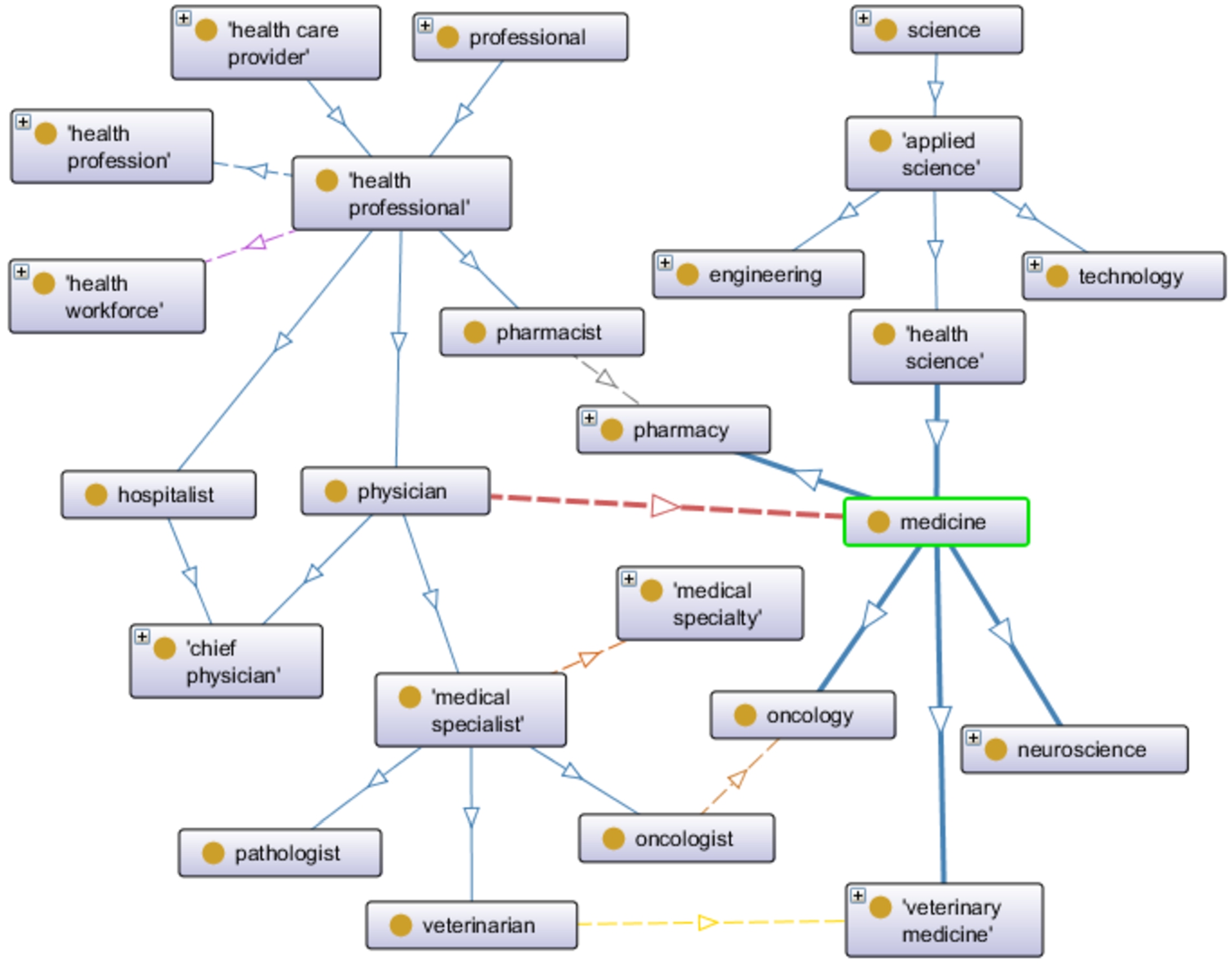
Fig. 7.
Excerpt of Topic-OPA around the concept Medicine.
7.2.Assignment of disambiguated named entities as instances
For each article
Table 1
Assignment of the named entities of the subset articles of A as instances of Topic-OPA
| Article | Named entity | Instance of |
| John Simon | ||
| Ramsay MacDonald | ||
| Adolf Hitler | ||
| Eric Phipps | ||
| Anthony Eden | ||
| Stanley Baldwin | ||
| Foreign Office | ||
| Miguel Primo de Rivera | ||
| ABC | ||
| Jean Benoit-Lévy | ||
| Marie Epstein | ||
| La Maternelle | ||
| Pension Mimosas | ||
| Simone Berriau | ||
| Simone Bourday | ||
| Sylvette Fillacier | ||
| Hubert Prelier | ||
| Camille Bert | ||
| Roland Caillaux | ||
| Henri Debain | ||
| Françoise Rosay | ||
| Paul Appell | ||
| Academy of Toulouse | ||
| Paris Academy | ||
| Legion of Honour | ||
| Georges Pelletier d’Oisy | ||
| René Le Grèves | ||
| Ambrogio Morelli | ||
| Romain Maes | ||
| Félicien Vervaecke | ||
| Charles Pélissier | ||
| Aldo Bertocco | ||
| Académie Nationale de Médecine | ||
| Albert Calmette | ||
| BCG vaccine | ||
| Tuberculose | ||
| Charles Rist | ||
| William H. Woodin | ||
| Trésor public | ||
| Bank of France | ||
| National Bank of Belgium | ||
| Paul van Zeeland |
7.3.Instance-topic mapping
The instance-topic mapping process is performed between each article
However, since Topic-OPA is not curated, it contains a vast number of general concepts. This implies that the average of the relatedness values is low (around 0.28). Such a low value of the threshold makes the overall performance of the classification process be degraded. Experimentation has shown that a threshold of about 0.5 provides good and relevant results. Therefore, we propose to use
For instance, by referring to the articles
Table 2 shows the experimental results of the mapping process of
Table 2
Excerpt of the instance-topic mapping process between
| Instance (i) | Related Topic (t) | |
| Académie Nationale de Médecine | Research Institute | 0.80 |
| Science | 0.76 | |
| Academic District | 0.69 | |
| Academy | 0.80 | |
| National Academy | 0.72 | |
| Albert Calmette | Physician | 0.73 |
| Medicine | 0.66 | |
| Health Professional | 0.58 | |
| Immunology | 0.64 | |
| Bacteriology | 0.64 | |
| Virology | 0.64 | |
| BCG vaccine | Medication | 0.58 |
| Biopharmaceutical | 0.59 | |
| Vaccine | 0.75 | |
| Vaccination | 0.71 | |
| Tuberculose | Disease | 0.67 |
| Health Problem | 0.5 |
7.4.Ranking and selection of labeling topics
Given a set of relevant topics for each instance
In the following, we describe the execution of the ranking and labeling procedure (Section 6.3) for
– By fulfilling step 1 (b), the concepts Academy, National Academy, Physician, Health Professional, Immunologist, Medication, Vaccine, Biopharmaceutical and Disease are eliminated. For instance, Physician and Immunologist are eliminated being hypernyms of the instance Albert Calmette.
– Furthermore, concepts such as Physicist and Research Institute are eliminated by fulfilling step 1 (c). Physicist is a hyponym of Person and Research Institute is a hyponym of Organization.
– The aim of step 2 is to compute the most common topics
– step 5 computes the average of relatedness values for each common topic concept
– By achieving step 6 and step 7,
Although,
In addition,
Table 3
Ranking and selection of labeling topics
| Threshold | Most Common Topics ( | Degree Centrality | Relatedness-Guided | Centrality-Guided | Selected Topics | ||
| 0.55 | Politics | 0.68 | 29.17 | Politics | Politics | Politics | |
| Political Activism | 0.56 | 6.94 | |||||
| 0.55 | Military Affairs | 0.67 | 6.94 | Military Affairs | War | Military Affairs-War | |
| Political Activism | 0.62 | 6.94 | |||||
| War | 0.59 | 22.22 | |||||
| 0.59 | Art | – | – | – | – | Art | |
| 0.52 | Higher Education | 0.58 | 15.28 | Higher Education | Science | Higher Education-Science | |
| Science | 0.55 | 23.62 | |||||
| 0.61 | Aviation | – | – | – | – | Aviation | |
| 0.55 | Cycle Sport | 0.68 | 13.20 | Cycle Sport | Cycling | Cycle Sport-Cycling | |
| Cycling | 0.59 | 27.38 | |||||
| Sport | 0.55 | 13.89 | |||||
| 0.58 | Vaccination | 0.71 | 13.48 | Vaccination | Vaccination | Vaccination | |
| Bacteriology | 0.64 | 7.64 | |||||
| Immunology | 0.64 | 7.64 | |||||
| Medicine | 0.58 | 7.64 | |||||
| Virology | 0.64 | 7.64 | |||||
| 0.51 | Economics | – | – | – | – | Economics |
8.Evaluation and comparison
The first part of this section evaluates Topic-OPA being an application-based ontology. The second part assesses the performance of
8.1.Evaluation of Topic-OPA
In the literature, various approaches for evaluating ontologies are recognized. These approaches are categorized depending on what kind of ontologies are being evaluated and for what purpose [7]. Examples of these approaches are [15]: gold standard-based, corpus-based, application-based, and criteria-based. In order to choose the “best” evaluation approach, there is a need to define the motivation behind evaluating a developed ontology [15]. In our study, as evoked earlier, Topic-OPA is an application-based ontology that is intended to be used in a topic labeling system for classifying and labeling a given set of old press articles. Thereby, gold standard-based and corpus-based approaches are eliminated for the following reasons. The former aims to compare the developed ontology with a previously created reference ontology. However, having a suitable gold ontology can be challenging since it should be created under similar conditions with similar goals to the developed ontology. The latter is eliminated since it is strongly dependent on textual resources. Therefore, the application-based and criteria-based approaches are applied to evaluate the performance and the semantic accuracy of Topic-OPA.
8.1.1.Application-based evaluation
The application-based approach evaluates the performance of ontologies in a specific task. Topic-OPA is employed for labeling old press articles by using it as a knowledge base. Technically, the semantic relatedness measure
8.1.2.Structure-based evaluation
The structure-based approach quantifies how far an ontology adheres to specific desirable criteria (e.g., size and complexity). This approach is recommended as an efficient approach for evaluating the learned ontologies [10]. Several measures have been recognized for the structure-based evaluation such as Knowledge coverage and popularity measures (e.g., number of classes and number of properties) and structural measures (e.g., maximum depth, average depth, depth variance, etc.) [15]. The application of these measures relies on the assumption that is a richly populated ontology, with higher depth and breadth variance, is more likely to provide reliable semantic content. In contrast to Knowledge coverage and popularity measures, the structural measures are positively correlated with the semantic accuracy of the knowledge modeled in the ontology [40].
In the context of Topic-OPA, we quantified the following structural measures by considering the taxonomic structure of Topic-OPA: (1) Maximum depth, that represents the length of the longest taxonomic branch in the ontology, is measured as the number of concepts from the root node to the leaves of the taxonomy (
8.2.Evaluation of Rel Topic
The evaluation of
8.2.1.Quantitative evaluation
For evaluating the relevance of the generated topics, a quantitative evaluation is used by considering human-based labeling [1] and rating [24] methods. For this purpose, we considered A as the corpus of 48 articles from Le Matin that we have introduced in Section 7. Since humans can be in contradiction for evaluating specific articles, three different annotators are involved for labeling and rating each article,
Table 4
Excerpt of human labeling of the articles represented in Table 3
| Annotator1 | Annotator2 | Annotator3 | |
| International Politics | International Relations | International Politics | |
| Politics | Foreign Policy | Politics | |
| Cinema | Art, Cinema | Cinema | |
| Higher Education | Politics, Education | Politics, Science | |
| Aviation | Event, Exploration, Aviation | Aviation | |
| Cycling | Sport, Cycling | Cycling | |
| Medicine | Science, Medicine | Science, Vaccination | |
| Economics | Economics | Finance |
To resume, our approach has an agreement quite close to the annotators’ agreement. For the rating method, the humans are asked to rate
Table 5
Excerpt of human rating of the articles represented in Table 3
| Annotator1 | Annotator2 | Annotator3 | |
| 2 | 2 | 2 | |
| 0 | 0 | 2 | |
| 2 | 3 | 2 | |
| 3 | 2 | 2 | |
| 3 | 2 | 3 | |
| 3 | 3 | 3 | |
| 2 | 2 | 3 | |
| 3 | 3 | 2 |
In the following, we analyze the cases where
Fig. 8.
Le Matin.

The existence of not disambiguated named entities In the presented use-case (Section 7), 20 articles have been represented by some named entities that are not disambiguated (e.g.,
The influence of the lack of named entities types As evoked earlier, in this study, we are interested in three main types of named entities: person, organization and product. In this section, we discuss the influence of the lack of some types on the relevance of generated topics. For instance, article
Table 6
Assignment of the disambiguated named entities of
| Article | Named Entity | Instance of |
| César Caire | ||
| Henri Galli | ||
| Emile Desvaux | − | |
| Ambroise Rendu | ||
| Alexandre Luquet | ||
| Flour | ||
| Wheat |
8.2.2.Qualitative evaluation
The qualitative evaluation assesses the labeling topics generated by
– Highly correlated: a concept with high degree centrality designates a large surface of connection with the concepts within the ontology. For instance, Politics, War, Science, Art and Sport have respectively 29.17, 22.22, 23.62, 31.34 and 13.89 values of degree centrality. Meanwhile, concepts such as Activity, Occupation and Group Behaviour have respectively 8.68, 9.81 and 7.63 values of degree centrality.
– Core concept: the depth of concepts in ontologies indicates their degree of generality. In Topic-OPA, abstract concepts, such as Entity, Agent, Object, Product and Occurrence are located at depths less than the average of depths in Topic-OPA which is equal to 4 (e.g.,
– Not a hypernym of named entities: a labeling topic is not linked hierarchically to the named entities. Therefore, it is not a subclass of Person, Organization, Location or Product.
8.3.Evaluation of topic labeling using Rel Topic
To evaluate the performance of topic labeling using
To automatically label these articles with
1. Construct a topic ontology representing the application domain named Topic-RPA (Topic ontology for Recent Press Articles). Thus, the SPARQL-based approach (Section 5.3) is applied based on the articles’ disambiguated named entities (the number of disambiguated named entities is 371). As a result, we obtained Topic-RPA, a not curated topic ontology composed of 2616 concepts, 1584 object properties, and 4132 SubClassOf relations. In contrast to Topic-OPA, Topic-RPA contains contemporary concepts such as Computer Science, Telecommunication, and Electronic Journal. Meanwhile, semantic properties such as the average depth is identical in both ontologies (
2. Application of the topic labeling process using
8.4.Comparison of Rel Topic
In this section, we compare
Table 7
Excerpt of the results of the instance-topic mapping process of
| Instance (i) | Topic Concepts ( | ||||
| Académie Nationale de Médecine | Research Institute | 0.5 | 7 | 0.87 | 0.81 |
| Education | 0.33 | 6 | 0.75 | 0.7 | |
| Research | 0.33 | 6 | 0.75 | 0.76 | |
| Higher Education | 0.25 | 5 | 0.62 | 0.57 | |
| Business | 0.14 | 3 | 0.37 | 0.32 | |
| Economics | 0.16 | 3 | 0.37 | 0.33 | |
| Albert Calmette | Physician | 0.5 | 7 | 0.87 | 0.73 |
| Medicine | 0.33 | 6 | 0.75 | 0.66 | |
| Immunology | 0.33 | 6 | 0.75 | 0.64 | |
| Science | 0.25 | 4 | 0.5 | 0.59 | |
| Business | 0.16 | 3 | 0.37 | 0.31 | |
| Alfred Boquet | Physician | 0.5 | 7 | 0.87 | 0.74 |
| Veterinary Medicine | 0.33 | 6 | 0.75 | 0.69 | |
| Science | 0.25 | 4 | 0.5 | 0.61 | |
| Business | 0.16 | 3 | 0.37 | 0.31 | |
| BCG vaccine | Vaccination | 0.33 | 6 | 0.75 | 0.71 |
| Medication | 0.33 | 6 | 0.75 | 0.68 | |
| Health Care | 0.25 | 4 | 0.5 | 0.48 | |
| Business | 0.14 | 2 | 0.25 | 0.3 |
Fig. 9.
Comparison of the results of the instance-topic mapping of
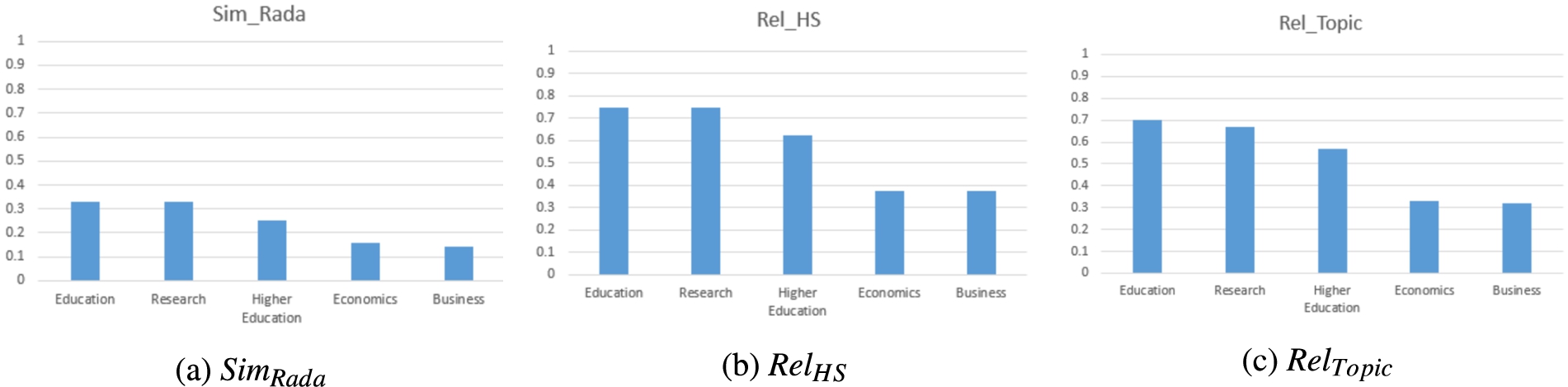
9.Discussion
This study’s main contribution is the design of a novel graph-based semantic relatedness measure, named
This study’s second contribution is developing the general topic ontology Topic-OPA using a SPARQL-based automatic approach. Topic-OPA is harvested from open knowledge graphs (e.g., Wikidata) based on a set of disambiguated named entities representing the application domain. Topic-OPA is a domain-dependent topic ontology since it is developed from the named entities of the given domain. Nevertheless, if Topic-OPA is developed from all the named entities of the application domain (e.g., Le Matin), it could be reused as a topic ontology for labeling old press articles of any journal or newspaper belonging to the same period of time. We assume that approximately the same types of persons (e.g., politician, diplomat, actor, physician, botanist, etc.), organizations (e.g., bank, public treasury, academy, etc,), or products (e.g., vaccine, film, etc.) are available during a comparable period of time (e.g., 1910–1945). Besides, the SPARQL-based approach is reusable (as shown in Section 8.3 in the case of recent newspapers) for harvesting ontologies from open knowledge graphs, requiring the starting named entities representing the domain of discourse.
Finally, a significant contribution is applying an ontology-based automatic topic labeling approach for labeling press articles. This process, which is composed of a topic ontology and the semantic relatedness measure
In this context, an important question arises. What if there is a lack of named entities, or if they are ambiguous or inexact? This situation contemplates the validity of this work’s general hypothesis (see Section 2). In Section 8.2.1, we analyzed the influence of two issues on the generated results: (1) existence of not disambiguated named entities and (2) lack of some types of named entities. Both of them had an impact on the generated topics. However, this impact is relative depending on the named entities representing the text to label. For example, the first issue has affected the generality of the assigned topic (e.g., Science is given instead of Medicine). Meanwhile, the second issue has affected the relevance of the assigned topic (e.g., Politics is given instead of Economics).
To resume, the relevance of the whole framework’s outcome is a crucial measure of the validity of this work’s hypothesis. Thus, the given named entities representing the articles are valid if
10.Conclusion
The task of automatically labeling newspaper articles according to a predefined set of topics is a challenging research issue, specifically in cultural heritage. A pertinent characterization of the application domain is required for this purpose. In the context of the ASTURIAS project, which aims to label a vast number of old press articles automatically, we envisaged graph-based semantic measures. These measures have shown effective results in different areas such as knowledge engineering, Semantic Web, and Natural Language Processing. Graph-based semantic measures are composed of similarity and relatedness measures. The former class is adapted to taxonomies and widely investigated in the community. The latter class is adapted to ontologies, and few attempts have been found in the literature to design such measures. Designing semantic relatedness measures is a challenging research task. Nevertheless, they are valuable since they inspect the semantic properties of entities in ontologies.
In this study, we proposed a novel semantic relatedness measure, named
The proposed approach is evaluated using a dual evaluation approach. First, a quantitative evaluation is performed with the help of three different annotators. The human annotators have assigned labels to a corpus of 48 articles from Le Matin. Our approach has shown an agreement quite close to that shown by humans for exact, specific, or general topics. Furthermore, the annotators have rated the results of
In future works, we will be interested in the following tasks. First, the contextualization of the articles is envisaged taking into account the named entities of type location (e.g.,
Notes
1 Structural Analysis and Semantic Indexing of Newspaper Articles.
2 https://gallica.bnf.fr/ark:/12148/cb328123058/date, last visited on April 8, 2020.
4 https://www.nlm.nih.gov/research/umls/index.html, last visited February 4, 2021.
5 https://wordnet.princeton.edu/, last visited February 5, 2021.
6 https://w3id.org/cso/downloads, last visited February 4, 2021.
7 https://protege.stanford.edu/, last visited July 23, 2020.
8 https://journals.openedition.org/primatologie/2816?lang=en, last visited April 27, 2020.
9 http://www.pathexo.fr/documents/notices/leger.html, last visited April 27, 2020.
10 https://en.wikipedia.org/wiki/Topic_and_comment, last visited April 28, 2020.
Acknowledgements
This work is funded by the Normandy Region (France) and the European Union with the European Regional Development Fund (ERDF).
References
[1] | M. Allahyari and K. Kochut, A knowledge-based topic modeling approach for automatic topic labeling, International Journal of Advanced Computer Science and Applications 8: (9) ((2017) ), 335–349. doi:10.14569/IJACSA.2017.080947. |
[2] | Y. Andrew, M.D. Blei and M.I. Jordan, Latent Dirichlet allocation, The Journal of Machine Learning Research 3: ((2003) ), 993–1022. |
[3] | S. Banerjee and T. Pedersen, Extended gloss overlaps as a measure of semantic relatedness, in: Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, Acapulco, Mexico, (2003) , pp. 805–810. |
[4] | R. Bellman, On a routing problem, Quarterly of Applied Mathematics 16: ((1958) ), 87–90. doi:10.1090/qam/102435. |
[5] | A. Bielefeldt, J. Gonsior and M. Krotzsch, Practical linked data access via SPARQL: The case of Wikidata, in: Proceedings of the WWW2018 Workshop on Linked Data on the Web (LDOW-18), CEUR Workshop Proceedings, (2018) . |
[6] | K. Böhm and M. Ortiz, A tool for building topic-specific ontologies using a knowledge graph, in: Proceedings of the 31st International Workshop on Description Logics Co-Located with KR 2018, (2018) . |
[7] | J. Brank, M. Grobelnik and D. Mladenić, A survey of ontology evaluation techniques, in: Proceedings of the Conference on Data Mining and Data Warehouses (SiKDD 2005), (2005) . |
[8] | E. Chernyak, An approach to the problem of annotation of research publications, in: Proceedings of the Eighth ACM International Conference on Web Search and Data Mining – WSDM’15, (2015) , pp. 429–434. doi:10.1145/2684822.2697032. |
[9] | C. D’Amato, Similarity-based learning methods for the semantic web, Ph.D. thesis, Universita degli Studi di Bari, 2007. |
[10] | K. Dellschaft and S. Staab, Strategies for the evaluation of ontology learning, in: Proceedings of the 2008 Conference on Ontology Learning and Population: Bridging the Gap Between Text and Knowledge, Frontiers in Artificial Intelligence and Applications, (2008) , pp. 253–272. |
[11] | E.W. Dijkstra, A note on two problems in connexion with graphs, Numerische Mathematik 1: ((1959) ), 269–271. doi:10.1007/BF01386390. |
[12] | M. El Ghosh, C. Zanni-Merk, N. Delestre, J.P. Kotowicz and H. Abdulrab, Topic-OPA: A topic ontology for modeling topics of old press articles, in: Proceedings of the 12th International Conference on Knowledge Engineering and Ontology Development, (2020) , pp. 275–282. doi:10.5220/0010147202750282. |
[13] | F. Erxleben, M. Günther, M. Krötzsch, J. Mendez and D. Vrandečić, Introducing Wikidata to the linked data web, in: The Semantic Web Conference – ISWC 2014, LNCS, (2014) , pp. 50–65. doi:10.1007/978-3-319-11964-9_4. |
[14] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer-Verlag, Berlin Heidelberg (DE), (2013) . doi:10.1007/978-3-642-38721-0. |
[15] | M. Fernández, C. Overbeeke, M. Sabou and E. Motta, What makes a good ontology? A case-study in fine-grained knowledge reuse, in: The Semantic Web, Springer, Berlin, Heidelberg, (2009) , pp. 61–75. doi:10.1007/978-3-642-10871-6_5. |
[16] | S. Fernando and M. Stevenson, A semantic similarity approach to para-phrase detection, in: Proceedings of Computational Linguistics Colloquium, U.K., (2008) , pp. 45–52. |
[17] | N. Fiorini, S. Ranwez, J. Montmain and V. Ranwez, USI: A fast and accurate approach for conceptual document annotation, BMC Bioinformatics 16: (83) ((2015) ), 1–10. doi:10.1186/s12859-015-0513-4. |
[18] | P.H. Guzzi, M. Mina, C. Guerra and M. Cannataro, Semantic similarity analysis of protein data: Assessment with biological features and issues, Briefings, Bioinformatics 13: (5) ((2012) ), 569–585. doi:10.1093/bib/bbr066. |
[19] | S. Harispe, S. Ranwez, S. Janaqi and J. Montmain, Semantic similarity from natural language and ontology analysis, Synth. Lect. Hum. Lang. Technol 8: ((2015) ), 1–254. doi:10.2200/S00639ED1V01Y201504HLT027. |
[20] | J. Heitzig, N. Marwan, Y. Zou, J. Donges and J. Kurths, Consistently weighted measures for complex network topologies, Europ. Phys. J. B. 85: ((2011) ), 1–16. |
[21] | G. Hirst and D. St-Onge, Lexical chains as representations of context for the detection and correction of malapropisms, in: WordNet: An Electronic Lexical Database, (1998) , pp. 305–332. |
[22] | T. Hofmann, Probabilistic latent semantic indexing, in: Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, New York, (1999) , pp. 50–57. doi:10.1145/312624.312649. |
[23] | J. Jiang and D. Conrath, Semantic similarity based on corpus statistics and lexical taxonomy, in: Proc. on International Conference on Research in Computational Linguistics, Taiwan, (1997) , pp. 19–33. |
[24] | J.H. Lau, K. Grieser, D. Newman and T. Baldwin, Automatic labelling of topic models, in: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, (2011) , pp. 1536–1545. |
[25] | C. Leacock and M. Chodorow, Filling in a sparse training space for word sense identification, in: Proceedings of the 14th International Joint Conference on Artificial Intelligence, (1995) , pp. 448–453. |
[26] | D. Lin, An information-theoretic definition of similarity, in: Proceedings of the Fifteenth International Conference on Machine Learning, ICML, (1998) , pp. 296–304. |
[27] | Y. Liu, B.T. Mclennes, T. Pedersen, G. Melton-Meaux and S. Pakhomov, Semantic relatedness study using second order co-occurrence vectors computed from biomedical corpora, UMLS and WordNet, in: Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, (2012) , pp. 363–372. doi:10.1145/2110363.2110405. |
[28] | A.G. Maguitman, R.L. Cecchini, C.M. Lorenzetti and F. Menczer, Using topic ontologies and semantic similarity data to evaluate topical search, in: Proceedings of 36th Latin American Informatics Conference (CLEI), (2010) . |
[29] | S. Malyshev, M. Krotzsch, L. Gonzalez, J. Gonsior and A. Bielefeldt, Getting the most out of Wikidata: Semantic technology usage in Wikipedia’s knowledge graph, in: Proceedings of the 17th International Semantic Web Conference (ISWC’18), LNCS, Springer, (2018) , pp. 376–394. |
[30] | L. Mazuel and N. Sabouret, Semantic relatedness measure using object properties in an ontology, in: The Semantic Web – ISWC 2008, A. Sheth et al., eds, LNCS, Vol. 5318: , Springer, Berlin, Heidelberg. doi:10.1007/978--3-540-88564-1_43. |
[31] | melghosh. (2022). melghosh/RelTopic: SWJ (v1.0.2-beta). Zenodo. doi:10.5281/zenodo.6201279. |
[32] | T. Opsahl, F. Agneessens and J. Skvoretz, Node centrality in weighted networks: Generalizing degree and shortest paths, Social Networks 32: (3) ((2010) ), 245–251. doi:10.1016/j.socnet.2010.03.006. |
[33] | F. Osborne and E. Motta, Klink-2, integrating multiple web sources to generate semantic topic networks, in: The Semantic Web Conference – ISWC 2015, LNCS, Springer International Publishing, Cham, (2015) , pp. 408–424. doi:10.1007/978-3-319-25007-6_24. |
[34] | T. Pedersen, S.V.S. Pakhomov, S. Patwardhan and C.G. Chute, Measures of semantic similarity and relatedness in the biomedical domain, Journal of Biomedical Informatics 40: (3) ((2007) ), 288–299. doi:10.1016/j.jbi.2006.06.004. |
[35] | R. Rada, H. Mili, E. Bicknell and M. Blettner, Development and application of a metric on semantic nets, IEEE Transactions on Systems, Man and Cybernetics 19: ((1989) ), 17–30. doi:10.1109/21.24528. |
[36] | P. Resnik, Using information content to evaluate semantic similarity in a taxonomy, in: 14th International Joint Conference on Artificial Intelligence, (1995) , pp. 448–453. |
[37] | P. Resnik, Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language, J. Artif. Intell. Res. 11: ((1998) ), 95–130. doi:10.1613/jair.514. |
[38] | A. Salatino, T. Thanapalasingam, A. Mannocci, F. Osborne and E. Motta, The computer science ontology: A large-scale taxonomy of research areas, in: The Semantic Web – ISWC, (2018) , pp. 187–205. doi:10.1007/978-3-030-00668-6_12. |
[39] | A. Salatino, T. Thanapalasingam, A. Mannocci, F. Osborne and E. Motta, The CSO classifier: Ontology-driven detection of research topics in scholarly articles, in: Digital Libraries for Open Knowledge, (2019) , pp. 296–311. doi:10.1007/978-3-030-30760-8_26. |
[40] | D. Sanchez, M. Batet, S. Martinez and J.D. Ferrer, Semantic variance: An intuitive measure for ontology accuracy evaluation, Engineering Applications of Artificial Intelligence 39: ((2015) ), 89–99. doi:10.1016/j.engappai.2014.11.012. |
[41] | J. Sleeman, T. Finin and M. Halem, Ontology-grounded topic modeling for climate science research, in: Proceedings of Semantic Web for Social Good Workshop, ISWC, (2018) . |
[42] | J. Sosnowska and O. Skibski, Attachment centrality for weighted graphs, in: Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), (2017) , pp. 416–422. |
[43] | R. Speer, J. Chin and C. Havasi, Conceptnet 5.5: An open multilingual graph of general knowledge, in: AAAI, (2017) , pp. 4444–4451. |
[44] | M.C. Suárez-Figueroa, A. Gómez-Pérez and B. Villazón-Terrazas, How to write and use the ontology requirements specification document, in: On the Move to Meaningful Internet Systems: OTM 2009, R. Meersman, T. Dillon and Herrero, eds, LNCS, Springer, Berlin, Heidelberg, (2009) . |
[45] | Y. Tang, P.D. Baer, G. Zhao and R. Meersman, On constructing, grouping and using topical ontology for semantic matching, in: Proceedings of OTM 2009 Workshops, R. Meersman, P. Herrero and T. Dillon, eds, Vol. 5872: , Springer, Heidelberg, (2009) , pp. 816–825. |
[46] | G. Zhao and R. Meersman, Architecting ontology for scalability and versatility, in: On the Move to Meaningful Internet Systems 2005: CoopIS, DOA, and ODBASE, OTM 2005, R. Meersman and Z. Tari, eds, LNCS, Vol. 3761: , Springer, Berlin, Heidelberg, (2005) . |
[47] | Y. Zuo, J. Zhao and K. Xu, Word network topic model: A simple but general solution for short and imbalanced texts, Knowledge and Information Systems 48: ((2016) ), 379–398. doi:10.1007/s10115-015-0882-z. |


