
Discovering alignment relations with Graph Convolutional Networks: A biomedical case study
Abstract
Knowledge graphs are freely aggregated, published, and edited in the Web of data, and thus may overlap. Hence, a key task resides in aligning (or matching) their content. This task encompasses the identification, within an aggregated knowledge graph, of nodes that are equivalent, more specific, or weakly related. In this article, we propose to match nodes within a knowledge graph by (i) learning node embeddings with Graph Convolutional Networks such that similar nodes have low distances in the embedding space, and (ii) clustering nodes based on their embeddings, in order to suggest alignment relations between nodes of a same cluster. We conducted experiments with this approach on the real world application of aligning knowledge in the field of pharmacogenomics, which motivated our study. We particularly investigated the interplay between domain knowledge and GCN models with the two following focuses. First, we applied inference rules associated with domain knowledge, independently or combined, before learning node embeddings, and we measured the improvements in matching results. Second, while our GCN model is agnostic to the exact alignment relations (e.g., equivalence, weak similarity), we observed that distances in the embedding space are coherent with the “strength” of these different relations (e.g., smaller distances for equivalences), letting us considering clustering and distances in the embedding space as a means to suggest alignment relations in our case study.
1.Introduction
The Semantic Web [3] offers tools and standards that facilitate the construction of knowledge graphs [17] that may aggregate data and elements of knowledge of various provenances. The combined use of these scattered elements of knowledge allows access to a larger extent of the available knowledge, which is beneficial to many applications, such as fact-checking or query answering. For this conjoint use to be possible, one crucial task lies in matching units across knowledge graphs or within an aggregated knowledge graph, i.e., finding alignments or correspondences between nodes, edges, or subgraphs. This task is well-studied in the Ontology Matching research field [12] and is challenging since knowledge graphs differ in quality, completeness, vocabularies, and languages. Consequently, different alignment relations may hold between units: some may indicate that two units are equivalent, weakly related, or that one is more specific than the other.
In the present work, we focus on matching specific nodes within an aggregated knowledge graph represented within Semantic Web standards. We view such a knowledge graph as a directed and labeled multigraph in which nodes represent entities of a world – also named individuals – (e.g., places, drugs), literals (e.g., dates, integers), or classes of individuals (e.g., Person, Drug). It should be noted that we discard litterals from the scope of the present work. Nodes are linked together through edges defined as triples
Fig. 1.
Outline of our approach. Gold clusters are computed from existing alignments between the nodes to match in the knowledge graph (e.g., owl:sameAs, skos:broadMatch, skos:related, etc.). These alignments are then removed and various inferences rules associated with domain knowledge are applied on the knowledge graph. Embeddings of nodes are learned with Graph Convolutional Networks (GCNs) and the Soft Nearest Neighbor (SNN) loss. Clustering algorithms are then applied on the embedding space and the resulting clusters are evaluated with regard to the gold clusters. A distance analysis is also performed for each alignment relation.
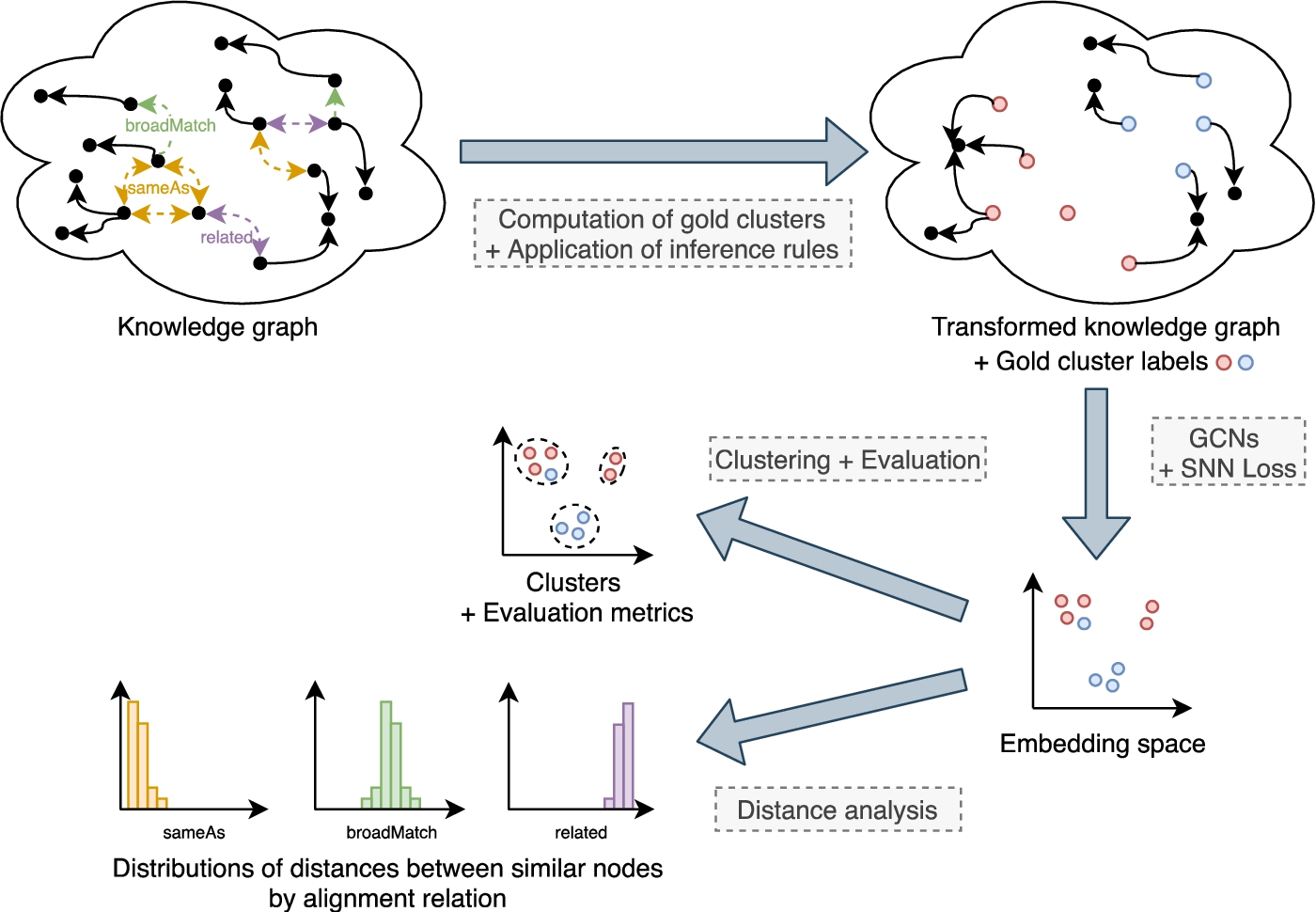
We propose to match specific individuals that represent n-ary relationships through an approach that combines graph embedding and clustering, outlined in Fig. 1. Graph embeddings are low-dimensional vectors that represent graph substructures (e.g., nodes, edges, subgraphs) while preserving as much as possible the properties of the graph [5]. More precisely, we learn node embeddings with Graph Convolution Networks (GCNs) [20,29] such that similar nodes have a low distance between their embeddings. We employ graph embeddings since their continuous nature may provide the needed flexibility to cope with the heterogeneous representations of nodes to match [15]. GCNs compute the embedding of a node by considering the embeddings of its neighbors in the graph. Hence, nodes with similar neighborhoods will have similar embeddings, what is well-adapted to a structural and relational matching approach [26,33].
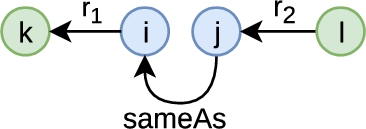
To suggest alignment relations from node embeddings, we apply a clustering algorithm on the embedding space and consider nodes that belong to the same cluster as similar. The resulting clusters are evaluated by comparison with gold clusters, i.e., reference clusters that we aim to reproduce. We define these gold clusters as groups of nodes linked directly or indirectly by preexisting alignments we obtained from a rule-based method previously published [21]. These pre-existing alignments use five different alignment relations. For example, nodes may be identical (owl:sameAs links), one may be more specific than the other (skos:broadMatch links), or weakly similar (skos:related links). Hence, our approach is supervised and requires the preexistence of such alignments.
Within our approach, we particularly investigated the interplay between GCNs and domain knowledge through the two following aspects. First, similarly to existing works with different embedding models [18], we applied various inference rules associated with domain knowledge (e.g., class and predicate hierarchies, symmetry and transitivity of predicates), independently or combined, before learning node embeddings, and we measured the improvements or declines in matching results. Second, we explored how embeddings can differentiate between different types of alignment relations. We made our GCN model agnostic to these exact relations during learning. However, we observed that distances between the embeddings of similar nodes are different and coherent with the type and “strength” of each alignment relation (e.g., smaller distances for equivalences, larger distances for weak similarities). Such results allow us to think that distances in the embedding space can be used to suggest alignment relations to connect nodes, in respect with distinct types of similarities. To the best of our knowledge, our approach is the first one to investigate these aspects in a matching task, combining GCNs and clustering.
Our approach based on GCNs was motivated by the need to align pharmacogenomic (PGx) knowledge that we previously aggregated in a knowledge graph named PGxLOD [22]. The biomedical domain of PGx studies the influence of genetic factors on drug response phenotypes. As an example, Fig. 2 depicts the relationship
Fig. 2.
Representation of a PGx relationship between gene CYP2C9, drug warfarin and phenotype vascular_disorders. This relationship is reified through the individual pgr_1, connecting its components through the causes predicate.

The remainder of this paper is organized as follows. In Section 2, we outline some works related to node matching in knowledge graphs and graph embeddings. We detail the core of our matching approach (node embeddings and clustering) in Section 3, and how inference rules associated with domain knowledge are considered in Section 4. In Section 5, we conduct experiments with this approach on PGxLOD, a large knowledge graph we built that contains 50,435 PGx relationships [22]. Finally, we discuss our results and conclude in Section 6 and 7.
2.Related work
2.1.Matching
Numerous papers exist about knowledge graph matching. The interested reader could refer to the book of Euzenat and Shvaiko [12] for a formalization of the matching task, and a detailed presentation of the main methods. In the following, we focus on graph embedding techniques. Such techniques have been successfully applied on knowledge graphs for various tasks such as node classification, link prediction, or node clustering [5,32]. Interestingly, the task of matching nodes can be alternatively tackled as a link prediction task (i.e., predicting alignments between nodes) or as a node clustering task (i.e., grouping similar nodes into clusters). Here, we choose the node clustering approach.
2.2.Graph embedding
Existing papers about graph embedding differ in the considered type of graphs (e.g., homogeneous graphs, heterogeneous graphs such as knowledge graphs) or in the embedding techniques (e.g., matrix factorization, deep learning with or without random walk). The survey of Cai et al. [5] presents a taxonomies of graph embedding problems and techniques. Hereafter, a few specific examples are detailed but a more thorough overview can be found in the following surveys [5,24,32]. Some approaches are translational. For example, TransE [4] computes for each triple
2.3.Graph Convolutional Networks (GCNs)
The approach adopted in this article is based on Graph Convolutional Networks (GCNs). GCNs have been introduced for semi-supervised classification over graphs [20] and extended for entity classification and link prediction in knowledge graphs [29]. In contrast with TransE and RDF2Vec that work at the triple and sequence levels, GCNs compute the embedding of a node by considering its neighborhood in the graph. Hence, as aforementioned, we believe GCNs are well-suited for our application of matching reified n-ary relationships since similar relationships have similar neighborhoods. Other existing works rely on this assumption that similar nodes have similar neighborhoods and use GCNs for their matching. For example, Wang et al. [33] propose to align cross-lingual knowledge graphs by using GCNs to learn node embeddings such that nodes representing the same entity in different languages have close embeddings. Pang et al. [26] use the same approach to align two knowledge graphs, but introduce an iterative aspect. Some newly-aligned entities are selected and used when learning embeddings in the next iteration. To avoid introducing false positive alignments, the newly-aligned entities are selected with a distance-based criteria proposed by the authors. Interestingly, the two previous approaches take into account literals in the embedding process and use the triplet loss, also used by TransE. On the contrary, in our work, we discard literals and use the Soft Nearest Neighbor loss [13] to consider all positive and negative examples instead of sampling.11
2.4.Graph embedding and domain knowledge
However, previous methods do not consider inference rules associated with domain knowledge represented in knowledge graphs on the contrary of recent papers [27]. For example, Iana and Paulheim [18] evaluate the RDF2Vec embedding model when inferred triples associated with subproperties, symmetry, and transitivity of predicates are added to the knowledge graph. Interestingly, the addition of inferred triples seems to degrade the performance of RDV2Vec embeddings in downstream applications (e.g., regression, classification). Instead of materializing inferred triples into the knowledge graph, d’Amato et al. [10] propose to inject domain knowledge in the learning process by defining specific loss functions and scoring functions for triples. Logic Tensor Networks [30] learn groundings of logical terms and logical clauses. The grounding of a logical term consists in a vector of real numbers (i.e., an embedding) and the grounding of a logical clause is a real number in the interval
These related works and our preliminary results [23] inspired the present work where we investigate how (i) inference rules associated with domain knowledge can improve the performances in node matching and (ii) the distance in the embedding space is representative of the type and “strength” of alignment relations, and thus can be used to suggest the specific relation to use between matched nodes.
3.Matching nodes with Graph Convolutional Networks and clustering
3.1.Approach outline
Our approach is outlined in Fig. 1.
It takes as input an aggregated knowledge graph
1. Learn embeddings for all nodes in
2. Apply a clustering algorithm only on the embeddings of nodes from S and consider nodes belonging to the same cluster as similar (Section 3.3).
It should be noted that gold clusters can result from another automatic matching method or a manual alignment by an expert. For example, in Section 5, our gold clusters are computed from alignments semi-automatically obtained with rules manually written by experts [21]. These alignments can use different alignment relations (e.g., equivalence, weak similarity). We further detail in Section 5.1 how distinct relations are taken into account in our experiments.
3.2.Learning node embeddings with Graph Convolutional Networks and the Soft Nearest Neighbor loss
To learn embeddings for all nodes in
Graph Convolutional Networks (GCNs) can be seen as a message-passing framework of multiple layers, in which the embedding
The number of predicates in
Recall that our objective is to cluster similar nodes, which differs from previous applications of GCNs (e.g., node classification, link prediction [20,29,33]). Hence, we propose to train GCNs from scratch by minimizing the Soft Nearest Neighbor (SNN) loss which, to the best of our knowledge, has never been used with GCN models before. This loss was defined by Frosst et al. [13] and is presented in Eq. (3),
– A set N of nodes belonging to the gold clusters (see Section 5.2).
– A set Y of labels for nodes in N. These labels corresponds to the assignments of nodes in N to the gold clusters.
– A temperature T.
– Embeddings h of nodes. These embeddings are the output of the last layer of the GCN model.
The computation of
This step enables to learn embeddings for all nodes in
3.3.Matching nodes by clustering their embeddings
After embeddings of all nodes in the graph have been output by the last layer of the GCN, we perform a clustering on embeddings
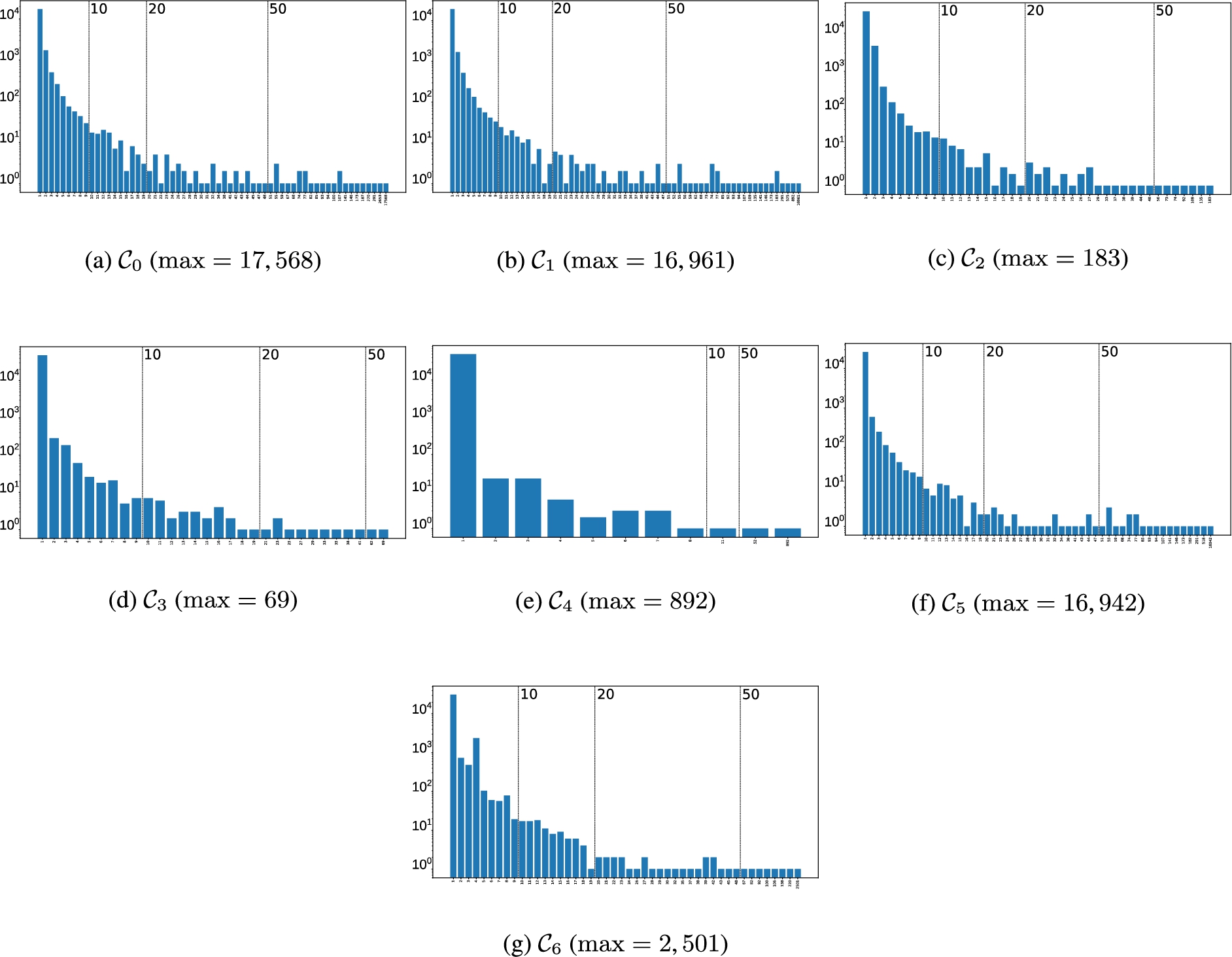
We conduct comparative experiments with three distinct clustering algorithms presented in Table 1, in regards with three classical metrics presented in Table 2. Within the large set of existing algorithms, our choice has been guided by the constraints of our task that requires to handle an important number of clusters, potentially large, and with uneven sizes (see Section 5.1 and Fig. 3 for the sizes of gold clusters computed on PGxLOD). We decided to arbitrarily limit ourselves to three algorithms, but decided to opt for algorithms that cover some diversity in the various family of algorithms. Our three algorithms differ in their parameters: in particular they require either the number of clusters to find (Ward and Single) or the minimum size of clusters (OPTICS). We used our set of gold clusters to set these parameters. Considering these distinct algorithms allows us to evaluate the influence of inference rules in different settings (see Section 4).
Table 1
Clustering algorithms applied on the embeddings of nodes in S. Nodes that belong to the same predicted cluster are considered as similar
| Algorithm | Parameter | Description |
| Ward | Number of clusters to find | Hierarchical clustering algorithm that successively merges clusters by minimizing the variance of merged clusters |
| Single | Number of clusters to find | Hierarchical clustering algorithm that successively merges clusters whose distance between their closest observations is minimal |
| OPTICS [1] | Minimum size of clusters | Algorithm that finds zones of high density and expand clusters from them |
Table 2
Performance metrics used to compare the clusters predicted by the algorithms presented in Table 1 with gold clusters
| Metric | Abbr. | Domain | Description |
| Unsupervised Clustering Accuracy | ACC | Counts nodes whose predicted cluster label is the same as their gold cluster label divided by the total number of nodes. As labels may be permuted between predicted and gold clusters, the mapping with the best ACC is used. | |
| Adjusted Rand Index | ARI | Considers all pairs of nodes and counts those whose nodes are assigned to the same or different clusters both in predicted and gold clusters. ARI is equal to 0 for a random labeling, and equal to 1 for a perfect labeling (up to a permutation). ARI is adjusted for chance. | |
| Normalized Mutual Information | NMI | Measures the mutual information between the predicted and gold clusters, normalized by the entropy of both types of clusters. NMI is equal to 1 for a perfect labeling (up to a permutation). |
4.Evaluating the influence of applying inference rules associated with domain knowledge
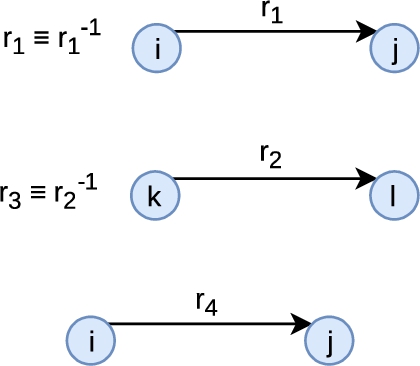
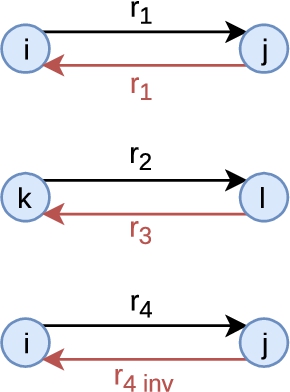
Semantic Web knowledge graphs are represented within formalims such as Description Logics [2] that are equipped with inference rules. Hence, we propose to evaluate the improvements in the results of our matching approach (detailed in Section 3) when considering such inference rules, independently or combined. Here, we only consider the inference rules associated with the following logic axioms: class and predicate assertions, equivalence axioms between entities or classes, subsumption axioms between classes or predicates, and axioms defining predicate inverses. We consider this limited set of inference rules because they are the only ones actionable in PGxLOD, the knowledge graph that motivated our study. Accordingly, we generate six different graphs (
Table 3
Visual summary of the transformations of
| Graph | Before | After |
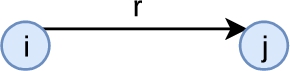 | 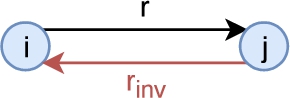 | |
 |  | |
 |  | |
 |  | |
 |  | |
| All transformations from | ||
(i) For a predicate
(ii) For a predicate
(iii) Otherwise, for a predicate
5.Experiments
We conducted experiments with PGxLOD,22 a large knowledge graph about pharmacogenomics (PGx) that we previously built and that motivated this study [22]. Our approach is implemented in Python, using PyTorch and the Deep Graph Library for learning embeddings, and scikit-learn for clustering. Our code is available on GitHub.33
5.1.Knowledge graph and gold clusters of similar nodes
PGxLOD presents several characteristics needed in the scope of our study. First, PGxLOD contains nodes whose matching is well-adapted to a structure-based approach such as ours. Additionally, alignments are expected to be found between these nodes. Indeed, PGxLOD contains 50,435 PGx relationships resulting from:
– an automatic extraction from the reference database PharmGKB;
– an automatic extraction from the biomedical literature;
– a manual representation of 10 studies made from Electronic Health Records of hospitals.
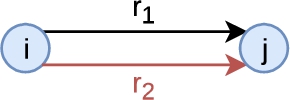
Second, PGxLOD contains owl:sameAs edges (or equivalence axioms), which makes possible the transformation represented in
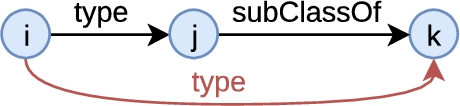
Third, PGxLOD contains subsumption axioms between classes and between predicates, which makes possible the transformations represented in
Table 4
Alignment relations considered in each gold clustering to compute the gold clusters used in our experiments. We indicate whether a relation is transitive (T or ¬ T) and symmetric (S or ¬ S)
| owl:sameAs | skos:closeMatch | skos:relatedMatch | skos:related | skos:broadMatch | |
| T, S | T, S | T, S | ¬ T, S | T, ¬ S | |
| × | × | × | × | × | |
| × | × | × | × | ||
| × | |||||
| × | |||||
| × | |||||
| × | |||||
| × |
Fourth, some PGx relationships in S are already labeled as similar through alignments resulting from the application of five matching rules previously published [21]. These alignments use the five following alignment relations: owl:sameAs, skos:closeMatch, skos:relatedMatch, skos:related, and skos:broadMatch. Alignments using owl:sameAs and skos:closeMatch indicate strong similarities, whereas skos:relatedMatch and skos:related indicate weaker similarities. Alignments using skos:broadMatch indicate that a PGx relationship is more specific than another. These alignments are removed before running inference rules over
Fig. 3.
Number of gold clusters (y-axis) by size (x-axis) for each gold clustering. The max value is the maximum size of gold clusters (in terms of number of nodes). The minimum size is 1 for every gold clustering. Only gold clusters larger than 10, 20, and 50 nodes are later used to compute performance metrics. Gold clusterings are defined in Table 4.
5.2.Learning node embeddings
We experimented our approach with different pairs
An architecture formed by 3 GCN layers is used to learn node embeddings. The input layer consists of a featureless approach as in [20,29], i.e., the input is just a one-hot vector for each node of the graph. It should be noted that this one-hot vector encoding can scale to relatively large knowledge graphs because (i) we use look-up mechanisms in weight matrices based on node indices, and thus one-hot vectors are actually never stored in memory or used in computations, and (ii) we use a basis-decomposition to limit the number of parameters. All three layers of our architecture have an output dimension of 16. Therefore, output embeddings for all nodes in the knowledge graph are in
Table 5
Statistics of PGxLOD and its transformations as described in Section 4. Statistics for PGxLOD discard literals and edges incident to literals. As we use a 3-layer architecture, statistics for all
| # nodes | # edges | # predicates | |
| PGxLOD | 11,808,396 | 43,341,712 | 416 |
| 3,758,814 | 39,956,844 | 689 | |
| 3,879,081 | 46,960,365 | 733 | |
| 3,758,814 | 22,085,701 | 347 | |
| 3,758,814 | 41,048,190 | 697 | |
| 3,758,928 | 42,691,984 | 701 | |
| 3,882,945 | 27,277,789 | 375 |
Only the embeddings of nodes in S (here, the PGx relationships) are considered in our clustering task. Hence, only these embeddings are constrained in the SNN loss. However, in
5.3.Clustering
Clustering algorithms are only applied on the embeddings of nodes in
Table 6
Summary of the results of clustering nodes for all gold clusterings and graphs
| Size of gold clusters | Gold clustering | ||
| × | |||
| × | |||
| × | |||
| × | × | ||
| × | × | ||
| × | |||
| × | |||
| × | |||
| × | |||
| × | |||
| × | |||
| × | |||
| × | |||
| × | × | ||
| × | |||
| × | |||
| × | × | ||
| × | |||
| × | |||
| × | × | ||
| × |
Results on all gold clusterings and graphs
Table 7
Summary of the results of our clustering for
| Graph | Performance |
| Baseline | |
| Improvements | |
| Light deterioration | |
| Improvements | |
| Consistent deterioration | |
| Improvements – Best results |
Results on
5.4.Distance analysis
During learning and clustering, our model is unaware of the different alignment relations holding between similar nodes. Indeed, the SNN loss only considers labels of gold clusters that do not indicate the alignment relations used to compute these clusters. This is particularly relevant for gold clusterings
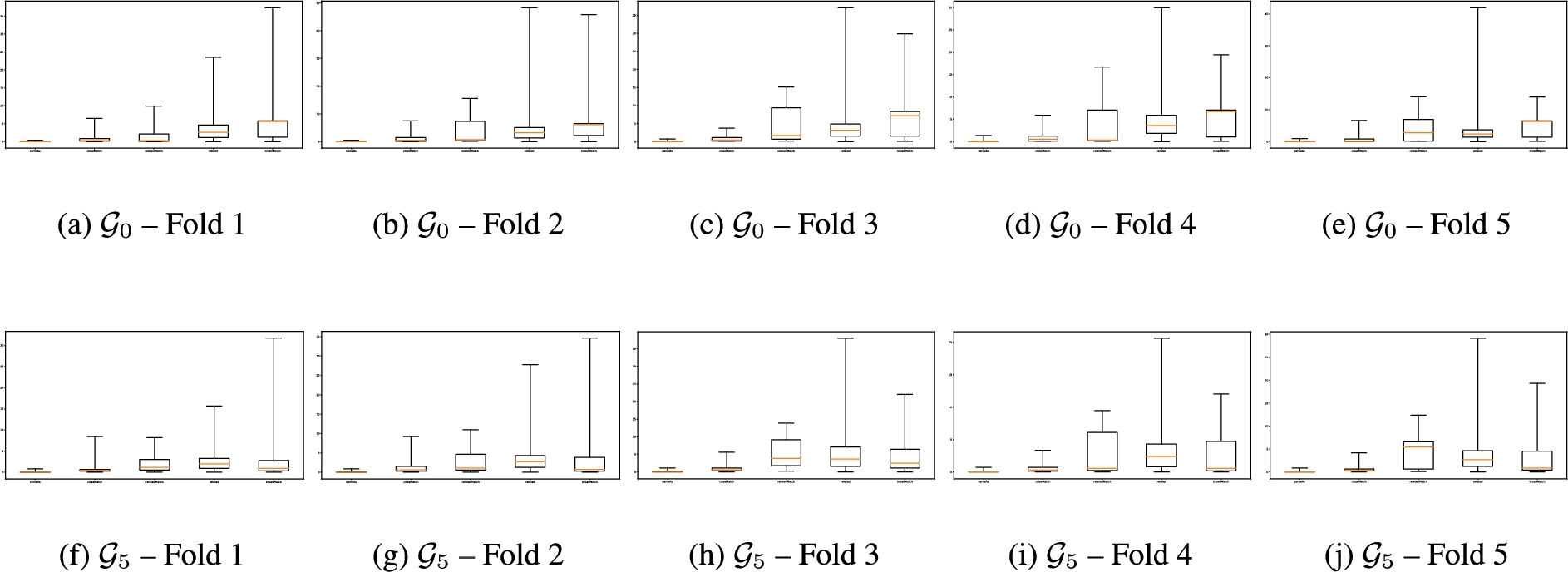
Fig. 4.
Distributions of distances between similar nodes by alignment relation for each test set, the
6.Discussion
6.1.Impact of inference rules
It appears that
In
6.2.Impact of clustering set-up
Clustering performances are generally better for gold clusterings
Among the considered clustering algorithms, Single generally performs better than the others. For
6.3.Distance analysis
Regarding the distance analysis of node embeddings, Fig. 4 shows that distances between similar nodes are different depending on the alignment relation holding between them. Recall that our GCN model is agnostic to these alignment relations when computing the SNN loss. Interestingly, distances reflect the “strength” of the alignment relations: strong similarities (i.e., owl:sameAs and skos:closeMatch links) have smaller distances than weaker ones (i.e., skos:relatedMatch and skos:related links). The skos:broadMatch relation appears more difficult to position with regard to others. This can be explained as it is the only alignment relation that is not symmetric. Such coherent distributions of distances seem to indicate the “rediscovery” of alignment relations by GCNs and encourages to consider the distance between embeddings of nodes in a “semantic” way, i.e., smaller distances indicate stronger similarities. Hence, an interesting perspective lies in predicting the exact alignment relation holding between similar nodes (i.e., in the same cluster) based on the distance between their embeddings, and evaluating this prediction. Additionally, such different distances also seem to confirm that the neighborhood aggregation of embeddings in GCNs makes them well-suited to a structural and relational matching.
6.4.Towards a further integration of domain knowledge in GCNs
Our results highlight the interest of considering domain knowledge associated with knowledge graphs in embedding approaches and seem to advocate for a further integration of domain knowledge within embedding models. Future works may investigate the same targets with additional inferences rules (e.g., from OWL 2 RL semantics) or different embedding techniques, whether based on graph neural networks [11] or others (e.g., translational approaches such as TransE). Additionally, we did not use attention mechanisms, which could also consider domain knowledge as in Logic Attention Network [31]. Here, inference rules associated with domain knowledge are used to transform the knowledge graph as a pre-processing operation. However, we could envision to consider such mechanisms directly in the model (e.g., weight sharing between predicates and their super-predicates). Literals could also be taken into account [33]. In a larger perspective, one major future work lies in investigating if and how other semantics than types of alignments can emerge in the output embedding space.
6.5.Generalization to other knowledge graphs
Despite our approach being motivated by the matching of individuals within an aggregated knowledge graph, its transposition to distinct graphs could be explored. Such a perspective could allow to assess the generalization of our approach and its results. In particular, we could consider knowledge graphs that are not completely independent such as LOD datasets that are connected through major LOD hubs. Recall that our approach is supervised since gold clusters are computed from preexisting alignments. Hence, testing our approach on different knowledge graphs of the LOD would require such preexisting alignments or using ontology alignment systems in a distant supervision process [8]. In this setting, merging the different graphs into one and learning a “global” embedding, as we did, may provide positive results but may pose additional scalability issues.
7.Conclusion
In this paper, we proposed to match entities of a knowledge graph by learning node embeddings with Graph Convolutional Networks (GCNs) and clustering nodes based on their embeddings. We particularly investigated the interplay between formal semantics associated with knowledge graphs and GCN models. Our results showed that considering inference rules associated with domain knowledge tends to improve performance. Additionally, even if our GCN model was agnostic to the exact alignment relations holding between entities (e.g., equivalence, weak similarity), distances in the embedding space are coherent with the “strength” of the alignment relations. These results seem to advocate for a further integration of formal semantics within embedding models.
Notes
1 GCNs and the Soft Nearest Neighbor loss are further detailed in Section 3.2.
4
5 The 3-hop neighborhood of a node n consists of all the nodes that can be reached with a breadth-first traversal that starts at n and traverses at most 3 edges.
Acknowledgements
This work was supported by the PractiKPharma project, founded by the French National Research Agency (ANR) under Grant ANR15-CE23-0028, and by the Snowball Inria Associate Team.
Appendices
Appendix
AppendixDetailed results of clustering experiments
Detailed results of clustering experiments are available Table 8, Table 9 and Table 10.
Table 8
Results of clustering nodes that belong to gold clusters whose size is greater or equal to 50 for graphs
| ACC | ARI | NMI | ACC | ARI | NMI | ||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
Table 9
Results of clustering nodes that belong to gold clusters whose size is greater or equal to 20 for graphs
| ACC | ARI | NMI | ACC | ARI | NMI | ||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
Table 10
Results of clustering nodes that belong to gold clusters whose size is greater or equal to 10 for graphs
| ACC | ARI | NMI | ACC | ARI | NMI | ||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
| Ward | |||||||
| Single | |||||||
| OPTICS | |||||||
Table 11
Results of clustering nodes that belong to gold clusters whose size is greater or equal to 50 for
| Ward | Single | OPTICS | |||||
| ACC | |||||||
| ARI | |||||||
| NMI | |||||||
| ACC | ↓ | ||||||
| ARI | ↓ | ||||||
| NMI | ↓ | ↓ | ↓ | ||||
| ACC | |||||||
| ARI | |||||||
| NMI | ↓ | ||||||
| ACC | ↓ | ||||||
| ARI | |||||||
| NMI | ↓ | ||||||
| ACC | ↓ | ↓ | |||||
| ARI | ↓ | ↓ | |||||
| NMI | ↓ | ↓ | ↓ | ||||
| ACC | |||||||
| ARI | |||||||
| NMI | ↓ |
Table 12
Results of clustering nodes that belong to gold clusters whose size is greater or equal to 20 for
| Ward | Single | OPTICS | |||||
| ACC | |||||||
| ARI | |||||||
| NMI | |||||||
| ACC | ↓ | ||||||
| ARI | ↓ | ||||||
| NMI | ↓ | ↓ | |||||
| ACC | |||||||
| ARI | ↓ | ||||||
| NMI | ↓ | ||||||
| ACC | ↓ | ||||||
| ARI | ↓ | ||||||
| NMI | |||||||
| ACC | ↓ | ↓ | |||||
| ARI | ↓ | ↓ | ↓ | ||||
| NMI | ↓ | ||||||
| ACC | |||||||
| ARI | |||||||
| NMI | ↓ |
Table 13
Results of clustering nodes that belong to gold clusters whose size is greater or equal to 10 for
| Ward | Single | OPTICS | |||||
| ACC | |||||||
| ARI | |||||||
| NMI | |||||||
| ACC | |||||||
| ARI | |||||||
| NMI | ↓ | ||||||
| ACC | ↓ | ↓ | |||||
| ARI | ↓ | ||||||
| NMI | ↓ | ↓ | ↓ | ||||
| ACC | ↓ | ||||||
| ARI | |||||||
| NMI | ↓ | ||||||
| ACC | ↓ | ||||||
| ARI | ↓ | ||||||
| NMI | ↓ | ||||||
| ACC | ↓ | ||||||
| ARI | |||||||
| NMI | ↓ | ↓ |
References
[1] | M. Ankerst, M.M. Breunig, H. Kriegel and J. Sander, OPTICS: Ordering points to identify the clustering structure, in: SIGMOD 1999, Proceedings ACM SIGMOD International Conference on Management of Data, Philadelphia, Pennsylvania, USA, June 1–3, 1999, ACM Press, (1999) , pp. 49–60. doi:10.1145/304182.304187. |
[2] | F. Baader et al. (eds), The Description Logic Handbook: Theory, Implementation, and Applications, Cambridge University Press, (2003) . |
[3] | T. Berners-Lee, J. Hendler, O. Lassila et al., The semantic web, Scientific American 284: (5) ((2001) ), 28–37. |
[4] | A. Bordes, N. Usunier, A. García-Durán, J. Weston and O. Yakhnenko, Translating embeddings for modeling multi-relational data, in: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Proceedings of a meeting held December 5–8, 2013, Lake Tahoe, Nevada, United States, (2013) , pp. 2787–2795. |
[5] | H. Cai, V.W. Zheng and K.C. Chang, A comprehensive survey of graph embedding: Problems, techniques, and applications, IEEE Trans. Knowl. Data Eng. 30: (9) ((2018) ), 1616–1637. doi:10.1109/TKDE.2018.2807452. |
[6] | K.E. Caudle et al., Incorporation of pharmacogenomics into routine clinical practice: The Clinical Pharmacogenetics Implementation Consortium (CPIC) guideline development process, Current Drug Metabolism 15: (2) ((2014) ), 209–217. doi:10.2174/1389200215666140130124910. |
[7] | J. Chen, P. Hu, E. Jiménez-Ruiz, O.M. Holter, D. Antonyrajah and I. Horrocks, OWL2Vec*: Embedding of OWL ontologies, Machine Learning 110: (7) ((2021) ), 1813–1845. doi:10.1007/s10994-021-05997-6. |
[8] | J. Chen, E. Jiménez-Ruiz, I. Horrocks, D. Antonyrajah, A. Hadian and J. Lee, Augmenting ontology alignment by semantic embedding and distant supervision, in: The Semantic Web – 18th International Conference, ESWC 2021, Virtual Event, June 6–10, 2021, Proceedings, R. Verborgh, K. Hose, H. Paulheim, P. Champin, M. Maleshkova, Ó. Corcho, P. Ristoski and M. Alam, eds, Lecture Notes in Computer Science, Vol. 12731: , Springer, (2021) , pp. 392–408. doi:10.1007/978-3-030-77385-4_23. |
[9] | A. Coulet and M. Smaïl-Tabbone, Mining electronic health records to validate knowledge in pharmacogenomics, ERCIM News 2016: (104) ((2016) ). |
[10] | C. d’Amato, N.F. Quatraro and N. Fanizzi, Injecting background knowledge into embedding models for predictive tasks on knowledge graphs, in: The Semantic Web – 18th International Conference, ESWC 2021, Virtual Event, June 6–10, 2021, Proceedings, R. Verborgh, K. Hose, H. Paulheim, P. Champin, M. Maleshkova, Ó. Corcho, P. Ristoski and M. Alam, eds, Lecture Notes in Computer Science, Vol. 12731: , Springer, (2021) , pp. 441–457. doi:10.1007/978-3-030-77385-4_26. |
[11] | V.P. Dwivedi, C.K. Joshi, T. Laurent, Y. Bengio and X. Bresson, Benchmarking graph neural networks, CoRR abs/2003.00982 (2020). |
[12] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, (2013) . ISBN 978-3-642-38720-3. |
[13] | N. Frosst, N. Papernot and G.E. Hinton, Analyzing and improving representations with the soft nearest neighbor loss, in: Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, California, USA, 9–15 June 2019, Proceedings of Machine Learning Research, Vol. 97: , PMLR, (2019) , pp. 2012–2020. |
[14] | T.R. Gruber, A translation approach to portable ontology specifications, Knowledge Acquisition 5: (2) ((1993) ), 199–220. doi:10.1006/knac.1993.1008. |
[15] | R.V. Guha, Towards a model theory for distributed representations, in: 2015 AAAI Spring Symposia, Stanford University, Palo Alto, California, USA, March 22–25, 2015, AAAI Press, (2015) , http://www.aaai.org/ocs/index.php/SSS/SSS15/paper/view/10220. |
[16] | V. Gutiérrez-Basulto and S. Schockaert, From knowledge graph embedding to ontology embedding? An analysis of the compatibility between vector space representations and rules, in: Principles of Knowledge Representation and Reasoning: Proceedings of the Sixteenth International Conference, KR 2018, Tempe, Arizona, 30 October–2 November 2018, AAAI Press, (2018) , pp. 379–388. |
[17] | A. Hogan, E. Blomqvist, M. Cochez, C. d’Amato, G. de Melo, C. Gutiérrez, J.E.L. Gayo, S. Kirrane, S. Neumaier, A. Polleres, R. Navigli, A.N. Ngomo, S.M. Rashid, A. Rula, L. Schmelzeisen, J.F. Sequeda, S. Staab and A. Zimmermann, Knowledge graphs, CoRR abs/2003.02320 (2020). https://arxiv.org/abs/2003.02320 abs/2003.02320. |
[18] | A. Iana and H. Paulheim, More is not always better: The negative impact of A-box materialization on RDF2vec knowledge graph embeddings, in: Proceedings of the CIKM 2020 Workshops Co-Located with 29th ACM International Conference on Information and Knowledge Management (CIKM 2020), Galway, Ireland, October 19–23, 2020, S. Conrad and I. Tiddi, eds, CEUR Workshop Proceedings, Vol. 2699: , CEUR-WS.org, (2020) , http://ceur-ws.org/Vol-2699/paper05.pdf. |
[19] | D.P. Kingma and J. Ba, Adam: A method for stochastic optimization, in: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings, (2015) . |
[20] | T.N. Kipf and M. Welling, Semi-supervised classification with graph convolutional networks, in: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24–26, 2017, Conference Track Proceedings, OpenReview.net, (2017) . |
[21] | P. Monnin, M. Couceiro, A. Napoli and A. Coulet, Knowledge-based matching of n-ary tuples, in: Ontologies and Concepts in Mind and Machine – 25th International Conference on Conceptual Structures, ICCS 2020, Bolzano, Italy, September 18–20, 2020, Proceedings, M. Alam, T. Braun and B. Yun, eds, Lecture Notes in Computer Science, Vol. 12277: , Springer, (2020) , pp. 48–56. doi:10.1007/978-3-030-57855-8_4. |
[22] | P. Monnin, J. Legrand, G. Husson, P. Ringot, A. Tchechmedjiev, C. Jonquet, A. Napoli and A. Coulet, PGxO and PGxLOD: A reconciliation of pharmacogenomic knowledge of various provenances, enabling further comparison, BMC Bioinformatics 20-S: (4) ((2019) ), 139:1–139:16. doi:10.1186/s12859-019-2693-9. |
[23] | P. Monnin, C. Raïssi, A. Napoli and A. Coulet, Knowledge reconciliation with graph convolutional networks: Preliminary results, in: Proceedings of the Workshop on Deep Learning for Knowledge Graphs (DL4KG2019) Co-Located with the 16th Extended Semantic Web Conference 2019 (ESWC 2019), Portoroz, Slovenia, June 2, 2019, CEUR Workshop Proceedings, Vol. 2377: , CEUR-WS.org, (2019) , pp. 47–56. |
[24] | M. Nickel, K. Murphy, V. Tresp and E. Gabrilovich, A review of relational machine learning for knowledge graphs, Proceedings of the IEEE 104: (1) ((2016) ), 11–33. doi:10.1109/JPROC.2015.2483592. |
[25] | N. Noy, A. Rector, P. Hayes and C. Welty, Defining N-ary relations on the semantic web, W3C Working Group Note 12: (4) ((2006) ). |
[26] | N. Pang, W. Zeng, J. Tang, Z. Tan and X. Zhao, Iterative entity alignment with improved neural attribute embedding, in: Proceedings of the Workshop on Deep Learning for Knowledge Graphs (DL4KG2019) Co-Located with the 16th Extended Semantic Web Conference 2019 (ESWC 2019), Portoroz, Slovenia, June 2, 2019, CEUR Workshop Proceedings, Vol. 2377: , CEUR-WS.org, (2019) , pp. 41–46. |
[27] | H. Paulheim, Make embeddings semantic again! in: Proceedings of the ISWC 2018 Posters & Demonstrations, Industry and Blue Sky Ideas Tracks Co-Located with 17th International Semantic Web Conference (ISWC 2018), Monterey, USA, October 8th – to – 12th, 2018, CEUR Workshop Proceedings, Vol. 2180: , CEUR-WS.org, (2018) . |
[28] | P. Ristoski and H. Paulheim, RDF2Vec: RDF graph embeddings for data mining, in: The Semantic Web – ISWC 2016 – 15th International Semantic Web Conference, Kobe, Japan, October 17–21, 2016, Proceedings, Part I, Lecture Notes in Computer Science, Vol. 9981: , (2016) , pp. 498–514. doi:10.1007/978-3-319-46523-4_30. |
[29] | M.S. Schlichtkrull, T.N. Kipf, P. Bloem, R. van den Berg, I. Titov and M. Welling, Modeling relational data with graph convolutional networks, in: The Semantic Web – 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings, Lecture Notes in Computer Science, Vol. 10843: , Springer, (2018) , pp. 593–607. doi:10.1007/978-3-319-93417-4_38. |
[30] | L. Serafini and A.S. d’Avila Garcez, Logic tensor networks: Deep learning and logical reasoning from data and knowledge, in: Proceedings of the 11th International Workshop on Neural-Symbolic Learning and Reasoning (NeSy ’16) Co-Located with the Joint Multi-Conference on Human-Level Artificial Intelligence (HLAI 2016), New York City, NY, USA, July 16–17, 2016, CEUR Workshop Proceedings, Vol. 1768: , CEUR-WS.org, (2016) . |
[31] | P. Wang, J. Han, C. Li and R. Pan, Logic attention based neighborhood aggregation for inductive knowledge graph embedding, in: The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, the Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, the Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27–February 1, 2019, AAAI Press, (2019) , pp. 7152–7159. doi:10.1609/aaai.v33i01.33017152. |
[32] | Q. Wang, Z. Mao, B. Wang and L. Guo, Knowledge graph embedding: A survey of approaches and applications, IEEE Trans. Knowl. Data Eng. 29: (12) ((2017) ), 2724–2743. doi:10.1109/TKDE.2017.2754499. |
[33] | Z. Wang, Q. Lv, X. Lan and Y. Zhang, Cross-lingual knowledge graph alignment via graph convolutional networks, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31–November 4, 2018, Association for Computational Linguistics, (2018) , pp. 349–357. doi:10.18653/v1/d18-1032. |
[34] | M. Whirl-Carrillo, E.M. McDonagh, J.M. Hebert, L. Gong, K. Sangkuhl, C.F. Thorn, R.B. Altman and T.E. Klein, Pharmacogenomics knowledge for personalized medicine, Clinical Pharmacology and Therapeutics 92: (4) ((2012) ), 414. doi:10.1038/clpt.2012.96. |


