
Location Selection of Express Distribution Centre with Probabilistic Linguistic MABAC Method Based on the Cumulative Prospect Theory
Abstract
In our daily life, we could be confronted with numerous multiple attribute group decision making (MAGDM) problems. For such problems we designed a model which employs probabilistic linguistic MABAC (multi-attributive border approximation area comparison) based on the cumulative prospect theory (CPT-PL-MABAC) method to solve the MAGDM. The CPT-PL-MABAC method can take experts’ psychological behaviour and preferences into consideration. Furthermore, we utilize the combined weight consisting of subjective weight and objective weight. The objective weight is acquired by the entropy method. Additionally, the concrete calculating steps of CPT-PL-MABAC method are proposed to solve the MAGDM for selecting the optimal location of express distribution centre. Also, a numerical example for location selection of express distribution centre is given as the justification of the usefulness of the designed method. Finally, we compare the designed model with the other three existing models, and summarize the advantages and shortcomings.
1Introduction
Multiple attribute decision making (MADM) or multiple attribute group decision making (MAGDM) is an effective approach to solve complex decision-making issues (Huang et al., 2021; Lei et al., 2021; Liu et al., 2018; Zhang D. et al., 2021; Zhang et al., 2018). In the decision-making process, decision makers are usually experts in their fields. Therefore, decision makers (DMs) would like to use linguistic terms rather than utilize the exact real numbers due to the complication of the socioeconomic setting and fuzziness of human beings’ thinking (Lei et al., 2021; Wei et al., 2021a). It means that the linguistic terms given by experts contain uncertainty and preference. To solve the uncertainty of decision-making problems, a lot of effective work has been done. Wang and Garg (2021) proposed new interaction Pythagorean operators and designed an algorithm to solve the MADM issues with Pythagorean fuzzy uncertainties. Yazdi et al. (2020) proposed an integrated method which combined BWM with Weighted Aggregated Sum-Product Assessment (WASPAS) on uncertain decision-making environments with Z-numbers. Xiao et al. (2021) built Taxonomy method for MAGDM based on interval-valued intuitionistic fuzzy information. Zhang H. et al. (2021) defined the CPT-MABAC method for spherical fuzzy MAGDM. Zhang S. et al. (2021) defined the grey relational analysis method based on cumulative prospect theory for intuitionistic fuzzy MAGDM.
The decision makers are more likely to choose ‘good’, ‘medium’, ‘a little good’ and ‘excellent’ to evaluate alternatives. Therefore, Rodriguez et al. (2012) defined hesitant fuzzy linguistic term set (HFLTS) to use the hesitancy degree in the linguistic context. Zeng et al. (2019) introduced several weighted operators to aggregate weighted hesitant fuzzy linguistic information. Liu et al. (2019) improved incomplete hesitant fuzzy linguistic preference relations (IHFLPRs). These concepts can describe ambiguity and preference in linguistic term sets, but ignored differences in the importance of evaluation information. Thus, Pang et al. (2016) used probabilistic linguistic term sets (PLTSs) to depict fuzziness and uncertainty with certain probabilities. They proposed some rules of operation and aggregation operators for PLTSs. We can find that PLTSs can more comprehensively and precisely represent the attitude of decision makers. Furthermore, many improvements have been made in decision-making issues on PLTSs. Yue et al. (2020b) put forward the group utility measure, the individual regret measure and the compromise measure under PLTSs. Some studies discussed decision making methods under PLTSs. Wei et al. (2021b) built the DAS method for probabilistic linguistic MAGDM. Chen et al. (2020) combined distillation algorithm with ELECTRE III method on PLTSs. He et al. (2021) modified the FMEA (the failure mode and effect analysis) model on the PLTSs. You et al. (2020) designed PL-VIKOR method and modified the distance measure. Some studies have introduced and defined some new distance formulas. Chang et al. (2021) introduced Hellinger distance measure. Jiang and Liao (2021) defined Kolmogorov-Smirnov distance measure on the PLTSs. Some studies have proposed effective tools to solve decision-making issues under PLTSs. Du and Liu (2021) researched quality function deployment tool under PLTSs. Lin et al. (2021) proposed score C-PLTSs and probability splitting algorithm. And a novel PLTS correlation coefficient was put forward by Luo et al. (2020). Peng and Wang (2020) introduced linguistic scale functions. Shen et al. (2021) came up with a model to reduce limitations of evaluation on the PLTSs. Teng et al. (2021) designed the Choquet integral operator under PLTSs. Wang and Liang (2020) put away a preference degree for g-granularity PLTS. Wang et al. (2021) extended the operational laws of PLTSs. Wang et al. (2020) proposed probabilistic linguistic Z-numbers to describe related information. Xie et al. (2020) defined the dual probabilistic linguistic correlation coefficient. Xu et al. (2020) proposed a method to make probabilistic linguistic more complete in describing evaluation information. Yu et al. (2020) combined stochastic dominance degrees with PLTSs. Yue et al. (2020a) introduced the projection formulas and Qu et al. (2020) introduced new utility functions on the PLTSs. Su et al. (2021a) built PT-TODIM method for probabilistic linguistic MAGDM.
Applying PLTSs and related methods to some practical cases can reflect advantages and the applicability of PLTSs. Liang et al. (2020) improved customer satisfaction evaluation system on PLTSs. Mo (2020) proposed the D-PLTS method to settle emergency decision-making issues. Pan et al. (2021) designed a probabilistic linguistic data envelopment analysis model. Xu C. et al. (2020) applied probabilistic linguistic preference relations to handle the healthcare insurance audits in China. Gao et al. (2021) proposed the PLTSs to describe information and built the MCGDM framework for the risk assessment. Luo et al. (2021) designed the IDOCRIW-COCOSO model to evaluate tourism attractions on the PLTSs. Ming et al. (2020) structured a medical service evaluation criteria system under PLTSs.
The MABAC method is an effective method to address some difficult decision making issues. Xu et al. (2019) used the MABAC algorithm to select the optimal green supplier. To select the optimal university, Gong et al. (2020) designed a new UTAE (undergraduate teaching audit and evaluation) approach combined with the MABAC method. Biswas (2020) selected the MABAC method to prepare a comparative analysis of supply chain performances. In order to make better use of the MABAC method, experts put it in different linguistic environments. Verma (2021) applied IFS (intuitionistic fuzzy set) with the MABAC algorithm. Liang et al. (2019) came up with the MABAC approach based on TFN to evaluate the risk of rock-burst. Hu et al. (2019) combined the MABAC method with the similarity of interval type-2 fuzzy numbers (IT2FNs). Sun et al. (2018) extended the MABAC method to HFLTSs (hesitant fuzzy linguistic term sets) for patients’ prioritization. Aydin (2021) applied the MABAC method with Fermantean fuzzy sets into decision-making process. Liu and Zhang (2021) integrated the MABAC model with prospect theory (PT) on a normal wiggly hesitant fuzzy set (NWHFS). Additionally, many studies combined MABAC with another algorithm to solve MADM or MAGDM problems. Pamucar et al. (2018) defined the IR-AHP-MABAC (interval rough analytic hierarchy process-MABAC) model to assess the quality of websites. Jiang et al. (2022) built the picture fuzzy MABAC method based on prospect theory for MAGDM.
The above investigations described a particular assumption that DMs are perfectly rational. However, many studies show that people’s behaviour is affected by their emotions. For example, people are inclined to be more sensitive to losses than to gains. That’s to say, the perception of equal gains and losses are not the same for DMs. In general, people are inclined to be risk-averse. Based on these assumptions of bounded rationality, the cumulative prospect theory (CPT) (Tversky and Kahneman, 1992) broke through the classical utility theory and defined the weight function and value function. Gong et al. (2018) built a new model based on CPT to tackle portfolio selection. Zhao et al. (2021b) combined CPT with TODIM method under several linguistic environments, such as pythagorean fuzzy sets (2021), the 2-tuple linguistic pythagorean fuzzy sets (Zhao et al., 2021c). Additionally, Zhao et al. (2021a) introduced the intuitionistic fuzzy MABAC method based on CPT. Furthermore, picture fuzzy sets (Jiang et al., 2021a, 2021b) were dealt with CPT. Su et al. (2021b) built the probabilistic uncertain linguistic EDAS method based on prospect theory for MAGDM.
In the originalMABAC method, the psychological factor such as the DMs’ preference towards risk will affect the distance between the border approximation area. Furthermore, there are relatively few researches on constructing the MABAC method for MAGDM depending on the CPT under PLTSs. The main research significance of this paper is the modified MABAC method with CPT which can reduce the affection. Therefore, the PL-MABAC based on cumulative prospect theory (CPT-PL-MABAC) method in this paper is defined to solve the location selection of express distribution centre, which is a classical MAGDM issue. This article makes contributions as follows: (1) the concept of CPT is integrated into the PL-MABAC method for MAGDM. This method not only has unambiguous logic and relatively simple calculation, but also expresses the DM’s psychological state, which is closer to reality; (2) we improved the entropy method, which is characterized by the mean value of attributes as the reference point; (3) the combined attribute weights are obtained through objective weight by the entropy method and by getting the subjective weight given by decision makers; (4) the effectiveness and stability of this new method is fully testified by taking advantage of a case about location selection of express distribution centre and comparisons with the existing methods.
To sum up, the structure of this paper is built as follows. The second part mainly introduces and reviews the basic knowledge, including the PLTSs and CPT. In Section 3, the PL-MABAC based on cumulative prospect theory (CPT-PL-MABAC) method is defined to solve the MAGDM. In Section 4, a case for location selection of express distribution centre is given as the justification of the usefulness of the designed method. Also, we compared our method with existing methods and demonstrated the stability and availability of this method. Finally, the main contributions of this paper, the limitations of the new method and future research directions are included.
2Preliminaries
In order to illustrate the CPT-PL-MABAC model, some relevant knowledge is introduced.
2.1PLTSs
Sometimes, decision makers give fuzzy evaluation information that cannot be expressed exactly. Pang et al. (2016) came up with PLTS, which have different weights and probabilities.
Definition 1
Definition 1(Gou et al., 2017).
Let
(1)
(2)
Definition 2
Definition 2(Pang et al., 2016).
Suppose
(3)
To make the PLTSs easier to deal with, Pang et al. (2016) normalized the PLTS
Definition 3
Definition 3(Pang et al., 2016).
Suppose
Definition 4
Definition 4(Pang et al., 2016).
Suppose
(4)
(5)
We can obtain the order relation between two PLTSs by Eqs. (4) and (5).
(1) If
(2) If
Definition 5
Definition 5(Lin et al., 2019).
Suppose
(6)
2.2Cumulative Prospect Theory
In the cumulative prospect theory (CPT) (Tversky and Kahneman, 1992), DMs will go through two stages when they are faced with choices and make decisions: editing stage and evaluation stage. In the editing stage, the decision-makers will collect information and do some preprocessing to find out the reference point; in the evaluation stage, the decision makers will evaluate the prospect which has been pretreated and choose the best prospect based on a value function
(7)
(8)
In this formula,
3CPT-PL-MABAC Model for MAGDM Issues
We will introduce the MABAC method based on CPT and on the PLTS. We will also give the following mathematical symbols which are used to express the relevant information. We suppose that there is a collection of alternatives
We designed the new PL-MABAC method in which the CPT is introduced to address MAGDM problems. A laconic frame diagram and the specific calculating procedure as follows:
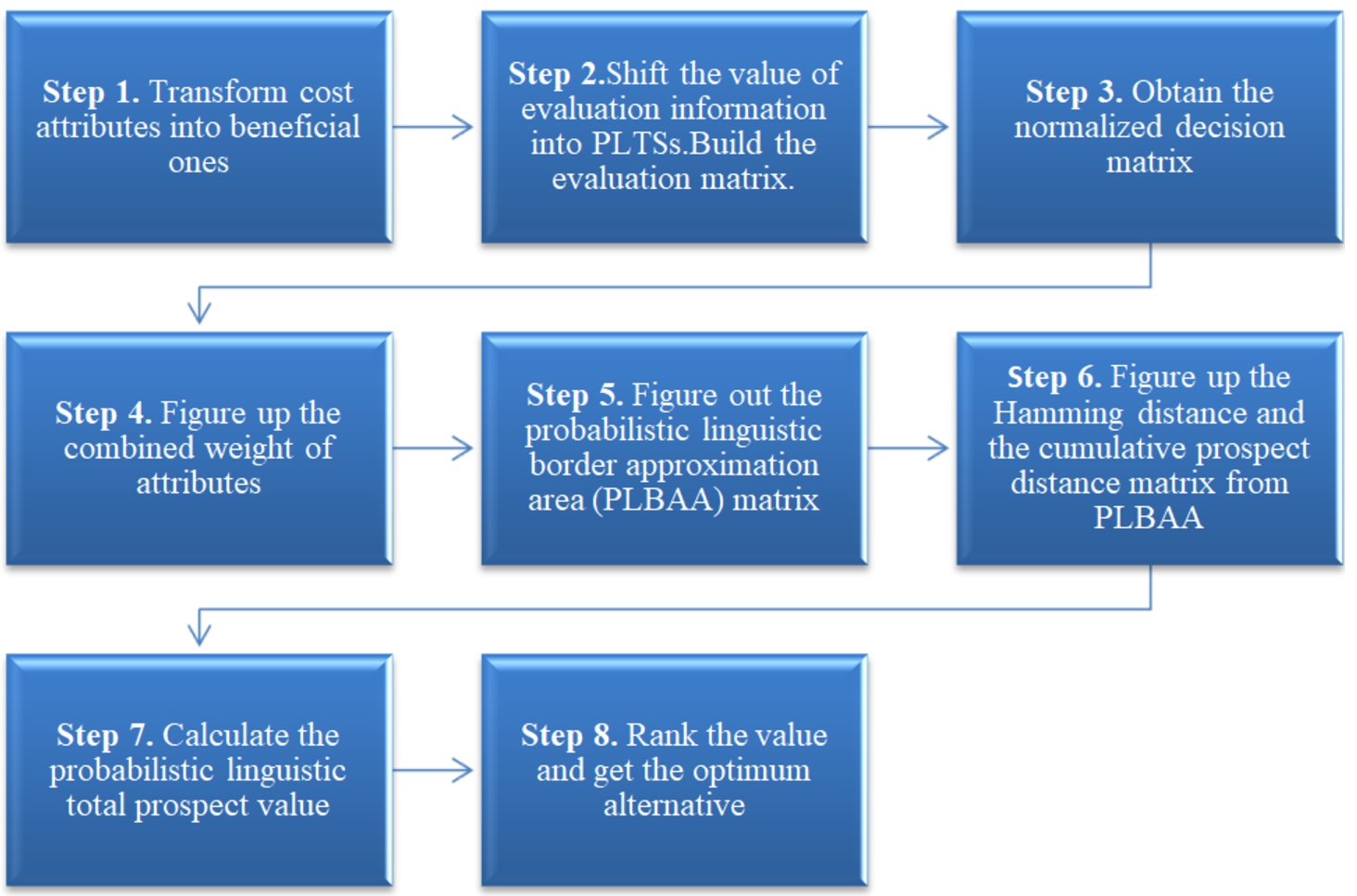
3.2The CPT-PL-MABAC Calculating Procedure
Step 1. Transform cost attributes into beneficial ones.
Given an LTS
Step 2. Shift the value of evaluation information
Step 3. Obtain the normalized decision matrix
Step 4. Figure up the combined weight of attributes.
We acquire the objective weight by the entropy method and get the subjective weight given by decision makers.
First, we introduce the specific procedure of the entropy method. It should be noted that when calculating entropy, we use the mean value of the attribute as the reference point to calculate its distance from the normalized attribute value.
1. Calculate the mean value of jth attribute, the formula is expressed below:
(9)
(10)
2. Let
(11)
3. Compute the objective weights of the jth attribute by using Eq. (12):
where(12)
Then, we calculate the combined weights by using the following equation. The advantage of using combined weight is that the influence of subjective weight and objective weight can be considered comprehensively.
Decision makers gave the subjective weights
(13)
Step 5. Figure out the probabilistic linguistic border approximation area (PLBAA) matrix
(14)
(15)
(16)
Step 6. Figure up the Hamming distance from PLBAA by Eq. (17) and the cumulative prospect distance matrix by using Eq. (18).
(17)
(18)
We take
Step 7. Calculate the probabilistic linguistic total prospect value.
(19)
Step 8. Rank the value of
4An Example Analysis and Comparative Analysis
4.1An Example Analysis
In the background of e-commerce, online shopping has become a very common way of consumption in people’s lives. The recent epidemic situation also makes people more accustomed to using online shopping for consumption. Therefore, express delivery has become a matter of great concern. Reasonable and effective site selection can improve the service quality and win the favour of customers, so as to achieve the all-win goal of Express Distribution Centre, businesses and consumers. The express industry is the product of rapid economic development. It means that the consumption capacity of a region has a crucial impact on the express business volume. How to choose a proper express distribution centre is of great importance to both express companies and consumers. Generally speaking, the more developed the region is, the more its express business volume will be, and the number of distribution centres will be more and more centralized. Additionally, the site selection also needs to consider the local population and demand. For example, the closer to the central business district, the denser the population, the more demand for express delivery. Besides, for the areas where e-commerce self-employed households are concentrated, the demand for express delivery is very large, which should be considered as the key object. Moreover, to choose a reasonable address for the express delivery centre, we must consider the problem of cost minimization. And convenient transportation can effectively ensure the timeliness of express delivery. Otherwise, in order to ensure service quality, express enterprises can only add more outlets or send more vehicles, no matter which way it will lead to increased costs. We know that choosing the best address of Express Distribution Centre is a classic MADM or MAGDM problem. In this case, we gave five alternative sites
Table 1
Linguistic decision matrix by the first DM.
| Alternatives | ||||
| SA | SI | A | M | |
| I | DI | SI | I | |
| M | I | A | DI | |
| I | DI | I | I | |
| M | I | M | M |
Table 2
Linguistic decision matrix by the second DM.
| Alternatives | ||||
| SI | I | DA | DA | |
| A | I | DI | M | |
| SA | M | SA | A | |
| DI | M | DI | M | |
| A | A | SI | I |
Table 3
Linguistic decison matrix by the third DM.
| Alternatives | ||||
| A | SI | SA | SA | |
| I | I | SI | I | |
| M | SI | A | DI | |
| SI | DA | SA | I | |
| M | DA | M | A |
Table 4
Linguistic decision matrix by the fourth DM.
| Alternatives | ||||
| SA | I | DA | DA | |
| A | DI | A | M | |
| M | I | A | A | |
| SI | DA | DI | A | |
| M | DA | SI | I |
Table 5
Linguistic decision matrix by the fifth DM.
| Alternatives | ||||
| SA | M | DA | DA | |
| SA | SI | A | SI | |
| I | I | A | SI | |
| DI | SA | DI | A | |
| A | DA | A | I |
For the convenience of calculation, we first express the evaluation information given by experts by using linguistic term sets (Tables 6–10).
Table 6
Decision matrix with linguistic term sets by the first DM.
| Alternatives | ||||
Table 7
Decision matrix with linguistic term sets by the second DM.
| Alternatives | ||||
Table 8
Decision matrix with linguistic term sets by the third DM.
| Alternatives | ||||
Table 9
Decision matrix with linguistic term sets by the fourth DM.
| Alternatives | ||||
Table 10
Decision matrix with linguistic term sets by the fifth DM.
| Alternatives | ||||
Then, we choose the most appropriate site fot the logistics distribution centre by using CPT-PL-MABAC method.
Step 1. Transform the cost attribute
Table 11
Linguistic evaluating value matrix by the first DM.
| Alternatives | ||||
Table 12
Linguistic evaluating value matrix by the second DM.
| Alternatives | ||||
Table 13
Linguistic evaluating value matrix by the third DM.
| Alternatives | ||||
Table 14
Linguistic evaluating value matrix by the fourth DM.
| Alternatives | ||||
Step 2. Shift the evaluation information with LTSs into a decision matrix
Table 15
Linguistic evaluating value matrix by the fifth DM.
| Alternatives | ||||
Step 3. Normalize the decision matrix with PLTSs. Transform the decision matrix
Table 16
Decision matrix with PLTSs.
| Alternatives | ||
| Alternatives | ||
Step 4. Figure out the combined weight.
Table 17
Normalized decision matrix with PLTSs.
| Alternatives | ||
| Alternatives | ||
Firstly, the objective weights are calculated by the entrophy method and the detailed calculation steps are as follows:
(1) The mean value of jth attribute is calculated by Eqs. (9)–(10) (see Table 18).
(2) The
(3) The objective weight of the jth attribute is computed by Eq. (12), and the results are as follows:
Table 18
The mean value for all attributes.
| The mean value | |
Table 19
Probabilistic linguistic total prospect value of the all alternatives.
| Alternatives | ||||
| 0.8689 | 0.9653 | 0.9453 | 0.9657 |
Secondly, the subjective weights are given by experts, which are:
Finally, the combined weight can be calculated by Eq. (13), and the results are as follows:
Step 5. According to Eqs. (14)–(16), the
Step 6. The Hamming distance can be calculated by using Eq. (17) and the cumulative prospect Hamming distance can be calculated by using Eq. (18) (see Tables 21–22).
Table 20
PLBAA for all attributes.
| PLBAA | |
Table 21
The Hamming distance matrix.
| Alternatives | ||||
| 0.0726 | 0.1130 | 0.2779 | 0.1774 | |
| 0.0615 | 0.1575 | −0.0417 | 0.0338 | |
| 0.0504 | 0.1221 | 0.1472 | −0.0328 | |
| −0.0830 | −0.0759 | −0.0480 | 0.1005 | |
| 0.0615 | −0.0332 | 0.0695 | 0.1005 |
Step 7. Figure up the probabilistic linguistic total prospect value, which is computed by using Eq. (19) (see Table 23).
Table 22
The cumulative prospect distance matrix.
| Alternatives | ||||
| 0.0236 | 0.0419 | 0.0724 | 0.0307 | |
| 0.0204 | 0.0561 | −0.0462 | 0.0072 | |
| 0.0171 | 0.0448 | 0.0624 | −0.0157 | |
| −0.0596 | −0.0664 | −0.0524 | 0.0186 | |
| 0.0204 | −0.0321 | 0.0322 | 0.0186 |
Step 8. According to the above calculation, the rank of alternatives is
Table 23
Probabilistic linguistic total prospect value of the all alternatives.
| Alternatives | |||||
| 0.1686 | 0.0374 | 0.1087 | −0.1598 | 0.0391 |
4.2Comparative Analysis
We compared our proposed model with three existing methods, which are the PLWA operator (Pang et al., 2016), the PL-TOPSIS method (Pang et al., 2016) and the PL-GRA method (Liang et al., 2018) (let
Table 24
Order by using diverse methods.
| Methods | Order | Optimal alternative | Bad alternative |
| PLWA operator (Pang et al., 2016) | |||
| PL-TOPSIS method (Pang et al., 2016) | |||
| PL-GRA method (Liang et al., 2018) | |||
| PL-MABAC | |||
| CPT-PL-MABAC method |
As you can see from the table above, all four methods obtain the same optimal site
5Conclusion
The location selection of the express distribution centre is of great significance in the development of the express delivery industry. Therefore, a new PL-MAGDM method (CPT-PL-MABAC) is established to be applied to this issue. The main contributions of this article can be summarized as follows. Firstly, we introduce the CPT into the original MABAC method under PLTSs. The psychological factors of experts are introduced in the evaluation. Secondly, we improved the entropy method under PLTSs, which is characterized by the mean value of attributes as the reference point. Thirdly, we improved the distance formula between the evaluation values of the alternative and PLBBA. Finally, the new method enriches the decision-making method based on PLTS and enriches the model of location selection.
The CPT-PL-MABAC model is a stable decision-making tool with direct computation algorithms. Also, it can get comprehensive final sorting results because it considers the potential values of gains and losses. However, the method proposed is ineffective in the face of some problems when attribute weights and evaluation information are not completely known. Moreover, we only refer to reference points and value functions in CPT.
In future studies, we plan to deal with the situation where the weights are not completely known. Additionally, this method can be applied to other specific decision-making problems and many other unpredictable and fuzzy environments, for example, green energy supplier issues and other location selection issues.
References
1 | Aydin, S. ((2021) ). A novel multi-expert MABAC method based on fermatean fuzzy sets. Journal of Multiple-Valued Logic and Soft Computing, 37: , 533–552. |
2 | Biswas, S. ((2020) ). Measuring performance of healthcare supply chains in India: a comparative analysis of multi-criteria decision making methods. Decision Making Applications in Management and Engineering, 3: , 162–189. |
3 | Chang, J.Y., Liao, H.C., Mi, X.M., Al-Barakati, A. ((2021) ). A probabilistic linguistic TODIM method considering cumulative probability-based Hellinger distance and its application in waste mobile phone recycling. Applied Intelligence, 51: (3). https://doi.org/10.1007/s10489-021-02185-w. |
4 | Chen, Z.Y., Wang, X.K., Peng, J.J., Zhang, H.Y., Wang, J.Q. ((2020) ). An integrated probabilistic linguistic projection method forMCGDMbased onELECTRE IIIand the weighted convex median voting rule. Expert Systems, 37: (6), e12593. |
5 | Du, Y.F., Liu, D. (2021). A novel approach to relative importance ratings of customer requirements in QFD based on probabilistic linguistic preferences. Fuzzy Optimization and Decision Making. https://doi.org/10.1007/s10700-020-09347-4. |
6 | Gao, J.W., Guo, F.J., Li, X.Z., Huang, X., Men, H.J. ((2021) ). Risk assessment of offshore photovoltaic projects under probabilistic linguistic environment. Renewable Energy, 163: , 172–187. |
7 | Gong, C., Xu, C.H., Ando, M., Xi, X.M. ((2018) ). A new method of portfolio optimization under cumulative prospect theory. Tsinghua Science and Technology, 23: , 75–86. |
8 | Gong, J.W., Li, Q., Yin, L.S., Liu, H.C. ((2020) ). Undergraduate teaching audit and evaluation using an extended MABAC method underq-rung orthopair fuzzy environment. International Journal of Intelligent Systems, 35: , 1912–1933. |
9 | Gou, X.J., Xu, Z.S., Liao, H.C. ((2017) ). Multiple criteria decision making based on Bonferroni means with hesitant fuzzy linguistic information. Soft Computing, 21: , 6515–6529. |
10 | He, S.S., Wang, Y.T., Peng, J.J., Wang, J.Q. ((2021) ). Risk ranking of wind turbine systems through an improved FMEA based on probabilistic linguistic information and the TODIM method. Journal of the Operational Research Society. https://doi.org/10.1080/01605682.2020.1854629. |
11 | Hu, J.H., Chen, P.P., Yang, Y. ((2019) ). An interval type-2 fuzzy similarity-based MABAC approach for patient-centered care. Mathematics, 7: (2), 140. https://doi.org/10.3390/math7020140. |
12 | Huang, Y., Lin, R., Chen, X. ((2021) ). An enhancement EDAS method based on prospect theory. Technological and Economic Development of Economy, 27: , 1019–1038. |
13 | Jiang, L.S., Liao, H.C. ((2021) ). Network consensus analysis of probabilistic linguistic preference relations for group decision making and its application in urban household waste classification. Journal of Cleaner Production, 278: 1, 122766. |
14 | Jiang, Z., Wei, G., Chen, X. ((2021) a). EDAS method based on cumulative prospect theory for multiple attribute group decision-making under picture fuzzy environment. Journal of Intelligent & Fuzzy Systems. https://doi.org/10.3233/JIFS-211171. |
15 | Jiang, Z., Wei, G., Wu, J., Chen, X. ((2021) b). CPT-TODIM method for picture fuzzy multiple attribute group decision making and its application to food enterprise quality credit evaluation. Journal of Intelligent & Fuzzy Systems, 4: , 10115–10128. |
16 | Jiang, Z., Wei, G., Guo, Y. ((2022) ). Picture fuzzy MABAC method based on prospect theory for multiple attribute group decision making and its application to suppliers selection. Journal of Intelligent & Fuzzy Systems. https://doi.org/10.3233/JIFS-211359. |
17 | Lei, F., Wei, G., Shen, W., Guo, Y. ((2021) ). PDHL-EDAS method for multiple attribute group decision making and its application to 3D printer selection. Technological and Economic Development of Economy, 1–22. https://doi.org/10.3846/tede.2021.15884. |
18 | Liang, D.C., Kobina, A., Quan, W. ((2018) ). Grey relational analysis method for probabilistic linguistic multi-criteria group decision-making based on geometric Bonferroni mean. International Journal of Fuzzy Systems, 20: , 2234–2244. |
19 | Liang, D.C., Dai, Z.Y., Wang, M.W., Li, J.J. ((2020) ). Web celebrity shop assessment and improvement based on online review with probabilistic linguistic term sets by using sentiment analysis and fuzzy cognitive map. Fuzzy Optimization and Decision Making, 19: , 561–586. |
20 | Liang, W.Z., Zhao, G.Y., Wu, H., Dai, B. ((2019) ). Risk assessment of rockburst via an extended MABAC method under fuzzy environment. Tunnelling and Underground Space Technology, 83: , 533–544. |
21 | Lin, M.W., Chen, Z.Y., Liao, H.C., Xu, Z.S. ((2019) ). ELECTRE II method to deal with probabilistic linguistic term sets and its application to edge computing. Nonlinear Dynamics, 96: , 2125–2143. |
22 | Lin, M.W., Chen, Z.Y., Xu, Z.S., Gou, X.J., Herrera, F. ((2021) ). Score function based on concentration degree for probabilistic linguistic term sets: an application to TOPSIS and VIKOR. Information Sciences, 551: , 270–290. |
23 | Liu, P.D., Zhang, P. ((2021) ). A normal wiggly hesitant fuzzy MABAC method based on CCSD and prospect theory for multiple attribute decision making. International Journal of Intelligent Systems, 36: , 447–477. |
24 | Liu, Y.S., Tang, L.N., Ma, Y.Z., Yang, T.H. ((2018) ). TFT-LCD module cell layout design using simulation and fuzzy multiple attribute group decision-making approach. Applied Soft Computing, 68: , 873–888. |
25 | Liu, H.B., Ma, Y., Jiang, L. ((2019) ). Managing incomplete preferences and consistency improvement in hesitant fuzzy linguistic preference relations with applications in group decision making. Information Fusion, 51: , 19–29. |
26 | Luo, D.D., Zeng, S.Z., Chen, J. ((2020) ). A probabilistic linguistic multiple attribute decision making based on a new correlation coefficient method and its application in hospital assessment. Mathematics, 8: (3), 340. https://doi.org/10.3390/math8030340. |
27 | Luo, Y.Y., Zhang, X.X., Qin, Y., Yang, Z., Liang, Y. ((2021) ). Tourism attraction selection with sentiment analysis of online reviews based on probabilistic linguistic term sets and the IDOCRIW-COCOSO model. International Journal of Fuzzy Systems, 23: , 295–308. |
28 | Ming, Y., Luo, L., Wu, X.L., Liao, H.C., Lev, B., Jiang, L. ((2020) ). Managing patient satisfaction in a blood-collection room by the probabilistic linguistic gained and lost dominance score method integrated with the best-worst method. Computers & Industrial Engineering, 145: , 106547. |
29 | Mo, H.M. ((2020) ). An emergency decision-making method for probabilistic linguistic term sets extended by D number theory. Symmetry-Basel, 12: (3), 380. https://doi.org/10.3390/sym12030380. |
30 | Pamucar, D., Stevic, Z., Zavadskas, E.K. ((2018) ). Integration of interval rough AHP and interval rough MABAC methods for evaluating university web pages. Applied Soft Computing, 67: , 141–163. |
31 | Pan, L., Xu, Z.S., Ren, P.J. ((2021) ) DEA cross-efficiency framework for efficiency evaluation with probabilistic linguistic term sets. Journal of the Operational Research Society, 72: (5), 1191–1206. |
32 | Pang, Q., Wang, H., Xu, Z.S. ((2016) ). Probabilistic linguistic linguistic term sets in multi-attribute group decision making. Information Sciences, 369: , 128–143. |
33 | Peng, H.G., Wang, J.Q. ((2020) ). Multi-criteria sorting decision making based on dominance and opposition relations with probabilistic linguistic information. Fuzzy Optimization and Decision Making, 19: , 435–470. |
34 | Qu, G.H., Xue, R.D., Li, T.J., Qu, W.H., Xu, Z.S. ((2020) ). A stochastic multi-attribute method for measuring sustainability performance of a supplier based on a triple bottom line approach in a dual hesitant fuzzy linguistic Environment. International Journal of Environmental Research and Public Health, 17: , 2138. |
35 | Rodriguez, R.M., Martinez, L., Herrera, F. ((2012) ). Hesitant fuzzy linguistic term sets for decision making. IEEE Transactions on Fuzzy Systems, 20: , 109–119. |
36 | Shen, A., Peng, S.L., Liu, G.F. ((2021) ). Transforming and decision-making based on probabilistic linguistic term sets with comparative linguistic expressions and incomplete assessments. Journal of Intelligent & Fuzzy Systems, 40: , 491–506. |
37 | Su, Y., Zhao, M., Wei, C., Chen, X. ((2021) a). PT-TODIM method for probabilistic linguistic MAGDM and application to industrial control system security supplier selection. International Journal of Fuzzy Systems. https://doi.org/10.1007/s40815-40021-01125-40817. |
38 | Su, Y., Zhao, M., Wei, G., Wei, C., Chen, X. ((2021) b). Probabilistic uncertain linguistic EDAS method based on prospect theory for multiple attribute group decision-making and its application to green finance. International Journal of Fuzzy Systems. https://doi.org/10.1007/s40815-40021-01184-w. |
39 | Sun, R.X., Hu, J.H., Zhou, J.D., Chen, X.H. ((2018) ). A hesitant fuzzy linguistic projection-based MABAC method for patients’ prioritization. International Journal of Fuzzy Systems, 20: , 2144–2160. |
40 | Teng, F., Liu, P.D., Liang, X. ((2021) ). Unbalanced probabilistic linguistic decision-making method for multi-attribute group decision-making problems with heterogeneous relationships and incomplete information. Artificial Intelligence Review, 54: (6). https://doi.org/10.1007/s10462-020-09927-1. |
41 | Tversky, A., Kahneman, D. ((1992) ). Advances in prospect theory: cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5: , 297–323. |
42 | Verma, R. ((2021) ). On intuitionistic fuzzy order-alpha divergence and entropy measures with MABAC method for multiple attribute group decision-making. Journal of Intelligent & Fuzzy Systems, 40: , 1191–1217. |
43 | Wang, B.L., Liang, J.Y. ((2020) ). A novel preference measure for multi-granularity probabilistic linguistic term sets and its applications in large-scale group decision-making. International Journal of Fuzzy Systems, 22: , 2350–2368. |
44 | Wang, L., Garg, H. ((2021) ). Algorithm for multiple attribute decision-making with interactive Archimedean norm operations under Pythagorean fuzzy uncertainty. International Journal of Computational Intelligence Systems, 14: (1), 503–527. |
45 | Wang, M.W., Liang, D.C., Xu, Z.S., Ye, D.J. ((2021) ). The evaluation of mobile health apps: a psychological perception-based probabilistic linguistic belief thermodynamic multiple attribute decision making method. Journal of the Operational Research Society, 72: (11). https://doi.org/10.1080/01605682.2020.1801361. |
46 | Wang, X.K., Wang, Y.T., Wang, J.Q., Cheng, P.F., Li, L. ((2020) ). A TODIM-PROMETHEE II based multi-criteria group decision making method for risk evaluation of water resource carrying capacity under probabilistic linguistic Z-number circumstances. Mathematics, 8: , 1190. https://doi.org/10.3390/math8071190. |
47 | Wei, G., Wei, C., Guo, Y. ((2021) a). EDAS method for probabilistic linguistic multiple attribute group decision making and their application to green supplier selection. Soft Computing, 25: , 9045–9053. |
48 | Wei, G., Wu, J., Guo, Y., Wang, J., Wei, C. ((2021) b). An extended COPRAS model for multiple attribute group decision making based on single-valued neutrosophic 2-tuple linguistic environment. Technological and Economic Development of Economy, 27: , 353–368. |
49 | Xiao, L., Wei, G., Guo, Y., Chen, X. ((2021) ). Taxonomy method for multiple attribute group decision making based on interval-valued intuitionistic fuzzy with entropy. Journal of Intelligent & Fuzzy Systems, 41: , 7031–7045. |
50 | Xie, W.Y., Xu, Z.S., Ren, Z.L., Herrera-Viedma, E. ((2020) ). The probe for the weighted dual probabilistic linguistic correlation coefficient to invest an artificial intelligence project. Soft Computing, 24: , 15389–15408. |
51 | Xu, C., Qian, G., Wang, H. ((2020) ). Stochastic multiple criteria comprehensive evaluation based on probabilistic linguistic preference relations: a case study of healthcare insurance audits in China. International Journal of Fuzzy Systems, 22: , 1607–1623. |
52 | Xu, X.G., Shi, H., Zhang, L.J., Liu, H.C. ((2019) ). Green supplier evaluation and selection with an extended MABAC method under the heterogeneous information environment. Sustainability, 11: (23), 6616. |
53 | Xu, X.H., Hou, Y.Z., He, J.S., Zhang, Z.T. ((2020) ). A two-stage similarity clustering-based large group decision-making method with incomplete probabilistic linguistic evaluation information. Soft Computing, 24: , 16869–16883. |
54 | Yazdi, A.K., Komijan, A.R., Wanke, P.F., Sardar, S. ((2020) ). Oil project selection in Iran: a hybrid MADM approach in an uncertain environment. Applied Soft Computing, 88: , 106066. |
55 | You, S.Y., Zhang, L.J., Xu, X.G., Liu, H.C. ((2020) ). A new integrated multi-criteria decision making and multi-objective programming model for sustainable supplier selection and order allocation. Symmetry-Basel, 12: , 302. |
56 | Yu, S.M., Du, Z.J., Lin, X.D., Luo, H.Y., Wang, J.Q. ((2020) ). A stochastic dominance-based approach for hotel selection under probabilistic linguistic environment. Mathematics, 8: , 1525. |
57 | Yue, N., Wu, D.R., Xie, J.L., Chen, S.L. ((2020) a). Probabilistic linguistic multi-criteria decision-making based on double information under imperfect conditions. Fuzzy Optimization and Decision Making, 19: , 391–433. |
58 | Yue, N., Xie, J.L., Chen, S.L. ((2020) b). Some new basic operations of probabilistic linguistic term sets and their application in multi-criteria decision making. Soft Computing, 24: , 12131–12148. |
59 | Zeng, W.Y., Li, D.Q., Yin, Q. ((2019) ). Weighted hesitant fuzzy linguistic term sets and its application in group decision making. Journal of Intelligent & Fuzzy Systems, 37: , 1099–1112. |
60 | Zhang, D., Su, Y., Zhao, M., Chen, X. ((2021) ). CPT-TODIM method for interval neutrosophic MAGDM and its application to third-party logistics service providers selection. Technological and Economic Development of Economy, 1–19. https://doi.org/10.3846/tede.2021.15758. |
61 | Zhang, H., Wei, G., Chen, X. ((2021) ). CPT-MABAC method for spherical fuzzy multiple attribute group decision making and its application to green supplier selection. Journal of Intelligent & Fuzzy Systems, 41: , 1009–1019. |
62 | Zhang, H.J., Palomares, I., Dong, Y.C., Wang, W.W. ((2018) ). Managing non-cooperative behaviors in consensus-based multiple attribute group decision making: an approach based on social network analysis. Knowledge-Based Systems, 162: , 29–45. |
63 | Zhang, S., Gao, H., Wei, G., Chen, X. ((2021) ). Grey relational analysis method based on cumulative prospect theory for intuitionistic fuzzy multi-attribute group decision making. Journal of Intelligent & Fuzzy Systems, 41: , 3783–3795. |
64 | Zhao, M.W., Wei, G.W., Chen, X.D., Wei, Y. ((2021) a). Intuitionistic fuzzy MABAC method based on cumulative prospect theory for multiple attribute group decision making. International Journal of Intelligent Systems, 36: , 6337–6359. |
65 | Zhao, M.W., Wei, G.W., Wei, C., Wu, J. ((2021) b). Pythagorean fuzzy TODIM method based on the cumulative prospect theory for MAGDM and its application on risk assessment of science and technology projects. International Journal of Fuzzy Systems, 23: (1), https://doi.org/10.1007/s40815-40020-00986-40818. |
66 | Zhao, M.W., Wei, G.W., Wu, J., Guo, Y.F., Wei, C. ((2021) c). TODIM method for multiple attribute group decision making based on cumulative prospect theory with 2-tuple linguistic neutrosophic sets. International Journal of Intelligent Systems, 36: , 1199–1222. |


