
PFA-GAN: Pose Face Augmentation Based on Generative Adversarial Network
Abstract
In this work, we propose a novel framework based on Generative Adversarial Networks for pose face augmentation (PFA-GAN). It enables a controlled pose synthesis of a new face image from a source face given a driving one while preserving the identity of the source face. We introduce a method for training the framework in a fully self-supervised mode using a large-scale dataset of unconstrained face images. Besides, some augmentation strategies are presented to expand the training set. The face verification experimental results demonstrate the effectiveness of the presented augmentation strategies as all augmented datasets outperform the baseline.
1Introduction
A person’s face plays a key role in the identification of individual members of our highly social species due to delicate differences that make every human face unique. These variations of a face pattern inform us also about characteristics such as age, gender, and race. Over the last decade, many remarkable works based on Deep Neural Networks have demonstrated unprecedented performance on several computer vision tasks, such as facial landmark detection, face identification, face verification, face alignment, emotion classification, etc. In addition, they showed that achieving a good generalization in unconstrained conditions strongly relies on training them on large and complex datasets. Well-annotated large-scale dataset can be both expensive and time-consuming to acquire. Hiring people to manually collect images and annotate them is not efficient at all since this manual process is widely recognized as error-prone. Furthermore, the existing face image datasets suffer from the problem of insufficient data amount for each person and the unbalanced pose data distribution between the classes. In addition, there is a lack of variations comparing to the real samples in the world. To cope with insufficient facial training data, visual data augmentation provides an effective alternative. It is a technique that enables practitioners to significantly increase the diversity of data available for training models, by transforming collected real face samples. The traditional visual data augmentation methods alter the entire face image by transferring image pixel values to new positions or by shifting pixel colours to new values. For instance, zooming in and out, rotating or reflecting the original image, translating, applying distortion and cropping. These generic methods have some limitations. (1) They do not scale well the number of variations of facial appearances, such as make-up, lighting, and skin color. (2) Creating high-level content such as rotating head while preserving the identity is a challenging problem (Zeno et al., 2019b) and it is still under study. The large discrepancy of head poses in the real world is a big challenge in face detection, identification (Farahani and Mohseni, 2019), and verification (Ribarić et al., 2008), due to lighting variations and self-occlusion. Therefore, many methods were proposed to generate face images with new poses. Pose synthesis methods can be classified into a 2D geometry-based approach, a 3D geometry-based approach, and a learning-based approach. The 2D and 3D based methods appeared earlier than learning-based approaches, have obvious advantage in that they need a small amount of training data. The 2D-based methods rely on building a PCA model for a face shape to control only yaw rotations (Feng et al., 2017), while the 3D based methods synthesize face images with new variations of poses using a 3D morphable face model (Crispell et al., 2017; Blanz and Vetter, 1999; Zhu et al., 2016; Guo et al., 2017). In recent years, many learning-based methods have been proposed for face rotation, where most of them rely on a generative adversarial network (Tran et al., 2017; Tian et al., 2018; Cao et al., 2018a; Antoniou et al., 2018; Yin et al., 2017; Huang et al., 2017; Zeno et al., 2019a). For example, the methods DRGAN (Tran et al., 2017), CRGAN (Tian et al., 2018) and LB-GAN (Cao et al., 2018a) were proposed to rotate a face image around the yaw axis only. While DRGAN synthesizes a new pose even for extreme profiles (
However, we argue that there are several drawbacks to the listed methods. The reposing method proposed in Crispell et al. (2017) produces many distortions in face structure and does not fix the background. And the 3D based approach (Blanz and Vetter, 1999) fails with large poses and it requires some additional steps to generate the hidden regions (e.g. the teeth). The augmentation methods in Zhu et al. (2016), Guo et al. (2017) reduce the realism of the generated images. On the other side, the GAN learning-based methods (Tran et al., 2017; Tian et al., 2018; Cao et al., 2018a; Antoniou et al., 2018; Yin et al., 2017; Huang et al., 2017) obtain impressive results, but they need additional information such as conditioning labels (e.g. indicating a head pose, 3DMM parameters). More specifically, Yin et al. (2017), Huang et al. (2017) need frontal face annotations, while (Tran et al., 2017; Tian et al., 2018; Cao et al., 2018a; Antoniou et al., 2018) need profile labels, while the IP-GAN (Zeno et al., 2019a) framework does not require any pose annotations. But despite this, it failed to learn disentangled representation of pose and identity on an unconstrained dataset of face images. Besides, the learning scheme of IP-GAN is very complex, which makes it difficult for it to converge.
To address the issues above, in this work we focus on pose face transformation for visual data augmentation using the Generative Adversarial Networks. We propose a novel GAN framework that enables a controlled synthesis of new face images from a single source face image given a driving face image while preserving the subject identity. The framework is trained in self-supervised settings using pairs of source and driving face images. To demonstrate the performance of our model, some face verification experiments are conducted using our proposed pose augmentation strategies. The framework architecture is described in Section 3, and the self-supervised training method in Section 4.
To conclude, our contributions are:
• We present the Pose Face Augmentation GAN (PFA-GAN) that can transform a pose of a source face image using another face image while preserving the identity of the source image, as well as the pose and the expression of the driving face image. The proposed framework consists of an identity encoder network, a pose encoder network, a generator, and a discriminator.
• We introduce a novel method for training the network in fully self-supervised settings using a large-scale dataset of unconstrained face images.
• We introduce some augmentation strategies that demonstrate how a baseline training set can be augmented to increase the pose variations.
• We conduct some comparative experiments on face verification. Our results clearly show that the augmented datasets based on our method outperform the baseline methods.
2Related Work
2.12D/3D Model-Based
Feng et al. (2017) proposed a 2D-based method to generate profile virtual faces with out-of-plane pose variations. They built a PCA-based shape model to control only the yaw rotations since the pose varies with the same rotation direction of the original shape, i.e. left or right. Meanwhile, many approaches employed 3D face models for face pose translation (Crispell et al., 2017; Blanz and Vetter, 1999; Zhu et al., 2016; Guo et al., 2017). Crispell et al. (2017) use a 3D face shape estimation method, followed by a rendering pipeline for arbitrarily reposing of faces and altering the light conditions. Although the results of the face re-lighting method are good, reposing of the face produces many distortions in its structure. In addition, the background is not fixed since it is rotated along with the direction of the face rotation. Blanz and Vetter (1999) proposed a method to estimate a 3D morphable face model by transforming the shape and the texture of a face image into a vector space representation. Then, faces with new poses and expressions can be modelled by modifying the estimated parameters to match the target 3D face model. This method is good at generating faces with small poses, but it failed with large poses due to the serious loss of the facial texture. Furthermore, some additional steps are required at synthesizing facial expressions such as smiling to generate the hidden regions (e.g. the teeth). Zhu et al. (2016) introduced the 3D Dense Face Alignment (3DDFA) algorithm to solve face alignment in large poses. 3DDFA has also been used to profile faces, which means synthesizing the face appearances in profile view from medium pose samples by predicting the depth of face image. However, this augmentation method reduces the realism of the generated images. Guo et al. (2017) proposed a face inverse rendering method (3DFaceNet) to recover geometry and lighting from a single image. With that, they can generate new face images with different attributes. Nevertheless, their inverse rendering procedure has limitations, and it may lead to inaccurate fitting for face images (e.g. estimating the coarse face geometry and pose parameters from a face image).
2.2GANs-Based
Recently, generative adversarial network model learning (Tran et al., 2017; Tian et al., 2018; Cao et al., 2018a; Antoniou et al., 2018; Yin et al., 2017; Huang et al., 2017; Zeno et al., 2019a) demonstrated an outstanding ability to synthesize face images with new poses. Tran et al. (2017) introduced Disentangled Representation Learning-Generative Adversarial Network (DR-GAN), where the model takes a face image of any pose as input and outputs a synthetic face, frontal or rotated with the target pose, even for extreme profiles (
2.3IP-GAN
Zeno et al. (2019a) proposed a framework for Learning Identity and Pose Disentanglement in Generative Adversarial Networks (IP-GAN). To generate a face image of any specific identity with an arbitrary target pose, IP-GAN incorporates the pose information in the synthesis process. Different from the recent work (Yin et al., 2017) that uses a 3D morphable face simulator to generate pose information and the works (Tran et al., 2017; Tian et al., 2018; Huang et al., 2017) that encode pose annotation in a one-hot vector, IP-GAN can learn such information by explicitly disentangling identity and pose representation from a face image in fully self-supervised settings. The overall architecture of the IP-GAN framework is depicted in Zeno et al. (2019a), and consists of five parts: 1) the identity encoder network
3The Proposed Framework
Inspired by the IP-GAN model, we present in this section a novel framework (PFA-GAN) for pose face augmentation based on a generative adversarial network.
3.1PFA-GAN
To simplify the proposed architecture in Zeno et al. (2019a), and according to the specific goal of the PFA-GAN in generating face images with new poses, we remove the Classification Network C, as there is no need to add a new task of face recognition to PFA-GAN, and preserving the subject identity in the generated face image is guaranteed by the use of the content loss function. To reduce the complexity of the learning method, we propose removing the generation pathway and focusing on the work of the transformation pathway, which consists of two sub-paths: reconstruction and transformation. The task of the head pose encoder network
3.2Model Description
Let
3.3Framework Architecture
Fig. 1
The proposed framework architecture, pose encoder network, identity encoder network, generator, discriminator. Learning scheme from left to right: the reconstruction sub-path, the transformation sub-path.
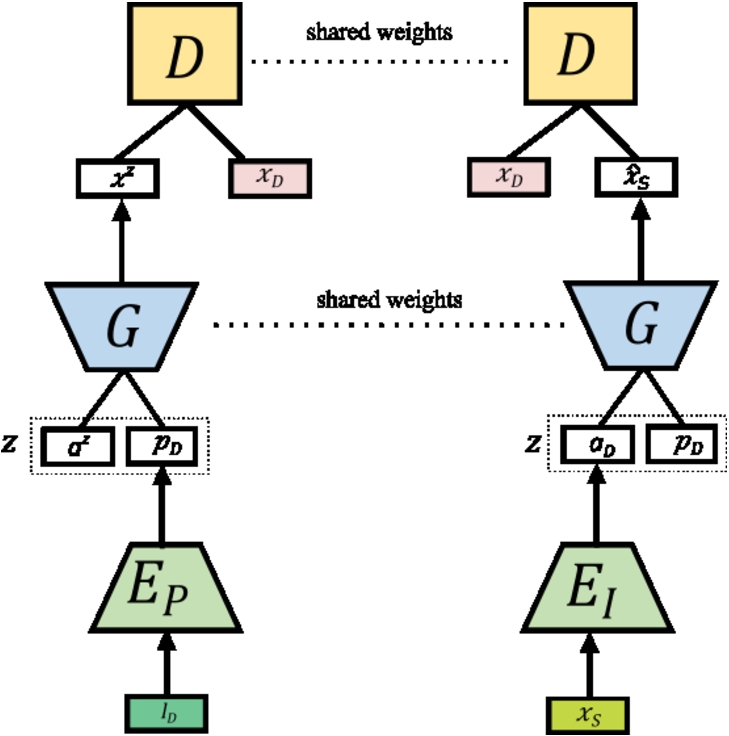
The proposed framework consists of the following four components, see Fig. 1:
• The pose encoder network
• The identity encoder network
• The generator
• The discriminator
4The Proposed Learning Algorithm
In this section, we present our method for learning a pose face augmentation model (PFAGAN). To achieve this goal the learning scheme is divided into two sub-paths, reconstruction and transformation, see Fig. 1. While the reconstruction sub-path aims to learn to generate a face image with the target pose, the learning goal of the transformation sub-path is to synthesize the target face image while preserving the identity of the subject. At each iteration, only one of these two sub-paths is randomly selected with a probability of 0.5.
4.1Reconstruction Sub-Path
The reconstruction pathway trains the generator G, the pose encoder network
(1)
(2)
(3)
(4)
(5)
4.2Transformation Sub-Path
The transformation sub-path trains the networks
(6)
(7)
(8)
(9)
(10)
4.3The Overall Loss Function
The final loss function is a weighted sum of all losses defined in Eqs. (1)–(10):
(11)
(12)
(13)
5Experiments
5.1Dataset
The PFA-GAN is trained on a subset of the MS-Celeb-1M (Guo et al., 2016) dataset, which contains about 5M images of 80K celebrities with unbalanced viewpoint distributions and with a very large appearance variation (e.g. due to gender, race, age, or even makeups). We use 36K face images belonging to 528 different identities, while no pose or identity annotations are employed in the training process. For each face image, we first detect the facial region using the multi-task cascaded CNN detector (MTCNN) (Zhang et al., 2016) and then align and resize the detected face to
5.2Implementation Details
We use the same implementations of the generator G and the discriminator D in IP-GAN that were introduced by Tian et al. (2018). For the pose encoder network
5.3Interpolation of Pose Latent Space
In this section, we demonstrate that a pose of the generated face images can be gradually changed with the latent vector. We call this phenomenon face pose morphing. We have tested our model on the selected subset from the MS-Celeb-1M (Guo et al., 2016) dataset. We first choose a pair of images
(14)
Fig. 2
Interpolation of the pose latent space.

5.4Visual Data Augmentation Strategies
The traditional visual data augmentation methods alter the entire face image by transferring image pixel values to new positions or by shifting pixel colours to new values. These generic methods ignore high-level content such as moving the head or adding a smile, so in this section, we show the effectiveness of using our model as an alternative face specific augmentation method. The ability of the PFA-GAN model to perform a controlled synthesis of a face image allows enlarging the volume of data for training or testing by generating new face images with new poses. So, using our proposed model, for each image in the dataset, an unlimited number of images can be generated for the same identity subject with a great variety of face poses. Assuming the original dataset is R, pose face augmentation can be represented by the following transformation:
(15)
(16)
• First augmentation strategy (Aug-S1). For each image in our dataset, we choose a random driving face image, and by following the interpolation technique described in Section 5.3, we choose the interpolated pose vector
(17)
• Second augmentation strategy (Aug-S2). Similar to the first augmentation strategy, we select the interpolated pose vector
(18)
• Third augmentation strategy (Aug-S3). The generated images may have a large degree of variation from the original with regard to head pose and facial expressions. That’s why for each source face image in our dataset, we randomly select a driving image to extract the pose embedding vector
Figure 3 shows examples of face images from the augmented datasets. We can note the pose variation between them.(19)
Fig. 3
Face image examples from the original and augmented datasets. From left to right: the original dataset R, the augmented datasets

5.5Face Verification Task
In this subsection, we evaluate whether the augmented datasets will improve the performance of the face verification task or not. In general, face verification needs the following steps: training a convolution neural network classifier on a dataset, then using it as a feature extraction network to extract the embedding vectors for a pair of face images from testing datasets. Next, the extracted two vectors are sent to the distance function to calculate the similarity between them, and according to the threshold, the function judges whether it is the face of the same person or not. Two classifiers are used,
Table 1
Characteristics of the training and testing datasets.
| Dataset | Number of people | Total images |
| R | 529 | 36000 |
|
| 529 | 72000 |
|
| 529 | 72000 |
|
| 529 | 72000 |
| LFW | 5749 | 13233 |
| CFP-FP | 500 | 2000 |
| CFP-FF | 500 | 5000 |
| AgeDB | 570 | 16488 |
| CALFW | 4025 | 12174 |
| CPLFW | 3884 | 11652 |
| VGGFace2-FP | 500 | 11000 |
Table 2
Verification accuracy after training the classifier
| Classifier | Training dataset | LFW | CFP-FP | CFP-FF | AgeDB | CAL-FW | CPLFW-FP | VGG-Face2 |
|
| R | 89.77 | 78.39 | 88.73 | 69.23 | 72.32 | 70.15 | 80.74 |
|
|
| 91.00 | 80.04 | 89.57 | 70.17 | 72.25 | 70.72 | 81.08 |
|
|
| 90.88 | 80.34 | 89.81 | 70.65 | 71.80 | 70.78 | 81.36 |
|
|
| 91.53 | 81.23 | 89.70 | 71.20 | 72.43 | 70.28 | 81.16 |
Table 3
Verification accuracy after training the classifier
| Classifier | Training dataset | LFW | CFP-FP | CFP-FF | AgeDB | CAL-FW | CPLFW-FP | VGG-Face2 |
|
| R | 89.38 | 77.97 | 88.39 | 68.30 | 70.50 | 69.90 | 80.06 |
|
|
| 90.90 | 80.13 | 89.67 | 70.38 | 72.03 | 70.90 | 80.44 |
|
|
| 91.23 | 81.17 | 89.73 | 69.23 | 72.18 | 71.42 | 81.56 |
|
|
| 91.68 | 81.70 | 89.77 | 70.93 | 72.67 | 71.58 | 81.64 |
We feed the augmented datasets to the classifiers
6Conclusion
In this paper, we proposed a self-supervised framework PFA-GAN based on Generative Adversarial Networks to control the pose of a given face image using another face image, where the identity of the source image is preserved in the generated one. This framework makes no assumptions about the pose of the source images since the proposed training method allows us to train the overall networks in fully self-supervised settings using a large-scale unconstrained face images dataset. Finally, we use the trained model as a tool for visual data augmentation. Our PFA-GAN framework demonstrates the ability to synthesize photorealistic and identity-preserving faces with arbitrary poses, which improve face recognition tasks. The face verification experimental results demonstrate the effectiveness of the proposed framework for pose face augmentation as all augmented datasets outperform the baseline. Furthermore, to the best of our knowledge, we are the first to train such a model using a large-scale unconstrained dataset of face images. One exciting avenue for future work is to improve the network architecture by utilizing operations such as adaptive instance normalization (AdaIN) and to train our framework on other datasets larger than ours.
References
1 | Antoniou, A., Storkey, A., Edwards, H. (2018). Data Augmentation Generative Adversarial Networks. Iclr. |
2 | Blanz, V., Vetter, T. ((1999) ). A morphable model for the synthesis of 3D faces. In: Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH, 1999. |
3 | Cao, J., Hu, Y., Yu, B., He, R., Sun, Z. (2018a). Load balanced GANs for multi-view face image synthesis. abs/1802.07447. |
4 | Cao, Q., Shen, L., Xie, W., Parkhi, O.M., Zisserman, A. ((2018) b). VGGFace2: a dataset for recognising faces across pose and age. In: Proceedings – 13th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2018. |
5 | Crispell, D., Biris, O., Crosswhite, N., Byrne, J., Mundy, J.L. (2017). Dataset augmentation for pose and lighting invariant face recognition. arXiv:1704.04326 [cs.CV]. |
6 | Deng, J., Guo, J., Xue, N., Zafeiriou, S. ((2019) ). ArcFace: additive angular margin loss for deep face recognition. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. |
7 | Farahani, A., Mohseni, H. ((2019) ). Multi-pose face recognition using pairwise supervised dictionary learning. Informatica, 30: , 647–670. |
8 | Feng, Z.H., Kittler, J., Christmas, W., Huber, P., Wu, X.J. ((2017) ). Dynamic attention-controlled cascaded shape regression exploiting training data augmentation and fuzzy-set sample weighting. In: Proceedings – 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017. |
9 | Guo, Y., Zhang, L., Hu, Y., He, X., Gao, J. (2016). MS-celeb-1M: a dataset and benchmark for large-scale face recognition. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). |
10 | Guo, Y., Zhang, J., Cai, J., Jiang, B., Zheng, J. (2017). 3DFaceNet: real-time dense face reconstruction via synthesizing photo-realistic face images. arXiv:1708.00980. |
11 | He, K., Zhang, X., Ren, S., Sun, J. ((2016) ). Deep residual learning for image recognition. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. |
12 | Huang, G.B., Ramesh, M., Berg, T., Learned-Miller, E. (2007). Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. Tech. Rep. 07-49, University of Massachusetts, Amherst. |
13 | Huang, R., Zhang, S., Li, T., He, R. ((2017) ). Beyond face rotation: global and local perception GAN for photorealistic and identity preserving frontal view synthesis. In: Proceedings of the IEEE International Conference on Computer Vision. |
14 | Johnson, J., Alahi, A., Fei-Fei, L. (2016). Perceptual losses for real-time style transfer and super-resolution. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). |
15 | Kingma, D.P., Ba, J.L. ((2015) ). Adam: a method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015 – Conference Track Proceedings. |
16 | Moschoglou, S., Papaioannou, A., Sagonas, C., Deng, J., Kotsia, I., Zafeiriou, S. ((2017) ). AgeDB: the first manually collected, in-the-wild age database. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. |
17 | Parkhi, O.M., Vedaldi, A., Zisserman, A. ((2015) ). Deep face recognition. In: British Machine Vision Conference, Vol. 1: , pp. 41.1–41.12. |
18 | Ribarić, S., Fratrić, I., Kiš, K. ((2008) ). A novel biometric personal verification system based on the combination of palmprints and faces. Informatica, 19: (1), 81–100. |
19 | Sengupta, S., Chen, J.C., Castillo, C., Patel, V.M., Chellappa, R., Jacobs, D.W. ((2016) ). Frontal to profile face verification in the wild. In: 2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016. |
20 | Simonyan, K., Zisserman, A. ((2015) ). Very deep convolutional networks for large-scale image recognition. In: 3rd International Conference on Learning Representations, ICLR 2015 – Conference Track Proceedings. |
21 | Tian, Y., Peng, X., Zhao, L., Zhang, S., Metaxas, D.N. ((2018) ). CR-GAN: learning complete representations for multi-view generation. In: IJCAI International Joint Conference on Artificial Intelligence. |
22 | Tran, L., Yin, X., Liu, X. ((2017) ). Disentangled representation learning GAN for pose-invariant face recognition. In: Proceedings – 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017. |
23 | Yin, X., Yu, X., Sohn, K., Liu, X., Chandraker, M. ((2017) ). Towards large-pose face Frontalization in the wild. In: Proceedings of the IEEE International Conference on Computer Vision. |
24 | Zeno, B., Kalinovskiy, I., Matveev, Y. (2019a). IP-GAN: learning identity and pose disentanglement in generative adversarial networks. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). |
25 | Zeno, B.H., Kalinovskiy, I.A., Matveev, Y.N. ((2019b) ). Identity preserving face synthesis using generative adversarial networks. In: ACM International Conference Proceeding Series. |
26 | Zhang, K., Zhang, Z., Li, Z., Qiao, Y. ((2016) ). Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23: (10), 1499–1503. |
27 | Zheng, T., Deng, W. (2018). Cross-pose LFW: a database for studying cross-pose face recognition in unconstrained environments. |
28 | Zheng, T., Deng, W., Hu, J. (2017). Cross-age LFW: a database for studying cross-age face recognition in unconstrained environments. ArXiv: abs/1708.08197. |
29 | Zhu, X., Lei, Z., Liu, X., Shi, H., Li, S.Z. ((2016) ). Face alignment across large poses: a 3D solution. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. |


