
Learning argumentation frameworks from labelings
Abstract
We consider the problem of learning argumentation frameworks from a given set of labelings such that every input is a σ-labeling of these argumentation frameworks. Our new algorithm takes labelings and computes attack constraints for each argument that represent the restrictions on argumentation frameworks that are consistent with the input labelings. Having constraints on the level of arguments allows for a very effective parallelization of all computations. An important element of this approach is maintaining a representation of all argumentation frameworks that satisfy the input labelings instead of simply finding any suitable argumentation framework. This is especially important, for example, if we receive additional labelings at a later time and want to refine our result without having to start all over again. The developed algorithm is compared to previous works and an evaluation of its performance has been conducted.
1.Introduction
An abstract argumentation framework due to Dung [15] is defined as a graph, where the nodes are arguments and the edges represent attacks between these arguments. An attack from an argument A to another argument B means that, if we consider the argument A to be acceptable, then we have to reject B, since A contradicts B. The goal of this approach is to model human argumentation in a formal manner and to use this model for reasoning. Abstract argumentation frameworks are interpreted using the notion of an (argumentation) semantics. A semantics characterizes acceptable sets of arguments (called extensions), which are supposed to model a valid outcome of the argumentation represented by an argumentation framework. In particular, they usually require that extensions are conflict-free, i.e., that there is no conflict between arguments of the extension, and that it defends itself, i.e., it counterattacks all its attackers (the latter property is called admissibility). While Dung proposed several different semantics in his seminal paper, like complete, grounded, preferred, and stable semantics, there have since been many proposals for new semantics [4], all with different goals in mind.
Extension-based semantics focus on the accepted arguments only, so, any extension with respect to some semantics only consists of the arguments that are considered acceptable. That means we also get the implicit knowledge that all other arguments are not accepted. However, we do not know for what reason these arguments are not accepted. They could be directly attacked by some acceptable argument, meaning the extension actively contradicts them. In contrast to that they could also be not accepted because they are part of some conflict, unrelated to the acceptable arguments, which means these arguments could potentially also be compatible with the acceptable arguments. This additional information can be encoded in labelings [17]. In a labeling each argument of the argumentation framework receives a label, if it is considered acceptable the argument is labeled
In Inductive Logic Programming [21] we derive from a given set of examples and background knowledge a hypothesized logic program that entails these examples. In a similar manner, algorithms for Bayesian Network Learning [13,18] are concerned with inducing a bayesian network from given data. Overall, both of these approaches are concerned with generalizing from observations or examples to a program or network which entails this knowledge and therefore also allows for inferring new knowledge in line with the input knowledge.
This approach is also interesting for the field of argumentation. In general, argumentation semantics allows us to perform inference with an abstract argumentation framework, by determining semantical information (extensions or labelings) from given syntactical information (in the form of an argumentation framework). In this work, we are, as already hinted at above, interested in the reverse direction, i.e., the process of learning a syntactic structure from semantical information. So, given a set of labelings we wish to infer a suitable attack relation that explains this input. That means, we want to find an argumentation framework that has at least those labelings.
This is interesting, if we look for example at the area of argument mining [20] which is concerned with extracting arguments and their relations from text. There, extracting the relations between arguments is especially hard [18]. This is one area where inductive learning approaches are useful, since they can aid us in constructing the attack relation for a set of arguments. Additionally, learning the attack relation for a set of arguments can also be helpful in terms of explainability [1,12] since this allows us to construct better argumentative explanations based on the underlying argumentation framework itself, see e.g., [16,27]. It will also allow us to better understand how the labelings originated and how we could challenge them, as the following example will highlight.
Assume a situation where we are able to meet up with a person A that has an anti-vax stance. We are able to discuss with them about the topic of the COVID-19 vaccine and our goal is to understand their personal reasoning process. Doing so may allow us to find better counterarguments in future discussions on the topic and it will also aid us in identifying false conclusions that A might have made, so that we can potentially clear them up. The internal reasoning process of A is represented as an argumentation framework, which is hidden to us. During the discussion, we may ask A for his opinion on different statements on the topic. From A’s answers we can then infer a labeling, which essentially assigns to each argument their stance, i.e., either they agree (
For example, lets consider the following four arguments:
(a) The development of the COVID-19 vaccine has been rushed.
(b) The COVID-19 vaccine reduces the risk of infection.
(c) The COVID-19 vaccine does not work at all.
(d) The COVID-19 vaccine is dangerous and has various side effects.
From our first discussion with A we may conclude that they agree with the arguments a and d while disagreeing with b and c. This would then translate to the complete labeling
For example, if we want to refine our understanding of A’s reasoning, we could initiate another discussion with them so that we can obtain another complete labeling. After our second discussion, we may get the labeling
Fig. 1.
Some argumentation frameworks that were reconstructed from the labelings
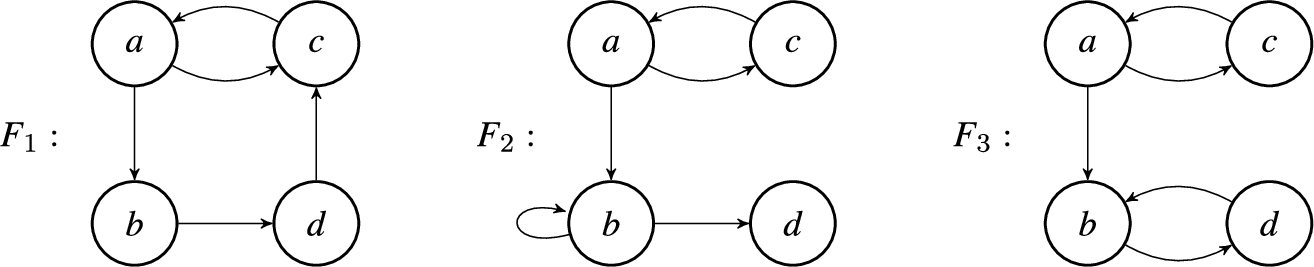
With the argumentation framework(s) that we have learned from the labelings, we can then for example try to identify missing or nonsensical attacks (e.g. there should probably be an attack from b on c). Another thing we can do, is identify key arguments that we can disprove to sway the opinion of the person A. For example, if we present some evidence that the vaccine development has in fact not been rushed, A might change their opinion on the argument a and subsequently this could influence their stance on arguments b and c.
In this work, we will answer the following research question:
Research Question.
For a given set of labelings
(1) if
(2) if
We explicitly allow the labelings to have different semantics in order to be more general, especially since different semantics have different advantages depending on the application [4]. In other words, for a given set of labelings L with respect to different semantics, we want to define a method to construct the set of all argumentation frameworks F, such that at least all labelings in L are labelings of F. In that case, we will also say that the argumentation framework F is consistent with L.
The general problem of learning argumentation frameworks has only received limited attention so far [23,25] and none of these works are able to address the exact scenario we outlined above. In their paper, Niskanen et al. [23] investigate the synthesis of argumentation frameworks from positive and negative examples. These examples are extensions with respect to conflict-free, admissible, complete or stable semantics. A positive example E is then encoded in some logical formula, representing the information in E. All positive examples are encoded with a corresponding formula for their semantics and the negative examples are encoded as the negation of those formulae. Their approach also allows for the attachment of weights to each example. The encoded examples, together with their weights, are given to a MaxSAT solver, which returns the optimal solution, i.e., an argumentation framework, which is consistent with all or most of the positive examples and the least of the negative examples.
On the other hand, Riveret et al. [25] propose an approach for learning attacks from labelings. Their algorithm is built around the grounded semantics and takes a stream of labelings as input. Since it is not possible to reconstruct the argumentation framework by only knowing the (uniquely determined) grounded extension, Riveret et al. decided to extend their scenario as follows. Their algorithm works with knowledge about the sub-frameworks of the argumentation framework, i.e., restrictions of the graph on different subsets of arguments. The input of their algorithm therefore consists of grounded labelings of different sub-frameworks. For the process of learning the hidden argumentation framework we start with a weighted argumentation framework, where every attack has an initial weight of 0. Then, for each input labeling we iterate over all combinations of two arguments and check whether they satisfy one of four rules, which essentially encode the different conditions a grounded labelings has to fulfill. If a rule is satisfied, the weight of the attacks between these two arguments are updated accordingly. After examining all input labelings we remove all attacks whose weight is below a certain threshold from the argumentation framework. The resulting argumentation framework is then the approximation of the original hidden argumentation framework.
While the above mentioned approaches can be used to construct argumentation frameworks from labelings or extensions, they only return a single argumentation framework as a result. This might not always be desirable, as we illustrated in the above example. In the case of the approach by Riveret et al. [25], their algorithm also relies on additional information about sub-frameworks.
Therefore, in this work, we propose an algorithm that better addresses this scenario by maintaining a representation of all consistent argumentation frameworks at all times. In general, our algorithm works according to the following procedure: We are given a set of arguments
To summarise, the contributions of this paper are as follows:
(1) We introduce the concept of attack constraints and define semantic constraint functions that compute attack constraints for a given labeling (Section 3.1–3.2).
(2) We define a novel algorithm for learning argumentation frameworks from labelings that utilizes these constraints to maintain a representation of all consistent argumentation frameworks (Section 3.3).
(3) We conduct an experimental evaluation of our algorithm, comparing a naive and a parallelized implementation (Section 4).
(4) We discuss our algorithm and distinguish it from the existing work on the topic (Section 5).
In Section 2 we introduce the necessary background knowledge on abstract argumentation and labeling-based semantics and Section 6 concludes the paper. Proofs of technical results can be found in the Appendix.
2.Background
We consider abstract argumentation frameworks [15] defined as follows.
Definition 2.1.
An argumentation framework (AF) is a pair
We say that an argument
A labeling-based semantics maps each argumentation framework to a set of labelings [8,17]. These are functions that assign to each argument a label indicating the acceptance status of the argument. The labeling-based semantics that we focus on in this paper use three labels:
Definition 2.2.
A labeling of a set
A semantics σ is represented by a condition that determines whether a labeling ℓ of F is a σ-labeling. We now define the semantics that we focus on in this paper, namely the complete, grounded, preferred and stable semantics. While not typically considered to be a semantics, we also define the notion of a conflict-free and admissible labeling and treat these conditions as semantics. For that, we will use the definitions from [8] or definitions that are equivalent to those.
A labeling is conflict-free whenever no two arguments a and b exist such that a attacks b and both are labeled
Definition 2.3.
A labeling ℓ of an argumentation framework
(1) if a is labeled
(2) if a is labeled
A labeling is admissible whenever it is conflict-free and, in addition, every argument a that is accepted is attacked only by arguments that are rejected. This amounts to requiring accepted arguments to be defended: in an admissible labeling, if a is accepted then all attackers of a are rejected and thus (as a consequence of Condition 2 in Definition 2.3) a is defended from these attackers by other arguments that are accepted.
Definition 2.4.
A labeling ℓ of an argumentation framework
(1) ℓ is conflict-free.
(2) if a is labeled
A labeling is complete whenever it is admissible and, in addition, (1) every argument attacked by an accepted argument is rejected, and (2) every argument whose attackers are rejected is accepted. This condition amounts to requiring defended arguments to be accepted: if all attackers of an argument a are attacked by some argument that is accepted, then all attackers of a are rejected and hence a is accepted.
Definition 2.5.
A labeling ℓ of an argumentation framework
(1) ℓ is admissible.
(2) if some attacker of a is labeled
(3) if all attackers of a are labeled
The remaining semantics are all defined in terms of complete labelings. Firstly, a labeling is grounded if it is complete and if it is minimal with respect to accepted arguments. The grounded labeling of an argumentation framework is unique and represents the most skeptical point of view on which arguments to accept [8,15]. A preferred labeling is a complete labeling that is maximal with respect to accepted arguments. Preferred labelings represent maximally credulous points of view on which arguments to accept. Finally, a stable labeling is a complete labeling in which no argument is undecided.
Definition 2.6.
Let
ℓ is a grounded if it is complete and if there is no complete labeling
ℓ is a preferred if it is complete and if there is no complete labeling
ℓ is a stable if it is complete and if
In the following, we will denote with
Proposition 2.1.
(1) Every admissible labeling is conflict-free.
(2) Every complete labeling is admissible.
(3) Every grounded, preferred and stable labeling is complete.
(4) Every stable labeling is preferred.
3.Learning from labelings
In this section, we introduce a novel algorithm for learning argumentation frameworks from labelings with the goal of constructing (or representing) all argumentation frameworks that are relevant to the input labelings. We start with formally defining the AF learning problem that we want to address. Afterwards, we define the concept of attack constraints and finally describe in detail our algorithm to solve this problem.
For the remainder of this work, we will consider the set of arguments
Definition 3.1.
An input pair is a pair
We will also sometimes refer to ℓ as an input labeling. So, given a set of inputs
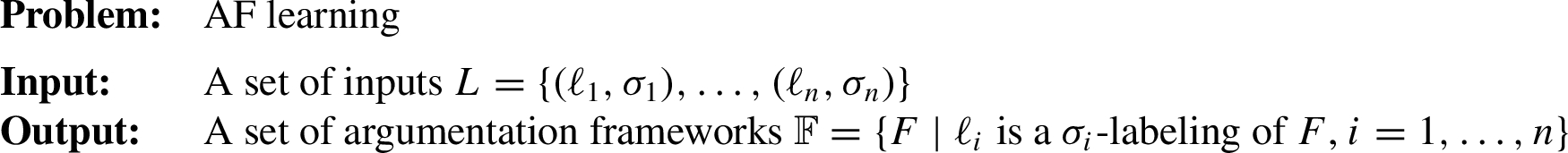
The general idea behind our approach to solve the AF learning problem is as follows. We use propositional atoms of the form
This approach can then also be extended to a set of input labelings
3.1.Attack constraints
The key element of our algorithm are the so called attack constraints. Before we define the concept of attack constraints, we first introduce the propositional language that we use to represent attacks in argumentation frameworks.
Let
Definition 3.2.
Let
A positive occurrence
Due to the correspondence between the above defined atoms
Definition 3.3.
Together with the fixed set of arguments
Example 1.
Consider the set of arguments
Recalling Section 2, under any semantics an argument can only be accepted if it is not attacked by any other accepted argument (conflict-freeness). In addition to that, the acceptance of an argument also depends on the label of its attackers. If the attackers of the argument a are labeled
For that reason, we define the attack constraints from the local perspective of an argument.
Definition 3.4.
Let
So, instead of specifying one constraint per input labeling, we will represent a labeling ℓ with a set of attack constraints. For this labeling constraint every model corresponds to an argumentation framework that has ℓ as a σ-labeling.
Definition 3.5.
Let
It is also worth noting that by defining the attack constraints as formulas over
Proposition 3.1.
Let
Finally, we may also say that an argumentation framework
Definition 3.6.
Let
3.2.Semantic constraint functions
To construct the constraints for an input
This function then takes the input labeling ℓ and an argument
Recall that in our scenario we want to compute all argumentation frameworks F such that for all inputs
The set of arguments
Whenever the semantics σ is not relevant or follows from context, we denote the labeling constraint for the labeling ℓ with just
Then, the following two conditions must hold for all labelings:
(1) The semantic constraint function is sound for all labelings ℓ, i.e.,
(2) The semantic constraint function is complete for all labelings ℓ, i.e.,
So, if there exists a semantic constraint function
In the following, we will define the semantic constraint function for conflict-free, admissible, complete and stable semantics and give some examples to illustrate what kind of restrictions the constraints of each semantics impose on an argumentation framework.
3.2.1.Conflict-free semantics
First, we recall the conditions that a labeling ℓ has to satisfy in order to be considered conflict-free:
(1) if a is labeled
(2) if a is labeled
From this we can derive what an attack constraint for a conflict-free input
In addition to that, every argument a can be attacked by any other argument c, that does not have the label
Definition 3.7.
Let
The attack constraints computed via the semantic constraint function
Theorem 3.1.
Let
The semantic constraint function is sound for conflict-free input labelings ℓ, i.e.,
Example 2.
Consider the set of arguments
These conditions represent the input labeling ℓ. They capture that the
We may also notice that the attack constraints contain no restrictions on attacks originating from c or d. That means these attacks are considered possible and we have to consider any combination of those when constructing the argumentation frameworks consistent with the conditions later.
3.2.2.Admissible semantics
Recalling the definition from Section 2, a labeling ℓ is considered admissible if (1) it is a
As the above condition (1) suggests, the attack constraint for an admissible input
However, an
Definition 3.8.
Let
The attack constraints computed via the semantic constraint function
Theorem 3.2.
Let
The semantic constraint function
Example 3.
Let us consider the set of arguments
These conditions represent the input labeling ℓ and impose some restrictions on any argumentation framework that wants to be consistent with the labeling. For the only
The attacks represented by all atoms
3.2.3.Complete semantics
We recall that a labeling ℓ is considered complete if it satisfies the following three conditions:
(1) ℓ is admissible.
(2) if some attacker of a is labeled
(3) if all attackers of a are labeled
The attack constraints for a complete input
Definition 3.9.
Let
The attack constraints computed via the semantic constraint function
Theorem 3.3.
Let
The semantic constraint function
Example 4.
Let us consider the set of arguments
Like before, the only
We have again a few other possible attacks in this example, for instance the argument a can additionally be attacked by itself, b or d while still satisfying the attack constraints.
3.2.4.Stable semantics
A labeling ℓ is considered stable if it is a
Definition 3.10.
Let
The attack constraints computed via the semantic constraint function
Theorem 3.4.
Let
The semantic constraint function
3.2.5.Other semantics
Besides the already mentioned semantics, Dung also introduced the grounded and preferred semantics in his seminal paper [15]. However, for both of these semantics, there exists no semantic constraint function which is sound and complete. The reason for that lies in the minimality and maximality constraints w.r.t. set inclusion for these semantics. The semantic constraint functions are supposed to return local constraints, i.e., a formula in
Proposition 3.2.
There exists no sound and complete semantic constraint function for the grounded semantics.
Proof.
Assume the contrary. Let
Proposition 3.3.
There exists no sound and complete semantic constraint function for the preferred semantics.
Proof.
Assume the contrary. Let
3.3.Algorithm
In the following we will introduce an algorithm for learning argumentation frameworks from labelings. The input of this algorithm is a set of arguments
The main procedure of the algorithm can essentially be split into three parts:
(1) Computing the labeling constraint
(2) Combining the labeling constraint
(3) Constructing the set of argumentation frameworks
Algorithm 1
Iterative algorithm for learning argumentation frameworks from labelings

In each iteration of the algorithm we take a mapping of constraints C, the set of arguments
For the input we compute the attack constraint
In the second step, we combine the labeling constraint
The third and final step is to construct the set of argumentation frameworks
This step is optional, since we only need the mapping of attack constraints C with the updated constraints for each argument for further learning. So, after each learning iteration the algorithm returns the updated set of attack constraints C and (if wanted) the set of constructed argumentation frameworks
Regarding the complexity of constructing argumentation frameworks for a set of attack constraints. We can consider the constraints in clausal form, which follows easily from the definition of the semantic constraint functions. A very helpful property of the attack constraints in clausal form is, that all clauses contain at most one negated literal, i.e., each clause is a dual-horn clause. That means, the process of constructing an argumentation framework for a given set of attack constraints can be considered as a Dual-Horn SAT problem, which is P-complete [14]. Thus, the construction argumentation frameworks can be done in polynomial time, more precisely in linear time with respect to the size of the attack constraints which is in
3.3.1.Properties
In the following we will look at some useful properties that the previously defined algorithm satisfies, namely soundness, completeness and monotonicity.
Theorem 3.5.
Let L be a set of inputs and
The algorithm is sound for all input labelings, i.e.,
The algorithm is complete for all input labelings, i.e.,
As shown in Theorem 3.5 the algorithm based on the above defined attack constraints is sound and complete for any combination of inputs with respect to all four semantics. That means, the algorithm computes exactly the set of argumentation frameworks that are consistent with the input labelings. From the proof of Theorem 3.5 it also follows that the order in which the labelings are processed by the algorithm does not matter.
Proposition 3.4.
Let
Then, the order in which the labelings are learned has no influence on the constructed set of argumentation frameworks
Another property of the algorithm is monotonicity (see Theorem 3.6), or more precisely the algorithm is monotonically refining. That means, if we have a set of labelings
Theorem 3.6.
Let
The algorithm for constructing argumentation frameworks from labelings is monotonically refining, i.e.,
3.4.Example
This section will showcase the application of Algorithm 1. Assume the following situation. Unknown to us, there is the hidden argumentation framework as shown in Fig. 2. Given are only the set of arguments
Fig. 2.
The hidden argumentation framework from which the input labelings are generated.
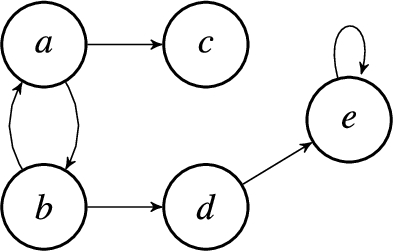
Fig. 3.
The three input labelings:
We start the process of learning with the admissible labeling
After processing the first labeling we know that the argument a must attack b and c. We also know that some attacks cannot exist, but there are still many possibilities for attacks. For example, the argument a can still be attacked by b or c and the resulting frameworks would still be consistent with
Lets consider the next labeling
We now have to combine the constraints C from the last step with the contraints
We have now reduced the number of possibilities even further. The argument a has to be attacked by either b or c and cannot be attacked by any other argument. The arguments b and c have to be attacked by a. They could also be attacked by d, but this attack is optional. d has to be attacked by b or c and optionally can also be attacked by itself or e. Finally, e has to attack itself and can also optionally be attacked by d. One observation we can make is that most of the uncertainty in the attack constraints is related to the argument d as it can still optionally attack b, c, e and itself. The algorithm then returns the updated set of attack constraints C.
The third and last input labeling
Again, we combine the attack constraints
These attack constraints now represent exactly the set of argumentation frameworks that are consistent with all three input labelings. The final step of the algorithm is now to construct these argumentation frameworks. Here, we use the fact that the atoms used in the attack constraints directly correspond to attacks in an argumentation framework, as described in Definition 3.3. First, we compute the models of the attack constraints of each argument:
The next step is constructing the corresponding partial attack relations for each model with the method
Here, we can see that b, c and e only have one partial attack relation while a has 3 and the argument d has 6 corresponding partial attack relations. That means, overall we will have
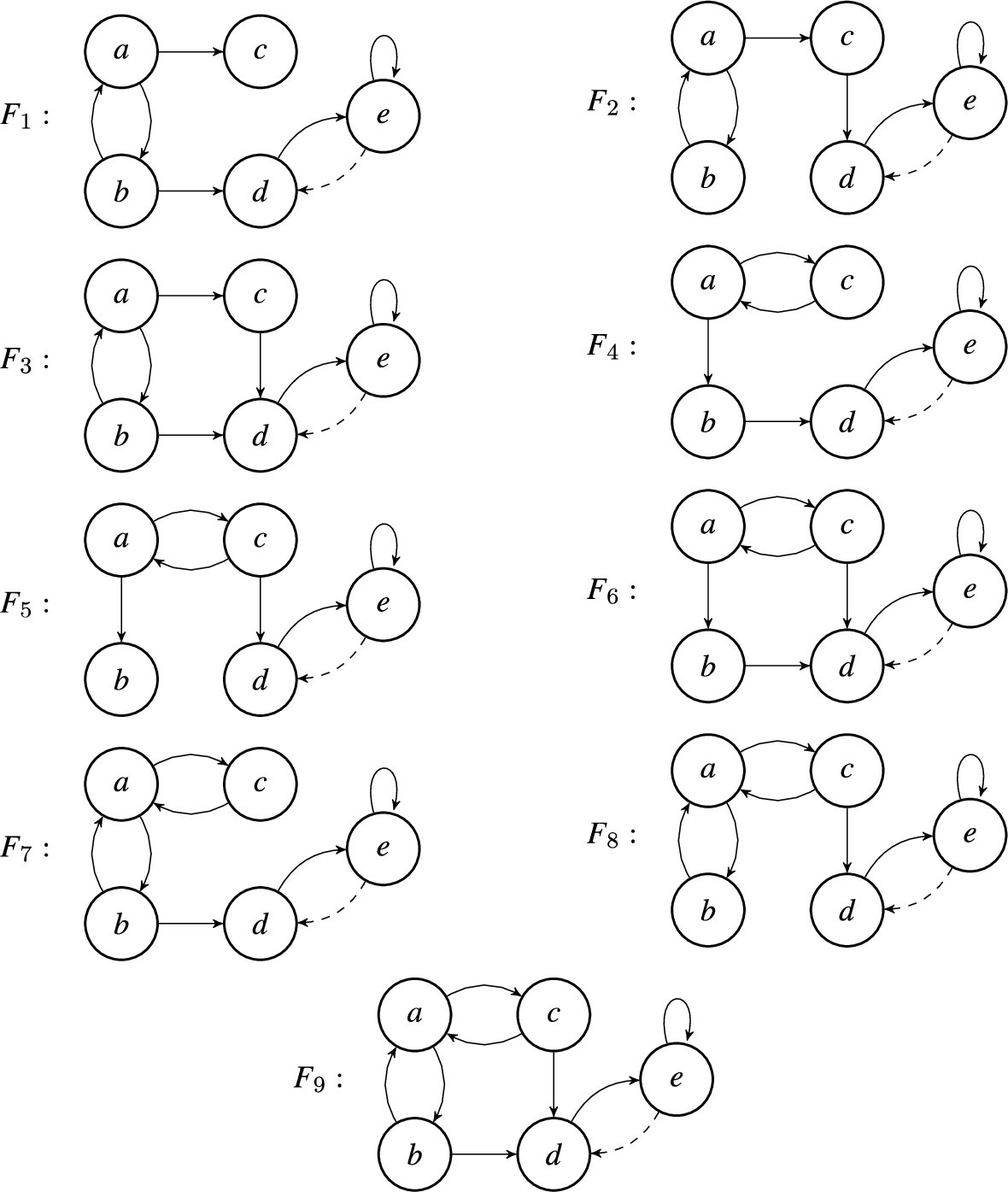
All constructed argumentation frameworks are shown in Fig. 4. In the figure, each framework
Fig. 4.
All 18 constructed argumentation frameworks which are consistent with the labelings
4.Experiments
In this section we will conduct an experimental feasibility study of the approach introduced in Section 3. For that, we will consider both a naive implementation of the algorithm, as well as an optimized implementation with parallelized learning and construction steps. For the evaluation we will measure the performance of the algorithm, i.e., the time the algorithm takes to learn the input labelings and the time for constructing an argumentation framework that satisfies the learned constraints.
We will look at two different scenarios for our experiments. In the first scenario, we will use argumentation frameworks generated with the AFBenchGen2 generators [10] in order to measure how the algorithm’s performance scales with the number of arguments. In the second scenario, we will use the benchmark argumentation frameworks from the ICCMA’19 competition [6] to measure the performance of the algorithm in a more realistic application scenario.
In the following, we briefly describe the system, both implementations and the two main metrics used for the evaluation.
System setup. The experiments were run on a machine with the Ubuntu 20.04 operating system. The machine has a 3.4 GHz Intel Xeon E5-2643v3 CPU with 12 cores and 24 threads and a total of 192 GB DDR4 memory.
Implementation. The implementation11 has been done in Java as part of the TweetyProject library [26]. For the computation of the models of the attack constraints, needed for the construction of argumentation frameworks in the final step of the algorithm, the Java-based SAT-solver Sat4j22 is used. In the naive version, all computations are done sequentially. On the other hand, in the optimized implementation, the learning of a labeling is done in parallel, i.e., the computation of the attack constraints for each argument. In addition to that, the computation of models of the constraints in the construction step is also done in parallel.
Metrics. In the following we define some questions that we want to answer with the experiments. Each question has a corresponding metric that will be investigated in order to answer it:
(1) How does the time to learn a single input labeling scale with the number of arguments?
The goal of this question is measuring how the algorithm’s performance scales with the number of arguments that are considered. In order to do that, we consider the time
(2) How much time does it take to construct an argumentation framework that is consistent with all input labelings?
For this question we measure the time
(3) How close is the constructed argumentation framework to the original argumentation framework?
For that, we compare the attack relation of the constructed argumentation framework
Essentially, this will give us some insight on how many uncertainty is still left after learning the input labelings. If the constructed argumentation framework is very far from the original one, i.e.,
4.1.Experiment 1: AFBenchGen2
The main goal of our first experiment is to investigate how our algorithm scales with the number of arguments. In particular, we are interested in how the parallelization affects the performance.
For this experiment, we generated a total of 1200 argumentation frameworks
4.1.1.Results
Fig. 5.
Learning time per labeling and construction time in relation to the number of arguments for the AFs generated via AFBenchGen2.
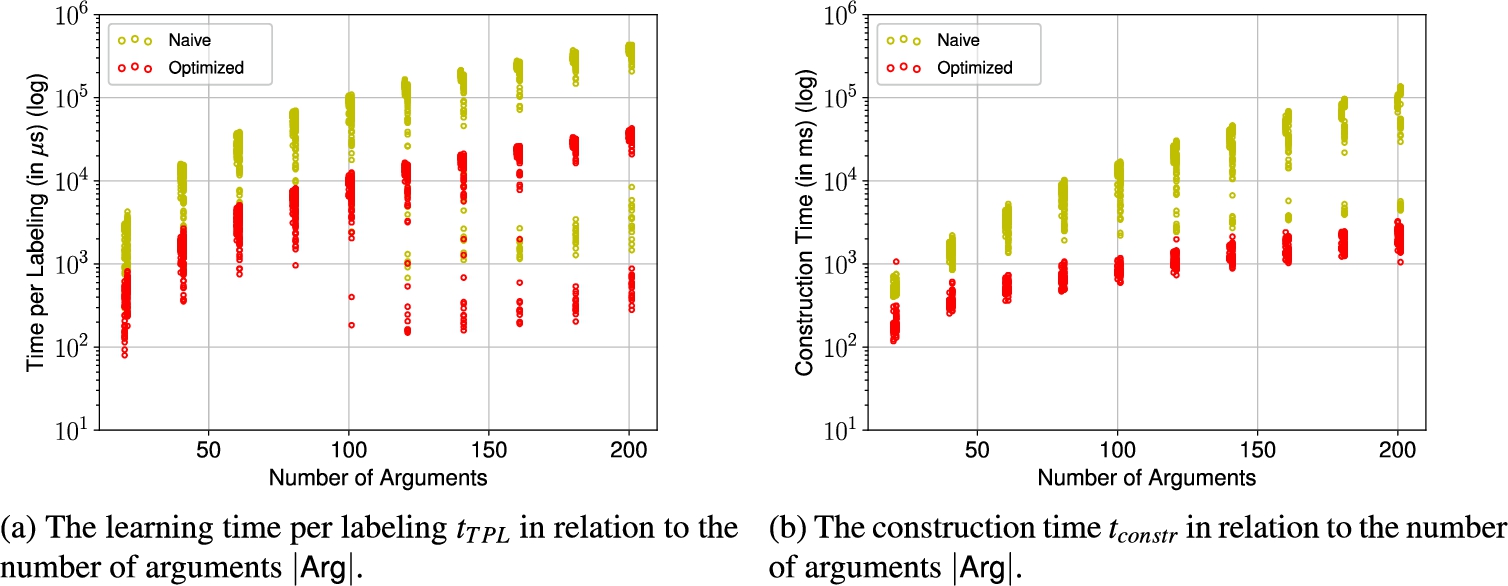
Let us first consider the median learning time per labeling
On the other hand, in the optimized implementation the median time per labeling ranges from 477 μs at 20 arguments to only 35 ms at 200 arguments, which is an increase by a factor of 73. That also means, for the smaller instances the parallelization reduces the computing time by approx. 77% and for the largest instances with 200 arguments by over 90%.
For the instances with 120 or more arguments we can observe outliers with significantly lower learning times per labeling. In these cases the argumentation frameworks had only very few labelings and thus less than the intended 1000 labelings were learned. This suggest that there is a positive correlation between the number of learned labelings and the time per labeling
Fig. 6.
The total learning time
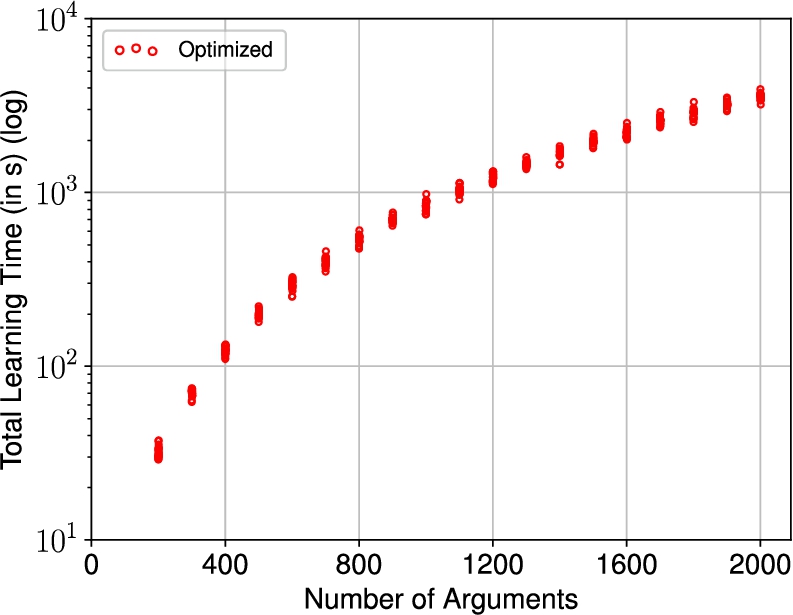
To ensure the observed scaling of the algorithm is accurate and not due to hardware, we consider larger and thus harder instances with up to 2000 arguments, generated in a similar fashion. The results for the total learning time
We now look at the time it takes to construct an argumentation framework that is consistent with the attack constraints of the learned labelings. This includes computing a model for the attack constraint of each argument as well as converting these models to an attack relation. The time
Regarding the difference between original and learned argumentation framework we can observe the following. On average, less than 2% of the possible attacks were different for the instances in this experiment with a standard deviation of 0.01. The biggest difference was only 5.67%. In general, we can observe that the learned argumentation frameworks contained about 55% less attacks than the original one. This is to be expected, since in our scenario we are interested in the argumentation frameworks that produce at least the input labelings. That means, we explicitly allow other labelings to exist in the learned framework. This allows for a less restrictive attack relation, leading to fewer attacks being necessary to represent the labelings.
Overall, we can say that the paralellization is very effective in reducing the computation time for both processing a labeling as well as constructing a consistent argumentation framework in this artificial scenario. It is however more effective in the construction step than in the learning step.
4.2.Experiment 2: ICCMA’19
In the second experiment we will learn argumentation frameworks on the basis of some more realistic data in order to get an idea of the general performance of our algorithm. For that, we will use the argumentation frameworks from the ICCMA’19 competition [6]. In this experiment we consider only admissible, complete and stable labelings. It would not be feasible to construct all argumentation frameworks since there may be millions of frameworks that may be consistent with the input labelings, thus we only construct one argumentation framework that satisfies the attack constraints.
From the benchmark set, we consider all argumentation frameworks that have less than 1,000 arguments. Thus, we have 276 argumentation frameworks with the number of arguments ranging from 4 to 1,000. For each argumentation framework, we compute the inputs
4.2.1.Results
In the following, the results of the first experiment are summarized and we look at each of the above defined questions and metrics.
Fig. 7.
Learning time per labeling and construction time in relation to the number of arguments in the experiment with the ICCMA’19 instances.
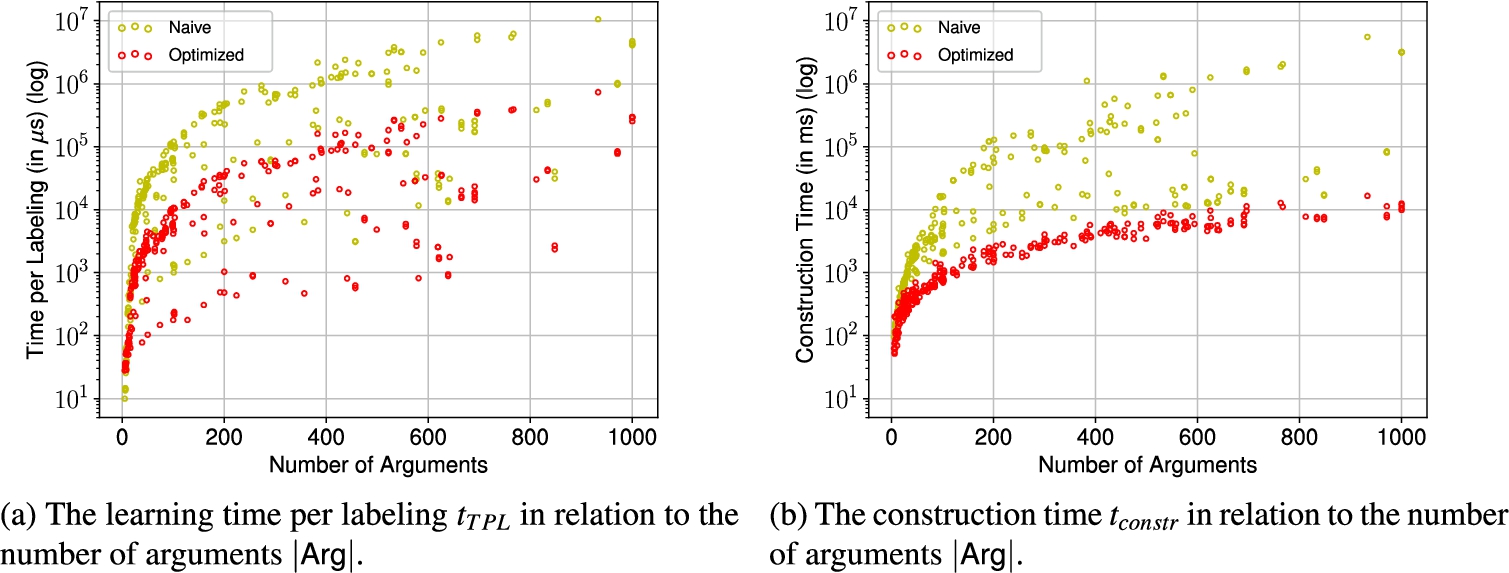
We consider again the time per labeling
For the naive version, the time per labeling ranges from 10 μs to 10.6 s with a median of 42.25 ms per labeling. On the other hand the time per labeling ranges from 28 μs to 733 ms with a median of 3.82 ms per labeling for the optimized implementation.
On average, the optimization brings a decrease in computation time by a factor of about 10. The higher the number of arguments the higher the performance improvement. For the smallest instances with less than 10 arguments the naive implementation actually performs better. This is likely due to some computational overhead of the parallelization, but already for instances with 10 or more arguments the optimized implementation consistently and significantly outperforms the naive version.
One observation we can make for both implementations is that there are some instances for which the time per labeling is significantly lower compared to other instances of similar size. Like in the previous experiment, these are instances where less than the intended 1000 labelings have been processed (simply due to the fact that there where not enough labelings for those instances). This is likely due to the fact, that with a growing number of input labelings the attack constraints get more complex and thus it takes longer to check satisfiability.
We now consider the construction times
Fig. 8.
The frequency distribution of the normalized number of different attacks
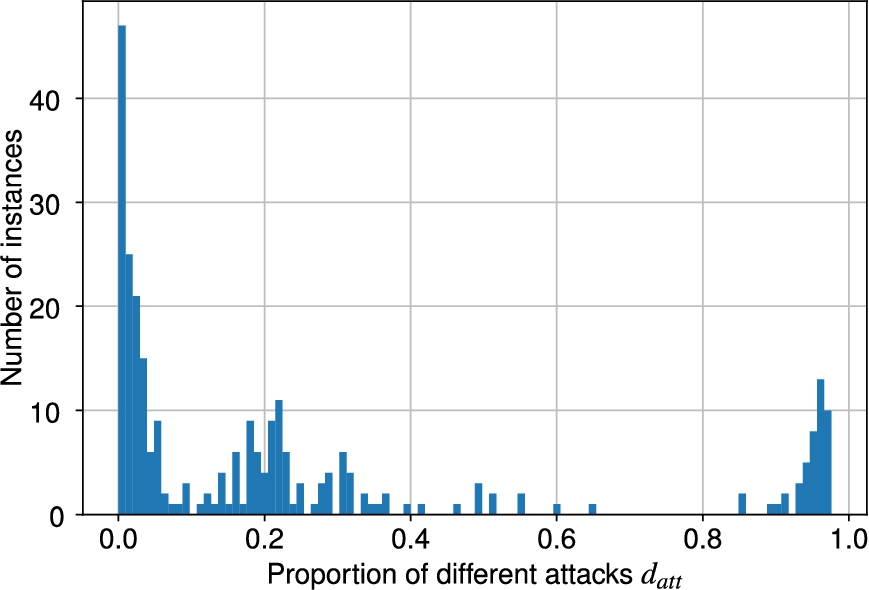
Finally, Fig. 8 shows the distribution of the normalized number of different attacks
Overall, this experiment on the ICCMA’19 dataset has confirmed the observation from the first experiment. Our findings suggest a time complexity within
5.Discussion
In the previous sections we have introduced and discussed an algorithm for learning a set of argumentation frameworks from a given set of labelings. This algorithm computes a set of attack constraints for each labeling. These constraints represent the acceptability of each argument with regards to the labeling. Afterwards they are combined into a single attack constraint per argument. This set of attack constraints then represents all input labelings and can then be used to construct the argumentation frameworks that are consistent with the input labelings.
In this section we will take a closer look at our algorithm and discuss its strengths and weaknesses. Furthermore, we will discuss some existing algorithms from Riveret et al. [25] and Niskanen et al. [23] and the recent work of Mumford et al. [22] on the computational complexity of the AF learning problem.
We will first discuss some key advantages that distinguish our algorithm proposed in this work from the existing algorithms. One key point is the structure of the algorithms. Our algorithm works in an iterative way and can be applied on a stream of input labelings similarly to the algorithm of Riveret et al. [25]. This is an important difference to the algorithm of Niskanen et al. [23] which only works with a set of input extensions. An iterative approach means we are able to get intermediate results after each processed input labeling. It also means that we are able to refine our result at any point by learning more labelings. This would not be possible in the algorithm of Niskanen et al. [23] where we would have to start over and learn all labelings again. The iterative approach also allows us to choose the order in which the labelings are processed. This means we can add an additional layer to the algorithm by deciding which labeling to learn next based on the current status (i.e., the last intermediate result).
Another important difference is related to the conditions that are used to encode the labelings. The algorithm of Niskanen et al. [23] also uses conditions based on the input, however there is an important difference: these conditions model one extension as a whole. So, using the terminology introduced in Section 3, these conditions are formulae over the set
The most important advantage of our algorithm compared to those of Riveret et al. and Niskanen et al. is the following: Our algorithm maintains a representation of all argumentation frameworks that are consistent with the input labelings while both other algorithms simply return one fitting argumentation framework. The algorithm of Riveret et al. [25] only maintains one representation of a weighted argumentation framework internally and returns this at the end. On the other hand, the algorithm of Niskanen et al. [23] computes one condition per labeling and as a result returns just one model that represent an argumentation framework. Our algorithm preserves all of the information that is given to it via the input labelings. This is done by translating the input labelings into a set of attack constraints and then combining and simplifying them. So, internally the algorithm only stores one set of mutually independent attack constraints that represent the set of argumentation frameworks. This approach enables us to incorporate additional input labelings at any point and refine the set of argumentation frameworks further. It also ensures that we do not discard any correct argumentation framework during the learning process, something that can happen in both the algorithms of Riveret et al. [25] and Niskanen et al. [23]. It should be mentioned however, that the algorithm of Niskanen et al. [23] can be modified to also return all consistent argumentation frameworks.
We will now look at some other minor differences between all three algorithms. The input of our algorithm is a set of arguments and a set of input labelings. That means, we assume that all arguments of the hidden framework are known. The same assumption is also made by both other algorithms. The second part of the input is the set of input labelings. In the iterative version this can also be a stream of input labelings, similarly to the algorithm of Riveret et al. [25]. This is a different approach compared to the algorithm of Niskanen et al. [23], which uses positive and negative examples in the form of extensions.
Furthermore, all approaches differ in the semantics that are accepted for the input. The algorithm of Riveret et al. [25] only allows grounded labelings as input, while the algorithm of Niskanen et al. [23] accepts conflict-free, admissible, complete, stable, grounded and preferred extensions. Our algorithm accepts conflict-free, admissible, complete and stable labelings. While the algorithm covers many semantics, it does not support grounded and preferred semantics. The reason for that is related to the definition of these semantics. The grounded labeling is defined as the minimal complete labeling and the preferred labelings are maximally complete. These constraints cannot be encoded in the attack constraints and thus it is not possible to learn these labelings with our algorithm, as already discussed in Section 3.2.5. The same applies to some other semantics proposed in the literature, such as semi-stable [7] which maximizes the attacked arguments of an extension. Similarly, the naive semantics and the semantics based on it, like CF2 [5], work with maximal conflict-free sets and thus cannot be modeled by the algorithm in its current form. However, it might be possible to address these issues by extending the algorithm with some form of global conditions. One possibility would be to use conditions similar to those used by Niskanen et al. [23] for modeling the grounded and preferred extensions and adjust them for the respective labelings. It should be mentioned, that this would of course weaken the advantages of our local constraints.
The algorithm of Riveret et al. [25] uses grounded sub-framework labelings as input. This considerably eases the task of learning from labelings since we can just consider all sub-frameworks with just two arguments and take the grounded labeling of these as input. Our algorithm does not rely on such labelings and is able to reconstruct argumentation frameworks from standard labelings.
Argumentation frameworks may contain self-attacking arguments. The algorithm of Riveret et al. [25] does have problems with such argumentation frameworks and there are cases where this algorithm is not able to reconstruct the hidden argumentation framework if there are self-attacking arguments. Our algorithm does not have any problems in that case and is able to work with self-attacking arguments.
Finally, we will also discuss some weaknesses of our algorithm compared to the existing work. The fact that our algorithm requires labelings instead of extensions as input can be considered a weakness. Labelings are more specific than extensions and hold more information about the argumentation framework that produced them. They make a distinction between directly rejected (out) and indirectly rejected (undecided) arguments. Without this distinction it would not be possible to compute the attack constraints in their current form. This is something that can potentially be worked on in the future.
Another observation regarding the input of the algorithm can be made. Our algorithm cannot handle input noise, i.e., some ‘wrong’ labelings that are not actually produced by the hidden argumentation framework. This is something that the algorithms of Riveret et al. [25] and Niskanen et al. [23] are able to handle. The algorithm of Riveret et al. [25] does this by using an internal weighted argumentation framework. This leaves more room to handle inconsistent input but might also lead to returning an argumentation framework which is not consistent with all of the correct input labelings. The algorithm of Niskanen et al. [23] uses weighted MaxSAT encodings for the input extensions. This allows them so find the argumentation framework which is consistent with the highest number of input extensions even if there are some noisy inputs. It might be possible to apply a similar concept to our attack constraints which is also something that can be tackled in the future. Alternatively, we could consider some paraconsistent logic [24] to interpret the attack constraints instead of the classical propositional logic.
The recent work of Mumford et al. [22] investigates the computational complexity of learning argumentation framework both from labelings and extensions. They focus on the complete semantics, but also consider grounded, preferred and stable semantics. Their results show that learning argumentation frameworks from extensions is NP-complete while learning from labelings is solvable in polynomial time. More specifically, they present an algorithm for constructing one consistent argumentation framework from labelings with a time complexity in
A final related work worthwhile to mention is [2], where an approach is presented that incrementally computes extensions when changes on the initial argumentation framework are observed, such as adding an attack. The problem faced in this work is somewhat orthogonal to ours, since we consider the argumentation framework to be unknown but fixed, and we process extensions (or more precisely labelings) incrementally.
6.Conclusion
We investigated the AF learning scenario, where we want to reconstruct argumentation frameworks from given labelings. The goal in this scenario is to find all argumentation frameworks that are consistent with at least all input labelings. To address this problem, we introduced a novel algorithm that iteratively processes labelings and translated them to attack constraints for each argument. These attack constraints are mutually independent and together they represent the set of all consistent argumentation frameworks. The independence of these constraints allows us to parallelize both the learning and construction part of the algorithm. Our experiments showed that this leads to a significant increase in performance. In particular, for the ICCMA’19 dataset the learning time has been improved by a factor of 10 while the construction time showed an even greater improvement with it being over 22 times faster. We also highlighted some of the key advantages of our approach compared to other similar existing approaches. These advantages are, among others, the ability to fully parallelize all computations and the fact that the attack constraints maintain a representation of all consistent argumentation frameworks at all times.
For future work, there are several possibilities. One such possibility is extending our algorithm to other AF-based formalisms, such as bipolar argumentation frameworks [9] or attack-support argumentation frameworks [11]. For these frameworks, there also exist acceptability semantics from whose labelings we can learn the respective frameworks. In particular, instances of these formalisms can be transformed into semantically equivalent meta argumentation frameworks [3]. That means, one only needs to deal with the meta arguments that are created by this transformation.
Another direction is to extend the capabilities of our algorithm. This could be done by defining semantic constraint functions for other semantics, e.g., for the strong admissible semantics [4]. We are however not limited to specific semantics. Alternatively, we can define semantic constraint functions for other concepts from the literature such as credulous or skeptical acceptance with respect to some semantics σ or properties like unattackedness. Another possibility would be to adapt the algorithm to be able to process negative examples, like the algorithm of Niskanen et al. [23]. It would also be interesting to convert the algorithm to a extension-based approach, if possible. One weakness of our approach is the inability to deal with noisy input. As already mentioned in Section 5, this could for example be addressed by using some paraconsistent logic [24].
Furthermore, it would also be interesting to consider a scenario where we can only obtain incomplete information in the form of a partial labeling wrt. some semantics where some of the arguments have no specified label. For a scenario like that, we would have to explore under which circumstances it is possible to recover information about the framework from the partial labeling and adapt the semantic constraint functions accordingly.
Another interesting thing to explore would be the relationship of the number of learned labelings and the difference between attacks in the hidden and the constructed argumentation framework. Meaning, we look at how many labelings we would need to learn in order to obtain construct exactly the hidden argumentation framework or some framework with at most k different attacks.
Finally, another interesting direction would be to make the scenario of learning argumentation frameworks from labelings more interactive, similar to the scenario of eliciting argumentation frameworks [19]. In that scenario the goal is to elicit a hidden argumentation framework from an entity by asking questions about the extensions of this framework. In our scenario, we could also include user input to control which labeling to learn next. This can then be used to steer the learning process to learn more “effectively”, i.e., by choosing labelings that shrink the set of consistent argumentation frameworks the most.
Appendices
Appendix
AppendixProofs
Theorem 3.1.
Let
The semantic constraint function is sound for conflict-free input labelings ℓ, i.e.,
Proof of Theorem 3.1 (Soundness).
Let
We will proof by contradiction that the set of argumentation frameworks
Assume there exists an argumentation framework
(1) There is an attack between two
(2) There is an
(3) There is an
Case 1: There is an attack between two
The algorithm constructs the argumentation frameworks based on the models of the attack constraints. We consider any argument
Case 2: There is an
That means, there exists an argument
Case 3: There is an
That means, there exists an argument
All in all, it follows that every
Proof of Theorem 3.1 (Completeness).
Let
We will proof by contradiction that the algorithm is complete for conflict-free labelings, i.e., for every argumentation framework F it holds that, if F is consistent with ℓ then
Assume there exists an argumentation framework
Then, according to Definition 2.3 the following three conditions hold for all arguments
(1) If
(2) If
(3) If
According to the first condition, there can be no attack between any
Furthermore, every
The third condition states that an
It follows that, if the argumentation framework F is consistent with the conflict-free labeling ℓ it also satisfies the attack constraints for all arguments as defined in Definition 3.7. Thus, it holds for all conflict-free labelings that, if F is consistent with ℓ, then
Theorem 3.2.
Let
The semantic constraint function
Proof of Theorem 3.2 (Soundness).
Let
We will proof by contradiction that the set of argumentation frameworks
Assume there exists an argumentation framework
(1) There is an attack between two
(2) There is an
(3) There is an
(4) There is an
Cases 1–3 are the same as for the conflict-free semantics. So, we only have to consider case 4 here.
Case 4: There is an
To summarize, it follows that every
Proof of Theorem 3.2 (Completeness).
Let
We proof by contradiction that the algorithm is complete for admissible labelings, i.e., for every argumentation framework F it holds that, if F is consistent with ℓ then
Assume there exists an argumentation framework
Then, according to Definition 2.4 the following three conditions hold for all arguments
(1) If
(2) If
(3) If
Conditions 2 and 3 are the same as for conflict-free semantics. So, we only have to proof that the first condition also holds in F.
According to the first condition, any
This is exactly what the first condition states and thus F must also satisfy the attack constraint
It follows that, if the argumentation framework F is consistent with the admissible labeling ℓ it also satisfies the attack constraints for all arguments as defined in Definition 3.8. Thus, it holds for all admissible labelings that, if F is consistent with ℓ, then
Theorem 3.3.
Let
The semantic constraint function
Proof of Theorem 3.3 (Soundness).
Let
The proof of the soundness of the algorithm for complete input labelings is similar to the proof for admissible input labelings. The only difference is that we have to consider an additional fifth possibility for the case distinction:
(5) There is an argument
Cases 1–4 have been shown in the proofs for conflict-free and admissible semantics.
Case 5: There is an argument
Assume
Assume
It follows, there is no argument
Proof of Theorem 3.3 (Completeness).
Let
We proof that the algorithm is complete for complete input labelings, i.e., for every argumentation framework F it holds that, if F is consistent with ℓ then
Assume there exists an argumentation framework
Then, according to Definition 2.5 the following four conditions hold for all arguments
(1) If
(2) If
(3) If
(4) If
As shown in the proof for admissible and conflict-free labelings, from the conditions for
As shown in the proof for admissible labelings from the third condition it follows that F satisfies the admissible attack constraint
It follows that, if the argumentation framework F is consistent with the complete labeling ℓ it also satisfies the attack constraints for all arguments. Thus, it holds for all complete labelings that, if F is consistent with ℓ, then
Theorem 3.4.
Let
The semantic constraint function
Proof of Theorem 3.4 (Soundness).
Let
We proof by contradiction that the attack constraints and thus the algorithm are sound for stable input labelings. Assume there exists an argumentation framework
(1) There is an attack between two
(2) There is an
(3) There is an argument a which is not labeled
Cases 1 and 2 are the same as for the conflict-free semantics. So, we will only look at the third case here.
Case 3: There is an argument a which is not labeled
For the second case with the attack constraint
To summarize, there can be no
Proof of Theorem 3.4 (Completeness).
Let
We proof that the algorithm is complete for stable input labelings ℓ, i.e., for every argumentation framework F it holds that, if F is consistent with ℓ then
Assume there exists an argumentation framework
Then, according to Definition 2.6 the following two conditions hold for all arguments
(1) If
(2) If
This proof is rather trivial. From the proofs for conflict-free and admissible semantics we know that any F that satisfies the above conditions for
That means, if the argumentation framework F is consistent with the stable labeling ℓ it also satisfies the attack constraints for all arguments as defined in Definition 3.10. Thus, it holds for all stable labelings that, if F is consistent with ℓ, then
Theorem 3.6.
Let
The algorithm for constructing argumentation frameworks from labelings is monotonically refining, i.e.,
Theorem 3.5.
Let L be a set of inputs and
The algorithm is sound for all input labelings, i.e.,
The algorithm is complete for all input labelings, i.e.,
Proof of Theorem 3.5.
It follows from Theorems 3.1, 3.2, 3.3 and 3.4 that the attack constraints are sound and complete for labelings with respect to conflict-free, admissible, complete and stable semantics. We need to prove that a set of attack constraints, and thus Algorithm 1, is sound and complete for any combination of input labelings with respect to different semantics. This follows from the fact that combining the attack constraints of each labeling is done by conjunction as shown below:
Let L be a set of inputs and
Consider two inputs
Proof of Theorem 3.6 (Monotonicity).
Let
We proof that the algorithm defined in Section 3.3 is monotonically refining. Consider any argument a. Per definition the attack constraint for a with respect to
From that we can easily see: it holds for every argument
Thus, we have shown for all sets of labelings
References
[1] | A. Adadi and M. Berrada, Peeking inside the black-box: A survey on explainable artificial intelligence (XAI), IEEE access 6: ((2018) ), 52138–52160. doi:10.1109/ACCESS.2018.2870052. |
[2] | G. Alfano, A. Cohen, S. Gottifredi, S. Greco, F. Parisi and G. Simari, Dynamics in abstract argumentation frameworks with recursive attack and support relations, in: Proceedings of the 24th European Conference on Artificial Intelligence (ECAI’20), (2020) . |
[3] | G. Alfano, S. Greco, F. Parisi and I. Trubitsyna, On the semantics of abstract argumentation frameworks: A logic programming approach, Theory and Practice of Logic Programming 20: (5) ((2020) ), 703–718. doi:10.1017/S1471068420000253. |
[4] | P. Baroni, M. Caminada and M. Giacomin, Abstract argumentation frameworks and their semantics, Handbook of formal argumentation 1: ((2018) ), 157–234. |
[5] | P. Baroni and M. Giacomin, Solving semantic problems with odd-length cycles in argumentation, in: European Conference on Symbolic and Quantitative Approaches to Reasoning and Uncertainty, Springer, (2003) , pp. 440–451. |
[6] | S. Bistarelli, L. Kotthoff, F. Santini and C. Taticchi, A first overview of ICCMA’19, in: AI3@ AI*IA, (2020) , pp. 90–102. |
[7] | M. Caminada, Semi-stable semantics, COMMA 144: ((2006) ), 121–130. |
[8] | M.W. Caminada and D.M. Gabbay, A logical account of formal argumentation, Studia Logica 93: (2) ((2009) ), 109–145. doi:10.1007/s11225-009-9218-x. |
[9] | C. Cayrol and M.-C. Lagasquie-Schiex, On the acceptability of arguments in bipolar argumentation frameworks, in: Symbolic and Quantitative Approaches to Reasoning with Uncertainty: 8th European Conference, ECSQARU 2005, Proceedings 8, Barcelona, Spain, July 6–8, 2005, Springer, (2005) , pp. 378–389. |
[10] | F. Cerutti, M. Giacomin and M. Vallati, Generating structured argumentation frameworks: AFBenchGen2, in: COMMA, (2016) , pp. 467–468. |
[11] | A. Cohen, S. Gottifredi, A.J. García and G.R. Simari, An approach to abstract argumentation with recursive attack and support, Journal of Applied Logic 13: (4) ((2015) ), 509–533. doi:10.1016/j.jal.2014.12.001. |
[12] | K. Čyras, A. Rago, E. Albini, P. Baroni and F. Toni, Argumentative XAI: a survey, 2021, arXiv preprint arXiv:2105.11266. |
[13] | L.M. de Campos and J.G. Castellano, Bayesian network learning algorithms using structural restrictions, International Journal of Approximate Reasoning 45: (2) ((2007) ), 233–254. doi:10.1016/j.ijar.2006.06.009. |
[14] | W.F. Dowling and J.H. Gallier, Linear-time algorithms for testing the satisfiability of propositional Horn formulae, The Journal of Logic Programming 1: (3) ((1984) ), 267–284. doi:10.1016/0743-1066(84)90014-1. |
[15] | P.M. Dung, On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games, Artificial intelligence 77: (2) ((1995) ), 321–357. doi:10.1016/0004-3702(94)00041-X. |
[16] | X. Fan and F. Toni, On computing explanations in argumentation, in: Twenty-Ninth AAAI Conference on Artificial Intelligence, (2015) . |
[17] | H. Jakobovits and D. Vermeir, Robust semantics for argumentation frameworks, in: Journal of Logic and Computation, Vol. 9: , OUP, (1999) , pp. 215–261. |
[18] | H. Kido and B. Liao, A Bayesian approach to direct and inverse abstract argumentation problems, 2019, arXiv preprint arXiv:1909.04319. |
[19] | I. Kuhlmann, Towards eliciting attacks in abstract argumentation frameworks, Online handbook of argumentation for AI 2021, 27. |
[20] | J. Lawrence and C. Reed, Argument mining: A survey, Computational Linguistics 45: (4) ((2020) ), 765–818. doi:10.1162/coli_a_00364. |
[21] | S. Muggleton, Inductive logic programming, New generation computing 8: (4) ((1991) ), 295–318. doi:10.1007/BF03037089. |
[22] | J. Mumford, I. Sassoon, E. Black and S. Parsons, On the complexity of determining defeat relations consistent with abstract argumentation semantics, in: Proceedings of COMMA 2022: 9th International Conference on Computational Models of Argument, IOS Press, (2022) . |
[23] | A. Niskanen, J. Wallner and M. Järvisalo, Synthesizing argumentation frameworks from examples, Journal of Artificial Intelligence Research 66: ((2019) ), 503–554. doi:10.1613/jair.1.11758. |
[24] | G. Priest, Paraconsistent logic, in: Handbook of Philosophical Logic, Springer, (2002) , pp. 287–393. doi:10.1007/978-94-017-0460-1_4. |
[25] | R. Riveret and G. Governatori, On learning attacks in probabilistic abstract argumentation, in: Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, (2016) , pp. 653–661. |
[26] | M. Thimm, Tweety – a comprehensive collection of Java libraries for logical aspects of artificial intelligence and knowledge representation, in: Proceedings of the 14th International Conference on Principles of Knowledge Representation and Reasoning (KR’14), (2014) . |
[27] | M. Ulbricht and J.P. Wallner, Strong explanations in abstract argumentation, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35: , (2021) , pp. 6496–6504. |


