
Computational opposition analysis using word embeddings: A method for strategising resonant informal argument
Abstract
In informal argument, an essential step is to ask what will “resonate” with a particular audience and hence persuade. Marketers, for example, may recommend a certain colour for a new soda can because it “pops” on Instagram; politicians may “fine-tune” diction for different social demographics. This paper engages the need to strategise for such resonance by offering a method for automating opposition analysis (OA), a technique from semiotics used in marketing and literary analysis to plot objects of interest on oppositional axes. Central to our computational approach is a reframing of texts as proxies for thought and opposition as the product of oscillation in thought in response to those proxies, a model to which the contextual similarity information contained in word embeddings is relevant. We illustrate our approach with an analysis of texts on gun control from ProCon.org, implementing a three-step method to: 1) identify relatively prominent signifiers; 2) rank possible opposition pairs on prominence and contextual similarity scores; and 3) derive plot values for proxies on opposition pair axes. The results are discussed in terms of strategies for informal argument that might be derived by those on each side of gun control.
1.Introduction
Our fascination with networked computers exposes us daily to hundreds if not thousands of informal arguments that seek to influence our behaviour. A diverse class of professionals – from advertising creatives to online influencers – strategise these persuasions for their livelihood. Their task until recent years has been predominantly qualitative, focused on optimising a message that will be somewhat predictably received. Increasingly, however, quantitative factors are becoming important. Online, successful persuasion is as much about competing for attention as about crafting message content, with one often complementing or constraining the other in ways that go far beyond “argument flags” into the structure of the argument itself. Consider, for example, these typical contemporary “marketplace argumentation” [2] scenarios:
A brand consultant ponders the best colour for a client’s new soda can
A prospective author models gaps in the activity book market for pre-teens
An artistic director tries to predict which Shakespeare play will attract the biggest crowds in July
A programmatic marketer seeks to maximise click-through based on the context in which a banner advertisement appears
A blogger vacillates between a post about housing costs and another about a royal wedding
A sociologist wonders if their article is more likely to be accepted by a British or American journal
A politician wants to know how to best appeal to those on the opposing side of gun control by analysing Twitter data
Natural language processing (NLP) provides tools that may assist in such tasks ad hoc by modelling lexical choices and classifying them in terms of relevance, topic, or sentiment, or in specialised components for systems for argument finding and invention [41] or automated persuasion [16,17]. The process of selecting soda can colours, for example, might be aided by analysing social media posts as an exercise in audience analysis. The analysis might uncover associations and sentiment around shades of red, blue, green, purple and so on, which could be used to design a can that appeals to a target market. The effect sought is not an immediate, conscious response but rather a type of “semantic priming” [22,24] – preparing the consumer to be convinced by a broader, integrated informal argument as to why the can should be preferred. A patriotic slogan in the United States and Britain, for example, is often paired with red, white and blue packaging. Indeed, Pepsi uses these colours for its soda cans.
As we know, however, many such marketplace argumentation projects fall flat, even when enormous amounts of data and millions of dollars are involved. The New Coke debacle of the 1980s is a famous example. It remains a major challenge to anticipate which future arguments will win attention or “resonate” with a certain community of consumers, influencers or voters. One reason is that such tasks are not only procedural but also creative. In such endeavours, the past represents a status quo to be disrupted rather than imitated (or even much extrapolated). Under pressure to compete for attention, it is sometimes more important to present unexpected modulations in one’s message that coax attention along desired trajectories than to build arguments on truisms that are easily ignored. An unexpected or offbeat word, metaphor, argument scheme, or even outright non sequitur can be powerful if it draws the attention of an audience. Continuing the soda can example: the optimal design may be another patriotic iteration of red, white and blue. But it may also be some reaction against it: pink with white letters spelling out “TaB”. The requirement for recognising such opportunities, of course, is to be aware of the current, often unrecognised, norms in one’s particular argument field – what Toulmin called field-dependent aspects [39].
While computation currently aids in areas such as sentiment analysis and argument mining, which can be matched with argument schemes for argument invention, we assert that some broader aspects of persuasion remain unrecognised. These cross into the domain of semiotics, a transdisciplinary field that informs a diverse cadre of academic and commercial practitioners from literary studies to the marketing and branding sectors [21,27,28,35].
1.1.Semiotics
Semiotics, often simply defined as the study of signs, has a long history dating back to antiquity. The Hippocratic tradition, for example, used the term σηµειον (“semeion” from which the term semiotics derives) to refer to signs in medical diagnosis – what we now call “symptoms”. Signs also have a place in the earliest history of argumentation. Aristotle used the term semeion, writing that the materials of enthymemes are “probabilities and signs” and that the syllogism is valid only for “necessary signs”. (Rhetoric, I, ii) [3].
Semiotics in the modern era derives largely from the work of two theorists: Ferdinand de Saussure, the Swiss linguist and instigator of structuralism; and Charles Sanders Peirce, the American polymath known as the father of pragmatism. While Saussure’s formality provides the bridge from linguistics to general sign analysis, Peirce is particularly relevant to the approach taken in this paper because he placed at the core of his inquiry the assertion that “all thought is in signs” [30, Vol. V, par. 254]. As a point of departure, Peirce’s ontology allows argument, and even argument schemes, to be viewed as evolving patterns of thought rather than fixed psychological capabilities. The mind from a Peircean perspective is something fallible that will resonate to its benefit or peril with its environment.
Marshall McLuhan, in his pioneering work on the semiotics of new media, expanded on Peirce. He urged us to pay attention to what modulates in our environments in order to understand what is happening in patterns of thought. A central tool for this effort in McLuhan’s later work was that of “figure” and “ground”. Borrowing from gestalt psychology, McLuhan maintained that we attribute our thoughts to only a few artefacts (the figure) while many others to which we have not paid attention are just as determinative (the ground). Hence, in his famous title, the medium (to which we rarely pay attention) is actually the message. In the case of informal argument, we theorise that subtle differences in the ground (typically words) unite and polarise allies and opponents on an issue, and that the figure of enthymemic or inferential structure that we retrospectively attribute – or to use Woods’ term “dress” [42] – sits upon this.
The most obvious use of ground modulation in persuasion is the tendentious choice of words, which was given explicit consideration by Aristotle:
Such modulation may have once been a minor rhetorical consideration. However, the rise in quantity and intensity of sign presentation the internet has made possible, and the processing pressure it puts us under, has unmasked – some might say, promoted [43] – its importance. In many cases of persuasion involving technology, for example, it may feel that we are not so much logically convinced as worn down or distracted into acquiescence. Technology has an indefatigable power to insist, and so any effects of ground modulation it employs (such as tendentious diction) are amplified.
To model the ground modulation structure of natural texts, we propose a computational approach to a common technique from applied semiotics that seeks to capture such patterns in ground and figure formations: opposition analysis.
1.2.Opposition analysis
In professional contexts, the semiotic tool most often employed to bring formality to questions of persuasion is opposition analysis (OA), whose history back to Saussure [7] is précised with a focus on computational semiotics in [4]. In establishing a visual format for OA, Greimas’ work on the semiotic square has been particularly influential [5,13,14]. In commercial practice, simplified versions of the semiotic square are more commonly employed, at least in initial surveys. For example, marketing consultants often begin by using OA to locate a product along two axes of “binary” opposition. Such a preliminary analysis of soft drink brands from [29] is offered in Fig. 1. It plots four well-known brands on axes of mature versus trendy, and individualistic versus social.
![A simple binary opposition analysis of soda brands ([29] p. 133).](https://ip.ios.semcs.net:443/media/aac/2019/10-3/aac-10-3-aac190467/aac-10-aac190467-g001.jpg)
The axes for such OA diagrams are normally selected impressionistically based on:
the analyst’s remit;
their knowledge of the target objects;
their experience with respondents and focus groups; and
their modelling of cultural norms and patterns.
Perhaps to enhance their impact in presentations to decision makers, the results of even fine-grained OA are commonly distilled to just two orthogonal axes and additional dimensions are smuggled in using colour differentiation and quadrant labels. This is illustrated in Fig. 2, which is an OA used, according to its authors, to model gaps in the children’s activity book market and set the basic parameters for the bestselling Unbored series. By plotting colloquial labels for characters in children’s lives along axes of
Fig. 2.
An opposition analysis used in a project leading to the Unbored children’s activity books undertaken by Glenn and Leone [11, 14m25s].
![An opposition analysis used in a project leading to the Unbored children’s activity books undertaken by Glenn and Leone [11, 14m25s].](https://ip.ios.semcs.net:443/media/aac/2019/10-3/aac-10-3-aac190467/aac-10-aac190467-g002.jpg)
1.3.Motivations for computational automation of OA
The centrality of OA to the theoretical position taken in 1.1, and the widespread availability of digital texts containing informal argumentation, makes a computational approach to OA an appealing avenue for investigation. While semiotics has taken an interest in computation [1,8,9,20,25], apart from [4], little work has been done in computational treatment of opposition analysis. To our knowledge no automated means of generating OA diagrams has been published. Moreover, while automation of a manual practice would be a valuable contribution in itself, we discern two other motivations.
Firstly, there is an opportunity to perform OA computationally in much higher dimensions than currently possible using impressionistic, “culture surfing”, manual methods. In Fig. 2, for example, the use of different colours for plotted values is used to include a third variable. One might consider the quadrant labels such as “Wacky” a fourth, but three dimensions is normally as far as manual OA goes. A general procedure for n-dimensional OA seems absent from semiotics. To view soft drink brands or activity books from a different perspective (rich versus poor, for example) it would seem necessary to rethink and redraw the entire analysis. In addition, a computational procedure for rotating oppositions between axes would, at the very least, be useful for revealing relations “on screen” that are not immediately obvious and help generate new ideas and understandings for persuasion in a particular field.
Secondly, computational treatment of OA can increase precision. As noted, OA is often reduced to binary OA in which objects are not plotted with specific values but, as in Fig. 1, simply allocated a quadrant. This not only affects the precision of analysis but makes longitudinal or real time updating an onerous task. It would be difficult, for example, to check on a weekly basis how near or far from each other Coke or Pepsi are on the
For the reasons developed above – automation, multidimensionality, precision, novel visualisation, and time series updating – this paper contributes an approach to computational opposition analysis (COA) that it is hoped will be of use to those seeking to persuade.
2.Theoretical foundation to the approach: Opposition theory and finite semiotics
Opposition theory asserts, in the words of Assaf, Cohen, Danesi, and Neuman, that “oppositions underlie basic cognitive and linguistic processes” [4, p. 159]. Obvious evidence for this is that objects appear to us to have properties. For the object bird we currently use as an opposition swan or pelican, just as for swan we currently recognise black or white. Conversely, we may meet someone new and classify them poor or rich, but only rarely swan or pelican. We have the choice and capability to say anything about the objects we encounter, but in practice we tend to only say a limited set of things and those things remain relatively stable over time implying a system of oppositions.
Because of the binary reductions that opposition theory promises, there has been a suspicion for some time that it may be helpful in adapting computation to new classes of problems [15]. However, the difficulty of using signs as a basis for statistical analysis has generally hindered this effort. A new theory of semiotics, called finite semiotics, has lately sought to address this disconnect by recasting the sign in terms of the finiteness of cognition [36–38]. Some of its underpinnings from traditional semiotics were flagged in 1.1. While a full account of finite semiotics is not possible here, two important notions derived from it that inform our approach to COA and are outlined in 2.1 and 2.2.
2.1.Artefacts as proxies for thought
Summarising for present purposes, finite semiotics grounds the notion of opposition in the more obvious and ontologically tenable concept of oscillation in thought: the tendency of our thoughts to vary in regular patterns over time [38]. It asserts that this patterning arises in response to the cumulative effects of our environments, which are typically rich in human artefacts11 evolved to play a disciplinary role in thought. Proof of this is trivial: it would be difficult to argue, for example, that learning to read in childhood does not pattern our thoughts so that later we react to text in an email. The recurrent presentation of signifiers via artefacts correlates with recurrence and homogenisation of thought across a population. Ubiquitous artefacts and their patterning, therefore, can be considered proxies for thought; and to study thought we need to study this patterning. This motivates us to prefer in our approach the living term proxy to the moribund and text-centric term corpus in referring to artefacts from which our COA approach will be derived.
Although the practice of regarding artefacts as proxies for thought is rarely formalised, it is of course not new: we do this every day when we read an email from someone and believe we know their thoughts (or at least some refracted version of them). Even the artefacts of antiquity are still regularly taken as proxies for thought: we believe we know something about the thoughts of Aristotle, for example, by reading works attributed to him. Such habits of interpretation of proxies, once formalised, can be extrapolated from the artefacts the digital age now supplies in abundance. Our thinking around “gun control”, for example, may result from actual experience with guns, but also from cumulative exposure to television and movies, comments seen and made on social media, reports in the news, academic study and so on. In this paper, we contend that an analysis of the signifiers contained in such artefacts, taken as a proxy, can be used to derive a high-dimensional, population-level oppositional “shape” for thought about an issue.
2.2.Oscillation in thought as the basis of opposition
Finite semiotics does not propose that the shape of any particular formation of thought such an argument is static – that each side is locked in its own immutable, irreconcilable thought patterns and never the twain shall meet. Instead it views opposition as the result of systematic deviations from the common ground of thought that necessarily engender the issue. To illustrate, consider these two concocted, but perhaps not atypical, statements on gun control:
Pro gun control: | Without gun control, women live in fear their children will grow up obsessed with guns and become murderers or victims. |
Con gun control: | If guns are controlled, men live in fear their sons will grow up to face death or oppression from unopposable governments. |
Figure 3, adapted from [38], illustrates how the patterns of thought implied by these statements engender both the issue and its oppositions. The two agents making the statements think about “gun control” using some common concepts such as “fear”, and “grow up”. However, they deploy these in quite different ways that give rise to oppositions. Some of these deployments may be incidental (e.g., “gun control” versus “guns are controlled”), while others, which might be seen as “field-defining” in Toulmin’s [39] terms, are likely to recur often in discourse on the issue (e.g., “women” and “men”, or “murder” and “death”).
Fig. 3.
How patterns of thought around an issue such as “gun control” imply oppositions. (Note: the space represented is not intended to be taken as two-dimensional. It is a flattening of a theorised high-dimensional space.)
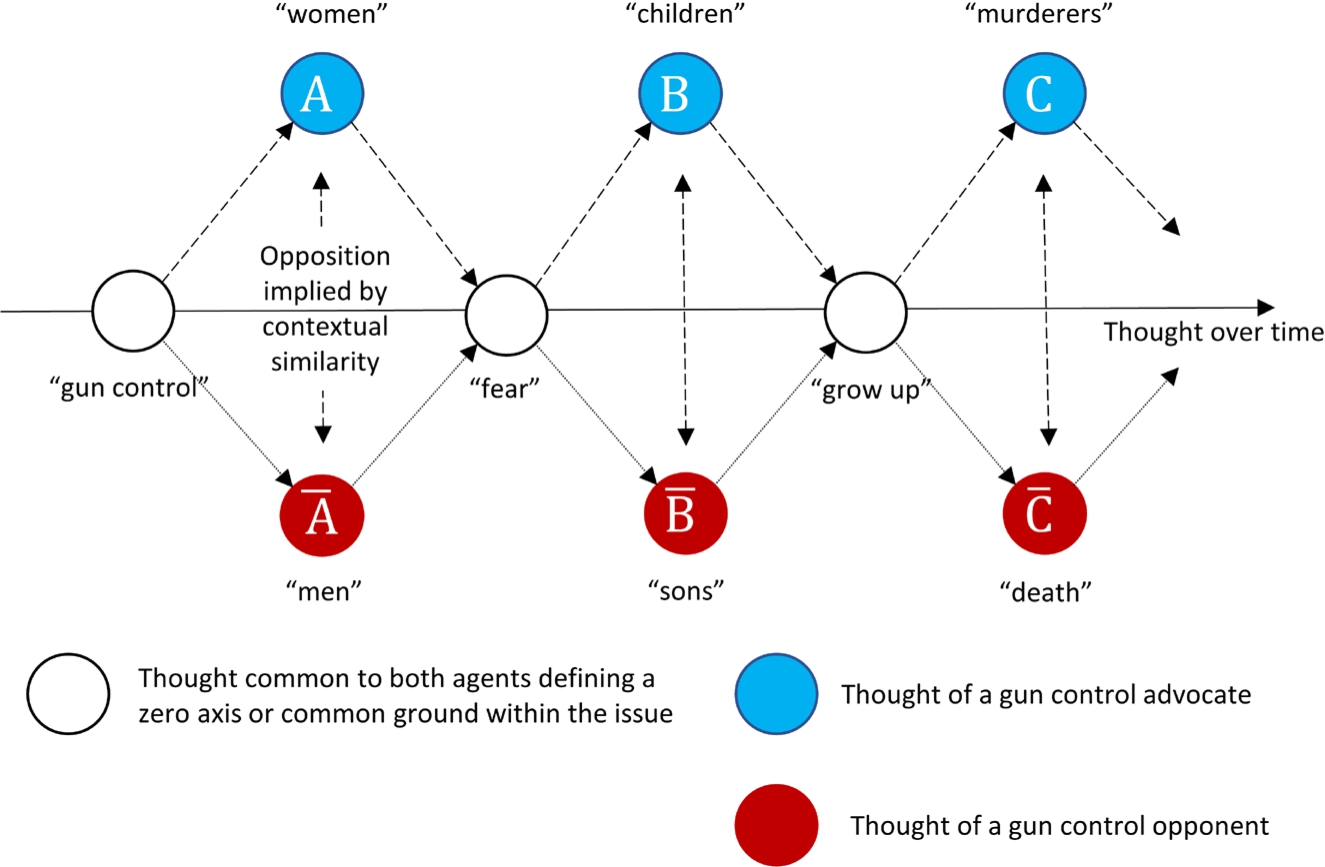
The underlying notion of oscillation is that the thoughts of differently convinced agents will nonetheless partially overlap. A common issue-defining set of thoughts will occur, as will a number of common variants. This leads to complex potentials for thought about an issue to occur as transitions from relatively defining to relatively variant structures. The more stable of these potentials are what we identify in our theory as oppositions.
It should be noted that this conception is also commensurate with drift in patterns of opposition. As new artefacts emerge (seemingly unrelated animal rights advertising, for example) the set of defining and variant thoughts change their relations. If someone is convinced to become a vegan, for example, many of their associations about gun control may shift also. This is not to say they will necessarily change sides. They may reverse their position, or simply come to think about the issue according to a new set of oppositions.
In dealing with such a dynamic entity as thought, it is self-evident that oppositions may vary greatly in being persistent or transitory. Persistent oppositions are often of most interest to the analyst, and certain types are already enshrined under special categories as antonyms or synonyms. Such oppositions are not our primary concern and are viewed simply as a special case. Oppositions may be of a much less expected form depending on the dynamic contexts created by circumstance. From Fig. 3 it is possible, for example, to see how “sons” and “children” might be strongly opposed in regard to gun control but not in regard to the abortion debate, which has different commonalities. Insightful work in this vein on different contextual varieties of textual opposition and how they are created has been carried out by Jeffries [18], while van Belle [40] has provided cogent analyses of “multimodel media” based on Fahnestock’s view of Aristotelian antithesis [10, ch. 4].
In summary, finite semiotics proposes that, to make it amenable for computational analysis, the synchronic notion of opposition must be “de-reduced” into the diachronic thought variations or oscillations that constitute it. Those thoughts, in turn, should be sought in the patterns of signifiers found in artefacts that can be considered their proxies. In this way, instead of a static set of oppositions, a proxy can be viewed as a set of complementary oscillations that it provokes in an audience through time. This more dynamic view of opposition allows us to approach it with more nuance, remain sensitive to its complexity, and find ways to trace and predict pathways of thought that are useful for persuasion.
3.Approach
The proposed approach seeks to detect oppositions, align them contextually, and estimate their opposing power to produce a plot similar to those used in traditional opposition analysis. At the abstract level, the following three steps were considered necessary:
1. Identify signifiers that are relatively prominent (that is, that occur more often in one proxy than others)
2. Identify and rank possible opposition pairs by a measure of relative prominence and contextual similarity
3. Derive a measure to plot each proxy on the axis created by opposition pairs
Before attempting to adapt NLP techniques to achieve each of these steps, it will be useful to consider a symbolic (rather than textual) example. Consider a minimal proxy representing an object consisting of two sets of tokens:
Set 1: | |
Set 2: |
The contexts of tokens B and C are identical in these sets: B and C are both preceded by A and in the terminal position. Their contextual similarity can be assigned a value of 1. The contextual similarity of A–B and A–C, on the other hand, can be assigned 0.5 reflecting two disparate instances of A: one in the initial position preceding B and one in the initial position preceding C. If, for convenience, we assign a zero value to pairings of identical tokens (A–A), we can construct a matrix such as:
Emerging from this formal exercise is a measure of contextual opposition for all permutations of A, B and C that suggests the opposition
To illustrate further, now consider two minimal hypothetical textual proxies invented for gun control consisting of just two sentences, one from the Con side and one from the Pro side:
Con: | Guns are good. |
Pro: | Guns are bad. |
As in the symbolic example, the contexts of signifiers good and bad are identical. If we omit are as a stop word,22 we can follow the process above to create a matrix as follows:
The matrix suggests that gun control oscillates strongly on the axis
Con: | Guns are good. |
Pro: | Guns are useful. |
The highest ranked axis of opposition becomes
Now consider a much less clear-cut example:
Con: | Guns are good. |
Pro: | Guns are macho. |
Whether good and macho are antonyms or synonyms seems a fruitless mode of analysis. However, while the opposition of good and macho is much less obvious, it could reveal a key division: for example, that goodness and machismo are highly opposed in the minds of the Pro side. This group might therefore be influenced by arguments that reframe or deemphasise machismo.
Of course, these examples are simplistic for illustrative reasons. The power of the approach is that it can be scaled computationally to model any number of oppositions in any number of dimensions. As a demonstration of how the approach may be implemented, the following section uses real world proxies for a COA of gun control, introducing and adapting NLP techniques as necessary to achieve the three steps identified above. The implicit purpose is to uncover patterns of thought related to gun control and suggest arguments to influence people on the issue.
3.1.Proxies
It was argued in 2.1 that opposition analysis must begin with the selection of artefacts that can be used as proxies for the target thought. Such proxies must contain a sufficient number of signifiers and arise from a context in which argument is in evidence. An ideal source, therefore, is one in which texts representing polarised views are identified.
On the topic of gun control, we found two opposing sets of texts on the website ProCon.org [31], which we designated Pro and Con. In accordance with the background discussion above, the articles were taken as proxies for two coexisting types of prevalent thinking about gun control. The Pro side favour tighter gun control; the Con side favour less control. Each set contained fifteen texts for a total of thirty. According to the ProCon.org site, the texts are a “professionally researched and curated nonpartisan compilation of the best Pro, Con, or General Reference responses” [32] to the question “Should More Gun Control Laws Be Enacted?”, and are sourced from “websites, magazines, newspapers, libraries, transcripts, videos, interviews, emails, legislation, direct correspondence, and more” [32].
3.1.1.Pre-processing
Each proxy was converted to a standard format by removing punctuation, non-alphabetical characters and stop words, converting to lower case, and lemmatizing.33 An inspection was then performed to identify any important multi-word expressions as signifiers. Three were identified: “gun control”, “Second Amendment” and “United States”. These were singularised by replacing white spaces with underscores as in “Second_Amendment”. While NLP has excellent methods for identifying multi-word expressions, to maintain clarity while delineating our approach, this step was performed manually. It should be noted, however, that signifier recognition is a crucial step and one that may always require the semiotic acumen of the analyst. For while the object under analysis is represented by formal tokens such as “gun”, the division of these into signifiers is a matter of generalising the cognitive habits of the discourse community concerned. A certain community in a certain context, for example, may recognise “all the king’s men” as a discrete literary allusion, while others may view it more as a conglomerate of individual terms. This necessary distinction is well explored by Danesi [6, ch. 5], and ultimately allows the application of OA (and thus potentially COA) beyond linguistic texts, a subject worthy of further discussion but beyond the scope of the present paper.
3.2.Step 1: Identifying relatively prominent signifiers
In two proxies selected to represent opposing sides, a number of common signifiers will inevitably be prominent. In gun control discourse, for example, one would expect to find many instances of gun, rights, crime and so on. In our oscillation-based approach to OA, however, it does not necessarily follow that common signifiers are most provocative of semiosis. In fact, the signifiers derived from common topic and relevance measures in our model more likely constitute the stable zero axis around which oscillation occurs. More germane to opposition in our model are signifiers that are relatively more prominent in one proxy than another. A simple way to identify these is to take the difference in term frequency (expressed as a fraction of total terms) between the two proxies.44 So, if the frequency of gun in the Pro proxy is 0.017 and in the Con proxy it is 0.014, then the difference of 0.003 will probably not mark this signifier as one of interest. But if the frequency of massacre in the Pro proxy is 0.017 and in the Con proxy it is 0.003, then the difference of 0.014 may indicate a noteworthy signifier and something that resonates and divides.
A general formula, therefore, to derive a metric for the relative prominence of a signifier in related proxies is to take the difference of its frequency in each proxy. Formally stated: for signifier s occurring in one or both proxies A and B with total numbers of signifiers
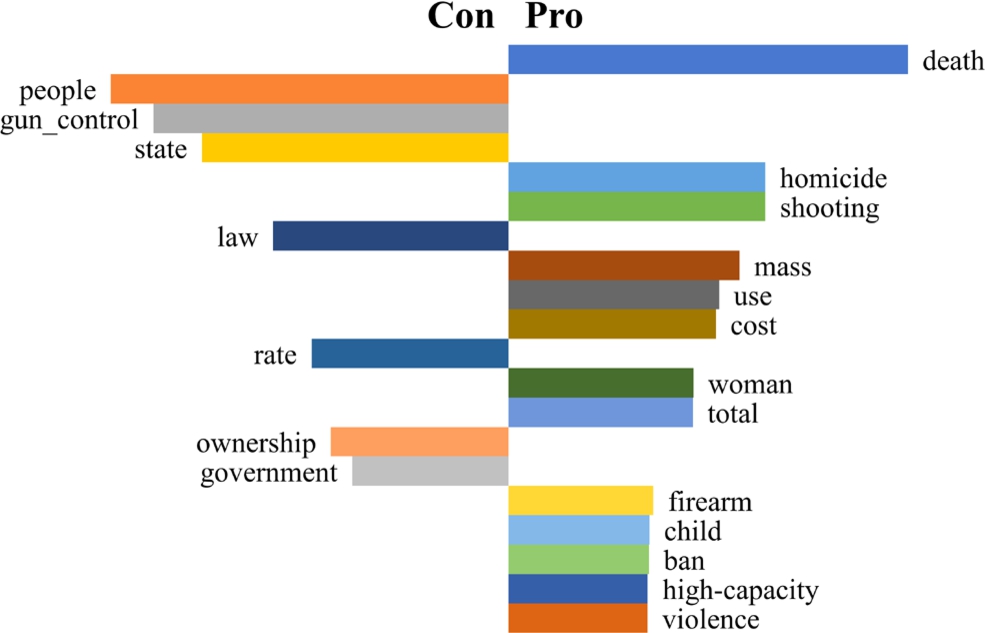
For convenience only, with regard to the gun control proxies, we assign A to the Pro proxy and B to the Con proxy, and this leads conveniently to positive or negative weighting of r indicating whether the signifier is favoured in the Pro proxy (positive) or Con proxy (negative). The top ten prominent relative signifiers for the Pro and Con gun control proxies calculated using this formula are shown in Table 1.
Table 1
The ten most relatively prominent signifiers for the Pro (+ve) and Con (−ve) gun control proxies
| Pro favoured signifier | r | Con favoured signifier | r |
| death | 0.011584 | people | −0.011471 |
| homicide | 0.007442 | gun_control | −0.010240 |
| shooting | 0.007442 | state | −0.008837 |
| mass | 0.006688 | law | −0.006766 |
| use | 0.006108 | rate | −0.005675 |
| cost | 0.006004 | ownership | −0.005129 |
| woman | 0.005354 | government | −0.004514 |
| total | 0.005337 | free | −0.003899 |
| firearm | 0.004211 | infringe | −0.003899 |
| child | 0.004089 | man | −0.003899 |
Figure 4 contrasts the top twenty relatively prominent signifiers in the Pro and Con gun control proxies, of which 13 are favoured in the Pro proxy and 7 in the Con. The dominance of the Pro side in the figure could suggest it exhibits a higher degree of polarisation that the Con proxy. In other words, it may indicate that it makes greater use of its preferred terms.
Fig. 4.
Bar chart of the top twenty relative prominent signifiers in the Pro and Con gun control proxies.
3.3.Step 2: Identifying and ranking possible opposition pairs by scoring on a measure of relative prominence and contextual similarity
As opposition must occur within the ordering restrictions of the code in which signifiers are embedded (in this case, the syntax of English), analysis of word context can be useful in determining which relatively prominent signifiers are most in opposition. At present one popular means of doing this is using word vectors,55 a popular implementation of which is “word2vec” [23]. Such models may be applied either internally by training on the proxy data provided it is sufficiently large, or externally by invoking a comparison with a large external proxy to provide a baseline of syntagmatic restrictions.
To illustrate the logic of the opposition ranking procedure, consider an example: if the Pro gun control proxy suggests the prominence of the signifier death relative to the Con proxy, and the Con proxy suggests the prominence of life relative to the Pro proxy, we can quantify this as an opposition (that is, as a defining substitution) by referring to the contexts in which each occurs in each proxy. If death occurs in one where life occurs in the other there is reason to think the signifiers are in opposition. For small proxies, this contextual similarity can be normalised by reference to a large, heterogenous external proxy. So, if the signifiers death and life commonly occur in similar contexts in broader discourse, we can theorise that both are possible in each Pro or Con context and that the use of one rather than the other (their relative prominence) tends to differentiate the two proxies. In other words, signifiers scoring highly on relative prominence and contextual similarity are excellent candidates to be strongly opposed and to occupy the ends of an axis of opposition in our COA.
The above logic can be formalised by stating that the opposition score O for two signifiers
The constants
It should be noted that the inclusion of the two relative prominence measures in this formula keeps commensurate contextual similarity and frequency of occurrence. Signifiers of great similarity in the formula will not be considered highly opposed if their relative prominence is low.
3.3.1.Implementation
In the case of the small ProCon.org gun control proxies, an external contextual measure was appropriate for calculating contextual similarity. The gensim python module utilising Google’s word2vec model with embeddings trained on roughly 100 billion words from an undated Google News dataset [12,23,33] was used to calculate a similarity score for signifier pairs and create a ranked list of opposition scores according to the formula above. As cosine similarity may be negative, the absolute value of the word2vec similarity was used (but did not in the eventuality play a role in any of the top thousand rankings). Unfortunately, a number of signifiers (most notably gun_control) were not present in the Google News embeddings and could not be processed. This could be addressed in larger scale analysis by training a custom set of embeddings.
Table 2 shows the top ten scored opposition pairs for the Pro and Con gun control proxies. These can be considered the most salient axes of opposition. Perhaps unsurprisingly, the top oppositions are dominated by signifiers pairing with death.
Table 2
The top ten opposition scores for the ProCon.org gun control proxies
| Pro signifier | Con signifier | Opposition score |
| woman | man | 0.007142060 |
| death | murder | 0.006958003 |
| death | die | 0.006815950 |
| death | fatal | 0.006634232 |
| person | people | 0.006580634 |
| homicide | crime | 0.006180689 |
| woman | people | 0.006043491 |
| someone | people | 0.005648217 |
| district | state | 0.005264503 |
| death | life | 0.005150456 |
For a more diverse overview of results, Table 3 shows the top ten scored opposition pairs where both signifiers appear for the first time (that is, excluding pairs where one signifier has already been used in a higher scoring pair).
Table 3
The top ten opposition pairs where both signifiers appear for the first time
| Pro signifier | Con signifier | Opposition score |
| woman | man | 0.007142060 |
| death | murder | 0.006958003 |
| person | people | 0.006580634 |
| homicide | crime | 0.006180689 |
| district | state | 0.005264503 |
| firearm | gun | 0.005087846 |
| rule | law | 0.004311344 |
| shooting | shoot | 0.004306246 |
| use | allow | 0.003702686 |
| cost | rate | 0.003664699 |
3.4.Step 3: Plotting the proxies on a classic opposition quadrant diagram
Having arrived at a computational means to identify oppositions in the proxies, it remains to plot them on a traditional OA diagram. The obvious means to do this is to discount occurrences of one signifier in a proxy with occurrences of the other signifier in the proxy. Thus, an axis score for each proxy can be derived by subtracting the normalised term frequencies of the two signifiers making up the axis. For example, for the
To create a traditional OA diagram, the top two scoring axes (
Fig. 5.
A computationally generated opposition analysis diagram showing the gun control Pro and Con objects on the two highest scored axes.
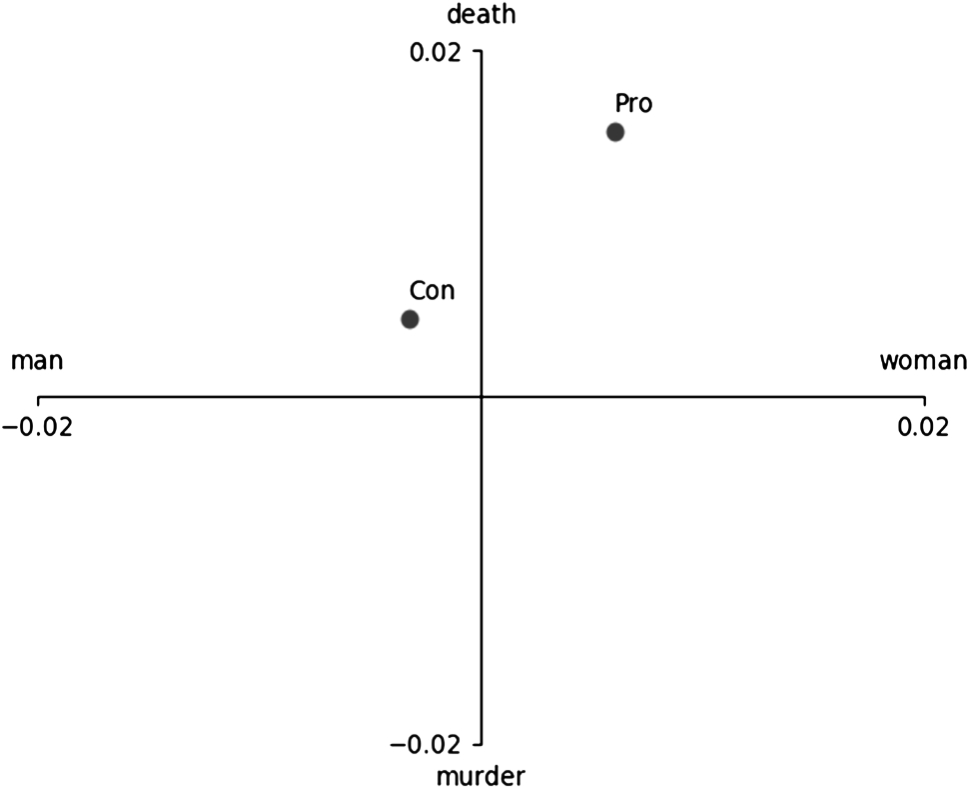
Due to their computational provenance, these diagrams could be generated in as many dimensions as required. This would allow multidimensional exploration of the proxies using visualisation technology (such as Google’s TensorBoard, for example). Further inspection could be performed to relate axes of opposition on other purposeful metrics than simple ranking. For example, guided by the purpose of the analysis, the
4.Interpretation
The results presented above are not intended to assert any definitive relations regarding gun control. Opposition analysis involves the development of a narrative around carefully selected objects for an implied or explicit purpose. The role of OA is to aid such reasoning: that is, to suggest avenues for investigation that might help to develop narratives useful for crafting arguments on a particular issue. COA seeks to assist and enrich this human process, not establish definitive practices. However, to offer an example, consider two obvious and already common informal arguments in gun control debate that are identified in the results:
Pro example: The high ranking of the
Con example: The high ranking of
A simple way that persuasion could be improved by knowledge of oppositions is in better selection of examples in argument by example. While a large range of examples might serve to illustrate a particular point, some will be more salient to one side than the other while exhibiting all the same relative elements. For example, to illustrate that guns are dangerous, one might say that a number of people die due to gun accidents each year. Far more compelling when speaking to unite the Pro side, however, might be to say that a number of women die each year due to gun accidents – simply because women are a pole of opposition on the Pro side.
Furthermore, if one is planning to deploy any argument scheme, it is useful to fill it out with words that are most helpful – or least injurious – to your cause (see the passage from Aristotle cited in 1.1). Armed with the results of COA, one might be aware that to resonate one should speak more of deaths to the Con side and more of murders to the Pro side. More subtly, one might be advised to speak of “rules” to the Pro side and “laws” to the Con side (
We contend that the computational finding and invention of salient examples and diction would be a useful contribution to rhetoric.
5.Refinements and further work
The COA of gun control above was presented in a simple format for clarity and some complexities that would be important to a real analysis were omitted. A more purposeful analysis could, for example, refine results by introducing word sense disambiguation measures to remedy potential miscounting of signifiers (such as state, verb, and state, noun). A custom trained word2vec or sense2vec model would be useful in this and would also allow better similarity scoring of domain-important entities: for example, the central signifier gun_control was not scored for similarity because it is not included in the Google News embeddings.
Using the high dimensional space generated by opposition scoring, it should be possible to not only programmatically generate and navigate OA plots to produce novel visualisations, but also to highlight or filter various relations such as antonymy or synonymy.66 Another possibility it that oppositions could be calculated, ranked and arranged using large quantities of historical and real-time data to create semiotic object trackers (for brands or opinions, for example) that might be used to great effect in programmatic argument invention.
As its operation is agnostic regarding the form of signifiers, there is also the possibility of extending the usefulness of COA beyond the strictly textual. It could be useful, for example, to model how one image resonates with another. This could be done by using the output of a feature recognition system to produce proxies. Thus, for example, a simple image detected as showing “man, gun, dog” could be automatically compared to one showing “woman, gun, child” and displayed or not displayed on a web page according to purpose.
Due to the difficulty of immediate, iterative evaluation of COA, refinements to the approach and its methods ultimately need to be guided by the community involved in opposition analysis – even by sub-communities particular to niche fields. This will involve evaluating the outputs of COA against the results of interventions based on them, or on the usefulness of COA in the chain of idea generation that leads to a successful informal argument.
6.Conclusion
Motivated by the grounding of opposition in oscillation from finite semiotics, this paper proposed a method to formalise, automate and expand opposition analysis, a technique commonly employed in areas such as lobbying, marketing and branding to create resonant informal argument. An analysis of gun control using texts from ProCon.org was made to illustrate the new approach’s methods and algorithms.
While there has been some interest in bringing computation to semiotics as surveyed in 1.2, and a number of recent papers in automated persuasion [16,17,26,34], we believe the rising pressure on individuals to process the vast number of informal arguments they encounter every day warrants more work in this area. How often, for example, is an argument glimpsed on the internet processed to completion? And how often does a clash of images on social media rather than careful deliberation determine subsequent action? In our view, persuasion in this new context has newly relevant properties – such as oppositional structure – that can be revealed by computational analysis. We hope this paper will raise awareness of the opportunity to re-envision signs, whose relevance was asserted as far back as Aristotle, as a tool for this effort.
Notes
1 Artefact here is meant to include physical things such as text and other media, but also gestures, sounds, language and other abstract things that nonetheless influence our thoughts.
2 In natural language processing, stop words are extremely common words such as “the”, “is”, “be” that are often deleted before processing a text.
3 Lemmatisation is the process of replacing each word with its root form or “lemma” with attention paid to its grammatical role (part of speech). Thus “guns” would become “gun” and “controlled” would become “control”.
4 Term frequency is used in this paper for clarity of exposition. In purposeful applications involving a larger corpus, adaptations of more complex techniques from information retrieval (e.g., tf-idf) or topic modelling (e.g., latent Dirichlet allocation) would likely be more appropriate.
5 For an introduction to vector space models such as word2vec, refer, for instance, to [19].
6 For example, tools such as WordNet could be used to ascertain if two words are antonyms or synonyms and highlight or exclude these from the list of oppositions.
References
[1] | P.B. Andersen, A Theory of Computer Semiotics: Semiotic Approaches to Construction and Assessment of Computer Systems, Cambridge University Press, Cambridge, UK, (1990) . |
[2] | R.L. Anderson and C.D. Mortensen, Logic and marketplace argumentation, Quarterly Journal of Speech 53: (2) ((1967) ), 143–151. doi:10.1080/00335636709382826. |
[3] | Aristotle, Art of Rhetoric, Harvard University Press, Cambridge, MA, (1926) . |
[4] | D. Assaf, Y. Cohen, M. Danesi and Y. Neuman, Opposition theory and computational semiotics, Σηµειωτκη´ – Sign Systems Studies 43: (2–3) ((2015) ), 159–172. |
[5] | S. Badir, How the semiotic square came, in: The Square of Opposition: A General Framework for Cognition, J.Y. Beziau and G. Payette, eds, (2012) , pp. 427–439. |
[6] | M. Danesi, The Quest for Meaning: A Guide to Semiotic Theory and Practice, University of Toronto Press, Toronto, (2007) . |
[7] | F. De Saussure, Course in General Linguistics, Columbia University Press, New York, (2011) [(1916) ]. |
[8] | C.S. De Souza, S.D.J. Barbosa and R.O. Prates, A semiotic engineering approach to user interface design, Knowledge-Based Systems 14: (8) ((2001) ), 461–465. doi:10.1016/S0950-7051(01)00136-8. |
[9] | C.S. De Souza and C.F. Leitão, Semiotic engineering methods for scientific research in HCI, Synthesis Lectures on Human-Centered Informatics 2: (1) ((2009) ), 1–122. |
[10] | J. Fahnestock, Rhetorical Figures in Science, Oxford University Press, Oxford, UK, (1999) . |
[11] | J. Glenn and T. Leone, Josh Glenn & Tony Leone, UNBORED games: “Serious fun for everyone”, Talks at Google, YouTube, 2015. |
[12] | Google, Google Code Archive – word2vec 2017. Available from: https://code.google.com/archive/p/word2vec/. |
[13] | A.J. Greimas, Structural Semantics: An Attempt at a Method, University of Nebraska Press, Lincoln, NE, (1966) /(1983) . |
[14] | A.J. Greimas and F. Rastier, The interaction of semiotic constraints, Yale French Studies 41: ((1968) ), 86–105. doi:10.2307/2929667. |
[15] | R. Gudwin and J. Queiroz (eds), Towards an introduction to computational semiotics, in: Proceedings of the International Conference on Integration of Knowledge Intensive Multi-Agent Systems, (2005) . |
[16] | E. Hadoux and A. Hunter, Comfort or safety? Gathering and using the concerns of a participant for better persuasion, Argument & Computation ((2019) ), Preprint, 1–35. |
[17] | A. Hunter, Towards a framework for computational persuasion with applications in behaviour change, Argument & Computation 9: (1) ((2018) ), 15–40. doi:10.3233/AAC-170032. |
[18] | L. Jeffries, Opposition in Discourse, Bloomsbury Publishing, London, (2014) . |
[19] | D. Jurafsky and J.H. Martin, Speech and Language Processing, 2nd edn, Pearson, London, (2014) . |
[20] | K. Liu, Semiotics in Information Systems Engineering, Cambridge University Press, Cambridge, UK, (2000) . |
[21] | P. Manning, The semiotics of brand, Annual Review of Anthropology 39: ((2010) ), 33–49. doi:10.1146/annurev.anthro.012809.104939. |
[22] | D.E. Meyer and R.W. Schvaneveldt, Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations, Journal of Experimental Psychology 90: (2) ((1971) ), 227. |
[23] | T. Mikolov, I. Sutskever, K. Chen, G.S. Corrado and J. Dean (eds), Distributed representations of words and phrases and their compositionality, in: Advances in Neural Information Processing Systems, (2013) . |
[24] | E. Minton, T. Cornwell and L. Kahle, A theoretical review of consumer priming: Prospective theory, retrospective theory, and the affective-behavioral-cognitive model, Journal of Consumer Behaviour 16: (4) ((2017) ), 309–321. doi:10.1002/cb.1624. |
[25] | Y. Neuman, Y. Cohen, D. Assaf and M. Danesi, Identifying the meta-forms of situations: A case-study in computational semiotics, International Journal of Semiotics and Visual Rhetoric (IJSVR) 1: (1) ((2017) ), 56–71. doi:10.4018/IJSVR.2017010107. |
[26] | R. Orji and K. Moffatt, Persuasive technology for health and wellness: State-of-the-art and emerging trends, Health Informatics Journal 24: (1) ((2018) ), 66–91. doi:10.1177/1460458216650979. |
[27] | L. Oswald, Marketing Semiotics: Signs, Strategies and Brand Value, Oxford University Press, Oxford, (2012) . |
[28] | L. Oswald, Creating Value: The Theory and Practice of Marketing Semiotics Research, Oxford University Press, USA, (2015) . |
[29] | L. Oswald, The structural semiotics paradigm for marketing research: Theory, methodology, and case analysis, Semiotica 205: ((2015) ), 115–125. |
[30] | C.S. Peirce, Collected Papers of Charles Sanders Peirce, P. Weiss and C. Hartshorne (eds), Harvard University Press, Cambridge, MA, (1974) . |
[31] | ProCon.org, Gun control – ProCon.org 2017, October 5 [updated 5/10/2017]. Available from: http://gun-control.procon.org/. |
[32] | ProCon.org, FAQs (Frequently Asked Questions) – ProCon.org 2017. Available from: https://www.procon.org/faqs.php. |
[33] | R. Řehůřek and P. Sojka, Software framework for topic modelling with large corpora, in: Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, (2010) . |
[34] | A. Rosenfeld and S. Kraus (eds), Strategical argumentative agent for human persuasion, in: Proceedings of the Twenty-Second European Conference on Artificial Intelligence, IOS Press, (2016) . |
[35] | G. Rossolatos, Handbook of Brand Semiotics, Kassel University Press GmbH, Kassel, (2015) . |
[36] | C. Shackell, Finite cognition and finite semiosis: A new perspective on semiotics for the information age, Semiotica 222: ((2018) ), 225–240. doi:10.1515/sem-2018-0020. |
[37] | C. Shackell, Finite semiotics: Recovery functions, semioformation and the hyperreal, Semiotica 227: ((2019) ), 211–226. |
[38] | C. Shackell, Finite semiotics: Cognitive sets, semiotic vectors, and semiosic oscillation, Semiotica 229: ((2019) ), 211–235. |
[39] | S.E. Toulmin, The Uses of Argument, Cambridge University Press, Cambridge, UK, (1958) . |
[40] | H. van Belle and L. Ado, More done: Verbal and visual antithesis in the media, Informal Logic 33: (3) ((2013) ), 343–360. doi:10.22329/il.v33i3.3758. |
[41] | D. Walton and T. Gordon, How computational tools can help rhetoric and informal logic with argument invention, Argumentation 33: (2) ((2018) ), 269–295. doi:10.1007/s10503-017-9439-5. |
[42] | J. Woods, Fearful symmetry, in: Fallacies: Classical Background and Contemporary Developments, H.V. Hansen and R.C. Pinto, eds, University of Pennsylvania Press, Philadelphia, PA, (1995) . |
[43] | J. Woods, The Death of Argument: Fallacies in Agent Based Reasoning, Springer, Dordrecht, (2004) . |


