
Theoretical foundations for illocutionary structure parsing1
Abstract
Illocutionary structure in real language use is intricate and complex, and nowhere more so than in argument and debate. Identifying this structure without any theoretical scaffolding is extremely challenging even for humans. New work in Inference Anchoring Theory has provided significant advances in such scaffolding which are helping to allow the analytical challenges of argumentation structure to be tackled. This paper demonstrates how these advances can also pave the way to automated and semi-automated research in understanding the structure of natural debate.
1.Introduction
Argument and debate form a particularly demanding area of natural language understanding, and one which has yielded rather poorly to existing techniques for language analysis and modelling. This paper presents a first, key step towards building a theory that supports Illocutionary Structure Parsing for such discourse material, tackling and indeed exploiting the contextual information offered by dialogical information in order to automatically identify the illocutionary forces associated with speaker actions of asserting, challenging, arguing, promising, requesting and so on [22,28,29]. With this step in place, it becomes possible to build further components for identifying larger scale argumentative structures in natural discourse.
In real dialogues, argumentative acts are never performed in isolation – they are usually embedded in a very complex linguistic context which signals that argumentation has been performed. More specifically, when Wilma says: Why p is the case?, and then Bob responds: q, then this dialogical sequence can be interpreted as being linked to an argument (an inference): p because q. In other words, since Wilma’s challenging move is a request for giving reasons for p, then Bob’s asserting move can be justifiably treated as delivering such a reason, i.e. q can be treated as a reason for p. The model that allows us to capture these dependencies between dialogical processes and argumentative structures is called Inference Anchoring Theory (IAT) [2].
In this paper, we focus on the most basic types of illocutionary acts specific for dialogical contexts: assertions, questions, challenges, concessions and (dis-)affirmations. Using a corpus of dialogue transcripts from the BBC Radio 4 Moral Maze programme, we provide their specification and then show their linguistic modelling and implementation, including preliminary experimental work in which a dialogue is decomposed into text units and associated with the distinguished dialogical acts.
The paper is structured as follows. Section 2 presents the challenges for building a reliable foundation for illocutionary structure parsing, introduces Inference Anchoring Theory and discusses some related work. Section 3 presents the corpus analysis, in particular delivers a taxonomy of the illocutionary structures typical for the Moral Maze type of dialogue, briefly describes our corpus used for linguistic analysis of illocutionary structures, and shows how they can be modelled within theoretical framework of IAT. Finally, in Section 4 we describe the linguistic modelling and the implementation for the identification of dialogue text units and distinguished illocutionary structures.
2.Identification of arguments in dialogue
Argument mining (also called argumentation mining; see e.g. [21,23]) aims at the development of methods and techniques for the automatic identification and extraction of argument structures from texts in natural language. Recently, this area of computational linguistics has become increasingly popular, even though it remains extremely challenging.
In this paper, we show the first step, illocutionary structure parsing, of a method for mining dialogical arguments which uses the theoretical framework of Inference Anchoring Theory (IAT) [2]. We claim that the dialogical context provides additional information about arguments performed during the dialogue which can facilitate the automation of the process of argument identification. More specifically, the type of dialogue game provides information about the type of moves and interactions legal in a given type of game, and as a result, about the types of argument structures which these moves and interactions create (see Section 2.1). The technique of illocutionary structure parsing needs to start with the manual (corpus) analysis of types of illocutionary structure which participants of a specific type of dialogue (in our case in the debate of the Moral Maze programme) are typically using (see Section 2.2). Finally, in this section we discuss some related work in more detail (Section 2.3).
2.1.Anchoring arguments in dialogue
Inference Anchoring Theory (IAT) [2] provides us with a framework for connecting dialogical structures with argument structures which can facilitate mining dialogical arguments. We will first sketch the general idea of IAT on a simplified example:22
(1)
a. Bob: p is the case.
b. Wilma: Why p?
c. Bob: q.
In IAT, different relations between propositions distinguished by logic and argumentation theory can be expressed. For example, (1) contains a reasoning structure consisting of a conclusion q, a premise p, and a relation between p and q called a rule application. This relation may correspond to some logical rule like modus ponens or some presumptive argumentation scheme such as argument from consequences [32] (for the purposes of the example, it is marked simply as a numbered instance of an application of some rule). Propositions may also be connected through other types of relations such as conflict, when, for example, one is the negation or some opposition of another. Conflict corresponds to the relation of attack studied extensively in abstract argumentation framework [7].
Fig. 1.
Interaction between argument and dialogue.
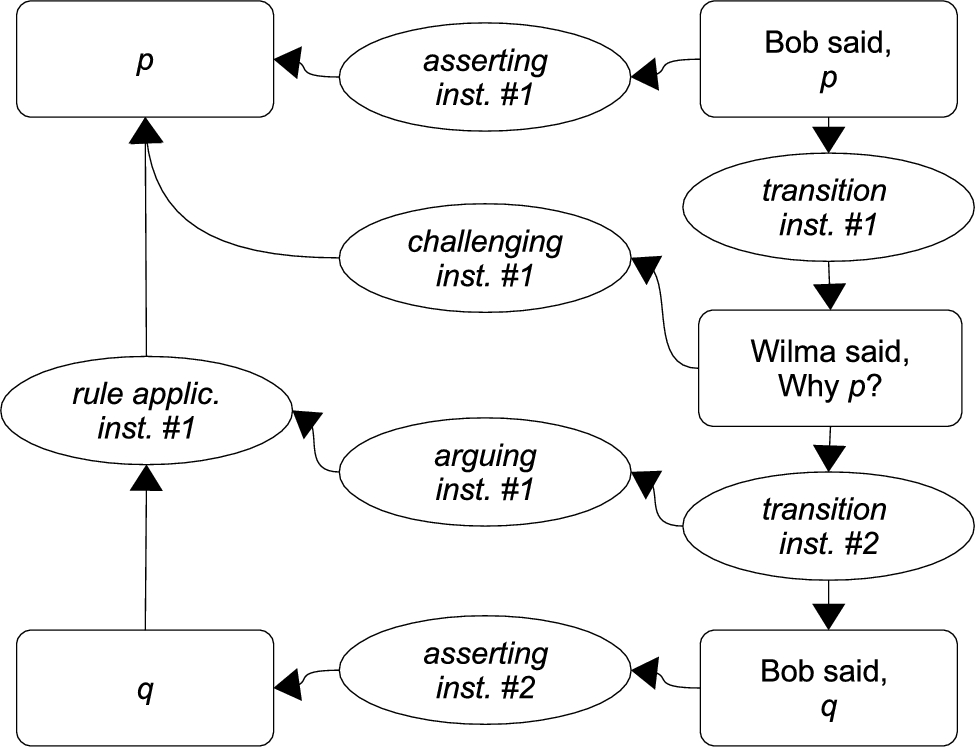
At the same time, (1) contains dialogical structure composing three utterances whose performance is governed by dialogue rules which express how sequences of utterances can be composed (these compositional steps are called transitions in IAT). For example, the dialogue rules permitted Wilma to perform (1-b) (i.e., to ask Bob for grounds for believing p), by virtue of the fact that at the previous move (1-a) Bob committed himself to p (see transition instance #1 in Fig. 1). In other words, the disputants followed a dialogical rule stipulating that challenging is allowed after asserting. Such a normative view of dialogue structure is quite common – in philosophy, authors such as Mackenzie [16] have explored dialogue rationality in these terms in a thread of work rooted in Wittgenstein, whilst in linguistics, approaches founded upon discourse analysis such as Dialogue Macrogame Theory [17] and the HCRC dialogue coding scheme [5] aim to account for dialogue coherence.
Characterising the application of dialogue rules specifically as transitions between locutions is rather more unusual, but is a central part of IAT, because these transitions can act as “anchors”. Logical structures, like propositions, are thus “anchored” in dialogical structures via illocutionary connections related to different illocutionary forces [22,28,29]. The illocutionary force of an utterance can be of a number of types (asserting, challenging, etc.). What type of force should be associated with a given speech act is dependent on the act’s constitutive rules. For example, in order for the connection to be reconstructed as having an asserting force, the utterance has to be a felicitous assertion. In Searle’s model, it means that it has to satisfy, e.g., the constitutive rule of sincerity, i.e. the speaker has to believe that the proposition he utters is true.
In IAT, the dialogical acts (e.g. “Bob said, p”) are linked to their propositional contents (p), by illocutionary connections (asserting instance #1). Some of the illocutionary structures, such as arguing (see arguing instance #1), are anchored in transitions (transition instance #2 in this case). The idea is that for reconstructing the asserting force of (1-c), it is sufficient to inspect the linguistic surface of what has been said in (1-c). Thus, the asserting connection is anchored in the locution (1-c). This, however, does not allow us to identify that Bob was also arguing – if I entered the room exactly in the moment of him performing (1-c), I can only assume that Bob asserted q. In order to recognise that he also argued p because q, I would have to know that (1-c) was the response to (1-b). Thus, the arguing connection is anchored in the transition (relation between locutions (1-b) and (1-c)).
Inference Anchoring Theory provides a framework for mining dialogical arguments. In this simplified case, if a software tool is able to automatically recognise that in (1-b) Wilma performed challenging p and in (1-c) Bob performed asserting q (this is the step of illocutionary structure parsing); and we identified what this sequence typically anchors in a given type of dialogue (in this example a sequence of challenging followed by asserting anchored arguing; such rules are called transition schemes in IAT); then the tool will be able to automatically identify that an argument: p because q, was performed. In natural communication, people use more complex transition schemes which are dependent on the type of interaction they are engaged (the dialogue between friends, in the court, in science and so on). The example of transition schemes elaborated for the Moral Maze type of dialogue is presented in Section 3.3.
This approach offers a significantly more fine-grained account of the context of a dialogue in which a logical inference is established, than is available in, for example, Segmented Discourse Representation Theory, SDRT [1], whilst offering an illocutionary account of structure rather than a rhetorical account – although illocutionary approaches have been criticised by some authors [22], they provide a much better account of argument and debate [24]: what we are after, therefore, by analogy to work on rhetorical structure parsing [19,20] is a mechanism for illocutionary structure parsing.
2.2.Illocutionary structure in dialogical context
One of the challenges of illocutionary structure parsing for the IAT method is the analysis and the manual identification of types of illocutions used in a given dialogue game. The Moral Maze programme can be described as an agreement-seeking type of dialogue where participants start with the difference of opinion and look for reaching an agreement during the course of the programme. Consider an example in which two people discuss whether the British Empire behaved in an uncivilised way during a war in Kenya in the 1950s:
(2)
a. Lawrence James: It was a ghastly aberration.
b. Clifford Longley: Or was it in fact typical? Was it the product of a policy that was unsustainable (…)?
Intuitively, what Longley claims in (2-b) is that uncivilised behaviour was typical for the Empire, and he supports this claim with a premise that such a behaviour was the product of an unsustainable policy. On the linguistic surface, however, we do have neither conclusion nor premise asserted explicitly qua assertions: instead, the act (2-b) is cast as a series of questions. So the problem can be phrased as: how to represent the dialogical acts that typically accompany argumentation in types of dialogues as our corpus, including such contexts in which argumentation is (at least partly) formulated as interrogative sentences?
According to, for example, Searle and Vanderveken’s [29] model, the utterances in (2-b) could be represented as having questioning force. But this would not allow us to express the relation of support between the propositional contents of those utterances, because pure questions do not (by definition as not belonging to assertive acts) convey opinions. One could claim that the utterances have in fact an (indirect) assertive force, for the interrogative form of question is here only the superficial grammatical surface.33 But then we face another problem: why the participants of the Moral Maze programme so often convey their opinions using the interrogative form instead of the straightforward indicative form? Should we ignore this dialogical manoeuvring by interpreting these questions simply as assertions? We claim that using interrogative rather than indicative form to convey one’s opinion influences the dynamics of argumentative interaction during the dialogue and therefore should not be ignored: (1) the speaker has a weaker burden of proof, i.e. he can more easily withdraw when challenged, instead of being obliged to defend his standpoint: “I didn’t claim it, I was only asking”; (2) it is also easier to seek an agreement with the other party which is the main goal of this type of dialogues, i.e., the speaker not only conveys his beliefs, but also, by using the interrogative form, expresses the desire of knowing whether the other party believes the same, and as a result – agrees with him.
The annotation scheme used in switchboard dialog act corpus, SwDA [30], in contrast, introduces a category of rhetorical questions, e.g. “Who would steal a newspaper?”, which are grammatically formed as questions but are used to convey opinions. Yet they have only assertive force, because (by definition) they do not invite the hearer’s response. As a result, they cannot fulfil the agreement-seeking function, since if the hearer is not allowed to respond, he cannot express whether he agrees or disagrees with the propositional content of the (rhetorical) question. In particular, if we understood (2-b) as a series of two rhetorical questions, then James would not be invited to respond and express his agreement or disagreement with the thesis that the British behaviour was the product of an unsustainable policy (while in fact in the next move James disagrees by saying: “It is the product of a policy conceived in – by the Cabinet, in the context of the Cold War, when (…) the British Government is in a near state of funk about what will happen in their Empire”).
What we need is to be able to identify the assertive intentions behind such questions. Only then can we assemble the parts of the argument and attempt to model their composition into large structures. As far as we are aware, there is no model which would allow the representation of such double (asserting and questioning) function of utterances. Thus, as a general goal we need to identify what types of text units (unitary illocutionary structures) are characteristic for our corpus and then develop a comprehensive list of these types.
2.3.Related work
In the literature, there are several models (annotation schemes) that are useful for describing various dialogue, argument and illocutionary structures. These approaches can be divided into two subclasses:
1. unit-based annotation schemes, such as speech act theory (cf. [28,29]) and the Switchboard Dialog Act model, SwDA [30], which focus on types of individual text components, such as, e.g., a text unit being of type assertion;
2. relation-based annotation schemes, such as Rhetorical Structure Theory, RST [18] and Segmented Discourse Representation Theory, SDRT [1], which concentrate on types of relations between components, such as, e.g., the explanatory relation holding between two text units.
Understanding the ways in which dialogical action can establish arguments and inferences stands at the intersection of many disciplines including (at least), discourse analysis, pragmatics and semantics. IAT is constructed to benefit from insights in all of these fields, whilst focusing, quite narrowly, on argumentation as a type (or rather, set of types) of discourse. In discourse analysis, Rhetorical Structure Theory has been enormously influential in facilitating computational models of discourse structure. It postulates a number of discourse relations that can account for the overall structure of any kind of text (a logical analysis of RST is given in [8]). Within our framework, RST can be used to represent the structure of arguments (a conclusion being a nucleus and a support its satellite), and, to a larger extent, to represent the structure of explanations, clarifications, reformulations, elaborations, illustrations, conditionals, causes, etc. From that point of view, RST offers a useful means to represent the linguistic structure of a dialogue. RST does not (not even in its dialogical extensions), however, capture inferential patterns, which lie at the very heart of IAT. It is insufficient for handling fine-grained argument structures for at least two reasons [23,24]: first, many argumentative relations seem to be quite orthogonal to rhetorical relations – whether two sentences are related through Elaboration or Justification says little or nothing about whether they form a part of a modus ponens or modus tollens, or a part of linked or convergent argument structure; and second, argument structure is often missed entirely by rhetorical structure, a problem which becomes manifest in the abundance of (vapid) joint relations in RST analyses of many arguments.
In pragmatics, one of the most significant approaches to dialogue meaning has come from DRT and particularly a more recent derivative, Segmented Discourse Representation Theory. Where Inference Anchoring Theory focuses specifically on argumentative discourse, SDRT has much broader goals than IAT and, as a result, is less well adapted at handling the structure of inference-establishing discourse units. In particular, the way in which the rules of dialogue influence the construction of argument lie beyond SDRT’s assumptions of context-independent semantics [2,31].
In semantics, Ginzburg [10] in particular has had a major impact on models of the meaning of dialogical actions. His KoS approach, like SDRT, is much more general than IAT, but, also like SDRT, suffers in its ability to handle argumentation as a result. Specifically, KoS does not allow the establishment of a relation between propositions (such as inference) to be the result of a pair of locutions which together establish an illocutionary force, such as arguing. Without such pairing, understanding how challenge-response sequences establish inferences becomes difficulty.
There are also a wide range of annotation schemes used specifically for corpus analysis of different dialogical structures. Probably the most comprehensive set of annotations originates from the Switchboard Dialog Act. This set of annotations was constructed from a large set of types of dialogues and is now widely used in the dialogue community. This rich tagset offers over 200 different tags (of which 60 are basic) that account for the various forms of exchanges found in dialogues, as found, e.g., in help desks. There are, however, no specific tags that can directly account for argumentation attitudes and it does not allow for expressing different propositional or psychological attitudes, and belief expressions important from a point of view of argument recognition.
Textual entailment (TE) [6] is a general approach that establishes a relation whenever the truth of a certain statement (or text fragment) follows from another statement or text fragment. The first statement is called the hypothesis. The type of inference developed in TE is quite different than those, much more specific, which are developed in Inference Anchoring Theory. IAT exploits the semantics and the dynamics of dialogical acts in order to identify inferences.
Presuppositional logic is a framework where a number of statements, called presuppositions, are generated by the preconditions that hold in particular on predicates and dialogue acts. Questions and assertions produced by the participants of a dialogue necessarily convey a number of presuppositions, be they historical, cultural or practical. In a statement such as “It was a fight for their independence”, presuppositions are e.g. that the population which is the focus of the dialogue was under the domination of another population or country and that it was not satisfied with this domination. These inferences may also be drawn to some extent by TE. Presuppositional logic involves general purpose reasoning as well as lexical inference (inferences which can be drawn from words taken in isolation) and offers a tool that can be used to draw some of the inferences introduced in the IAT model, for example to establish causal or thematic links between statements in different dialogue turns. IAT is more powerful in the sense that it includes many other forms of inferences related in particular to argumentation.
Speech Act Theory [22,28,29] considers interactions from the point of view of the intentions of the speakers (i.e. the force they give to their statements); however, it says little about whether and how, two illocutionary forces relate to each other. With IAT, illocutionary connections between locutions and propositional contents show the speaker’s intentions, and illocutionary connections derived from a sequence of locutions show their argumentative functions.
To summarise, the approaches cited above all have advantages over IAT, but have had influence on its coherence for handling argumentation in particular. For example, RST annotation schemes have influenced local structural analysis in IAT; Speech Act Theory offers an account of speakers’ communicative intentions that IAT renders through the analysis of illocutionary structures, etc.; SDRT reifies the relationship between an utterance and the dialogical history leading to that utterance, which is found in IAT in transition schemes. The essence of IAT therefore rests on its ability to combine linguistic, argumentation and pragmatic theories in order to deliver an analytical framework for dialogical argumentative discourse, which presents major challenges for all of the alternative approaches.
3.Corpus analysis
3.1.Annotation scheme
We assume that the utterance
Asserting. The speaker S uses an act of assertion to directly communicate his opinion about p. Asserting p does not assume S truly believes p – it is rather a public declaration of belief to which the speaker can be held.
Depending on the strength of assertive force (as [29] discuss, the illocutionary point, i.e. the internal purpose of a type of illocution, can be achieved with different degrees of strength), we distinguish three subcategories: strong assertion +A, e.g. “I certainly think people who don’t work, who are unemployed, are depressed”; standard assertion A, e.g. “It’s important to bring to justice the actual perpetrators of atrocities or war crimes”; and weak assertion −A, e.g. “Well, I guess for my definition, I would talk about rich countries in the West occupying countries of other people and imposing their rule on them”.
The rationale behind this distinction is to allow and enhance the identification of argumentative behaviours in dialogue. When the speaker performs a strong assertion rather than a weak one, it is more likely that he thereby generates an argument as a response to the opponent’s challenge. In the case where there are no linguistic cues for recognising the strength of asserting force, we use the default category of standard assertion A, and no anticipation of the argumentative behaviour can be made.
For example, if Bob expresses p with strong asserting force +A in (1-a), then it is more likely that he will react as in (1-c) in response to Wilma’s challenge. On the other hand, if he utters p with a weak assertion −A, then the dialogue could proceed differently and in (1-c), Bob could retract his commitment to p rather than argue that p because q.
Asserting force can be applied to three types of propositional contents: a strong content A+; a weak content A−; and a “neutral” content A. Strong propositional content A+ is identified when the speaker explicitly expresses some type of necessity of the truth of propositional content, e.g. “(…) for sure, there should be no statute of limitations in prosecuting them”; and weak content A−, when he expresses only the possibility of the content being true, e.g. “There might be a right to compensation in this case”. Again, the neutral content is the default subcategory, when there is no cue to associate a strong or weak type of content.
As a result, different combinations of the strengths of assertive illocution are possible, e.g. the weak assertion of a weak propositional content −A− as in: “We reckon that something like 100 billion pounds has been transferred from savers to borrowers”. In case it is ambiguous whether a linguistic cue refers to a type of illocutionary force or a propositional content like in: “(…) certainly all debt is not immoral”, we assign the strength to both of them (in this case: +A+).
Questioning. The speaker S utters a question when he formulates p in the grammatical form of interrogative sentence: “Is/Isn’t p the case?”. Here, only yes-no questions are taken into account, i.e. questions for which the possible answers in the next move in a dialogue are: “Yes, p”, “No, not-p”, or “I don’t know”.
Three main subcategories of questions have been distinguished in our corpus: pure questions PQ, assertive questions AQ, and rhetorical questions RQ. When S utters a PQ, e.g. “(…) should it be the occasion for examining the colonial legacy?”, he expresses that he is asking for the hearer H’s opinion on p: whether H believes p (manifested in the next move by the utterance “Yes, it should”), or not (“No, it shouldn’t”), or he doesn’t have an opinion on p (“I don’t know”).
AQ and RQ, in contrast, convey some assertive communicative intention. In the literature, there is no common specification of rhetorical questions. For example, in semantics, RQs are defined as denoting a truth-conditional statement (cf. [12]), while in discourse analysis the focus is on investigating the precise linguistic form of RQs (cf. [9,14,26]). For our purposes, however, it is sufficient to use a basic feature of RQs, upon which all these approaches agree [15], i.e., when S performs RQ: “Is/Isn’t p the case?”, S is grammatically stating a question, but in fact communicating that he does (or does not) believe p.
Finally, when S uses AQ, e.g. “Is it not the case that you are stretching your definition in order to make the British Empire fit into that?”, he not only directly seeks H’s opinion on p, but also indirectly publicly declares his own opinion on p. These subcategories form the continuum of the speaker’s intentions, with PQ and RQ as the extremes at either end, and AQ in the middle.
Challenging. S uses a dialogical act of challenging p in a dialogue when he suggests that he is asking about the grounds for hearer H’s opinion on p. Challenges are a dialogical mechanism for triggering argumentation. For example, in (1) Wilma’s utterance “Why p?” is a challenge, since she asks Bob about the reasons for believing p. In the next move, Bob provides a reason q and, as a result, the argument “p since q” is constructed by means of the dialogue. In the same way as for questions, challenges form a continuum from pure challenges (PCh) through assertive challenges (ACh) to rhetorical challenges (RCh).
Conceding. A concession, Cn, of p is used to convey agreement with respect to p, e.g., “I understand your point and of course there are living victims”. Concessions are like assertions, but place weaker commitments on the speaker, and as a result, in many types of dialogues S might not be obliged to defend his concession as a response to the opponent’s challenge (i.e. does not have a burden of proof [33]). The situation for disagreement is not symmetrical, i.e. when S disagrees with the opponent, he will perform just a simple assertion, because in disagreeing S clearly puts forward his standpoint and therefore he can be challenged by the respondent in the next move.
Amongst concessions we distinguish the subcategory of popular concession PCn, in which the speaker communicates some sort of general knowledge which is taken to be obvious and as such does not require to be defended (i.e. does not place a burden of proof on the speaker): “We know Kenya was a brutal war, …”. Popular concessions are often introduced to the discussion in order to partly agree with the opponent and with generally accepted truths, but at the same time to prepare ground for expressing disagreement in the next statement (with the contrast typically signalled with “but”) and showing that the real disagreement in the discussion lies elsewhere: “we have known about these things for years, there is nothing new in this, in Kenya and the problems we had in India, end of Empire is always a difficult bloody thing, but to pin the blame on the British for this is simply absurd, it’s not true”.
Affirming and disaffirming. The illocutionary structures that do not have explicit propositional content and are performed as a reaction to the opponent’s question are called affirmations Af (for a positive reaction, e.g. “Yes”, “Indeed”, “Most definitely”) and disaffirmations Df (for a negative reaction, e.g. “No”, “I’m not saying that”, “Actually, that’s not correct”).
Observe that when the broader dialogical context is not known and an assertion is examined in isolation, such as e.g. “these crimes were committed”, it is impossible to know what other dialogical act may be being made, e.g. whether it constitutes disagreement with what the opponent previously stated, or argumentation supporting some previously claimed opinion. Similarly, when an affirmation is put forward, such as e.g. “Oh yes, of course”, it is neither possible to know what other act may be being performed, nor even what propositional content is being referred to when a speaker says, “yes”.
3.2.A corpus for illocutionary structures
The corpus describes the genre of the moral debate and comprises of three episodes of the Moral Maze BBC Radio 4 programme in 2012 in which the total number of 12 speakers participated. The episodes have been transcribed to support IAT annotations: the transcripts presented punctuation but no prosodic marks. In Moral Maze, participants discuss moral aspects of important social and political issues in Great Britain. The programme is chaired by Michael Buerk who leads the discussion between four panellists i.e. public personalities with a background in social activism (writers, journalists, lecturers, public commentators etc.), and (usually) four witnesses who are invited because of their expertise on a given topic. These well-structured debates present some very long sentences, several types of statements, discourse regulators and other forms of dialogue management. The language used by participants contains much explicit signalling and speakers’ positions are made clear in terms of e.g. beliefs, strength of position or of assumptions [3]. The annotation task is still in progress aiming to have analysed all episodes from the year 2012.44
The global characteristics for our corpus are described in Table 1. The corpus was divided in two sub-corpora: development and test. Analysing texts according to IAT is particularly time-consuming task because of the large variety of schemes and categories, hence the relatively small size of our corpus. It remains, however, the largest publicly available corpus of analysed dialogical argumentation currently available.
Table 1
Summary of the language resources for the method of illocutionary structure parsing in the corpus of the Moral Maze programme
| Corpus | Words | Turns | Labels |
| Development | 15,200 | 169 | 342 |
| Test | 9,000 | 101 | 179 |
| Total | 24,200 | 270 | 521 |
Table 2 shows the distribution of the different illocutionary structures which were manually annotated. It demonstrates the prominence of pure assertions (noted as A) over the other types: 124 questions have been identified as opposed to 317 assertions, which is relatively well balanced. Discourse regulators, meant to manage the overall discussion, occur on average every 15 assertion or question discourse units, which shows the vitality of the discussions and the diversity of the sub-topics addressed. These figures are also useful to manage priority identification in the implementation.
Table 2
The number of occurrences of categories (labels) annotated in the corpus of the Moral Maze programme
| Category | # | Sub-category | # |
| Asserting | 317 (61%) | A | 280 |
| +A | 9 | ||
| −A | 8 | ||
| A+ | 14 | ||
| A− | 6 | ||
| Questioning | 124 (24%) | PQ | 36 |
| AQ | 52 | ||
| RQ | 36 | ||
| Challenging | 7 (1%) | PCh | 5 |
| ACh | 2 | ||
| Conceding | 9 (2%) | Cn | 1 |
| PCn | 8 | ||
| (Dis-)affirming | 37 (7%) | Af | 27 |
| Df | 10 | ||
| Discourse regulators | 27 (5%) | ||
| Total | 521 (100%) |
3.3.Illocutionary structure, arguments and dialogical context
Using the taxonomy described in Section 3.1, together with the IAT framework described in Section 2.1, we are now able to adequately represent the dialogical context of arguments in example (2). The utterance (2-a) is an assertion (see asserting instance #1 in Fig. 2), in which James publicly declares his belief that the uncivilised behaviour of the Empire was a ghastly aberration. The first utterance in (2-b) is RQ (see rhetorical questioning instance #1), and as a result, we recognise that in saying “Or was it in fact typical?” Longley is not searching for James’ response, but is instead declaring his own belief that uncivilised behaviour was typical for the Empire.55 The second utterance in (2-b) is AQ (assertive questioning instance #1), in that Longley is not only asking James whether he thinks that an uncivilised behaviour was the product of a policy, but also declares that he believes so himself.
Fig. 2.
Asserting, rhetorical questioning and assertive questioning as the dialogical context for argument structures in example (2).
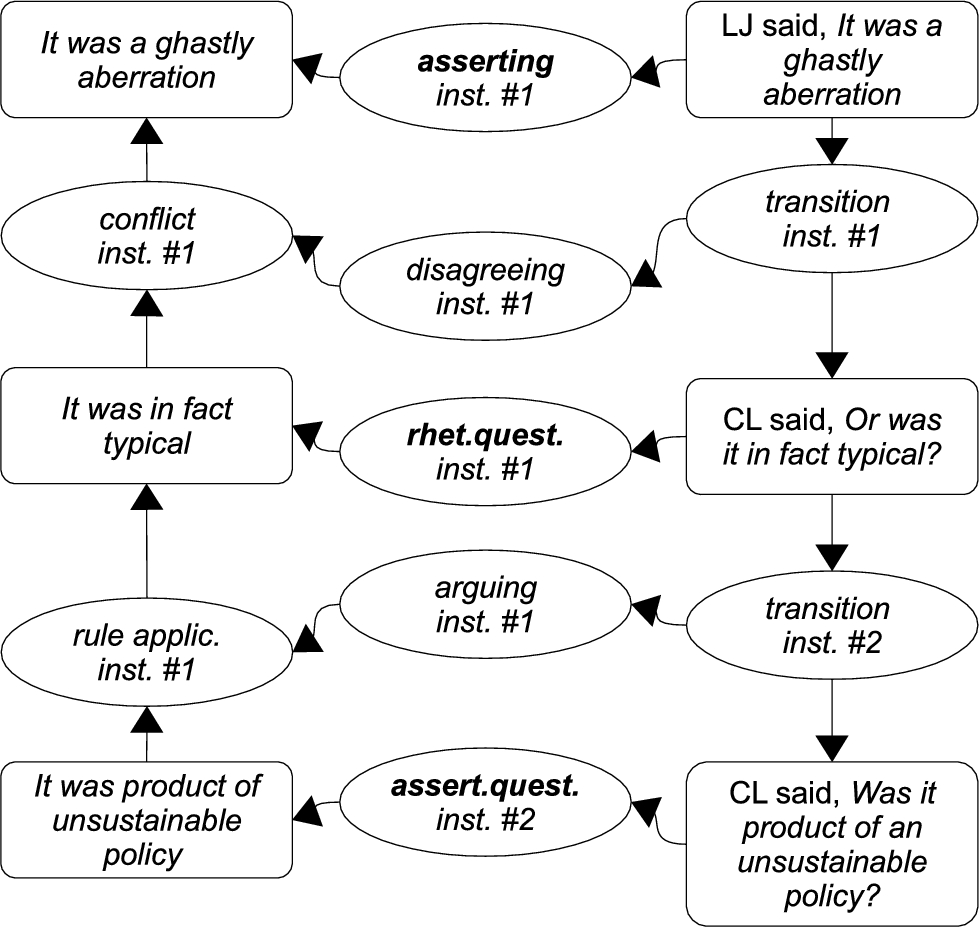
We can thus extract the contents of RQ and AQ, which allow us to identify a relation between them that constitutes an inference (inference instance #1) with the illocution of arguing (arguing instance #1) and thence to recognise the remaining components such as, e.g., the fact that Longley’s argument is a dialogical response in which he communicates his disagreement (disagreeing instance #1) and constructs a conflict (conflict instance #1) between the conclusion of his argumentation and the content of proponent’s utterance (2-a).
Inference Anchoring Theory is not a simple composition of a unit-based approach and a relation-based approach. It provides a framework of constraints on how particular unit types (unitary illocutionary structures) constrain the available relation types (relational illocutionary structures). As a result, IAT delivers a rich set of features for recognising arguments as dialogical sequences of, for example, assertion and rhetorical questioning, or rhetorical questioning and assertive questioning. The connections between unitary illocutionary structures and relational structures can be then operationalised in standard statistical machine learning techniques.
4.Linguistic model and implementation
The next sections briefly describe the linguistic modelling and the implementation of some of the foundational aspects of illocutionary force analysis presented above. We will show how (1) a dialogue can be decomposed into meaningful dialogue text units using a dedicated grammar than can identify and delimit such units and (2) how an illocutionary force can be assigned to each of these units, following the definitions given in Section 3.1. The analysis has been realized from a development corpus and tested on a different corpus of the same origin.
4.1.A grammar for text unit identification
Given a dialogue transcript, the first task is, for each dialogue turn, to identify the basic dialogue units (also called argumentative segments). These basic units are the minimal units, in terms of contents, which are autonomous and can be connected to other units via various types of dialogue relations. Our analysis posits that in a coherent argumentative text, these units are all linked to each other, and form a graph, as shown in Figs. 1–2. No unit is left pending: all units are connected to others. The structure is however not as hierarchical as discourse analysis in general, and there is no a priori notion of nuclearity.
For that purpose, we developed an elementary discourse unit (EDU) [27] analysis dedicated to dialogical situations. These specific EDUs turn out to have specific forms and linguistic marks proper to argumentative dialogue compared to those defined for discourse analysis in general. According to the observations made on our corpus, in most situations, units can be identified on the basis of discourse marks typical of dialogue, e.g. marks related to challenge, position or belief statements, or an aggregation of such marks, e.g. when there is an intention of persuasion. Marks are developed below. Since our corpus was rather small at that time, and due to the well-known linguistic sparsity of some constructions, besides corpus analysis, we added closely related terms, such as quasi synonyms. At the time of publication, the corpus has grown to a much larger size, making EDUs analysis much more reliable.
A number of psycholinguistic investigations summarized in [11] show that marks are used by human subjects both as cohesive links between adjacent clauses and as connectors between larger textual units. An important result is that discourse markers are used consistently with the semantics and pragmatics of the textual units they connect and they are relatively frequent and unambiguous. The semantics and pragmatics of a number of connectors are investigated in e.g. [34].
A grammar that allows for the identification and the delimitation of these text units can be elaborated on the basis of these marks and punctuation. The main categories of marks used to identify text units include:
– verbs, which promote controversies, beliefs, position statement and argumentation. The following classes are the most prominent: propositional attitude verbs (think, believe, agree, deny), epistemic verbs (know, understand), communication and report verbs (claim, hold) and psychological verbs (dream, worry, be intrigued); we also noted a few metaphorical uses (it tends to);
– modal expressions specific to interaction (could be, may mean);
– opinion expression adverbials and related expressions (definitely, surely, obviously) found in assertive statements;
– specific interrogative forms, rhetorical questions, or marks suggesting challenges (where does + pronoun, isn’t + demonstrative, why should).
To handle these marks and their associated linguistic elements (e.g. subjects, pronouns, negation, modals, etc.), potential synonyms, and morphological variations, we developed ‘local’ grammars dealing with e.g. propositional attitude expressions, position statements, psychological expressions, questions, etc. in their linguistic diversity. A total of 52 rules have been developed for that purpose. These rules implement what we call g-marks (grammaticalized marks), e.g. informally:
Rules of the same type have been developed for modals, opinion expression of question formulation, such as, with the same notations:
These rules were designed manually and emerged from corpus observations, leading to the above categorizations, and to generalizations (e.g. including all the relevant propositional attitude verbs in the lexicon even if only a few have been observed) in order to have an adequate linguistic coverage.
These local grammars are then integrated into larger grammatical forms which both identify and delimit the text units. The general form of these latter rules follows the Dislog syntax, which is roughly as follows:
The symbol “gap” indicates a finite set of words which are of no present interest which can be skipped. For example, in: “Well, isn’t that a source of injustice?”, the first unit delimiter is the beginning if the sentence, the g-mark is isn’t that and the second unit delimiter is the question mark. The two gaps are respectively: well, and a source of injustice. In a number of cases where the unit delimiter is at the beginning of the unit, the gap is empty.
The grammar is implemented using the <TextCoop> platform and the Dislog language [25], specifically designed for discourse processing. Dislog extends and generalizes the expressive power of regular expressions in several ways, most notably via the introduction of typed feature structures, controls over skipped structures (gaps) and its ability to include reasoning schemas, e.g. to resolve ambiguities or to compute a result. In general, the result of an analysis is an XML tagged text; it can also be a dependency structure.
We have conducted an indicative evaluation (to identify improvement directions) on the previously manually annotated test text where 179 text unit occurrences have been identified. This is a small scale test but it turns out to be sufficient for a first analysis. Out of this set of 179 units, our system:
– correctly annotated 153 units (85%) (identification and delimitation);
– correctly identified 13 units (7%) but with incorrect delimitation (a unit is split into several or vice-versa, or unit is larger or shorter than what was manually annotated);
– identified 7 units (4%) which are not directly dialogical text units;
– failed to identify 6 units (4%) because of a lack of linguistic data, including the quasi-synonyms we added.
4.2.Illocutionary structure identification
The next step is to identify the illocutionary structures (depending on the type of an illocutionary force) presented in Section 3.1 for each text unit. A coherent dialogue requires that each text unit is assigned a type. Unlike at the previous step, it is not possible, however, to identify all illocutionary force types solely on the basis of linguistic marks. In some cases the illocutionary force cannot be assigned to a unit in isolation: it is necessary to take into account e.g. the illocutionary forces assigned to adjacent units, the position of the unit in the dialogue turn (starting, ending) and the role of the speaker in the debate (e.g. moderator).
Linguistic marks alone do, however, provide substantial information about illocutionary structure, and, in this preliminary analysis, we present the main results obtained on that basis. Our observations show that the linguistic criteria used to identify illocutionary forces are within each text unit, without any reference to other text units. Linguistic forms and aggregation of simple forms used to identify the types of dialogical acts are different from those used for text unit delimitation. These linguistic forms have been identified from our corpus, and then expanded to similar terms and represented as above for text units by means of g-marks. The technique and the current limitations (relatively small corpus) are the same as for the previous step. However, with the current development of a much larger and stable corpus, these results will most probably largely evolve and be improved.
A significant number of linguistic forms we have identified are very general and are shared by several illocutionary forces. Our strategy is not to have default illocutionary force assignment, but to explicitly represent the ambiguity, which may be resolved later by other means. For that purpose, we introduce polymorphic types that represent the ambiguity (or underspecification). For example, AQ–RQ is the polymorphic type assigned to a text unit which can be one of the two types AQ or RQ, when it was not possible to make a decision between these two types. Of interest is the study of the overlap situations, so that the pragmatic factors at stake can be better identified. Polymorphic types concern questions or assertions separately, since these two main categories can be relatively well identified via punctuation.
Linguistic forms are quite diverse (42 forms have been identified), with a large number of morphological variants. 12 types, simple or polymorphic, have been defined for questions, with an average of about 35 forms with morphological variants for each. Forms which are common to two or more basic types are then associated with the polymorphic types. These forms are implemented in the Dislog language, using g-marks as symbols in the rules.
From our analysis, it turns out that about 63% of the linguistic marks are typical of a unique illocutionary force, therefore proper to specific types. We have, for example the following types of marks (implemented in g-marks):
– RQ: conditional questioning (why should, should we), and indirect forms based on negation (aren’t, isn’t);
– AQ: important use of the past (was it, were we), and forms using would (would you, would that);
– AC: why followed by the auxiliary to be;
– PCh: why followed by do or would;
– Polymorphic types such as PCh–RQ include forms which are ambiguous, in particular why + (do) + demonstrative;
– RQ–PQ includes forms in should + demonstrative or personal pronoun.
To identify illocutionary forces we have then written 18 rules in Dislog that implement the g-mark recognition and illocutionary force assignment.
Considering our corpus of three manually annotated texts, we have the following distributions for polymorphic types:
– PQ–AQ: 13%,
– AQ–RQ: 10%,
– PQ–AQ: 6%,
– RQ–PCh: 4%,
– RQ–ACh: 4%,
– and 3% for the remainder.
This means that about 62% of the text units are a priori unambiguous w.r.t. their illocutionary force, which is a rather low proportion. It is thus crucial to identify additional factors (pragmatic, typographic) that contribute to resolve the ambiguities.
Table 3
The results of illocutionary structure parsing
| Correctly identified | 78% | via basic types | 38% |
| via polymorphic types | 40% | ||
| Incorrectly identified | 22% |
To carry out a simple indicative evaluation, let us consider the 153 text units that were correctly identified, as indicated in the previous section, we obtain the results given in Table 3. In the first case, the assignment is made for the basic type of illocutionary forces, so there is no ambiguity. In the second case, it is important to note that 65% of the polymorphic types is the combination of different strengths of assertions where the distinction, even for humans, is difficult to make. The erroneous assignment can still be improved by some typographic and linguistic adjustments. These results – of 78% accuracy with polymorphic types – although still preliminary, are very encouraging considering the difficulty of the task.
The results of the parse is annotation over the original text, as shown for example (2):
<utterance speaker = “lj” illoc = “standard_assertion”> <textunit nb = “215”> it was a ghastly aberration </textunit> </utterance>.
<utterance speaker = “cl” illoc = “RQ”> <textunit nb = “216”> or was it in fact typical? </textunit> </utterance>.
<utterance speaker = “cl” illoc = “RQ–AQ”> <textunit nb = “217”> was it the product of a policy that was unsustainable that could only be pursued by increasing repression? </textunit> </utterance>.
An internal representation, in Prolog, has been developed in parallel with this XML annotation, so that (1) these two steps can be pipelined and connected to the following ones (transition analysis in particular) and (2) OVA+ diagrams can be generated.
5.Conclusions
Building upon the general framework of Inference Anchoring Theory, the paper proposes a simple taxonomy of unitary illocutionary structures that accompany argumentation in dialogical contexts in the corpus from the Moral Maze programme, and reports preliminary results for recognition of those illocutionary structures in raw, spoken-language transcripts. These results are encouraging and bring the automatic identification of dialogic argument structure in discourse such as the real-world, complex example (2) one step closer, with the parse above representing a crucial milestone.
This is a first experiment in illocutionary structure parsing that needs to be further extended to other texts of the same type (agreement-seeking dialogues on controversial issues), so that the linguistic model can be enhanced. Results so far are relatively good, though more deteriorated forms of dialogues will also be considered, where irony and emphasis may present additional challenges.
Then, we will need to develop the two further steps to handle the remaining two types of information shown in Figs. 1–2, namely the types of transitions between locutions in a given dialogue type, and the illocutionary structures that are anchored in them. In particular, we expect that besides argumentative illocutionary structures, the participants could have explanatory intentions (which will introduce further inferences), and disagreeing and undercutting intentions (which will introduce the relation of conflict between contents). In terms of transitions typical for our corpus, we expect to encounter sequences of PCh–A which will anchor argumentative illocutions and inferences, but also, e.g., sequences of AQ–Df which will anchor illocutions of disagreement and conflict. Together, these techniques can pave the way towards recognition of the structure of argumentative dialogues as a whole.
The linguistic model and the implementation proposed in this paper are exploratory: our goal was to investigate the language model, the lexical resources and the type of categorisations that could be carried out from a relatively small corpus. The results are encouraging: lexical categories typical of interaction and argumentation emerged and seem to confer a good linguistic coverage to the analysis system. The language model is so far relatively simple but with a good explanatory power, that confirms our intuitions. The evaluation is indicative, but the results suggest that the techniques we deployed are appropriate and could be extended. As the corpus annotation task continues, increasingly stable annotations should allow us to have a much more accurate analysis system, based on approximately the same technology.
Notes
2 This is only a simple example illustrating how IAT explains the relation between argument structures and dialogue structures. Since this paper focuses only on the first step of the identification of dialogical arguments – i.e. illocutionary structure parsing, we do not describe other argument structures related to e.g. conflict or rephrase (see e.g. [4] for more details).
3 In this model, the exact representation of (2-b) would be: argue(Uncivilised behaviour was typical for the Empire); assert(Such a behaviour was the product of an unsustainable policy).
4 The current version of MM2012 corpus annotated using the OVA+ software tool (ova.arg-tech.org [13]) can be found at corpora.aifdb.org/mm2012.
5 Observe that an alternative interpretation is also possible, viz. that this utterance is an assertive question.
Acknowledgements
The authors would like to acknowledge that the work reported in this paper has been supported in part by the Polish National Science Center under grant 2011/03/B/HS1/04559 and in part by the EPSRC under grant EP/G060347/1.
References
[1] | N. Asher and A. Lascarides, Logics of Conversations, Cambridge University Press, (2003) . |
[2] | K. Budzynska and C. Reed, Whence inference? in: University of Dundee Technical Report, (2011) . |
[3] | K. Budzynska, M. Janier, J. Kang, C. Reed, P. Saint Dizier, M. Stede and O. Yaskorska, Towards argument mining from dialogue, in: Computational Models of Argument (COMMA14), Frontiers in Artificial Intelligence and Applications, Vol. 266: , IOS Press, (2014) , pp. 185–196. |
[4] | K. Budzynska, M. Janier, J. Kang, C. Reed, P. Saint-Dizier, M. Stede, O. Yaskorska and B. Konat, Automatically identifying transitions between locutions in dialogue, in: Studies in Logic and Argumentation, Proceedings of the 1st European Conference on Argumentation (ECA 2015), King’s College Publication, (2016) . |
[5] | J. Carletta, The reliability of a dialogue structure coding scheme, Computational Linguistics 23: (1) ((1997) ), 13–32. |
[6] | I. Dagan, O. Glickman and B. Magnini, The Pascal recognising textual entailment challenge, Lecture Notes in Computer Science 3944: ((2006) ), 177–190. doi:10.1007/11736790_9. |
[7] | P.M. Dung, On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games, Artificial Intelligence 77: ((1995) ), 321–357. doi:10.1016/0004-3702(94)00041-X. |
[8] | A. Fiedler and H. Horacek, Argumentation within deductive reasoning, International Journal of Intelligent Systems 22: (1) ((2007) ), 49–70. doi:10.1002/int.20189. |
[9] | J. Frank, You call that a rhetorical question? Journal of Pragmatics 14: ((1990) ), 723–738. doi:10.1016/0378-2166(90)90003-V. |
[10] | J. Ginzburg, The Semantics of Dialogue, Cambridge University Press, (2012) . |
[11] | B. Grosz and C. Sidner, Attention, intention and the structure of discourse, Computational Linguistics 12: (3) ((1986) ), 175–204. |
[12] | C. Han, Interpreting interrogatives as rhetorical questions, Lingua 112: ((2002) ), 112–229. |
[13] | M. Janier, J. Lawrence and C. Reed, Ova+: An argument analysis interface, in: Computational Models of Argument (COMMA14), Frontiers in Artificial Intelligence and Applications, Vol. 266: , IOS Press, (2014) , pp. 463–464. |
[14] | I. Koshik, Wh-questions used as challenges, Discourse Studies 5: ((2003) ), 51–77. doi:10.1177/14614456030050010301. |
[15] | R. Lee-Goldman, A typology of rhetorical questions, Presented to the Syntax and Semantics Circle, UCB, 2006. |
[16] | J. Mackenzie, Four dialogue systems, Studia Logica 51: ((1990) ), 567–583. doi:10.1007/BF00370166. |
[17] | W.C. Mann, Dialogue macrogame theory, 2002, available at: http://www-bcf.usc.edu/~billmann/dialogue/SIG-DMT-PF6.htm. |
[18] | W.C. Mann and S. Thompson, Rhetorical structure theory: Toward a functional theory of text organization, Text 8: (3) ((1988) ), 243–281. |
[19] | D. Marcu, The rhetorical parsing of natural language texts, in: ACL ’98, (1997) , pp. 96–103. |
[20] | D. Marcu, The Theory and Practice of Discourse Parsing and Summarization, MIT Press, (2000) . |
[21] | M.-F. Moens, Argumentation mining: Where are we now, where do we want to be and how do we get there? in: FIRE ’13: Proceedings of the 5th 2013 Forum on Information Retrieval Evaluation, (2013) . |
[22] | J. Moeschler, Speech act theory and the analysis of conversation, in: Essays in Speech Act Theory, John Benjamins, (2002) , pp. 239–261. |
[23] | A. Peldszus and M. Stede, From argument diagrams to argumentation mining in texts: a survey, International Journal of Cognitive Informatics and Natural Intelligence (IJCINI), 7: (1) ((2013) ), 1–31. |
[24] | C. Reed, Generating arguments in natural language, Unpublished doctoral dissertation, University College London, 1998. |
[25] | P. Saint-Dizier, Processing natural language arguments with the <textcoop> platform, Journal of Argument and Computation 3: (1) ((2012) ), 49–82. doi:10.1080/19462166.2012.663539. |
[26] | D. Schaffer, Can rhetorical questions function as retorts?: Is the pope catholic? Journal of Pragmatics 37: ((2005) ), 433–460. |
[27] | H. Schauer, From elementary discourse units to complex ones, in: SIGDIAL ’00, 2006. |
[28] | J. Searle, Speech Acts: An Essay in the Philosophy of Language, Cambridge University Press, (1969) . |
[29] | J. Searle and D. Vanderveken, Foundations of Illocutionary Logic, Cambridge University Press, (1985) . |
[30] | A. Stolcke, K. Ries, N. Coccaro, E. Shriberg, R. Bates, D. Jurafsky, P. Taylor, R. Martin, M. Meteer and C.V. Ess-Dykema, Dialogue act modeling for automatic tagging and recognition of conversational speech, Computational Linguistics 26: (3) ((2000) ), 339–371. doi:10.1162/089120100561737. |
[31] | J. Turri, Epistemic invariantism and speech act contextualism, Philosophical Review 119: (1) ((2010) ), 77–95. doi:10.1215/00318108-2009-026. |
[32] | D. Walton, C. Reed and F. Macagno, Argumentation Schemes, Cambridge University Press, (2008) . |
[33] | D.N. Walton and E.C.W. Krabbe, Commitment in Dialogue: Basic Concepts of Interpersonal Reasoning, State University of N.Y. Press, (1995) . |
[34] | G. Winterstein, What but-sentences argue for: An argumentative analysis of but, Lingua 122: ((2012) ), 1864–1885. doi:10.1016/j.lingua.2012.09.014. |


